工业级机器翻译研究与应用

分享嘉宾:王明轩博士 字节跳动 算法科学家
编辑整理:曾辉、Hoh
语音朗读:蒋志新
出品平台:DataFunTalk
导读:本文的主题为火山翻译:工业级应用与研究,将从两个维度介绍字节跳动的机器翻译工作:首先,机器翻译工业级别的应用,如何通过机器翻译服务全球用户;然后,介绍我们在大规模应用中产生的一些新算法,包括预训练、多语言机器翻译和多模态机器翻译等。
1. 背景介绍

其实机器翻译这几年在产业界已经有了非常多的应用。日常生活中大家接触的信息主要是中文或者英文,但是从全球的范围来看,语言的分布还是比较广泛的。全球有5000多种语言,400多种文字。这些地区的人需要获取新的信息,由于本土语言的内容比较少,所以需要通过机器翻译来打破这种信息障碍,使不同语言的人们可以进行交流,了解对方。

最近有一项社会学研究称,在过去的几年中,机器翻译让国际贸易增加了10%,并且让整个世界变小了26%。这是一个非常实际的影响,AI技术真正的在改变世界。
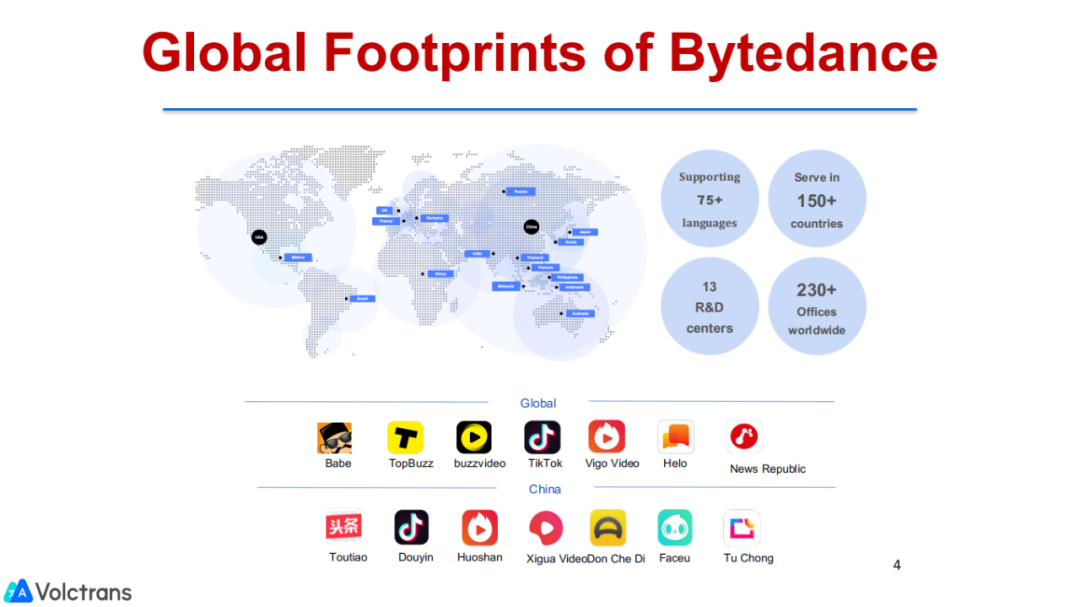
字节跳动诞生伊始就以国际化为目标,从我们的名字上就可以看出,字节跳动先有的英文名Bytedance,然后才定了中文名字节跳动。所以字节在建立之初就很重视做全球化的产品。目前字节在全球化方面,相对来说,都比较成功。比如TikTok,在全球上百个国家和地区都有用户,并且占据绝大多数国家的应用排行榜榜首。
2. Demo
接下来通过demo看一看我们怎么通过这种多语言的机器翻译能力来在产品上做一些有趣的东西。
第一个demo是Xiaomingbot,这是我们做的一个比较有趣的跨语言的多模态机器人,它综合了很多有趣的技术。
第二个demo相当于一个多语言的媒体解说,在一些体育比赛中,我们可以通过图像技术抓取现场的信息,比如谁进球了,谁做了什么动作,谁在带球等等,利用这些信息生成自动的媒体播报,由图像生成文本,最后写成一篇图文并茂的新闻稿。然后比较有趣的是,我们会有一个多媒体虚拟主播把新闻给播出来。我们的新闻主播会同时用多种语言进行播报,口型也会对上。
这个demo另一个比较有趣的地方是我们做了语言克隆,同一个人不管讲中文、英文、法语、德语,不管讲什么语言,他的音色是一致的,只是语言不一样。这里面也有一些zero-shot的transfer,这个也是比较有趣的。未来我们也会做一些抖音的机器人,可以自动生成短视频,然后自动播报一些有趣的新闻。
然后另外一个场景就是办公翻译,比如说日常的跨语言办公。现在很多公司其实都是跨国公司,日常工作中大家需要跨语言交流,使用跨语言的文档、email以及表格。在开会时也需要翻译。

飞书有以下办公翻译场景:
① 翻译IM消息
它支持按照目标语言自动翻译收到的消息,让跨语言沟通轻松无障碍。可以开启译文和双语对照模式,也支持对消息的手动翻译或划词翻译。同时还可以对翻译文进行打分,并提供更好的翻译译文。云文档支持原文译文对照,也可以翻译外文表格。
② 视频会议翻译
想体验外语会议上有同声传译的快感吗?快来使用飞书翻译吧。支持听音后按照设置的目标语言展示字幕,跨语言听讲和开会顺畅无阻。
③ 电子邮件翻译
跨语言email一键翻译,使用手动或自动翻译,快速get邮件信息。
以上是办公场景的翻译。在办公时,我们比较鼓励大家讲母语,并不强求通过英语来交流。大家讲自己舒服的语言,中国人讲中文,法国人讲法语,最后通过机器翻译打破障碍,让大家跨语言进行交流。
另外一个比较偏客户端的一个应用场景就是TikTok。TikTok上有各种语言的视频,它可以是中文、英文、德语或法语,如果要在日本播放,就需要做日语字幕。

另外我们也做视频直播。前一段时间刚刚做了一个村上隆的直播,他是海外的一个艺术家。抖音未来会越来越多地邀请其他国家的一些名人来国内做直播,或者邀请他们做跨国直播,这个过程中可能需要通过机器翻译来解决这种语言障碍。
上一次直播还是比较成功的,当时的全球关注用户在800万左右,现场直播峰值大概有百万听众。这是一个比较大的场景,一个人做跨国直播,可以有上百万人的关注,这是技术带来的一个很大的变化。
上面这部分主要是对字节跳动翻译在或者说对火山翻译在字节跳动内的一些应用场景做了一些介绍,概括起来说,主要包括:
泛娱乐翻译:包括给TikTok和其他面向用户的客户做内容翻译,让用户享受跨语言的内容。
工具侧:以办公翻译为例,通过机器翻译技术能够让用户跨语言办公,比如Lark翻译、doc翻译、email翻译和视频翻译,当然这中间可能会面临不同的技术挑战。
接下来首先为大家介绍下机器翻译,然后分享下我们做的一些比较有趣的技术。
3. Mechine Translation
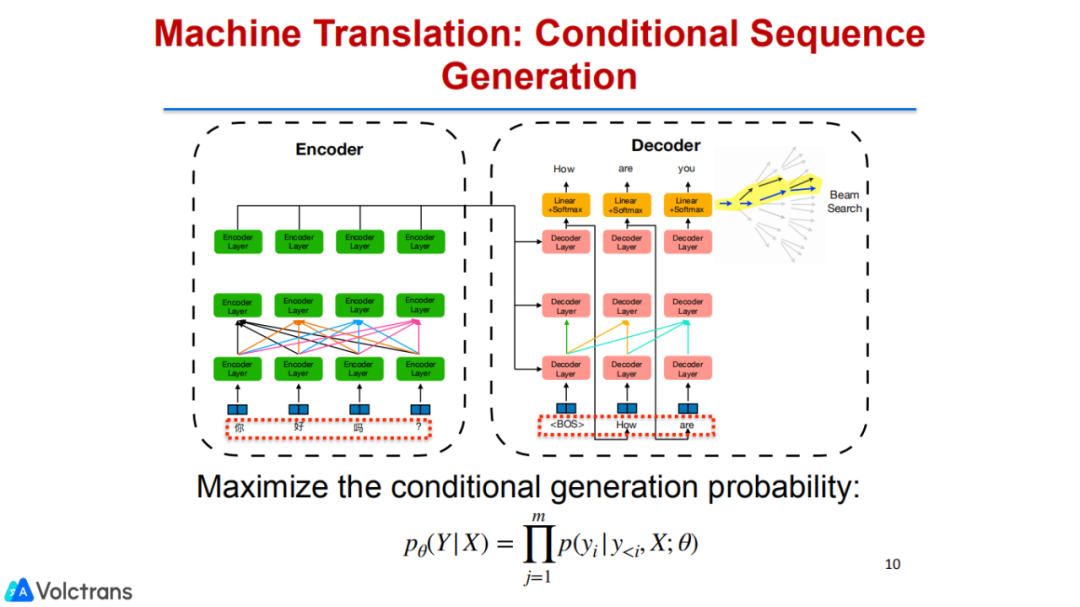
机器翻译本质上是一个基于condition的sequence generation任务,它是一个条件概率生成模型。目前比较火的GPT就是一个language model,它是一个不基于条件的语言模型,是一种无条件限制的生成式模型。所以,机器翻译模型就是基于源语言生成目标语言的条件概率模型。
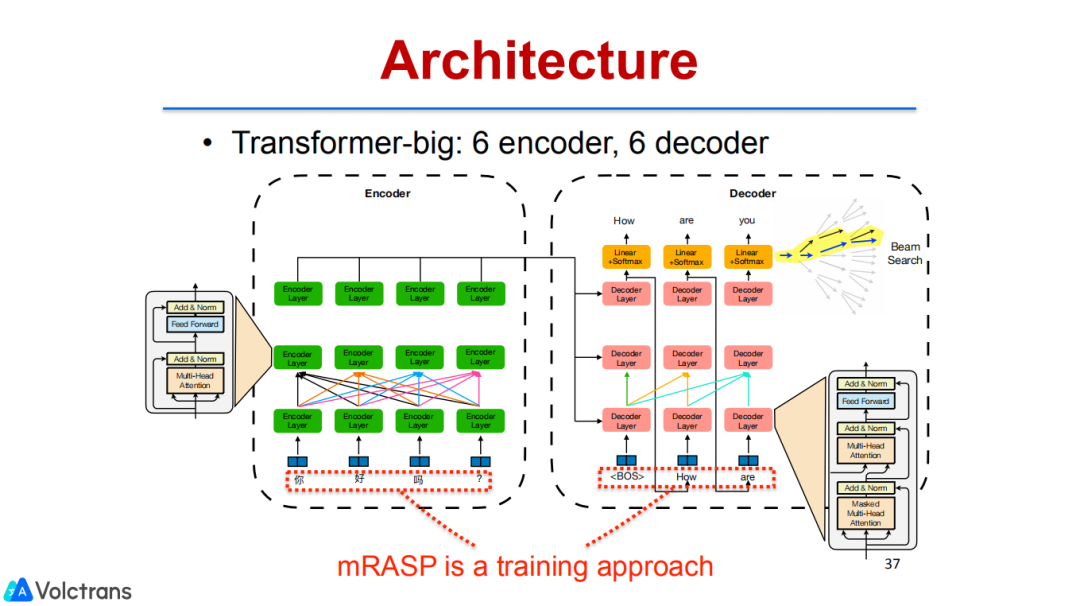
目前业界比较通用的transformer,源端做self attention,目标端也通过self attention做生成,然后两个模块之间通过cross attention做align的关系,这个细节就不展开了。
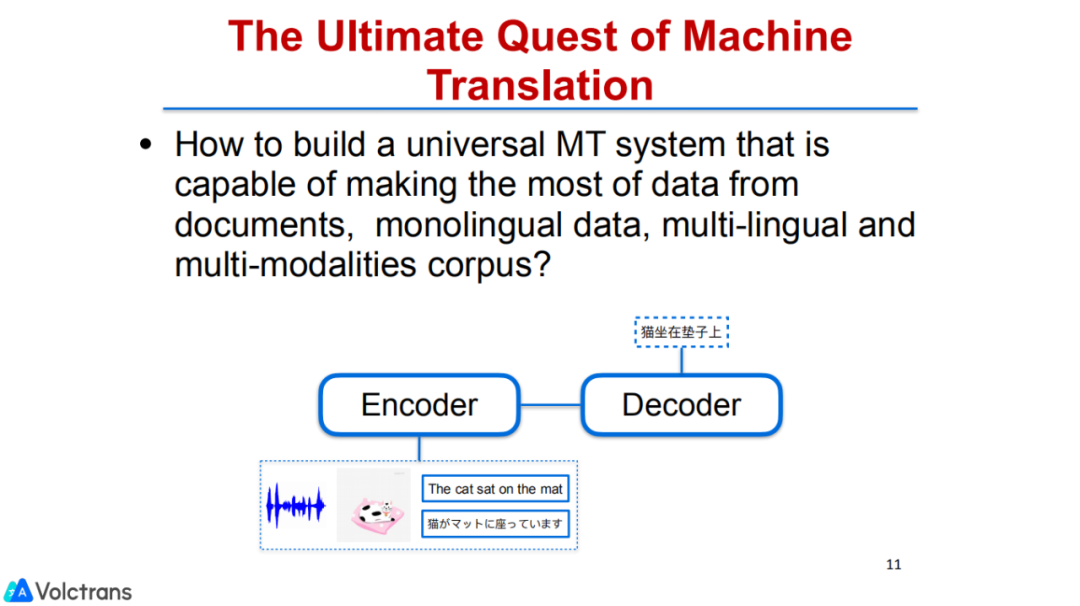
目前的翻译还都是基于文本的,我们的目标是做一个通用的MT system,源端做一个跨模态的编码,可以非常好的利用各种类型的数据,包括语音数据、单语数据、文档数据、多语言数据和多模态的数据,对这些数据进行理解,用目标端生成文字。

