知识蒸馏方法的演进历史综述
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要7分钟
跟随小博主,每天进步一丢丢


作者:Nishant Nikhil
编译:ronghuaiyang
来自:AI公园
带你回顾知识蒸馏的6篇文章,了解知识蒸馏的演进历史。
历史
2012年,AlexNet在ImageNet数据上的表现超过了所有现有模型。神经网络即将被广泛采用。到2015年,许多SOTA都被打破了。业界的趋势是在你能找到的任何场景上都使用神经网络。VGG Net的成功进一步肯定了采用可以使用更深层次模型或模型集成来提高性能。
(模型集合只是一个花哨的术语。它意味着对多个模型的输出进行平均。比如,如果有三个模型,两个模型预测的是“A”,而一个模型预测的是“B”,那么就把最终的预测作为“A”(两票对一票))。
但是这些更深层次的模型和模型的集合过于昂贵,无法在推理过程中运行。(3个模型的集成使用的计算量是单个模型的3倍)。
思想
Geoffrey Hinton, Oriol Vinyals和Jeff Dean想出了一个策略,在这些预先训练的集成模型的指导下训练浅层模型。他们称其为知识蒸馏,因为你将知识从一个预先训练好的模型中提取到一个新的模型中。这就像是老师在指导学生,所以也被称为师生学习:https://arxiv.org/abs/1503.02531。
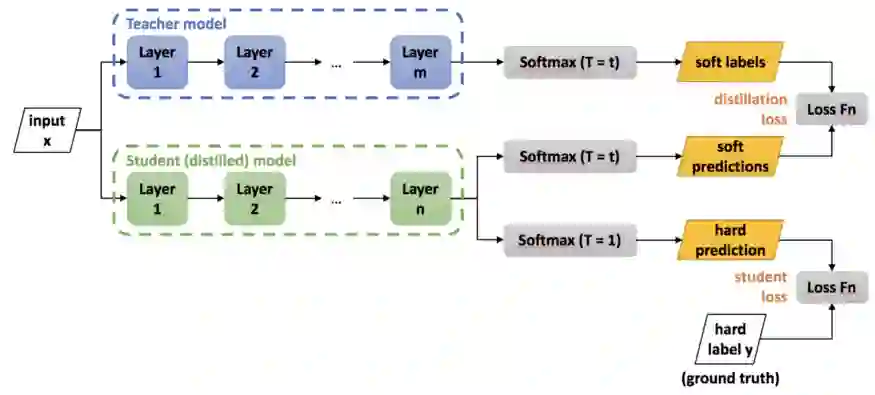
在知识蒸馏中,他们使用预训练模型的输出概率作为新的浅层模型的标签。通过这篇文章,你可以了解到这项技术的演进。
Fitnets
2015年出现了FitNets: hint for Thin Deep Nets(发布于ICLR'15)除了KD的损失,FitNets还增加了一个附加项。它们从两个网络的中点获取表示,并在这些点的特征表示之间增加均方损失。
经过训练的网络提供了一种新的学习-中间-表示让新的网络去模仿。这些表示有助于学生有效地学习,被称为hints。
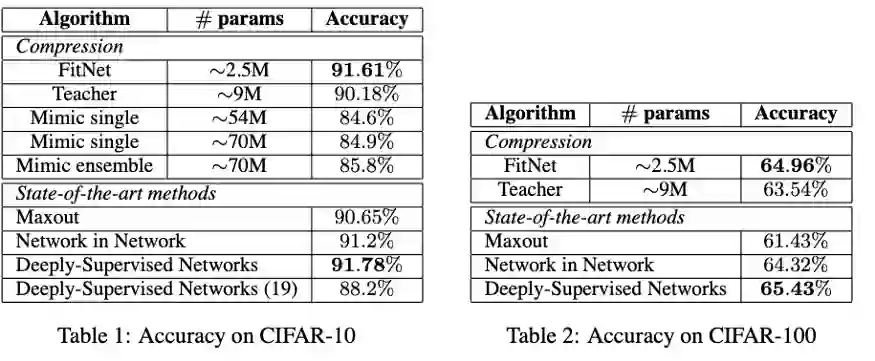
回过头看看,使用单点给出hints的选择不是最优的。随后的许多论文都试图改进这些hints。
Paying more attention to attention
Paying more attention to attention: Improving the performance of convolutional neural networks via Attention Transfer发布于ICLR 2017。

它们的动机与FitNets类似,但它们不是使用网络中某个点的表示,而是使用注意力图作为hints。(老师和学生的注意力图)。它们还使用网络中的多个点来提供hints,而不是FitNets中的单点hints。
A Gift from Knowledge Distillation
同年,A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning发布于CVPR 2017。
这和FitNets和注意力转移的论文也很类似。但是,与表示和注意力图不同的是,它们使用Gram矩阵给出了hints。
他们在论文中对此进行了类比:
“如果是人类的话,老师解释一个问题的解决过程,学生学习解决问题的过程。学生DNN不一定要学习具体问题输入时的中间输出,但可以学习遇到具体类型的问题时的求解方法。通过这种方式,我们相信演示问题的解决过程比讲授中间结果提供了更好的泛化。”
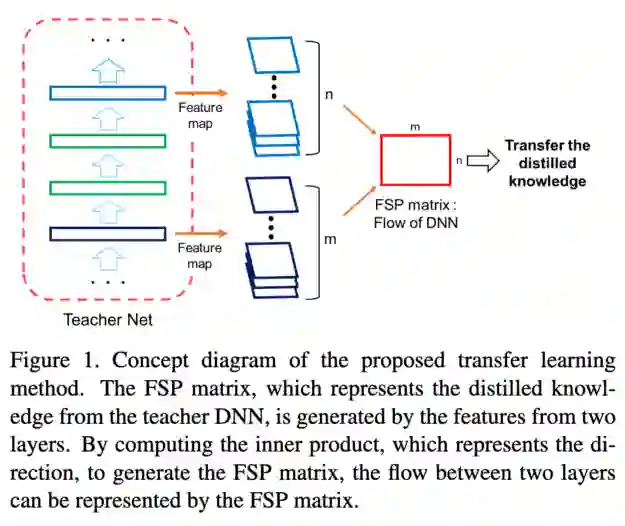
为了度量这个“解决流程”,他们在两个层的特征图之间使用了Gram矩阵。因此,它没有使用FitNets中的中间特征表示作为hints,而是使用特征表示之间的Gram矩阵作为hints。
Paraphrasing Complex Network
然后到了2018年,Paraphrasing Complex Network: Network Compression via Factor Transfer发布于NeurIPS 2018。

他们在模型中增加了另一个模块,他们称之为paraphraser。它基本上是一个不减少尺寸的自编码器。从最后一层开始,他们又分出另外一层用于reconstruction loss。
学生模型中还有另一个名为translator的模块。它把学生模型的最后一层的输出嵌入到老师的paraphraser维度中。他们用老师潜在的paraphrased 表示作为hints。
学生模型应该能够为来自教师网络的输入构造一个自编码器的表示。
AComprehensive Overhaul of Feature Distillation
在2019年,A Comprehensive Overhaul of Feature Distillation发布于ICCV 2019。
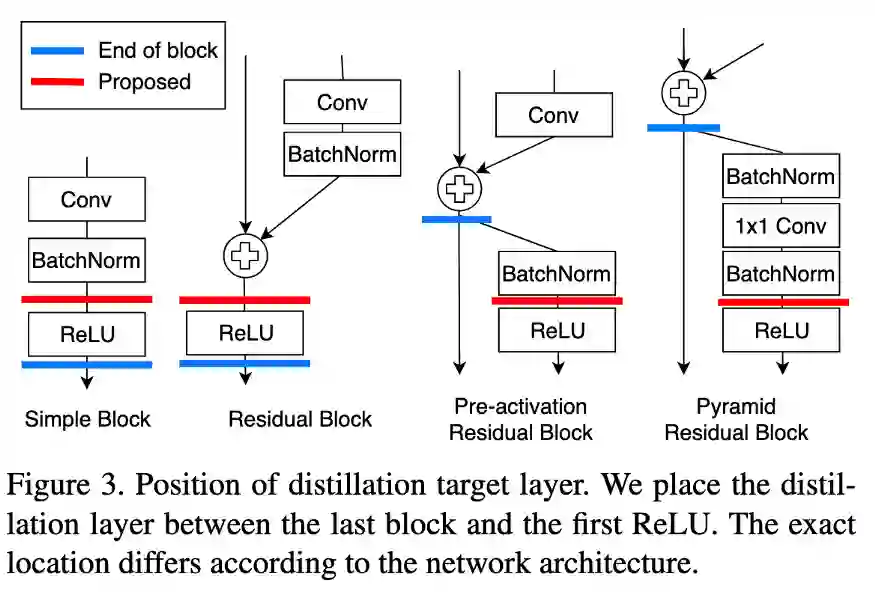
他们认为我们获取hints的位置不是最佳的。通过ReLU对输出进行细化,在转换过程中会丢失一些信息。他们提出了marginReLU激活函数(移位的ReLU)。“在我们的margin ReLU,积极的(有益的)信息被使用而没有任何改变,而消极的(不利的)信息被压制。结果表明,该方法可以在不遗漏有益信息的情况下进行蒸馏。“
他们采用了partial L2 distance函数,目的是跳过对负区域信息的蒸馏。(如果该位置的学生和老师的特征向量都是负的,则没有损失)
Contrastive Representation Distillation发表于ICLR 2020。在这里,学生也从教师的中间表示进行学习,但不是通过MSE损失,他们使用了对比损失。
总的来说,这些不同的模型采用了不同的方法
-
增加蒸馏中传递信息的量。(特征表示、Gram矩阵、注意力图、Paraphrased表示、pre-ReLU特征) -
通过调整损失函数,使蒸馏过程更有效(对比损失,partial L2 distance)
看待这些想法的另一种有趣的方式是,新想法是旧想法的向量和。
-
KD的Gram矩阵 = Neural Style Transfer + KD -
KD的注意力图 = Attention is all you need + KD -
Paraphrased表示 KD = Autoencoder + KD -
Contrastive表示蒸馏 = InfoNCE + KD
其他向量的和是什么?
-
GANs for KD(即改变特征表示之间的GAN损失的对比损失) -
弱监督KD( Self-Training with Noisy Student Improves ImageNet classification )

英文原文:https://towardsdatascience.com/knowledge-distillation-a-survey-through-time-187de05a278a
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! ![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT ![]()
后台回复【南大模式识别】
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
记得备注呦
推荐两个专辑给大家: 专辑 | 李宏毅人类语言处理2020笔记 专辑 | NLP论文解读 专辑 | 情感分析
整理不易,还望给个在看!








