CVPR | About Network Dissection


Momenta公号现推出
CVPR 2017精彩看点系列总结
每日一篇推送,每天收获一点
炎炎夏日,Momenta Paper Reading依旧与你同在
在刚刚结束的CVPR 2017上,来自Momenta的十余位研发人员亲赴夏威夷,见证这场学术盛会。与会期间,高级研究员们与众多学术大牛面对面交流,收获良多。回国后纷纷将学术心得整理成文,以飨读者。
本期带来分享的是Momenta高级研究员蒋云飞,他将为大家解读关于Network Dissection: Quantifying Interpretability of Deep Visual Representations的论文。

Network Dissection: Quantifying Interpretability of Deep Visual Representations 论文解读
本文的是CVPR一篇Oral的文章,作者希望通过寻找到网络中间层与一些语义概念的对应关系,从而实现对于CNN网络潜在的表达能力的定量化分析,归纳发现深度神经网络的本质,从而进一步解释其黑盒特性。
作者首先建立了一个完善的测试数据集,叫做Broden(Broadly and Densely Labeled Dataset),每张图片都在场景、物体、材质、纹理、颜色等层面有pixel-wise的标定。接下来,将该数据集中的每一张图喂给需要分析的网络,拿到每个feature map 上的响应结果,进一步分析该层feature map对应的语义关系,归纳结果。整体流程如下图a所示。
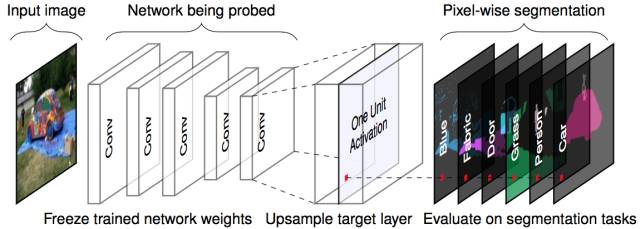

【Unit与Concept的关系】
作者希望将每个卷积核单元(unit)与一些语义上的概念(concept)对应起来,从而使用这些对应关系以及不同concept对应的unit的分布情况来表征该网络的表达能力。
通过如下公式,作者首先定义某一个单元的与语义上的概念的相关程度:
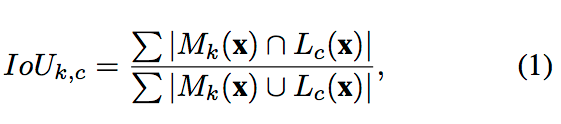
也即,通过计算该层feature map二值化激活区域与不同语义Ground Truth结果的交并比来确定该层所应该属于的语义结果。其中,x代表输入图像,c代表concept(概念),k代表某个单元, Sk(x) 是该单元特征图像feature map A(x)缩放回输入大小后的结果,Mk(x) ≡ Sk(x) ≥ Tk,Mk(x)为大于某个阈值的激活区域。
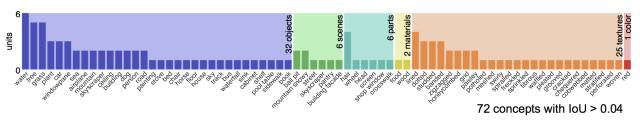
本文设定对于IoU(k,c) > 0.04,则该单元属于某一个语义概念。如果某个层对应多个语义概念,则取IoU最大的;只有唯一一个语义概念对应的层被称之为特定概念单元(unique concept unit),而这些特定概念层的数量的大小与分布情况,则定量的表示了该网络的可解释性(Interpretability)。
【结果分析】
为了探究网络的可解释性(Interpretability)的是否是与units的排列分布有关,作者对于某一层的所有unit进行random linear combination(下图Q),也即打乱该排布方式,而后将打乱的次序归位(下图Q^(-1)),观察concept的变化情况得到结果。具体如下图所示:
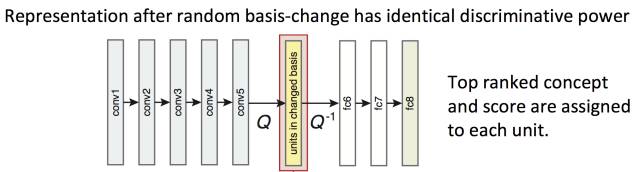
其中,rotation的大小代表了random Q的程度大小,而打乱这些units的排布并不会对于网络的最终输出产生影响,同时也不会改变该网络的表达能力(discriminative power)。
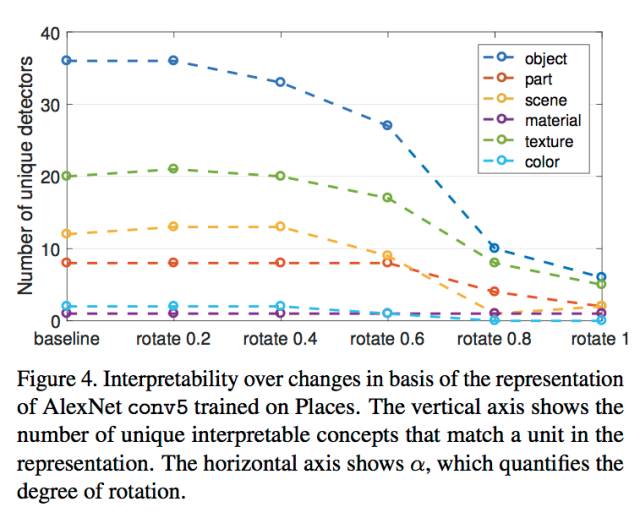
可以从结果中发现,随着rotation的逐渐变大,unique concept unit的数量开始急剧减少,因此CNN网络的可解释性是受到unit的排序的影响的。(写者注,这个结论强依赖于公式(1)的定义,是否是恰当的对于可解释性的描述有待讨论)。