在这个过程中,我们非常想利用大量的数据,因为在绝大多数的MT实验中,大家用到的数据可能都比较有限,可能都是千万级别的平行数据,因为机器翻译对数据的要求是比较严格的。所以我们思考能不能通过半监督或者pre-training的方式构建一种模型,能够不只利用sentence level的数据,还可以利用包括document在内的一切数据,把所有可用的数据都利用上。
我们也在考虑通过多模态的方式获得信息,包括语音信号或者visual信号。人类理解世界是通过对语音、视频等信号进行感知,并且我们也不是生活在一个纯文本的世界里。所以首先和大家分享下我们在pre-training的一些工作,因为做知识迁移,最容易想到的思路就是预训练,由于双语资源是受限的,如何利用几乎无穷的多语言信息,或者其他的一些multilingual的信息,都是值得考虑的点。
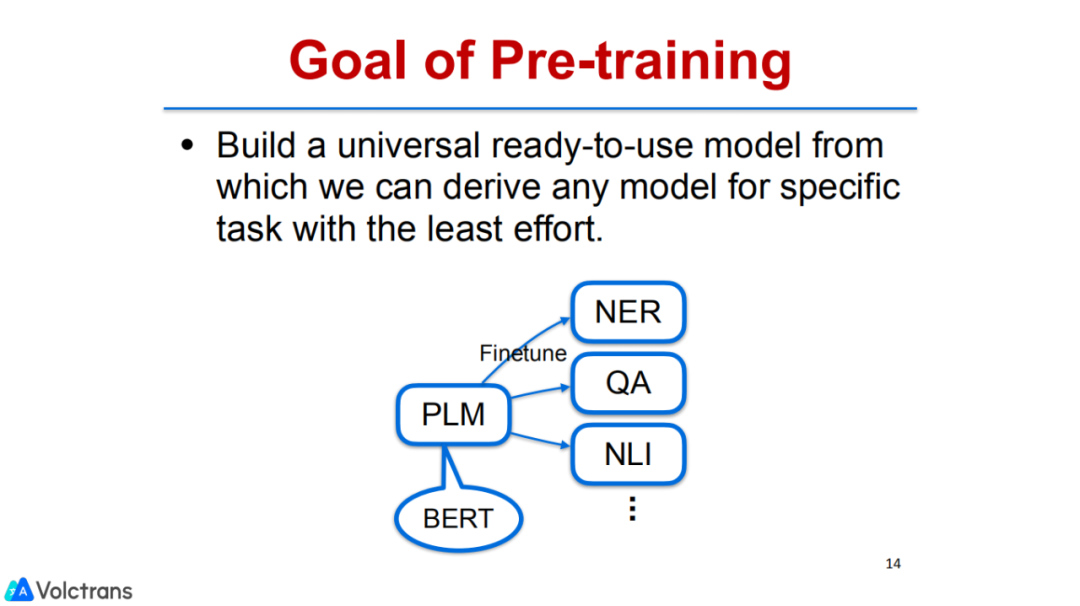
pre training简单说就是我们先预训练一个model,通过其他的task做ready to use 的model。然后我们可以在一个具体的task上对model做finetuning。
1. 最大程度地利用BERT提升NMT性能
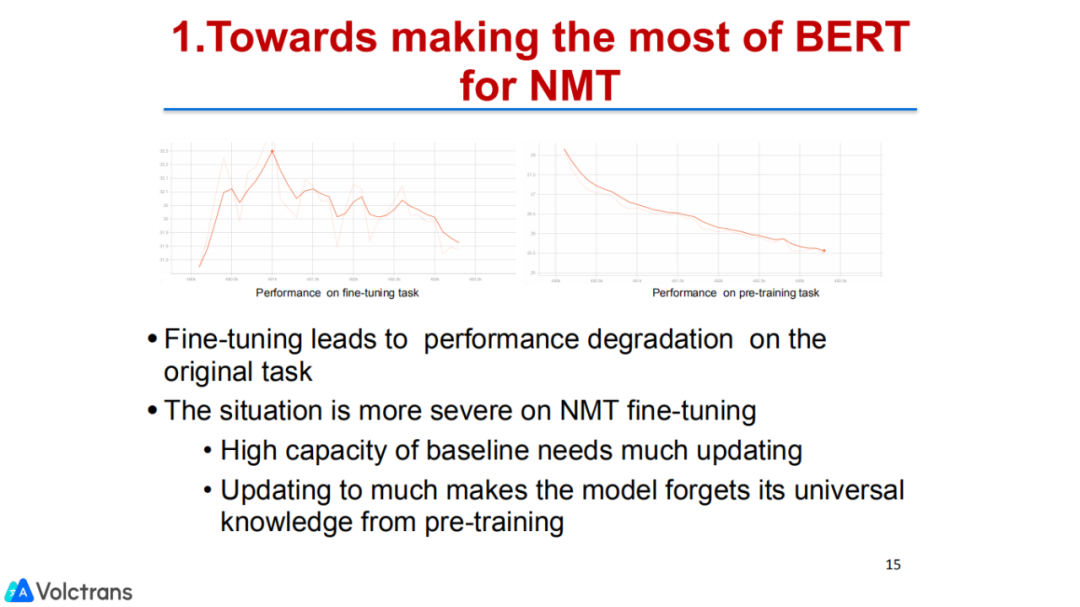
首先,介绍bert pretrain的相关工作。这个工作思路比较简单,我们主要是解决pre train finetuning过程中存在一个灾难性遗忘问题。简单说,pre train是一个task,finetuning是另外一个task,很多任务在做pre train finetuning时,会forget掉pre train的一些信息,随着下游任务的越来越大,遗忘的会越来越严重。因此,如何保留上游任务的information是非常重要的。我们提出了一些简单的方法来保留bert的信息。
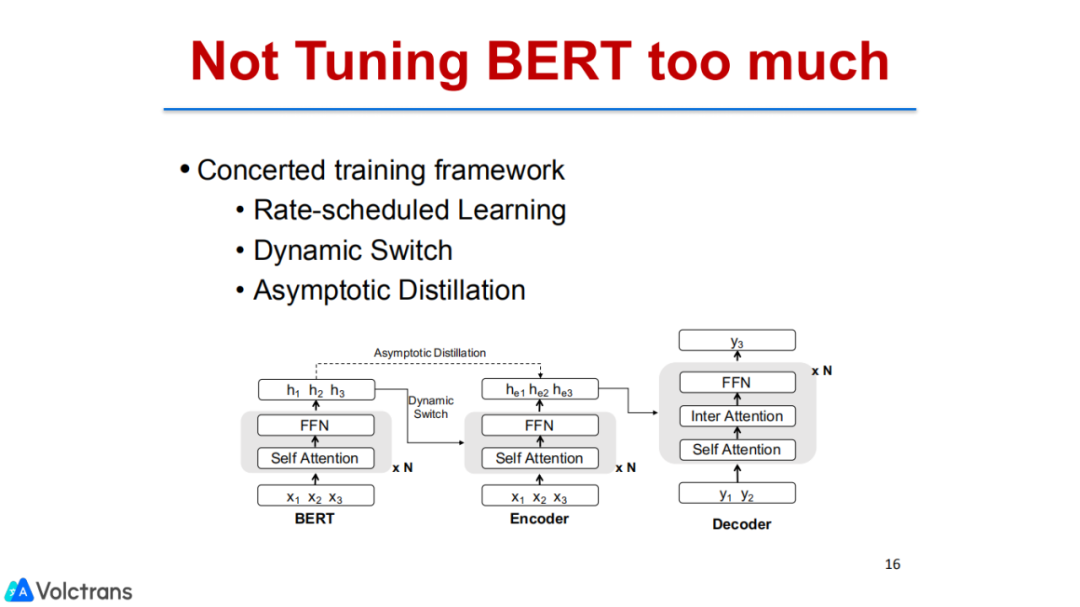
简单来说,就是我们在下游updating bert时,不要updating太多,尽可能的控制bert update的规模。因此,我们提出了三种不同的思路:
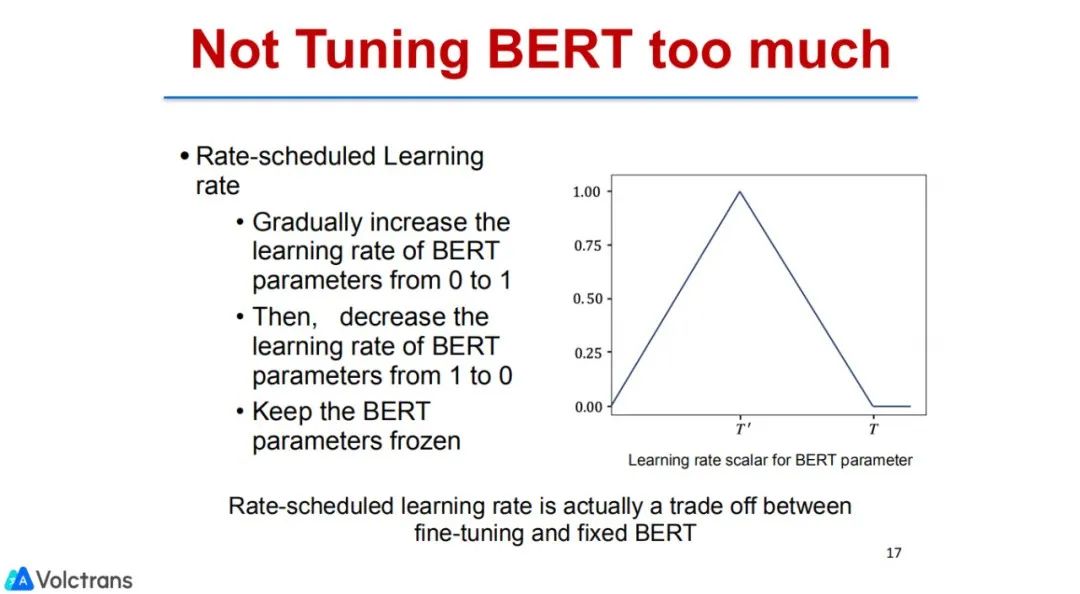
控制learning rate:用bert初始化NMT时,控制bert的更新频率。先更新NMT的参数,固定bert的参数。当NMT的参数已经更新的差不多时,开始把bert和NMT放在一起做tuning。当模型更新的完毕,我们固定bert的参数,只更新NMT部分的参数,也就是只更新decoder的参数,固定encoder bert的参数。通过这种方式,我们尽可能多地保留了bert的信息。这种方法存在的问题:需要通过具体的设置,比如什么时间开始更新bert,什么时间结束更新bert。这是一个比较固定、简单的方法,我们取得了一些效果。
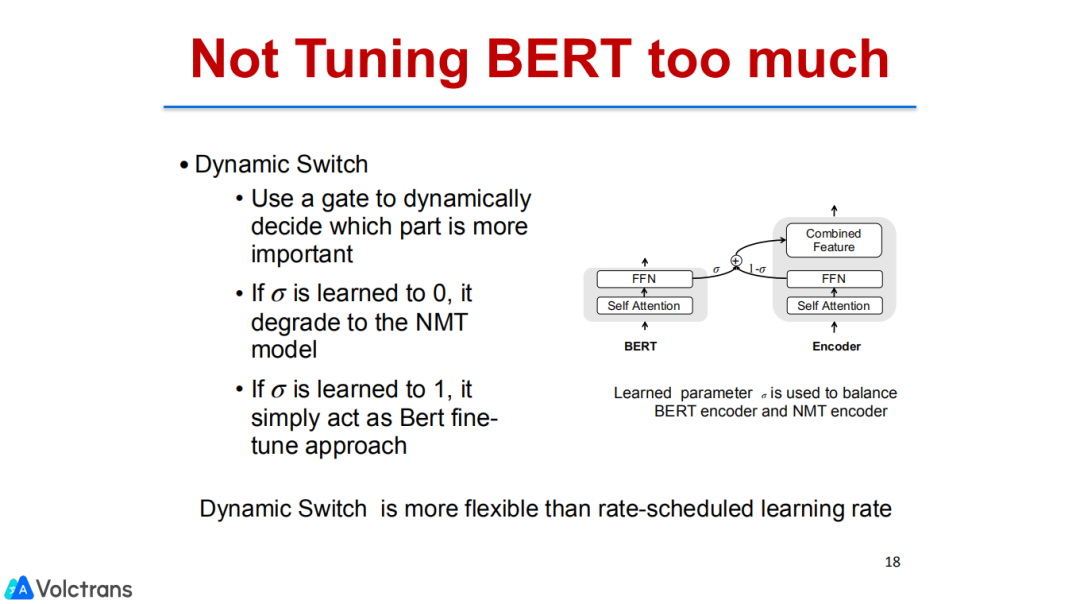
Dynamic Switch:在上述基础上我们又用一个gate来控制这种更新,即dynamic switch,通过gate来控制bert和NMT encoder对翻译的贡献比例,然后用它来控制更新,尽可能多的保留bert的信息。
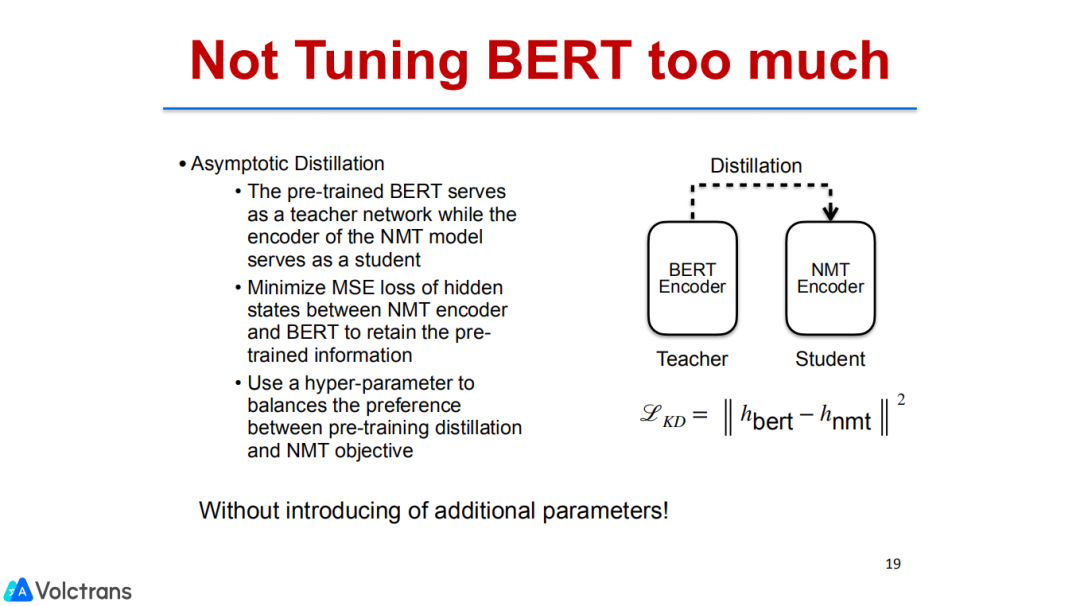
Asymptotic Distillation:其实也是做life long learning或者continue learning常见的一个方法,即KD。我们在整个更新的过程中依然保留encoder,让它去KD bert的knowledge,在做翻译loss的同时依然要去做bert的loss,两个loss同时进行,也会尽可能多地保留pre train的knowledge。
最后,我们在翻译结果上,有了非常显著的提升,比NMT model的baseline有差不多3%的提升。
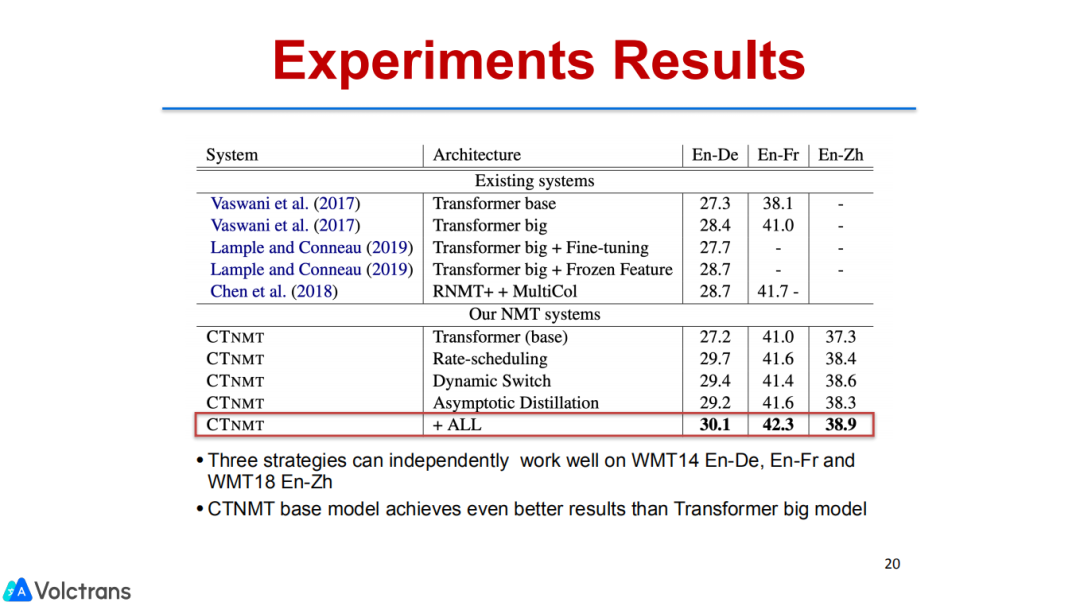
这三种策略的每一种都可以独立工作,把它们joint在一起,也能work。另外我们也尝试了pre trained encoder或者decoder,也引入了GPT或者引入bert,分别做encoder或者decoder pre train,整体发现目前encoder还是更work一些。
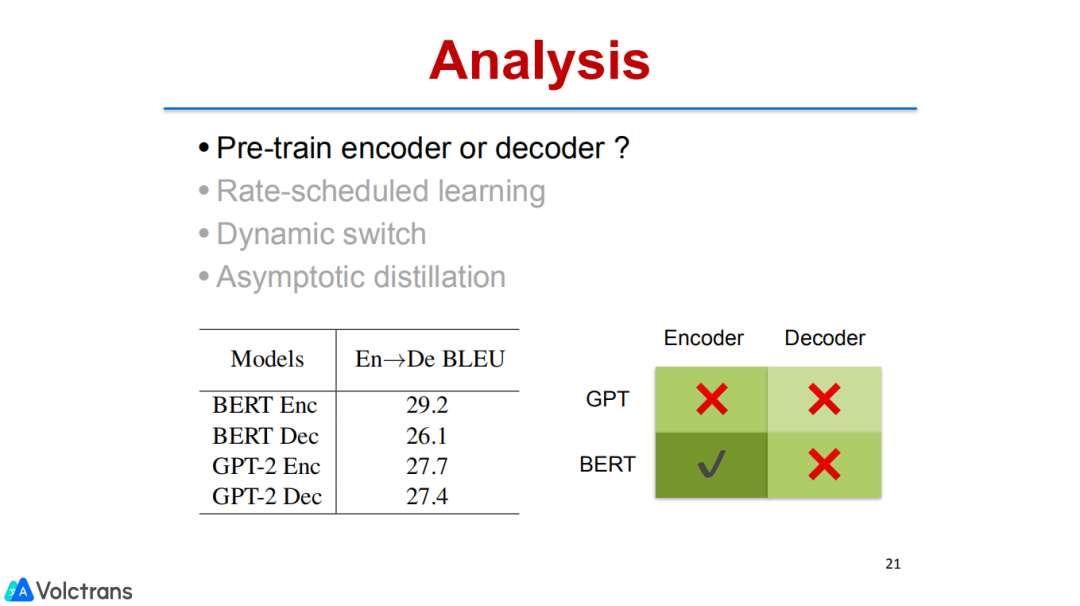
GPT decoder也有效果,但是效果不是特别明显,与baseline相比,没有显著的提高。这块值得进一步的探索。
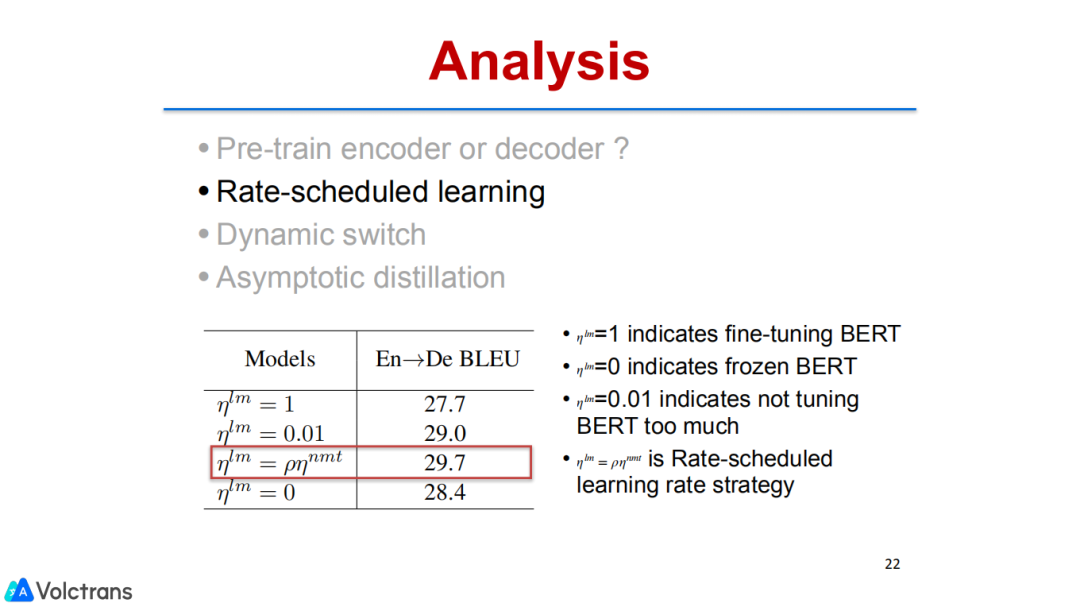

