Sentence-BERT: 一种能快速计算句子相似度的孪生网络
 !
!
阅读大概需要9分钟 ![]()
跟随小博主,每天进步一丢丢 ![]()


作者:光彩照人
学校:北京邮电大学
原文地址:https://www.cnblogs.com/gczr/p/12874409.html
一、背景介绍
BERT和RoBERTa在文本语义相似度等句子对的回归任务上,已经达到了SOTA的结果。但是,它们都需要把两个句子同时喂到网络中,这样会导致巨大的计算开销:从10000个句子中找出最相似的句子对,大概需要5000万(C100002=49,995,000)个推理计算,在V100GPU上耗时约65个小时。这种结构使得BERT不适合语义相似度搜索,同样也不适合无监督任务(例如:聚类)。
本文基于BERT网络做了修改,提出了Sentence-BERT(SBERT)网络结构,该网络结构利用孪生网络和三胞胎网络结构生成具有语义意义的句子embedding向量,语义相近的句子其embedding向量距离就比较近,从而可以用来进行相似度计算(余弦相似度、曼哈顿距离、欧式距离)。该网络结构在查找最相似的句子对,从上述的65小时大幅降低到5秒(计算余弦相似度大概0.01s),精度能够依然保持不变。这样SBERT可以完成某些新的特定任务,例如相似度对比、聚类、基于语义的信息检索。
二、模型介绍
1)pooling策略
SBERT在BERT/RoBERTa的输出结果上增加了一个pooling操作,从而生成一个固定大小的句子embedding向量。实验中采取了三种pooling策略做对比:
直接采用CLS位置的输出向量代表整个句子的向量表示
MEAN策略,计算各个token输出向量的平均值代表句子向量
MAX策略,取所有输出向量各个维度的最大值代表句子向量
三个策略的实验对比效果如下:
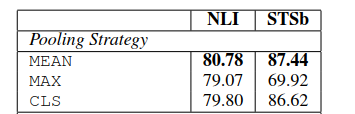
可见三个策略中,MEAN策略是效果最好的,所以后面实验默认采用的是MEAN策略。
2)模型结构
为了能够fine-tune BERT/RoBERTa,文章采用了孪生网络和三胞胎网络来更新权重参数,以达到生成的句子向量具有语义意义。该网络结构依赖于具体的训练数据,文中实验了下面几种结构和目标函数:
Classification Objective Function:
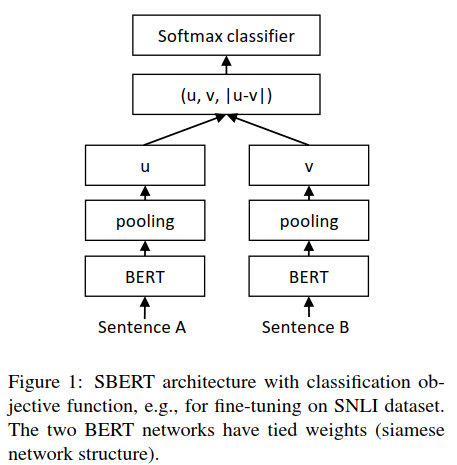
这里将embedding向量u和v以及它们之间的差向量拼接在一起,组成一个新的向量,乘以权重参数Wt∈R3n*k,n表示向量的维度,k是分类标签数量。
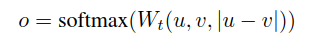
优化的时候采用交叉熵损失函数。
Regression Objective Function:
两个句子嵌入向量u和v的相似度计算结构如下:
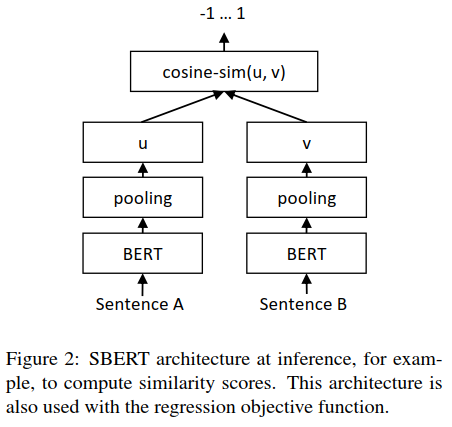
采取MAE(mean squared error)损失作为优化的目标函数。
Triplet Objective Function:
给定一个主句a、一个正面句子p和一个负面句子n,三元组损失调整网络,使得a和p之间的距离小于a和n之间的距离。数学上,我们最小化以下损失函数:
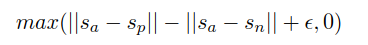
s表示a、p、n的句子嵌入向量,||·||表示距离,边缘参数ε表示sp与sa的距离至少比sn近ε。
3)模型训练
文中训练结合了SNLI(Stanford Natural Language Inference)和Multi-Genre NLI两种数据集。SNLI有570,000个人工标注的句子对,标签分为矛盾、蕴含、中立三种;MultiNLI是SNLI的升级版,格式和标签都一样,有430,000个句子对,主要是一系列口语和书面语文本。文本蕴含关系描述的是两个文本之间的推理关系,其中一个文本作为前提(premise),另一个文本作为假设(hypothesis),如果根据前提P能够推理得出假设H,那么就说P蕴含H,记做P->H。参考样例如下:

实验时,每个epoch作者用3-way softmax分类目标函数对SBERT进行fine-tune,batch_size=16,采用Adam优化器,learning rate=2e-5,pooling策略是MEAN。
三、评测-语义文本相似度(Semantic Textual Similarity-STS)
在评测的时候,这里采用余弦相似度来比较两个句子向量的相似度。
1)无监督STS
本次评测采用的是STS 2012-2016 五年的任务数据、STS benchmark数据(2017年构建)、SICK-Relatedness数据,这些数据集都是标好label的句子对,label表示句子之间的相互关系,范围为0~5,样例如下:

无监督评测不采用这些数据集的任何训练数据,直接用上述训练好的模型来计算句子间的相似度,然后通过斯皮尔曼等级相关系数来衡量模型的优劣。结果如下:
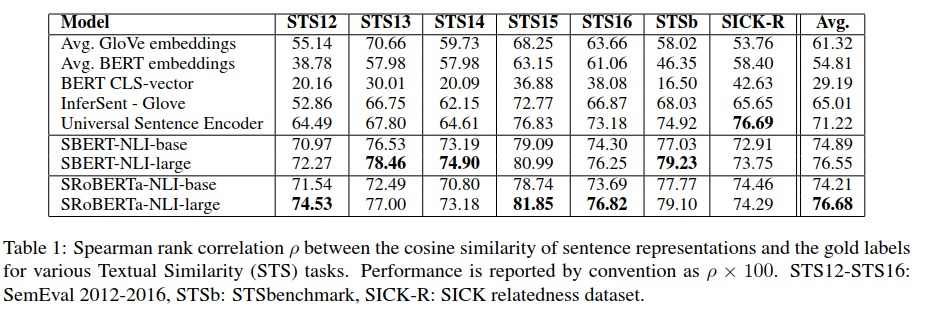
结果显示直接采用BERT的输出结果,效果挺差的,甚至不如直接计算GloVe嵌入向量的平均值效果好;采用本文的孪生网络在NLI数据集上fine-tuning后的模型效果明显要好很多,SBERT和SRoBERTa差异不大。
2)有监督STS
有监督STS数据集采用的是STS benchmark(简称STSb)数据集,就是上面提到的2017年抽取构建的,是当前比较流行的有监督STS数据集。它主要来自三个方面:字幕、新闻、论坛,包含8,628个句子对,训练集5,749,验证集1,500,测试集1,379。BERT将句子对同时输入网络,最后再接一个简单的回归模型作为输出,目前在此数据集上取得了SOTA的效果。
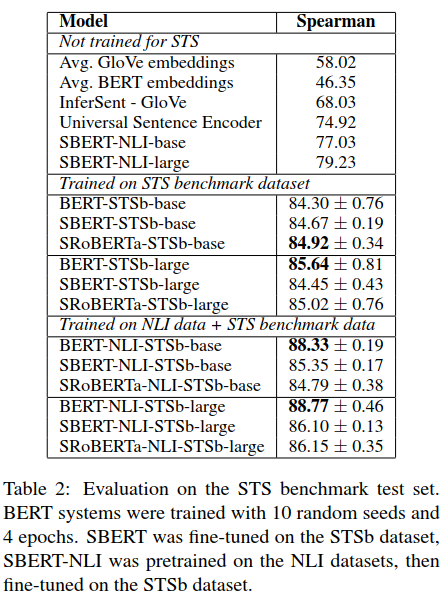
上述实验结果分为三块:
not trained for STS:表示直接采用的是跟上面无监督评测一样的模型,结果也一样;
Trained on STS benchmark :表示没有使用NLI数据集,直接在STSb训练数据集上利用孪生网络结构构建回归模型fine-tuning;