通过对于AlexNet中conv1~conv5层中各单元响应情况的分析,我们可以归纳出: 浅层的单元更倾向于响应简单的纹理、颜色特征,而高层的单元则对于更具体的物体有响应,例如人脸、花朵等等。
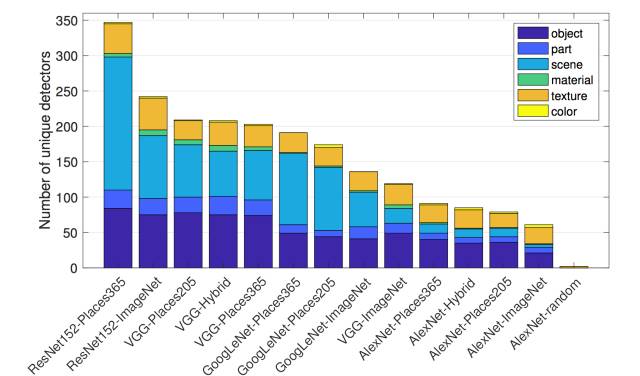
在网络结构实验中,作者将常见的网络结构在不同的数据集上进行训练,从中我们可以发现ResNet152的表达能力最强,而不同的训练集对于同一网络的表达能力也有影响,Places 365更多是场景分类,而且图片数量较ImageNet更多,因此网络会有更多的concept响应单元。
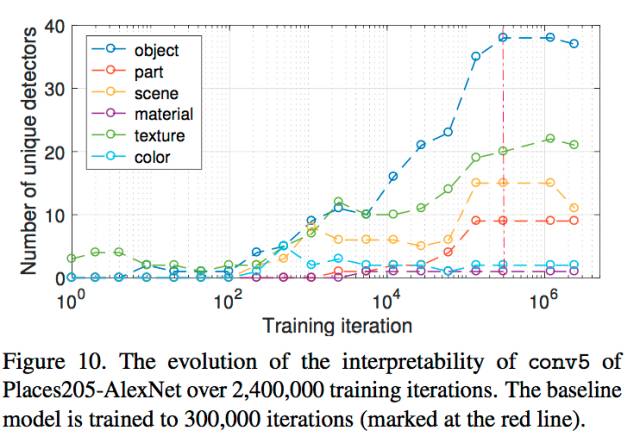
训练过程的探究实验中,我们可以发现,网络在训练初期更容易学习到物体的底层的特征,而到后期,逐渐学习到更为高阶的一些物体特征;而在Fine-tune的实验中,作者也发现,随着finetune的进行,不少的层的concept对应关系也会因为finetune数据集不同而发生对应数据集的迁移转变。

Q&A:
在7月23日(夏威夷时间)下午的Poster中,我们有幸遇到了本文的第二作者周博磊童鞋,并且就本文中的一些问题与他进行了深入地交流。

Q: 如何理解文中提到的rotation实验?
A: Rotation指的是对于某个层中的units的组合进行打乱,然后再将打乱的关系还原,从本质上来说,这样一种打乱不会导致最后的结果发生改变,然而当随机打乱的程度加大(rotation变大)则会发生sematic的concepts急剧下降(AlexNet conv5 从72下降为18),因此,unit之间的位置排序是有关系的,或者说sematic不在feature space, 而是在unit维度的,也即单个神经元是有意义的,不是像以前说的整个conv是有语义的。
Q:同一个网络,做不同的任务,那么网络的interpretability是否有不同?
A:首先从论文的试验中可以看到不同的数据集会有bias,因此其中的concept就会有不同,例如ImageNet中非常多种类的Dogs,那么concept会有多数偏向于dogs类;在同样的数据集上训练,从理论上来说,如果dominant保持一样,则大部分应该是一致的。
Q: 如何保证结果的正确性?
A: 对于超出测试集的类别,本文的方法确实不能够进行量化分析的,但目前来说这样一个数据集是能找到的最大的了,我们这边也会通过一些方式去扩充这样一个数据集。
Q: 如何确认哪个层更重要,是否有考虑过weights,因为 weights 同样会影响网络的后续输出?
A: 可以通过与concept的IOU的大小来确定层的重要性,IOU越大的话这个层作为某个concept的概率也越大,那么这个层更加重要;对于weights方面,作者表示目前没有考虑。
Q: 如何比较不同网络之间的优劣
A: 根据 interpretability可以去推测某个网络的能力大小,本文认为,interpretability越大的话网络的表达能力越强,性能也越强。

Momenta CVPR干货系列:
第一篇 CVPR | ImageNet冠军模型SE-Net详解
第二篇 CVPR | Deep Layer Cascade论文解读
第三篇 CVPR | 主动卷积 论文评析
敬请期待,后续还有解读来袭

Momenta,打造自动驾驶大脑。
Momenta致力于打造自动驾驶大脑,核心技术是基于深度学习的环境感知、高精度地图、驾驶决策算法。产品包括不同级别的自动驾驶方案,以及衍生出的大数据服务。
Momenta有世界顶尖的深度学习专家,图像识别领域最先进的框架Faster R-CNN和ResNet的作者, ImageNet 2015、ImageNet 2017、MS COCO Challenge 2015等多项比赛冠军。团队来源于清华大学、麻省理工学院、微软亚洲研究院等,有深厚的技术积累和极强的技术原创力。
编辑标题:“GH+姓名+职位”
简历砸向:talentoverflow@momenta.ai
做你自己的伯乐,来实习,拿4096现金大奖!


扫描二维码,关注Momenta微信公众号
看CVPR 2017精彩回顾