另外我们也做了一些AB test,测试什么时间开始进行 bert indicates或者什么时间进行bert funtuning,baseline是我们直接做fine tuning或者frozen的两种形式。实验证明我们提的策略比这两种简单的形式效果都要好。
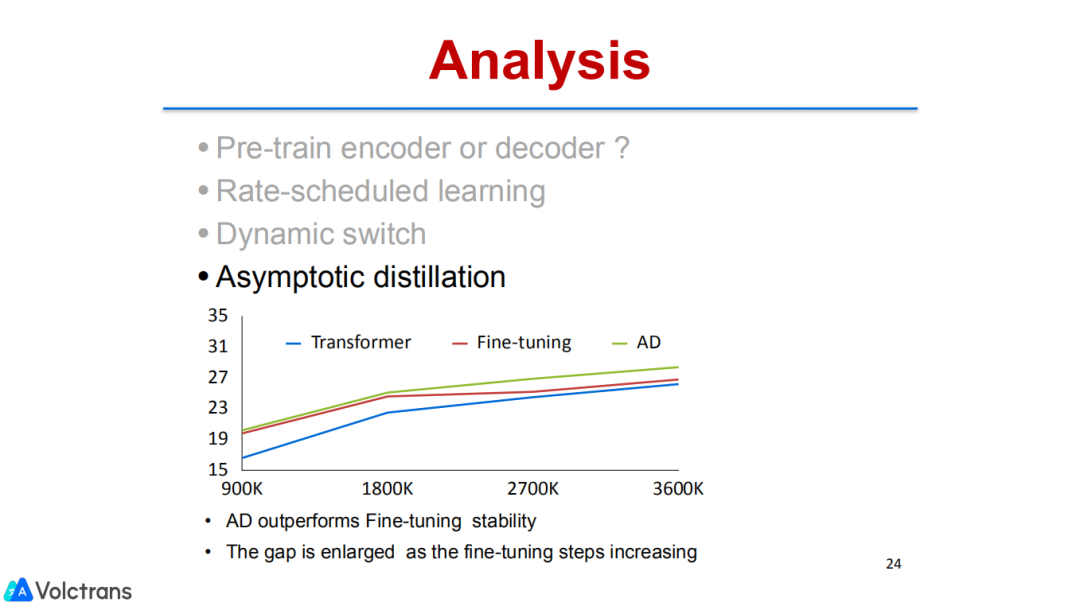
比较值得印证的一点,我们发现数据量和finetuning是有关系的,当数据量比较少时,简单的pre train finetuning效果会很好,但是随着数据量的增大,pre train finetuning比baseline的提升gap就会越来越小。当引入了我们的方法来解决forget问题,或者解决灾难性遗忘之后,发现gap变大提升会更显著。

这里有两个启发值得大家探索:
pre train finetuning模式对于机器翻译来说是非常有潜力的。我们简单地用bert做encoder,就可以在MT的benchmark上取得3个blue的提升,是一个非常显著的效果。
我们发现decoder pre train目前还没达到一个理想的状态,这是因为结构不一致。GPT是一个语言模型,但翻译是一个conditional language generation模型,所以这两个目标不一致会导致decoder用GPT pre train还没有那么有效,这也是一个非常有潜力、值得探索的方向。
2. Prune-tune:找出适合特定神经网络机器翻译任务的稀疏网络结构
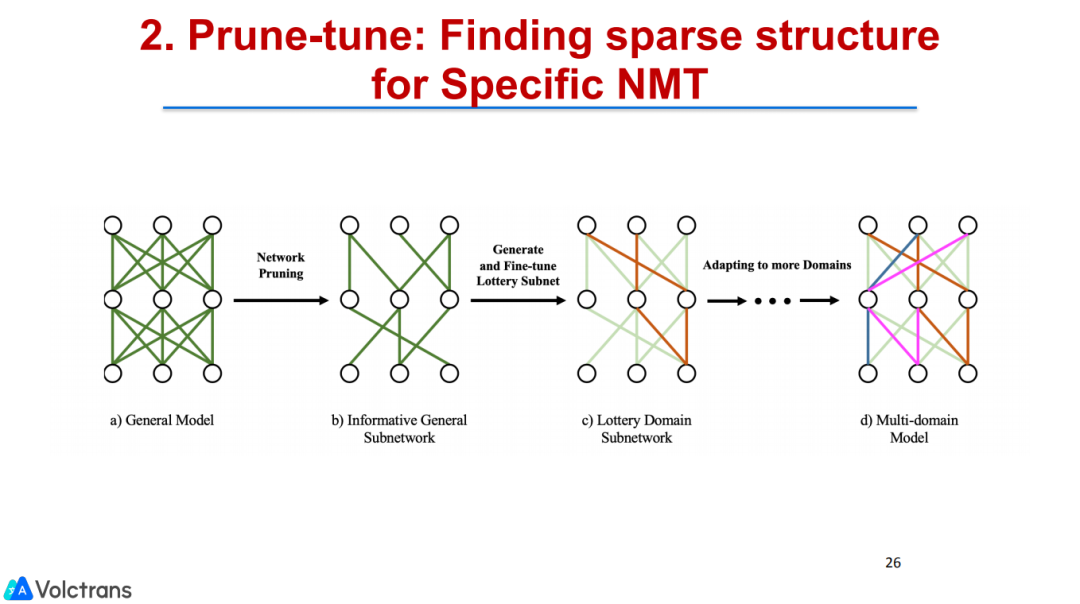
为了解决同样的问题,在这基础上我们做了一个prune-tune的工作来尽可能多的保留上游任务的信息。我们的上一个工作的思路是通过learning rate控制pre train model,不要更新太多,然后主要在下游fine tuning时,更新下游的task、parameter。而在这里我们是想找网络的主网络,因为有一个彩票理论:在一个网络中存在一个subnetwork可以cover网络绝大部分的信息。我们的工作就是找到 sparse subnetwork,它是模型中比较重要的。比如说bert,虽然bert可能有100万参数,其中也许只有40万参数是重要的,就这部分参数,我们把它找到,不做更新。通过update或者finetuning不重要的参数,让它既能保留上游任务的能力,也能在下游任务上去做tuning,而且这个过程可以sequential的去做,我们不断的去找这种subnetwork,然后去finetuning。
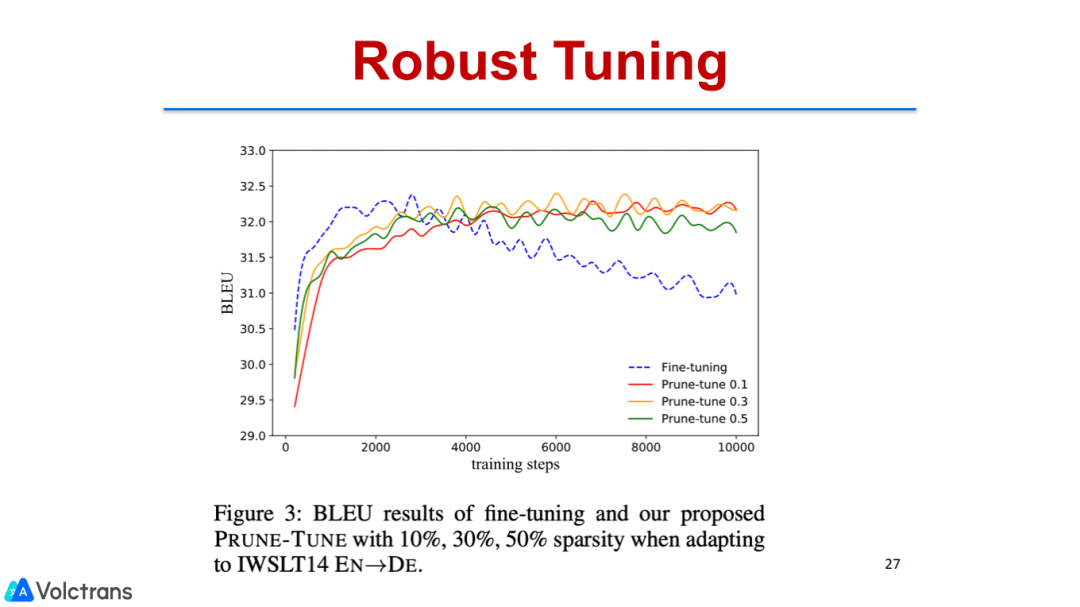
通过实验,证明了这种方法是非常有效的,structure learning的表现比fine-tuning更稳定,并且是鲁棒的,无论参数怎么设置,收敛性都非常好。
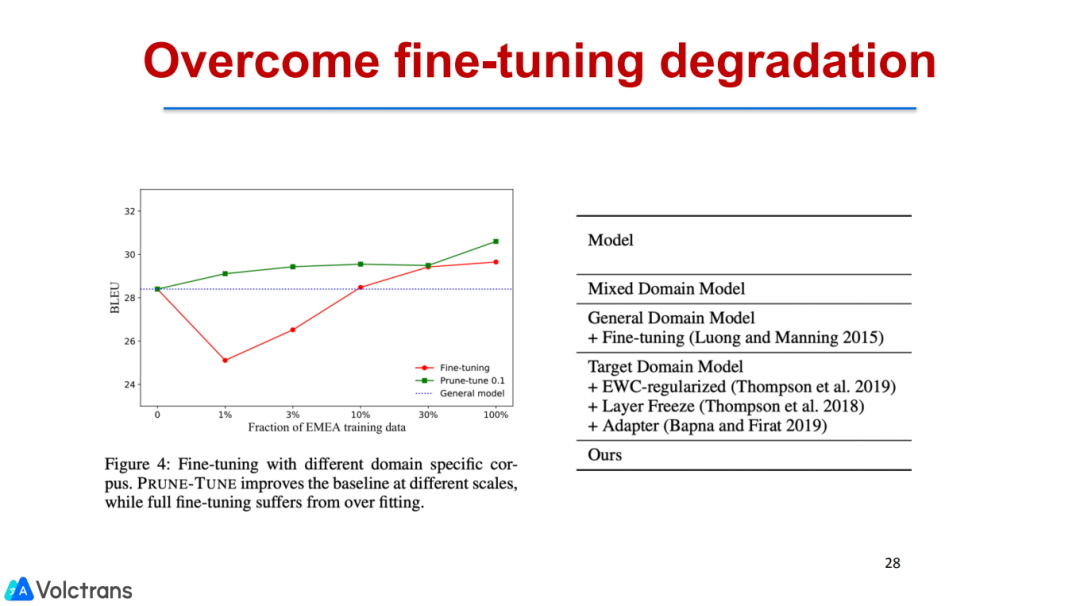
另外,在不同数据规模下,sparse structure fine-tuning都有比较显著的提升。
这两个工作都是旨在解决pre training和fine-tuning的task目标不一致时,我们以什么样的策略做fine-tuning。这两个工作更侧重于如何做fine-tuning来适应上游任务。
3. 神经网络机器翻译的多语言预训练

同样的一个思路,我们思考如何做pretraining,因为之前的pretrain model可能大家是用bert和GPT做,下游任务做fine-tuning,我们也在思考如何做一个针对机器翻译的multilingual的pretrain model,可以在任何机器翻译的方向上做fine-tuning,相当于机器翻译领域的bert,让整个过程变得更简单高效。

我们的出发点是希望找到多语言之间universal 的 representation。不同的语言,如英、法、意、德、西,都可以被表示在同一个空间里,不同的句子虽然有不同的字符,但它们的hidden state都是一样的。
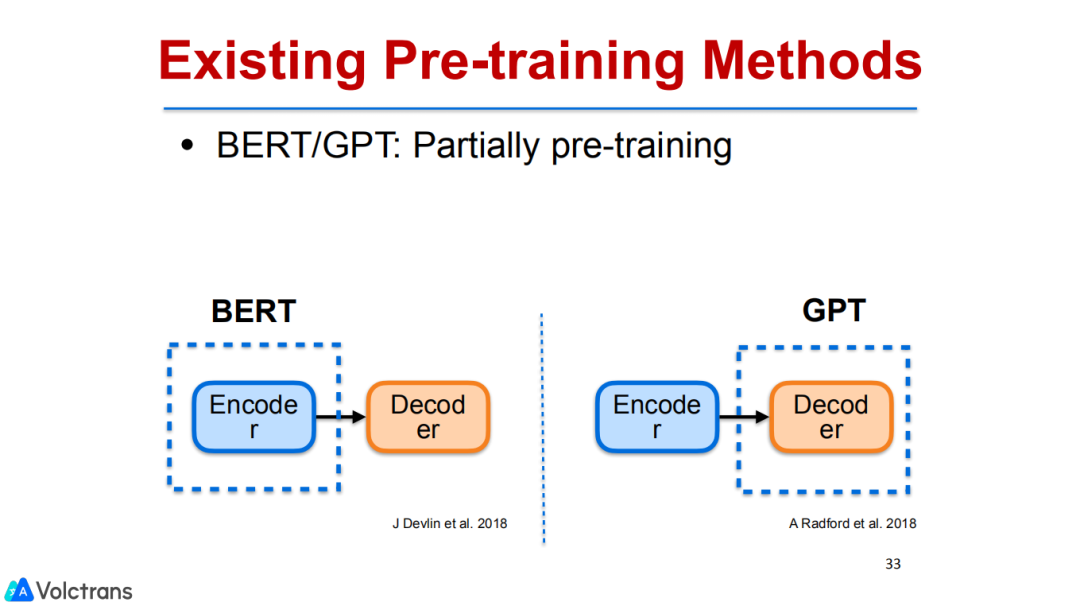
当然这个工作和bert的出发点是不一样的。bert更大程度上是encoder pretrain;GPT更大程度上是decoder pretrain,二者都不是针对翻译的。
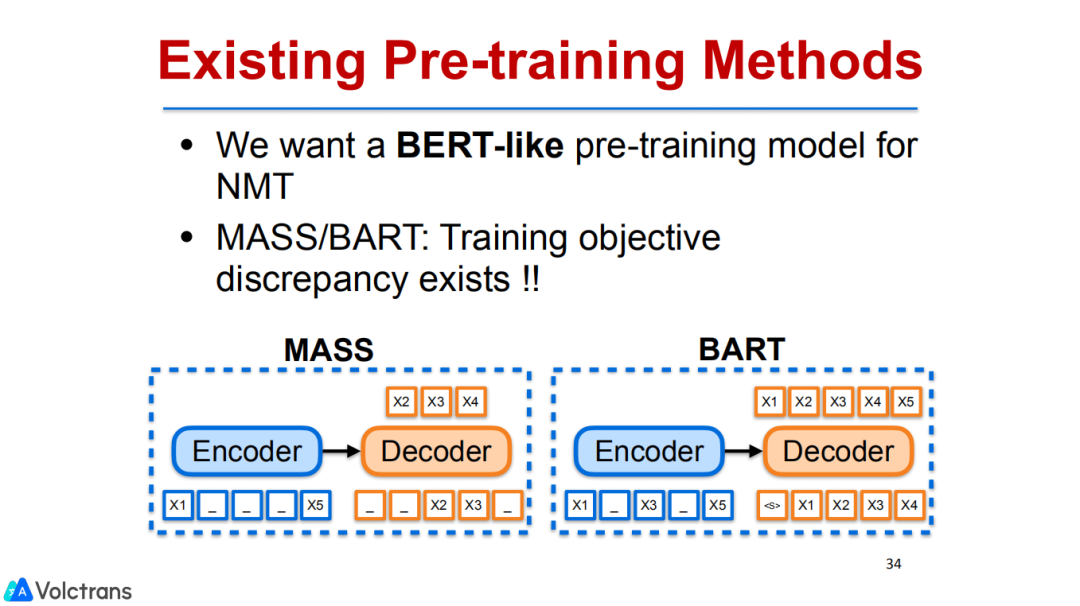
像之前的mass或者bert,都是同一种语言的autoencoder,也不是针对翻译的,它是英语到英语或者法语到法语的sequence to sequence pretrain,并不是英到法这样的pretrain。
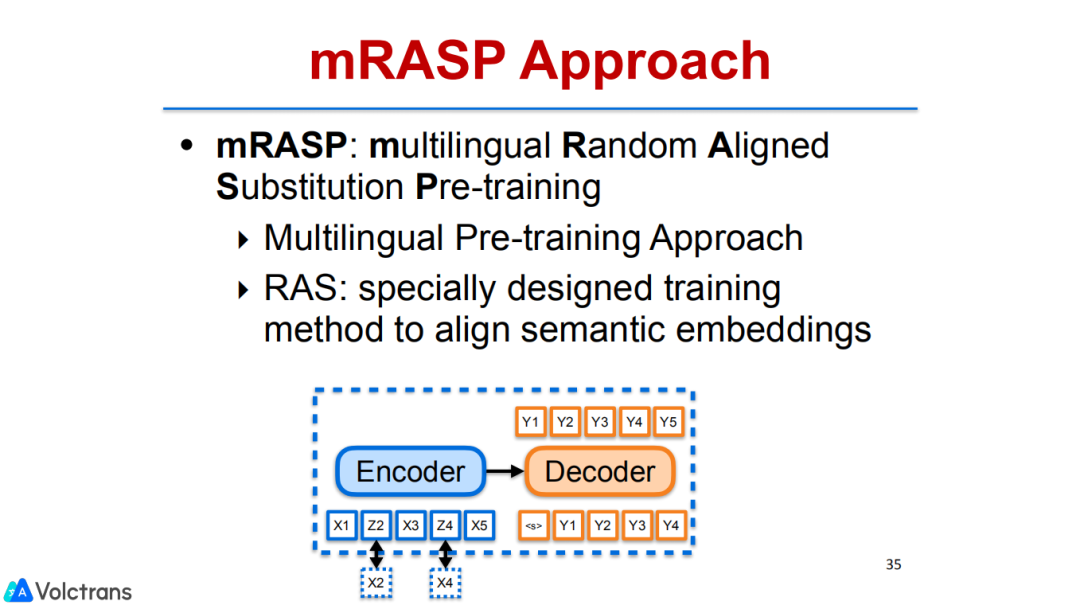
我们的工作和这些工作不一样,我们想做的是multilingual pretrain,encoder是一种语言,decoder是另外一种语言,把很多种语种放在一起,做一个multi learner。
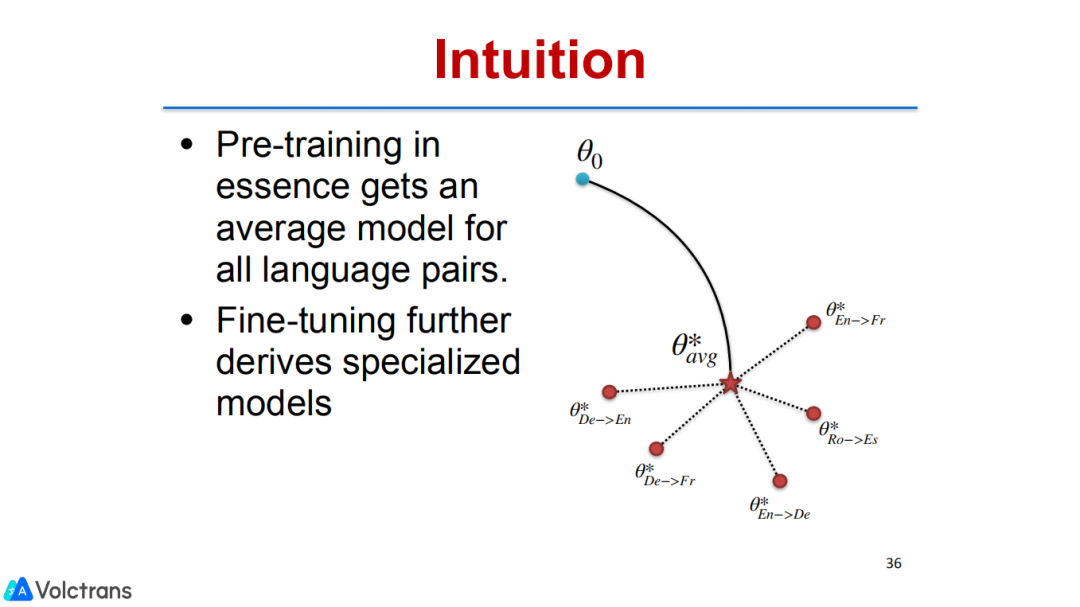
学到各种语言的average,再去做下游的fine-tuning。
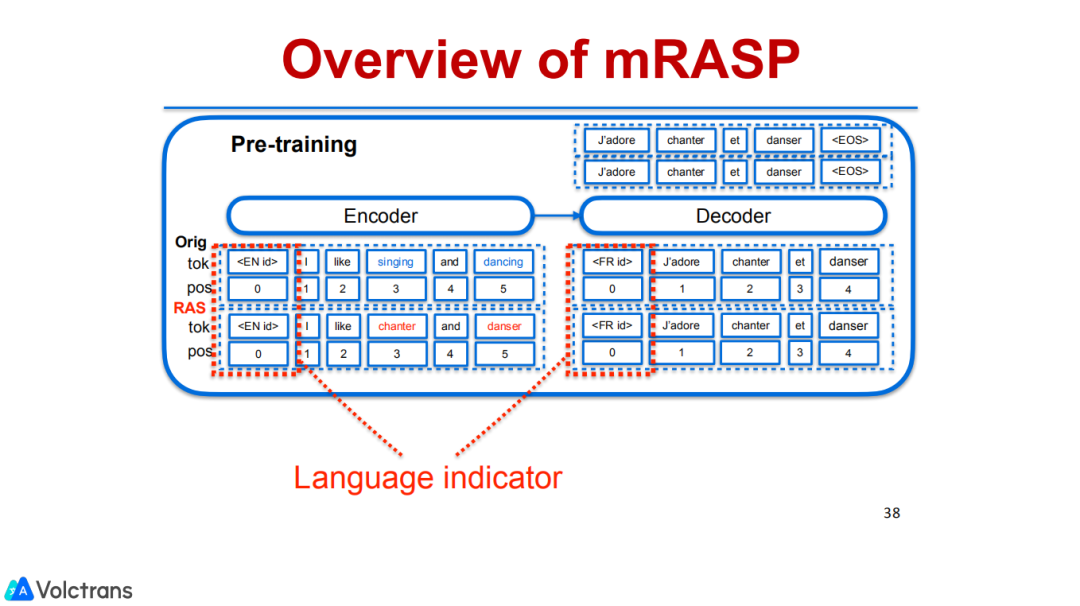
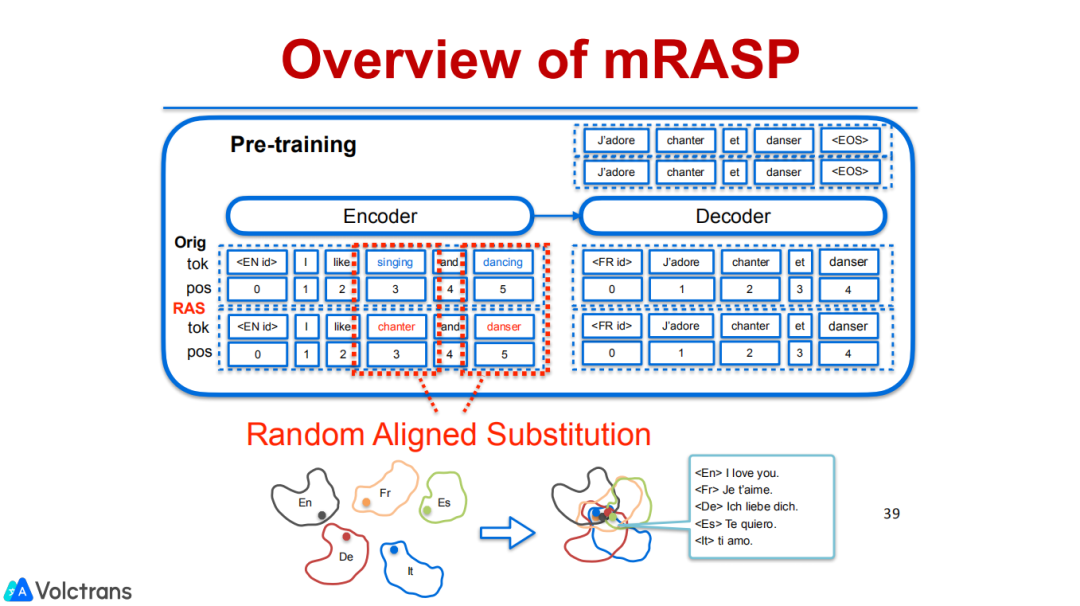
更具体的,在这个过程中我们也提出了随机替换策略,对源端的每一个句子中的词都进行一些替换。


比如说在英语句子I like singing中,把singing这个词替换成法语的词,因为singing和chanter这两个词上下文一致,虽然是跨语言的,它也会得到一个同样的表示。
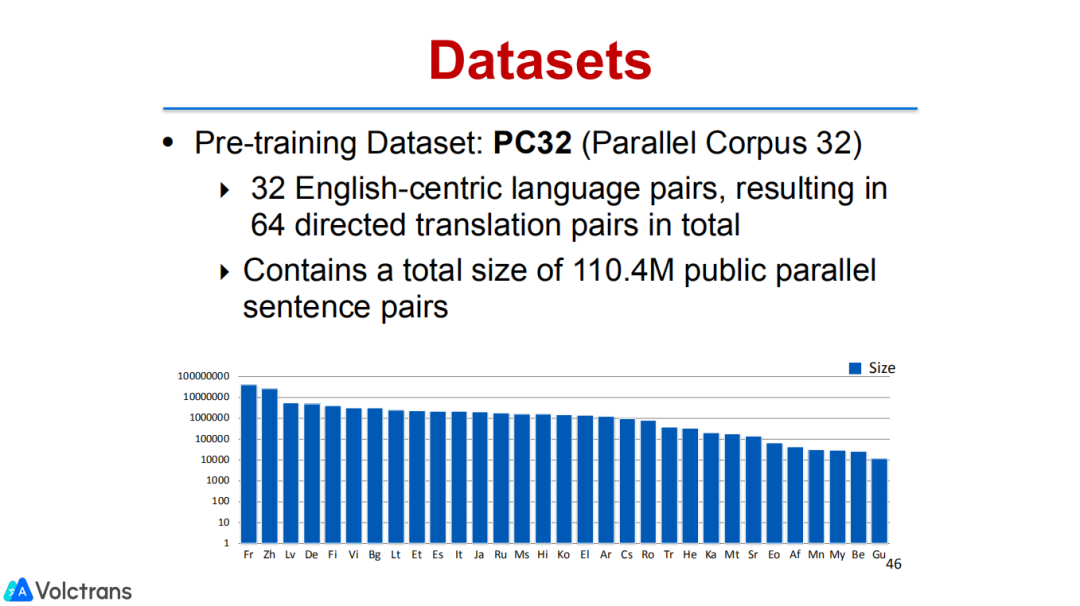

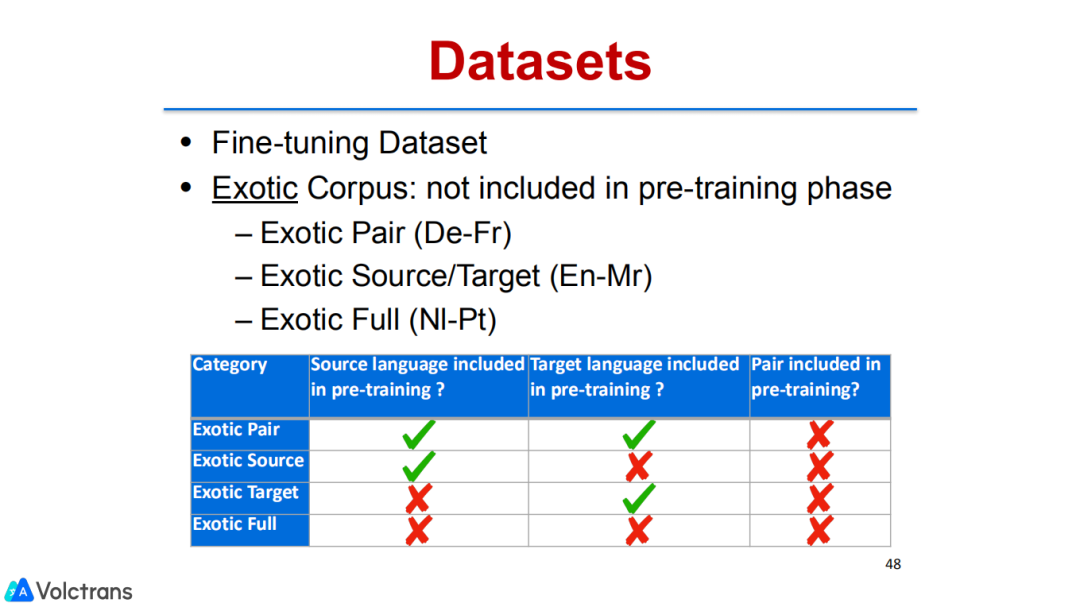
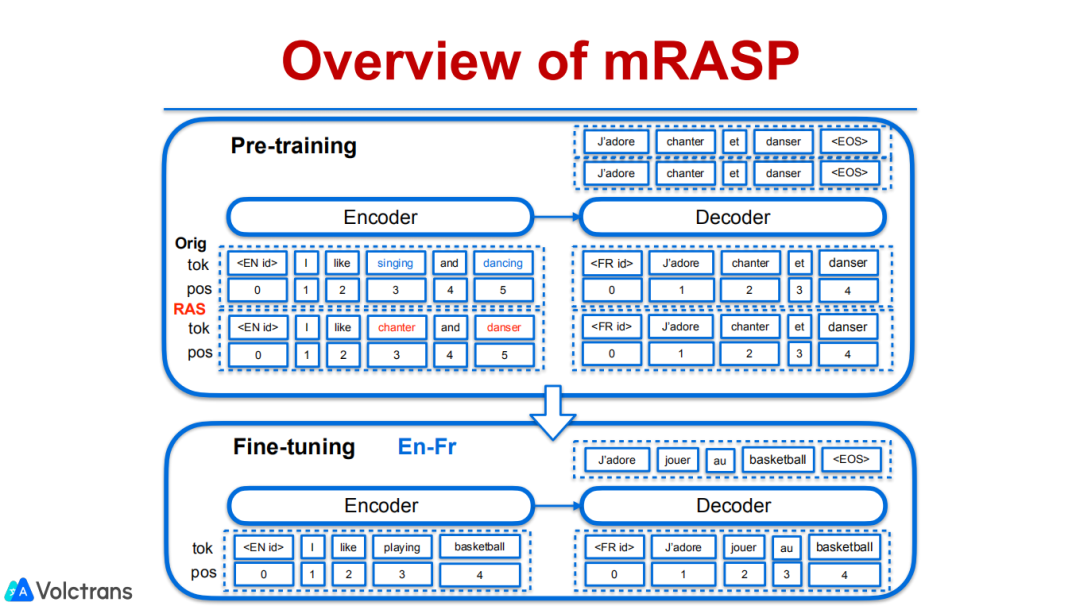
通过实验,我们很好的验证了这项工作,我们在32个语言对的平行数据上做了pre train,在48个下游任务做fine-tuning,也包括了一些从来没有见过的语言,比如从NI到PT这种语言对,pre train训练数据中完全没有这两种语言的数据,也是比较难的。

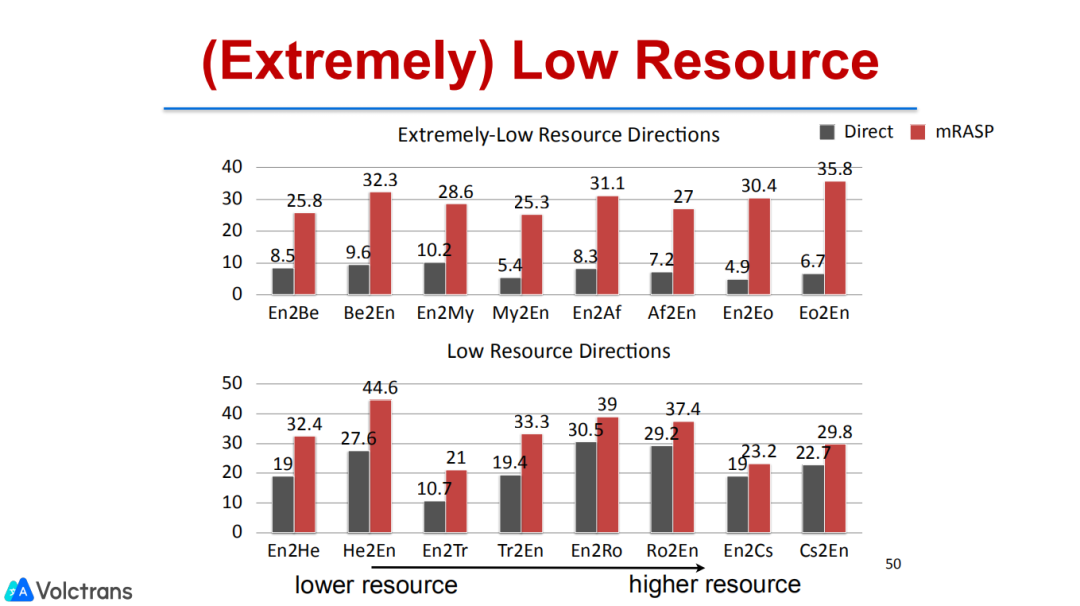
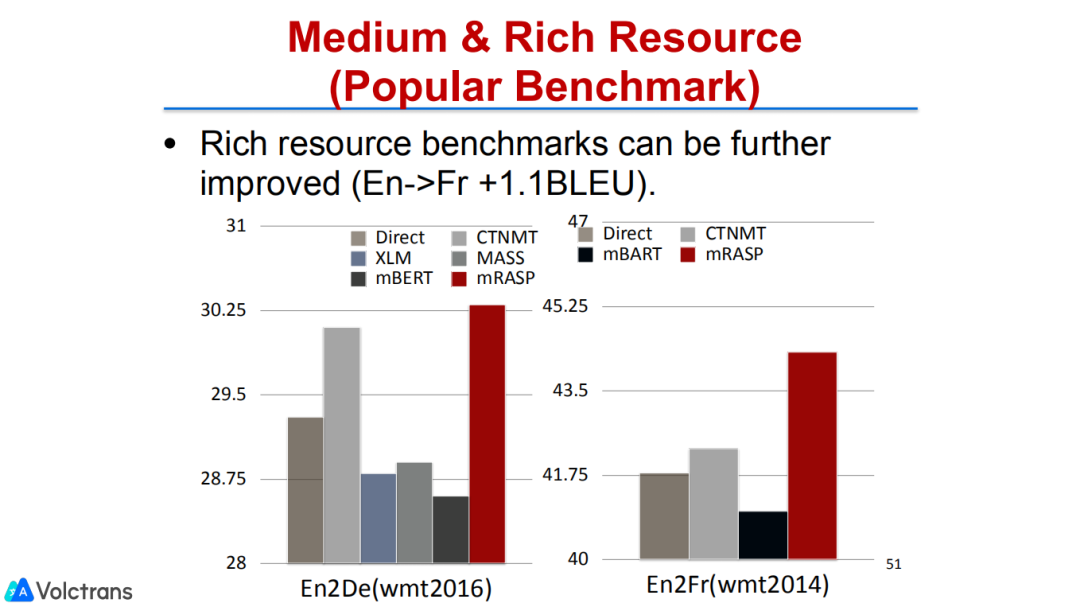

我们的model在rich resource的英法语言对的benchmark上,也能取得1.1个BLEU的显著提升,达到了一个比较SOTA的结果。另外,在从来没有见过的语言对上也能有一个非常显著的提升,特别是在Nl-PT这种只有12000句训练数据、平行数据非常少的情况下也能够取得10个BLEU的显著提升。
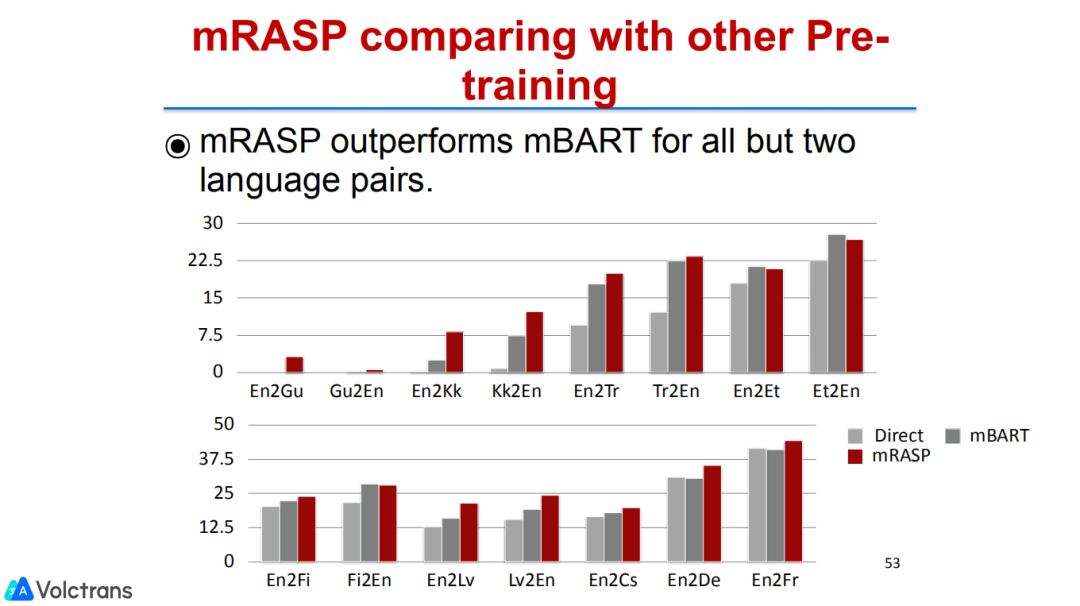
同时我们也对比了一些其他的工作,比如mBART,它是个多语言的sequence to sequence pre train model,当然它也不是针对翻译的pre train model。我们也在绝大多数的情况下都比它有显著的提升。
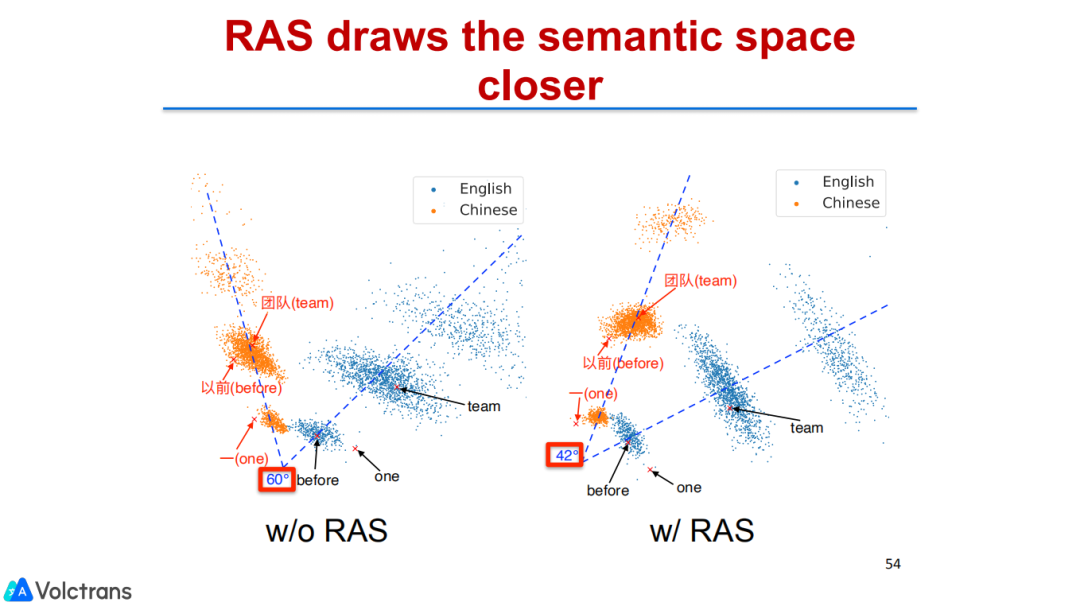

另外我们也做了一些分析,发现它确实拉近了多语言之间的相似性。通过RAS替换,语言之间的cosine similarity以及表示更接近了。
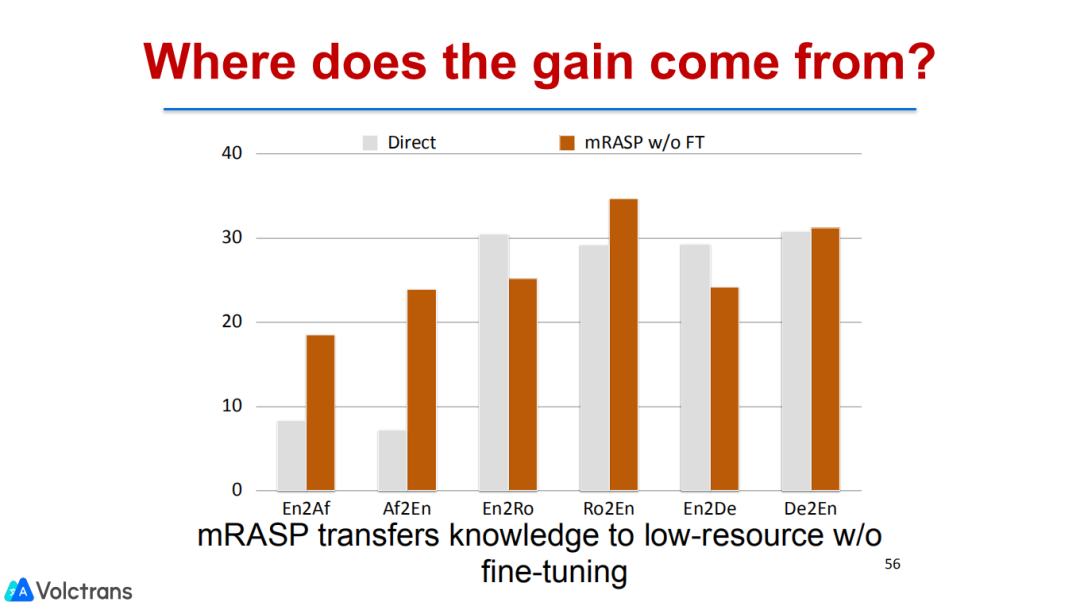
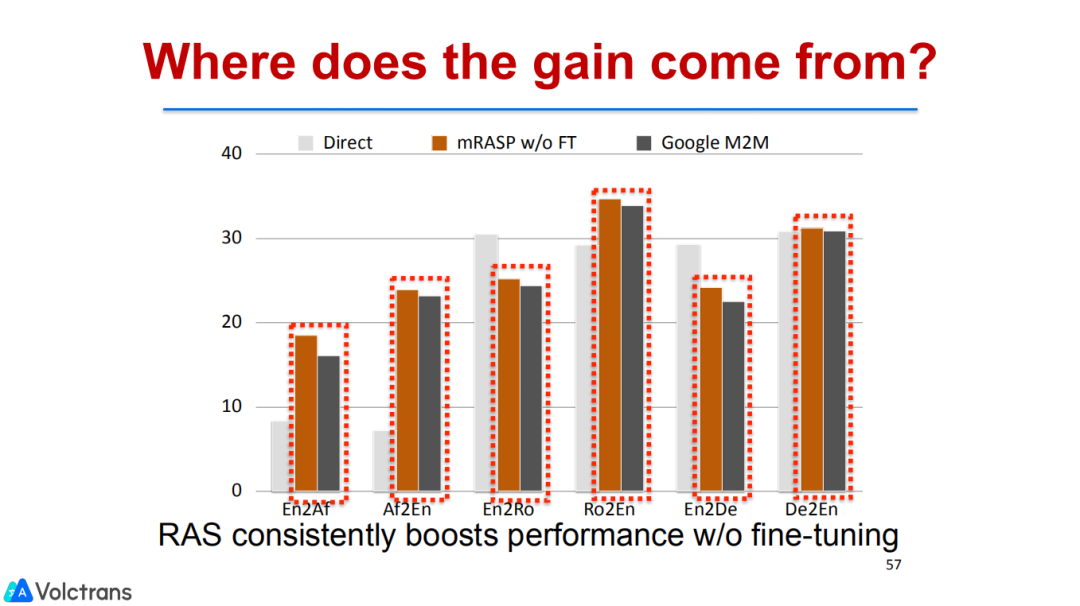
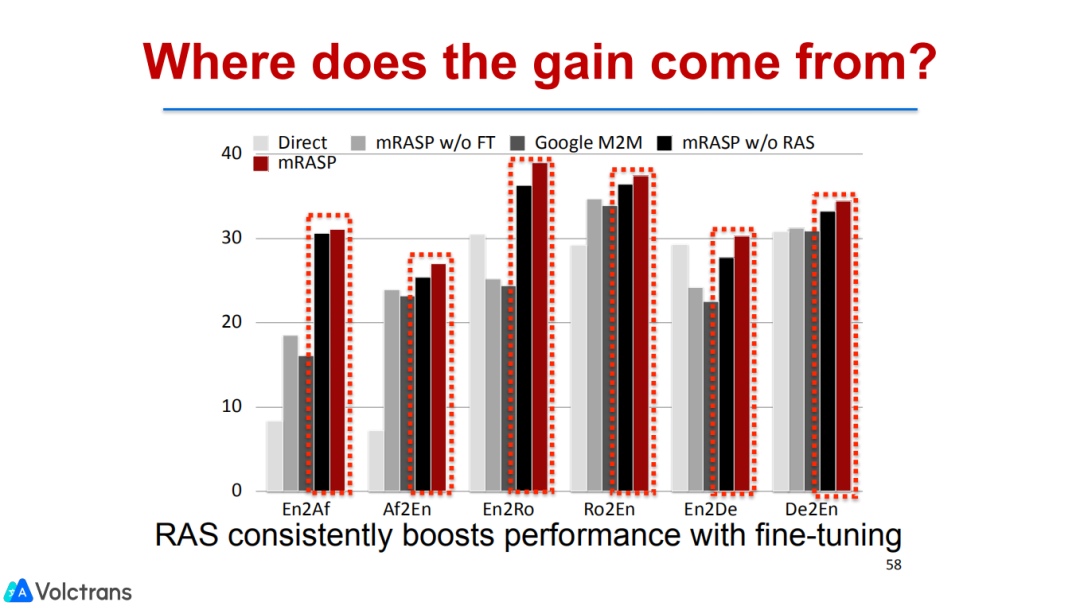
这里一件比较有启发的事情是:我们有可能只训练一个机器翻译的pretrain model,就可以针对任何语言对做fine-tuning并获得提升。

另外,我们还探索了跨语言表示。如果能够拉近跨语言表示距离,对于下游的fine-tuning任务是非常有帮助的。

mRASP的代码和模型都已开源。
4. 重新审视文档机器翻译

我们也用类似的思路做了document machine translation,引入了非常多的文档数据。

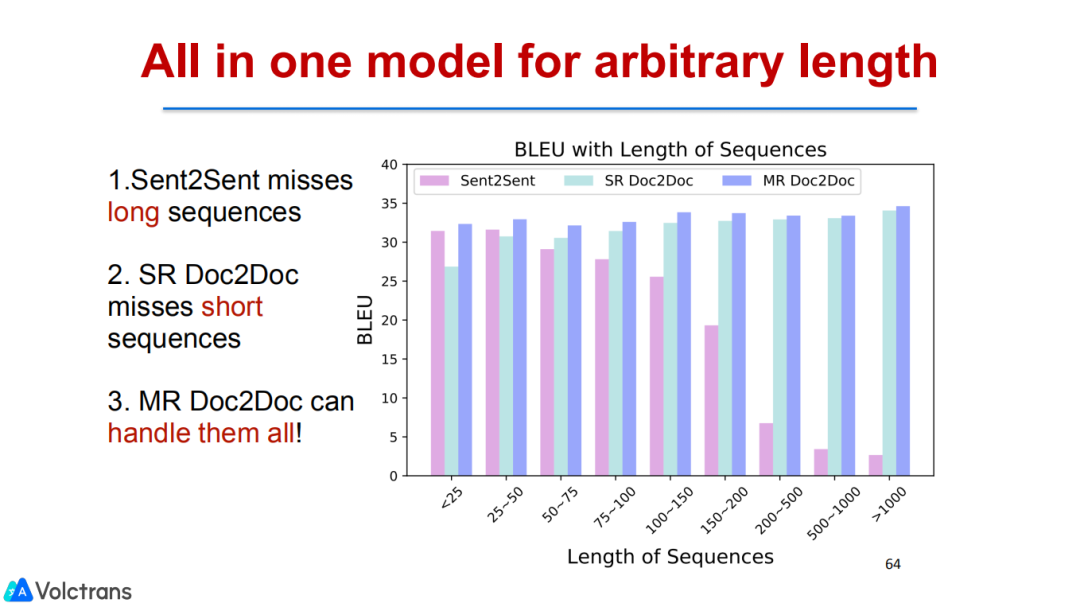
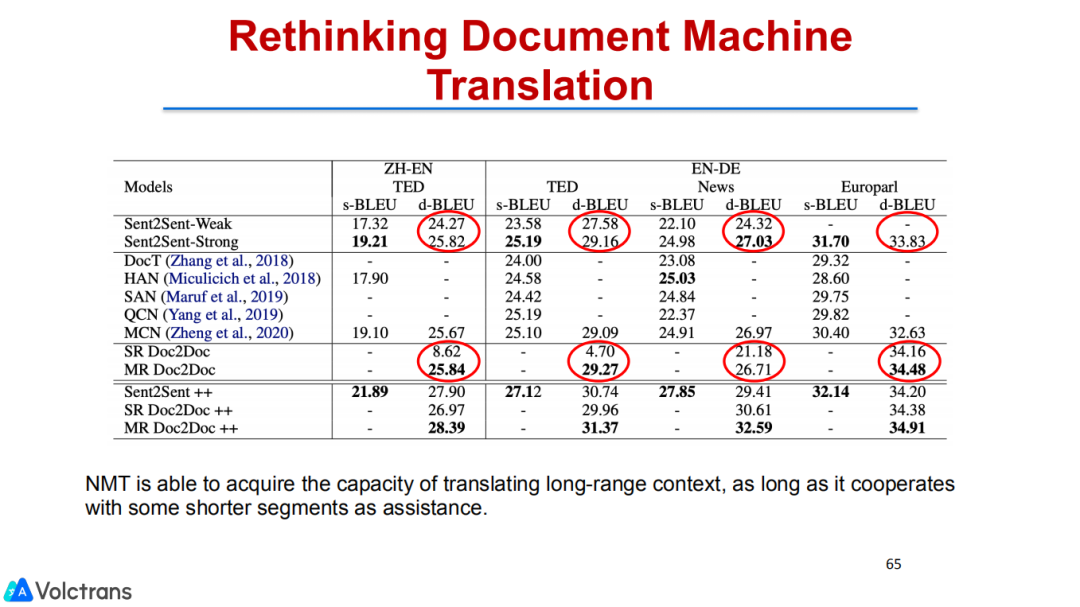

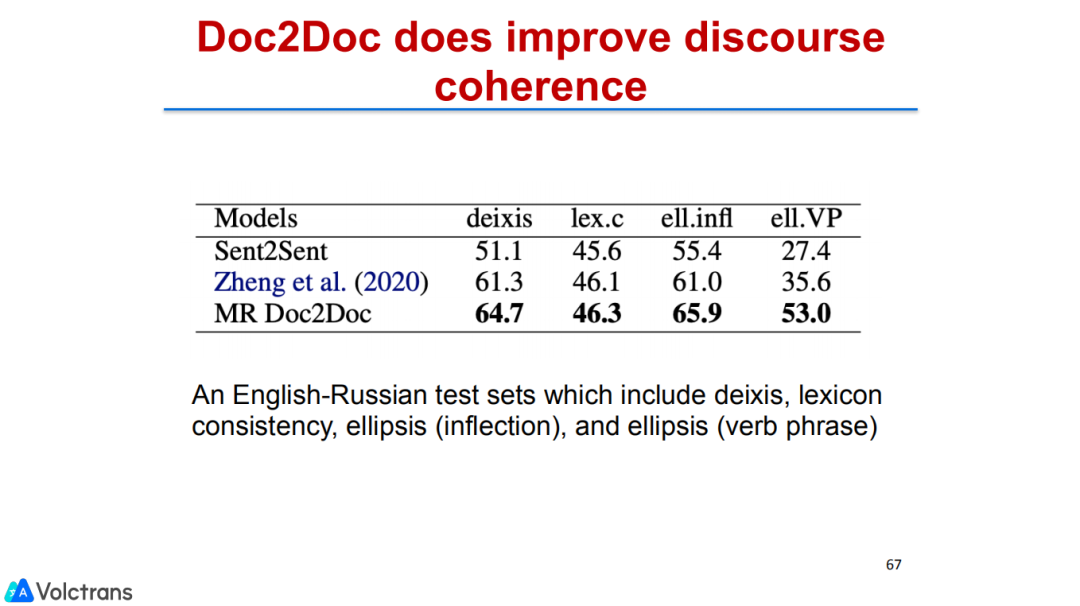
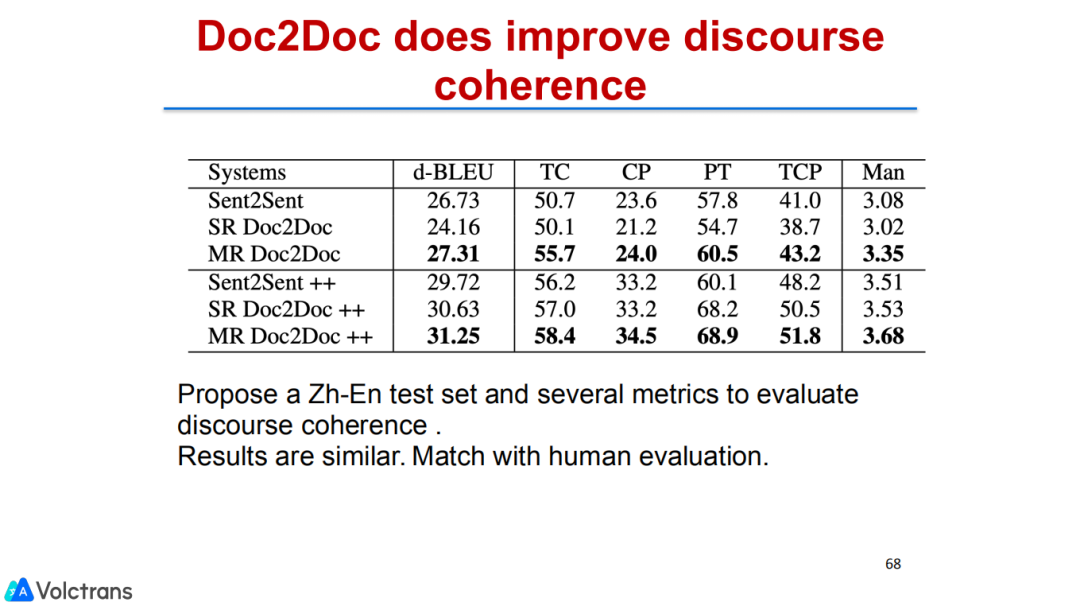
也做了pre train fine-tuning。文档翻译能够做到任何长度的翻译,在2000个字符的长度上我们都可以实现非常好的效果。

1. Listen,Understand and Translate
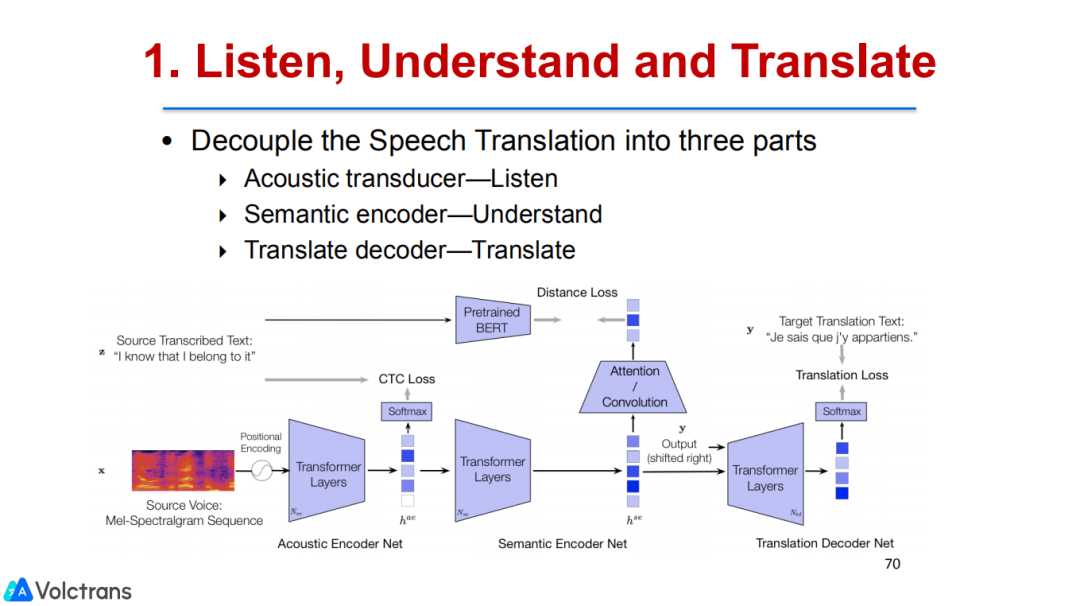
另外还有一些工作其实也是和之前的工作思路比较接近,我们希望通过pre train model引入语音信息或者多模态信息。我们做了一个解耦的端到端的语音翻译,把语音翻译分成多个阶段,但还是采用端到端方式。我们采用acoustic transducer做语音信息的监督,然后做语义信息的监督,把bert这种pre train model或者MT encoder的一些knowledge放到语音翻译里面起到帮助作用,最后再做翻译,也取得了很多SOTA结果。
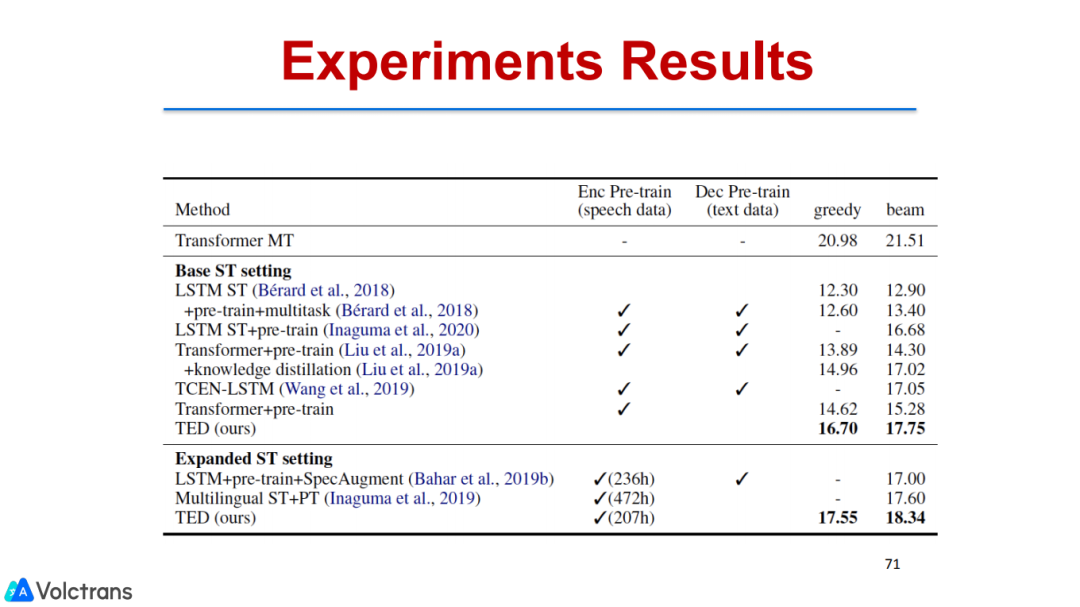
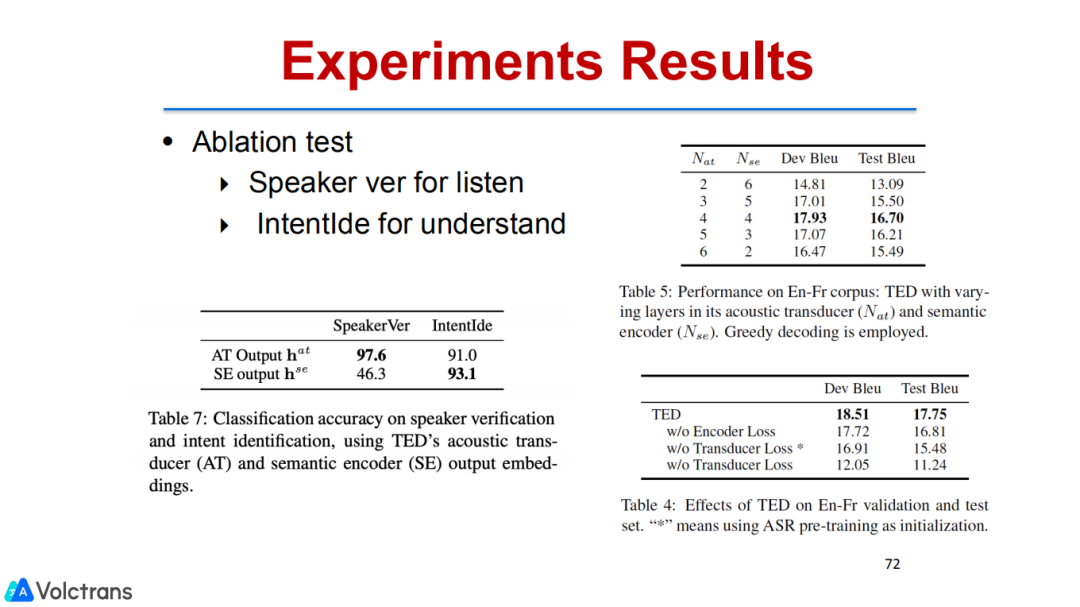
2. Consecutive Decoding
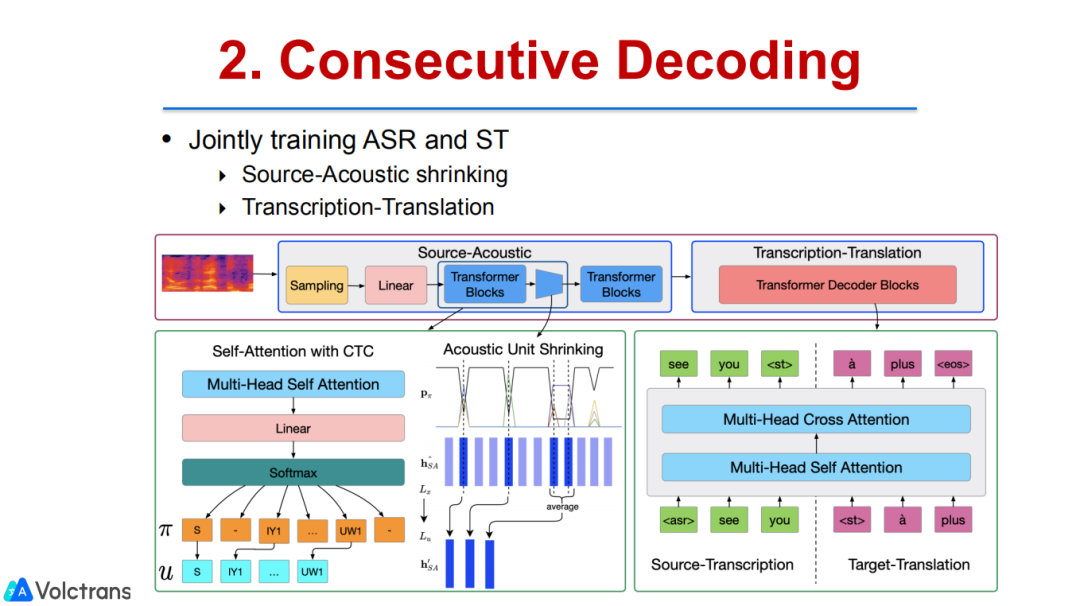
通过分析,我们发现这种解耦是必要的,通过多阶段的pre train fine-tuning,可以让model的底层更多地关注语音信号,高层更多关注语义信息。
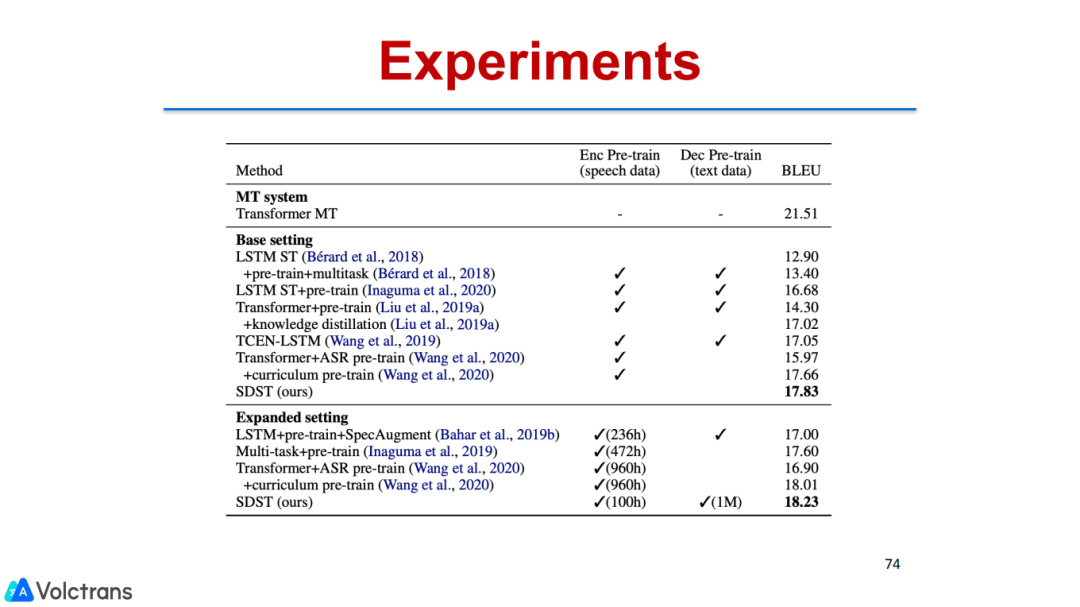
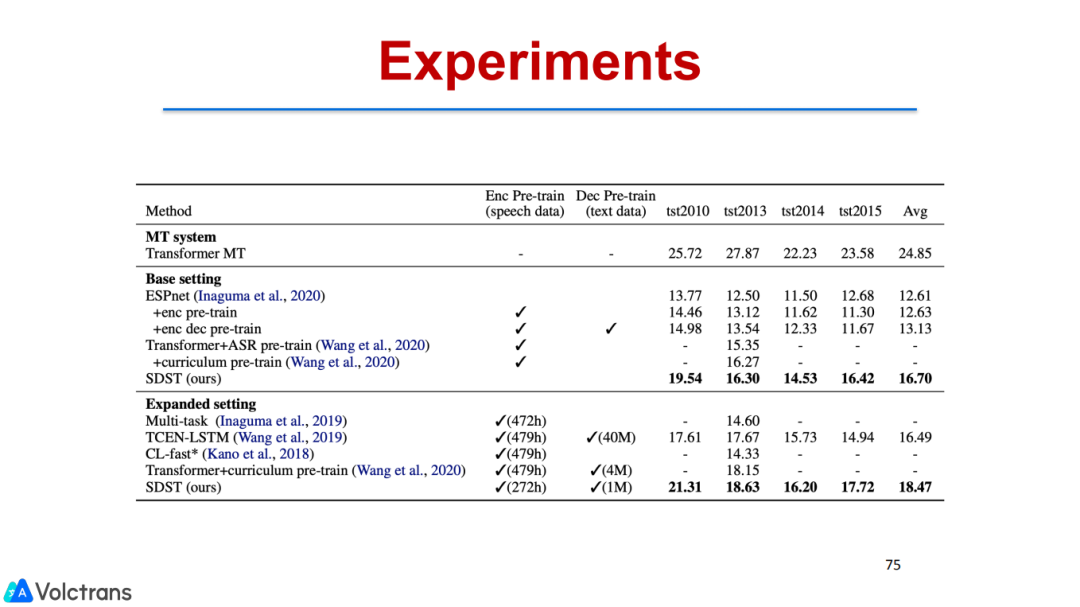
我们也做了一些相关的decoder,把MT pretrain model(text pretrain)放到语音翻译里面。我们也做了consecutive decoder,把目标端的模型解耦,解耦成ASR和ST两个model,但也是端到端的,和上一个工作比较互补,能把MT数据用上。上一个工作是把ASR和单语数据用上。经过这两个工作,我们就可以把单语数据、ASR数据、MT数据用到端到端语音翻译中,能够很好的提升模型性能,并且有潜力达到可用状态,在多个数据集上都取得了SOTA的结果。
3. Imagination improves MT

我们也以类似的思路做了图像翻译,但不同于之前的多模态图像翻译。之前的多模态图像翻译更多的是把图像和文本综合起来,我们的输入必须要求一段文本配合一个图像做翻译,会有一些局限性。一方面是没有办法利用到大规模的文本图像数据,你必须需要triple数据,就是中英的pair加图像,这样的数据是非常稀缺的,几乎没有。另外一个点是使用起来不方便,我们的input必须是图像加文本。所以我们想做的是imagination,给定一个文本,想象出它的图片,然后再拿文本和图像一起做翻译。
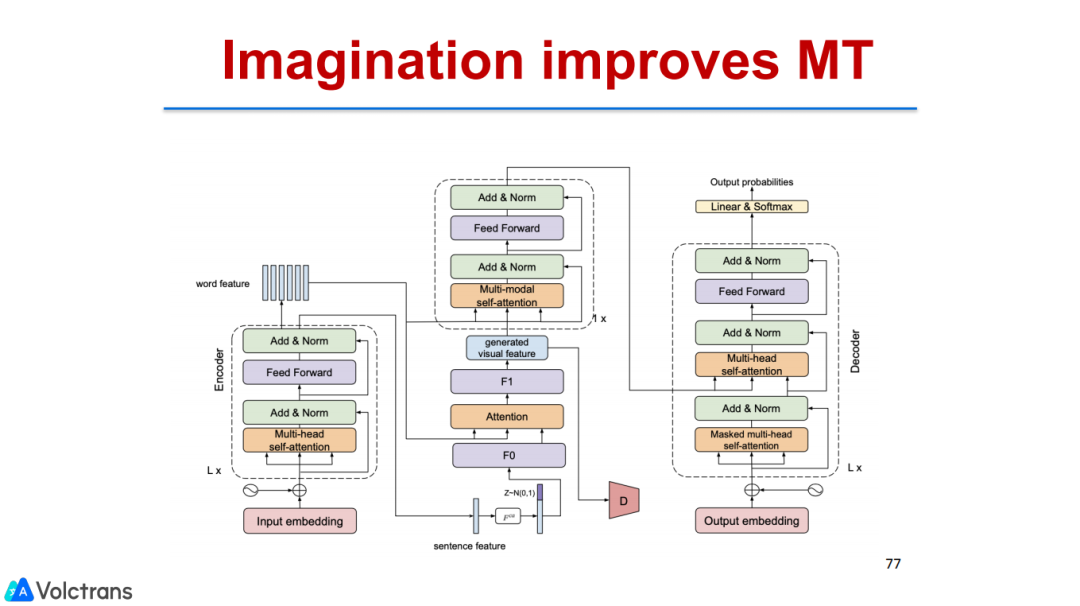
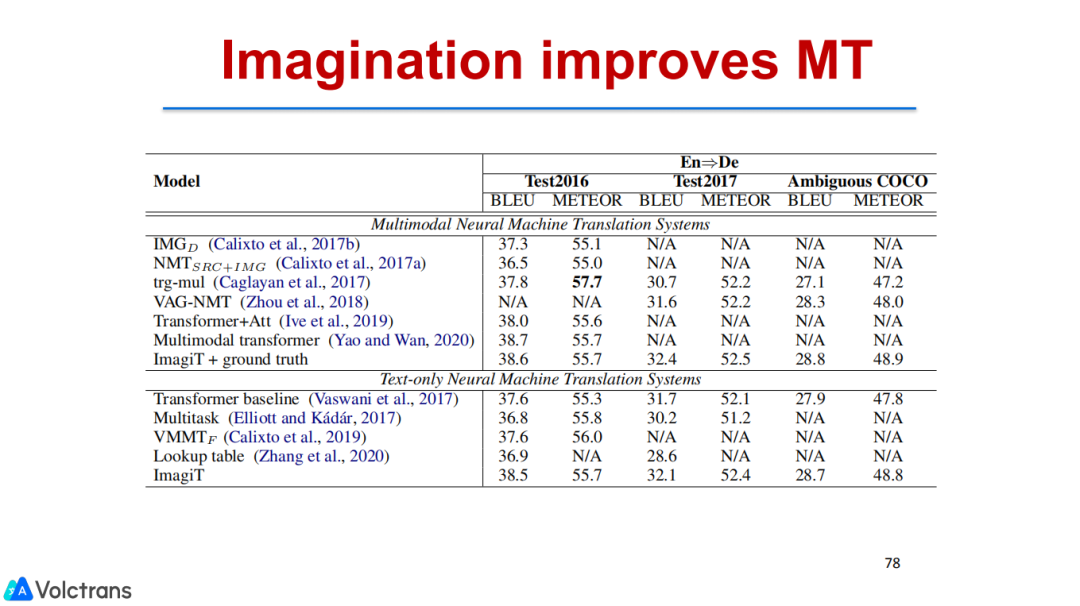
这个效果也是非常好的。整个模型结构这里就不展开了,简单说就是先通过文本生成图像信息,再把文本和图像一起编码,最后去做翻译。最后的结果还是非常不错的,我们在没有输入图像的情况下就能够和其他的一些多模态的有图像输入的模型达到相当或几乎一样的效果。

LightSeq:

另外我们的整个模型要serve,包括multilingual model,引入bert,其实整个model是非常heavy,如何把它做上线也是我们考虑的问题,所以我们同时也发布了一个非常高效的、非常快速的解码器,使我们的inference速度几乎比原生tensorflow要快十倍以上,能够serve我们的大模型,能够支持我们的pre train大模型上线。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

王明轩 博士
字节跳动 | 算法科学家、团队负责人
中科院博士,主要研究方向是机器翻译和自然语言处理。目前在字节跳动负责机器翻译团队,支持公司国际化业务,服务全球上亿用户。在 ACL、EMNLP 等顶级会议发表论文 20 多篇,也有比较丰富机器翻译的比赛经验,带领团队在 WMT2018,WMT2020 等比赛中多次拿到第一。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MT50” 可以获取《最新《机器翻译》进展报告,纽约大学Kyunghyun Cho讲解,附50页ppt》专知下载链接索引





