太强了!人脸合成效果媲美StyleGAN,而它是个自编码器 | CVPR 2020
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转载自:机器之心 | 参与:魔王
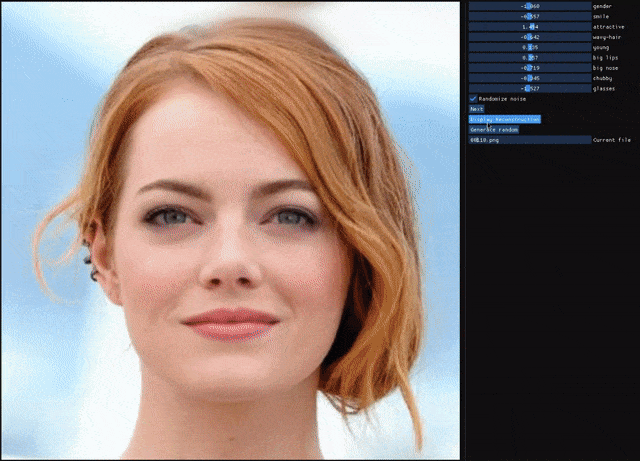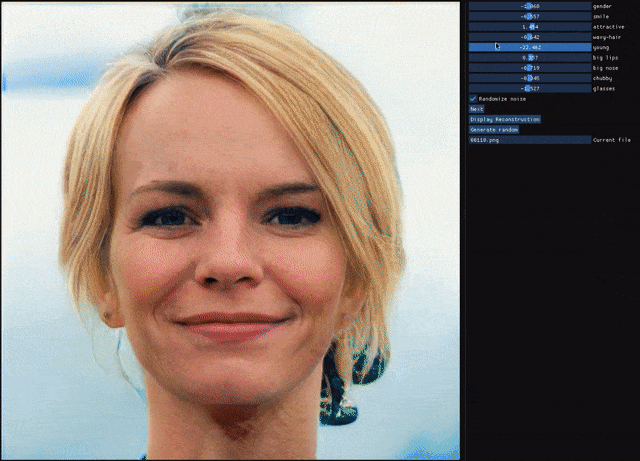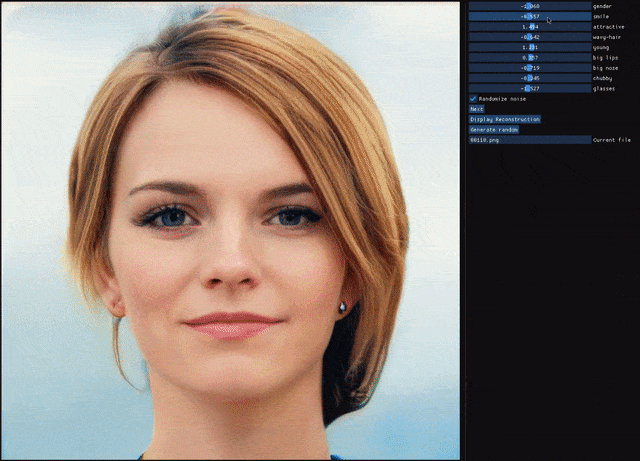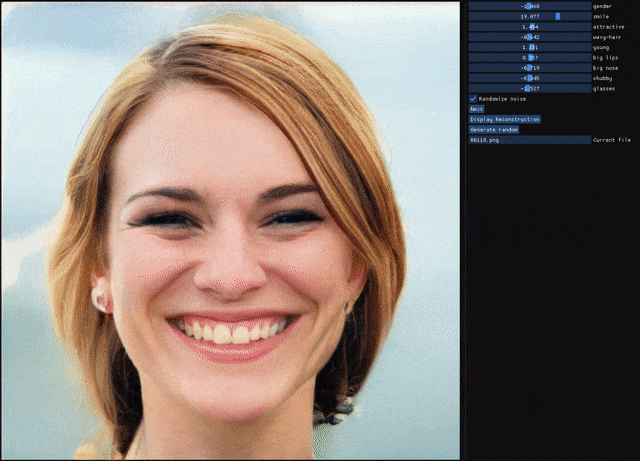
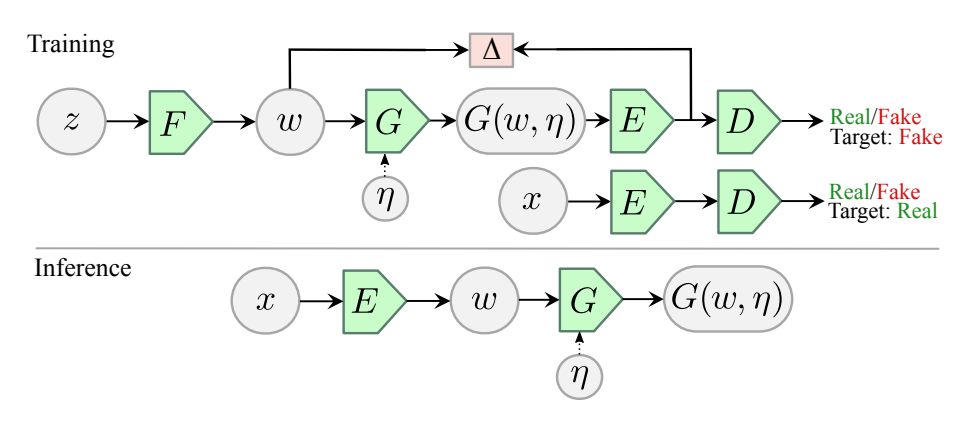
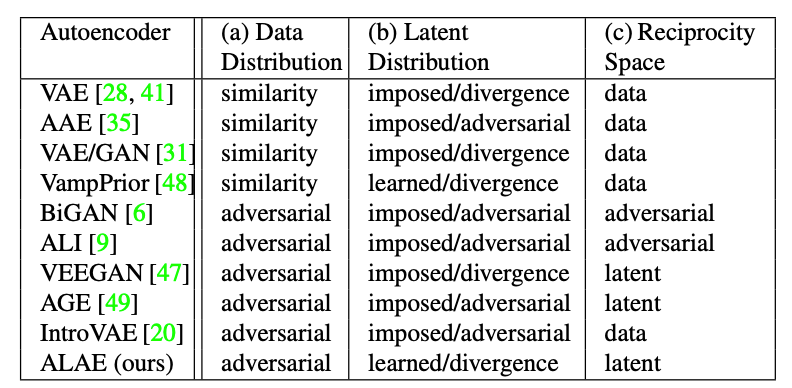
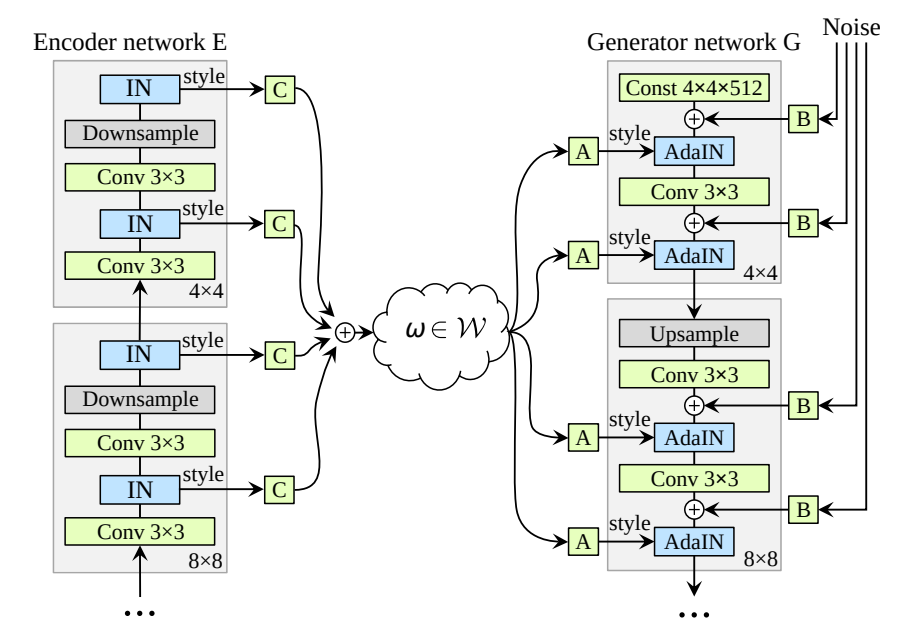
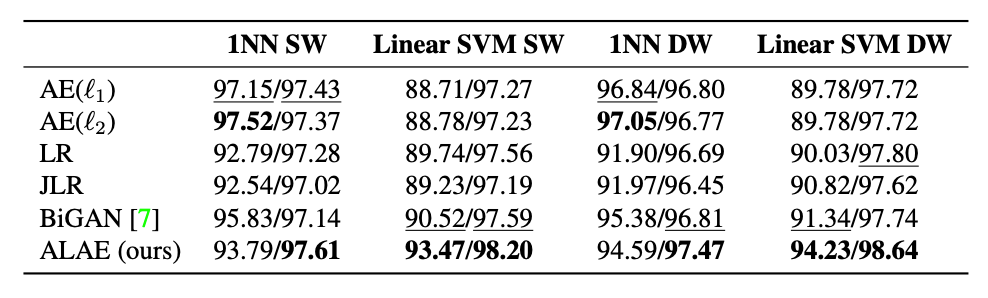
自编码器(AE)与生成对抗网络(GAN)是复杂分布上无监督学习最具前景的两类方法,它们也经常被拿来比较。人们通常认为自编码器在图像生成上的应用范围比 GAN 窄,那么自编码器到底能不能具备与 GAN 同等的生成能力呢?这篇研究提出的新型自编码器 ALAE 可以给你答案。目前,该论文已被 CVPR 2020 会议接收。
论文地址:https://arxiv.org/pdf/2004.04467.pdf
GitHub 地址:https://github.com/podgorskiy/ALAE
自编码器是否具备和 GAN 同等的生成能力?
自编码器能否学习解耦表征(disentangled representation)?




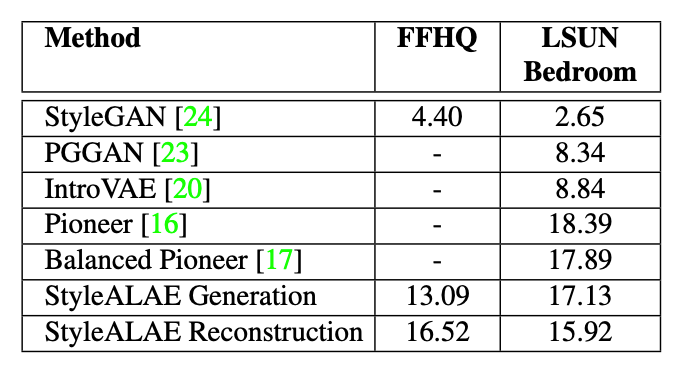
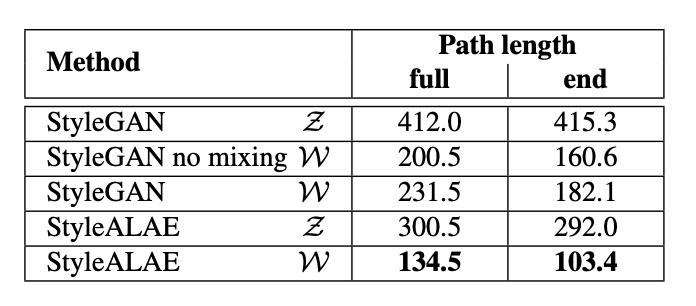



论文下载
在CVer公众号后台回复:StyleALAE,即可下载本论文
重磅!CVer-论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满1250+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
麻烦给我一个在看!
登录查看更多
相关内容

专知会员服务
36+阅读 · 2020年3月13日
Arxiv
5+阅读 · 2019年2月14日
Arxiv
3+阅读 · 2018年8月20日
Arxiv
4+阅读 · 2018年6月11日
Arxiv
10+阅读 · 2018年3月20日



相关VIP内容
专知会员服务
36+阅读 · 2020年3月13日
相关资讯
相关论文
Arxiv
5+阅读 · 2019年2月14日
Arxiv
3+阅读 · 2018年8月20日
Arxiv
4+阅读 · 2018年6月11日
Arxiv
10+阅读 · 2018年3月20日