深度学习平台技术演进
2017年12月22日,袁进辉(老师木)代表OneFlow团队在全球互联网架构大会上海站做了《深度学习平台技术演进》的报告,小编对报告内容作简要梳理注解,以飨读者。
此次报告的主要观点为:(1)计算力是神经网络/深度学习复兴的最大推动力之一;(2)面对深度学习的计算力挑战,软件至少和硬件一样地关键,单靠硬件无法提供易用性和扩展性;(3)鉴于深度学习上层业务和底层硬件的独特性,传统大数据平台里的某些技术未必再对深度学习平台适用;(4)深度学习软件平台技术在快速演进中,一部分早期被采用的技术正在被新方法替代;(5)仍有很多重要问题未被现有开源深度学习平台解决;(6)深度学习软件尚处在发展早期,百花齐放,百家争鸣,但必将收敛到一种业界公认的最佳实践(best practice)。


注:深度学习在近些年带来的突破无须赘言,从图像 (ImageNet) ,语音,围棋人机大战等方面的突破都源于深度学习技术。
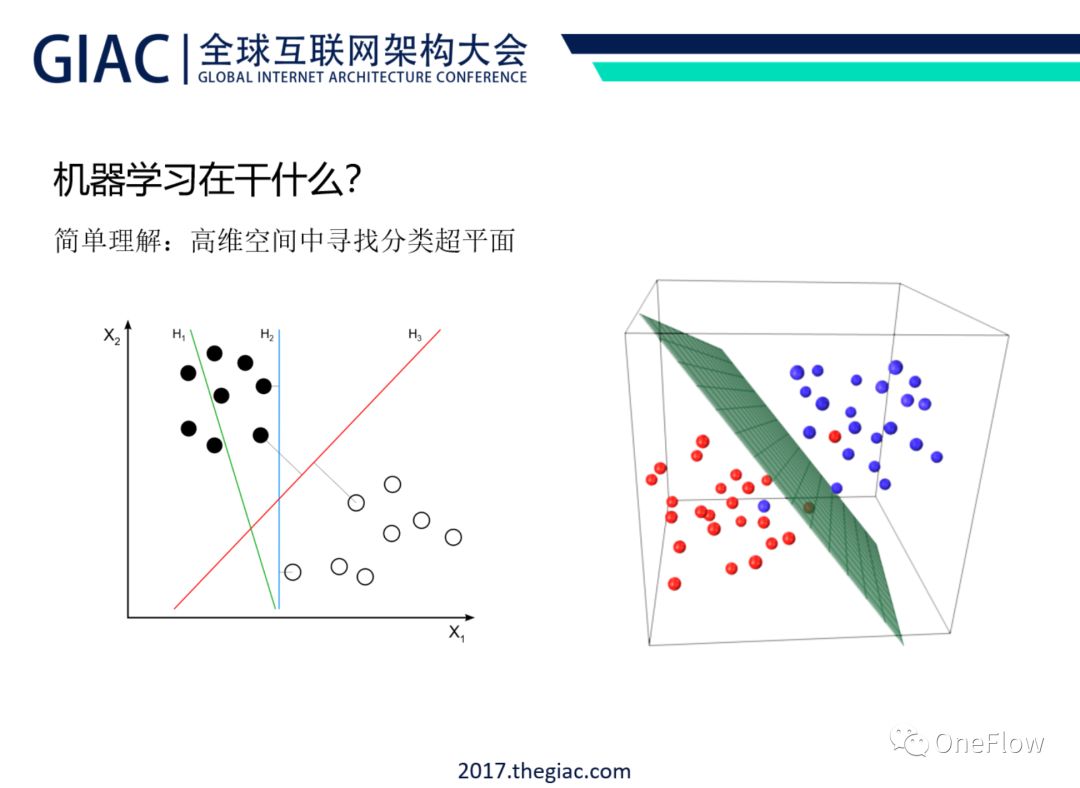
注:机器学习可以视为一种从训练数据中自动推导出程序的方法。以最常见的有监督学习(supervised learning)为例,可简单理解为,通过优化方法自动在高维空间找到分类超平面。
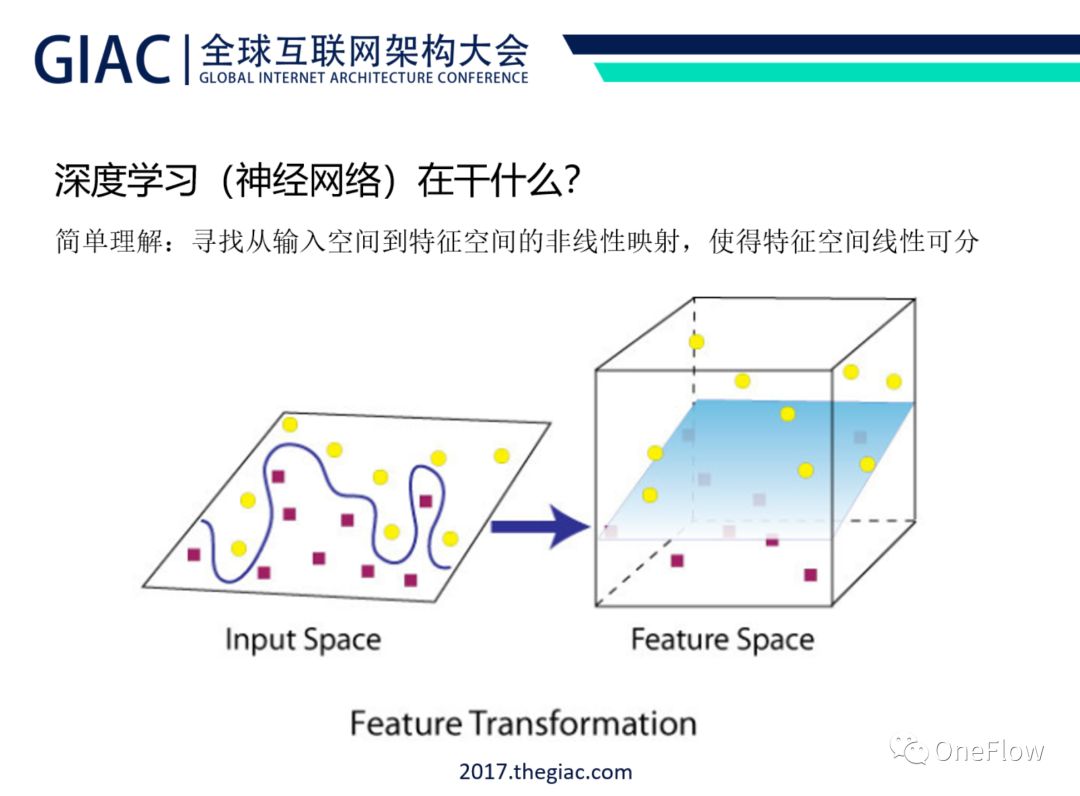
注:现实中遇到的绝大部分机器学习问题,基于原始特征(Input Space)无法找到分类超平面把训练数据里的正例和负例恰好分开。在机器学习领域,有一些通用的手段来处理线性不可分的问题,譬如可以在Input Space 寻求非线性分界面,而不再寻求线性分界面;也可以通过对特征做预处理,通过非线性映射的手段把训练数据从Input Space 映射到一个所谓的Feature Space,在原始Input Space无法线性可分的样例在Feature Space有可能线性可分。深度学习就是这种思想的一个典型应用。
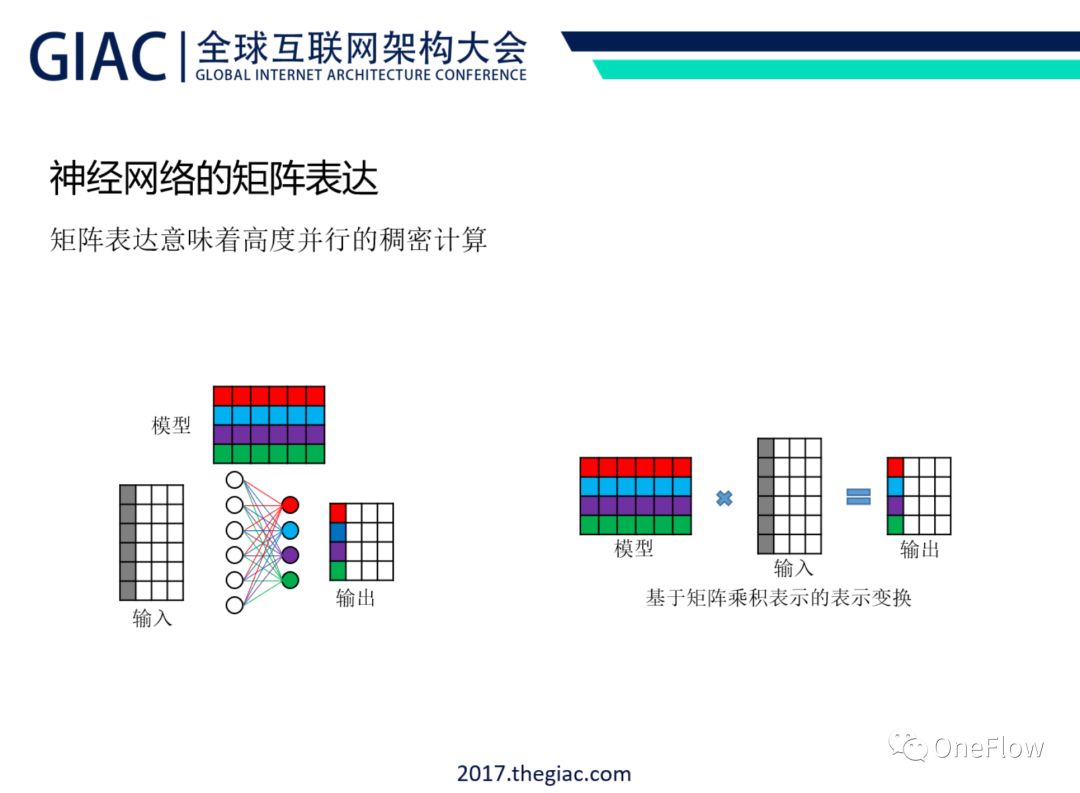
注:深度学习从计算上体现为一连串的变换(transformation),常见的变换都可以表示成矩阵计算。以上图为例,输入层有6个神经元,输出层共有4个神经元,每个输出神经元都和输入层的每个神经元有一条边相连,每条边有一个对应的权重(红色神经元的输入边权重都用红色表示)。输入数据是4个样例,每个样例是一个6维的列向量,列向量的每一维对应输入层的一个神经元。输入数据经过这层神经元的作用,仍是4个样例,每个样例变成了4维的列向量。这样一层神经网络可以用右图的矩阵乘法来表示。像这种稠密矩阵运算意味着并行计算的潜力。

注:以大家耳熟能详的卷积神经网络CNN 为例,可以感觉一下目前训练深度学习模型需要多少计算力。这张表列出了常见CNN模型处理一张图片需要的内存容量和浮点计算次数,譬如VGG-16网络处理一张图片就需要16Gflops。值得注意的是,基于ImageNet数据集训练CNN,数据集一共大约120万张图片,训练算法需要对这个数据集扫描100遍(epoch),这意味着10^18次浮点计算,即1exaFlops。简单演算一下可发现,基于一个主频为2.0GHz的CPU core来训练这样的模型需要好几年的时间。下面我们看一下使用几种典型硬件来训练CNN模型需要多少时间。
转自:OneFlow
完整内容请点击“阅读原文”