Trained on NLI data+STS benchmark :表示利用孪生网络先在NLI数据集上训练分类模型学习句子向量表示,然后在STSb训练集上再利用回归模型再次学习句子embedding,相当于利用两种数据集进行了两次fine-tuning。
评测的时候都是采用的STSb的测试集进行评测。可以看到,最后一种训练方式表现最好,尤其单纯的BERT架构有较大的提升幅度。
四、评测-SentEval
SentEval是一个当前流行的用来评测句子embedding质量的工具,这里句子embedding可以作为逻辑回归模型的特征,从而构建一个分类器,并在test集上计算其精度。这里利用SentEval工具在下面几个迁移任务上对比SBERT与其它生成句子embedding的方法:
MR(movie review):电影评论片段的情感预测,二分类
CR(product review):顾客产品评论的情感预测,二分类
SUBJ(subjectivity status):电影评论和情节摘要中句子的主观性预测,二分类
MPQA(opinion-polarity):来自新闻网的短语级意见极性分类,二分类
SST(Stanford sentiment analysis):斯坦福情感树库,二分类
TREC(question-type classification):来自TREC的细粒度问题类型分类,多分类
MRPC:Microsoft Research Paraphrase Corpus from parallel news sources,释义检测。
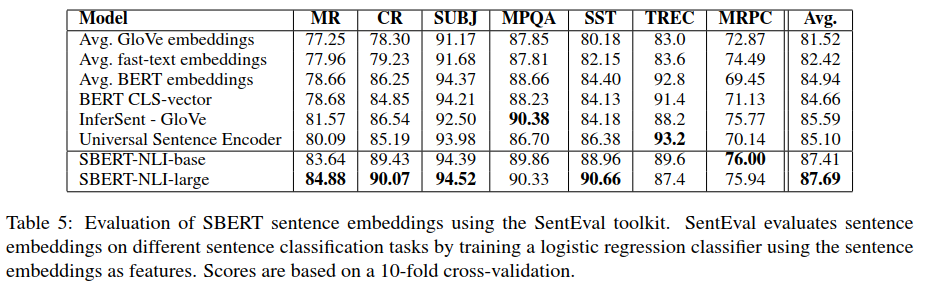
实验结果显示,SBERT生成的句子向量似乎能够很好捕获情感信息,在MR、CR、SST上都有较大的提升;BERT在之前的STS数据集上表现比较差,但是在SentEval上却有了不错的效果表现,这是因为STS数据集上利用余弦相似度衡量句子向量,余弦相似度对于向量的每一个维度都是同等的,然而SentEval是利用逻辑回归分类器来评测,这样某些维度会对最终的分类结果产生影响。
所以,BERT的直接输出结果无论是CLS位置的还是平均embedding都不适合用来计算余弦相似度、曼哈顿距离和欧式距离。虽然BERT在SentEval上面表现稍微好一些,但是基于NLI数据集的SBERT还是达到了SOTA的效果。
五、消融研究
为了对SBERT的不同方面进行消融研究,以便更好地了解它们的相对重要性,我们在SNLI和Multi-NLI数据集上构建了分类模型,在STSb数据集上构建了回归模型。在pooling策略上,对比了MEAN、MAX、CLS三种策略;在分类目标函数中,对比了不同的向量组合方式。结果如下:
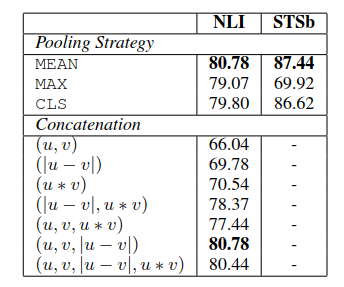
在pooling策略上,MEAN效果最好;在向量组合模式上,只有在分类训练的时候才使用,结果显示element-wise的|u-v|影响最大。
原文题目:《Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks》
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦




