低清视频也能快速转高清:超分辨率算法TecoGAN
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
来自慕尼黑工业大学的研究人员提出了一种用于实现视频超分辨率的新型 GAN——TecoGAN。利用该技术能够生成精细的细节,甚至蜘蛛背上的斑点都清晰可见,同时还能保持视频的连贯性 。
作者 | Mengyu Chu 等
来源 | 机器之心
图像超分辨率技术指的是根据低分辨率图像生成高分辨率图像的过程,该技术希望根据已有的图像信息重构出缺失的图像细节。视频超分辨率技术则更加复杂,不仅需要生成细节丰富的一帧帧图像,还要保持图像之间的连贯性。
在一篇名为
「Temporally Coherent GANs for Video Super-Resolution (TecoGAN)」的论文中,来自慕尼黑工业大学的研究人员提出了一种用于实现视频超分辨率的新型 GAN——TecoGAN。
此前,已经有开发者利用 ESRGAN 这种视频超分辨率模型重制了很多单机游戏,包括经典的重返德军总部、马克思·佩恩和上古卷轴 III:晨风等等。重制的高清版游戏在画质上有很好的效果,而且还保留了原始纹理的美感与风格。
以下三幅动图的右半部分是用 TecoGAN 生成的,说不定用它来重制单机游戏会有更惊人的效果。该方法能够生成精细的细节,较长的生成视频序列也不会影响其时间连贯度。
图中,动物皮的网格结构、蜥蜴的图案和蜘蛛背部的斑点无不彰显该方法的效果。该方法中的时空判别器在引导生成器网络输出连贯细节方面居功至伟。



这个视频超分辨率 GAN 牛在哪里?
自然图像超分辨率是图像和视频处理领域的一大经典难题。对于单一图像超分辨率(SISR),基于深度学习的方法可以达到当前最佳的峰值信噪比(PSNR),而基于 GAN 的架构在感知质量方面实现了重大改进。
在视频超分辨率(VSR)任务中,现有的方法主要使用标准损失函数,如均方差损失,而不是对抗损失函数。类似地,对结果的评估仍然聚焦于基于向量范数的指标,如 PSNR 和结构相似性(Structural Similarity,SSIM)指标。与 SISR 相比,VSR 的主要难点在于如何获取清晰的结果,且不会出现不自然的伪影。基于均方差损失,近期的 VSR 任务使用来自低分辨率输入的多个帧 [13],或重用之前生成的结果 [28] 来改进时间连贯度。
尽管对抗训练可以改善单个图像的视觉质量,但它并不常用于视频。在视频序列案例中,我们不仅要研究任意的自然细节,还要研究可以稳定形式基于较长图像序列生成的细节。
该研究首次提出了一种对抗和循环训练方法,以监督空间高频细节和时间关系。在没有真值动态的情况下,时空对抗损失和循环结构可使该模型生成照片级真实度的细节,同时使帧与帧之间的生成结构保持连贯。研究者还发现了一种使用对抗损失的循环架构可能会出现的新型模型崩溃,并提出了一种双向损失函数用于移除对应的伪影。
该研究的核心贡献包括:
提出首个时空判别器,以获得逼真和连贯的视频超分辨率;
提出新型 Ping-Pong 损失,以解决循环伪影;
从空间细节和时间连贯度方面进行详细的评估;
提出新型评估指标,基于动态估计和感知距离来量化时间连贯度。
论文:Temporally Coherent GANs for Video Super-Resolution (TecoGAN)

论文链接:
https://arxiv.org/pdf/1811.09393.pdf
摘要:对抗训练在单图像超分辨率任务中非常成功,因为它可以获得逼真、高度细致的输出结果。因此,当前最优的视频超分辨率方法仍然支持较简单的范数(如 L2)作为对抗损失函数。直接向量范数作损失函数求平均的本质可以轻松带来时间流畅度和连贯度,但生成图像缺乏空间细节。该研究提出了一种用于视频超分辨率的对抗训练方法,可以使分辨率具备时间连贯度,同时不会损失空间细节。
该研究聚焦于新型损失的形成,并基于已构建的生成器框架展示了其性能。研究者证明时间对抗学习是获得照片级真实度和时间连贯细节的关键。除了时空判别器以外,研究者还提出新型损失函数 Ping-Pong,该函数可以有效移除循环网络中的时间伪影,且不会降低视觉质量。之前的研究并未解决量化视频超分辨率任务中时间连贯度的问题。该研究提出了一组指标来评估准确率和随时间变化的视觉质量。用户调研结果与这些指标判断的结果一致。总之,该方法优于之前的研究,它能够得到更加细节化的图像,同时时间变化更加自然。
模型方法
该研究提出的 VSR 架构包含三个组件:循环生成器、流估计网络和时空判别器。生成器 G 基于低分辨率输入循环地生成高分辨率视频帧。流估计网络 F 学习帧与帧之间的动态补偿,以帮助生成器和时空判别器 D_s,t。
训练过程中,生成器和流估计器一起训练,以欺骗时空判别器 D_s,t。该判别器是核心组件,因为它既考虑空间因素又考虑时间因素,并对存在不现实的时间不连贯性的结果进行惩罚。这样,就需要 G 来生成与之前帧连续的高频细节。训练完成后,D_s,t 的额外复杂度不会有什么影响,除非需要 G 和 F 的训练模型来推断新的超分辨率视频输出。
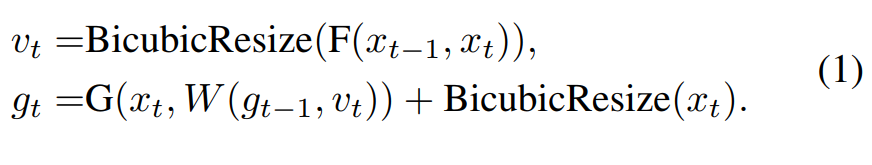
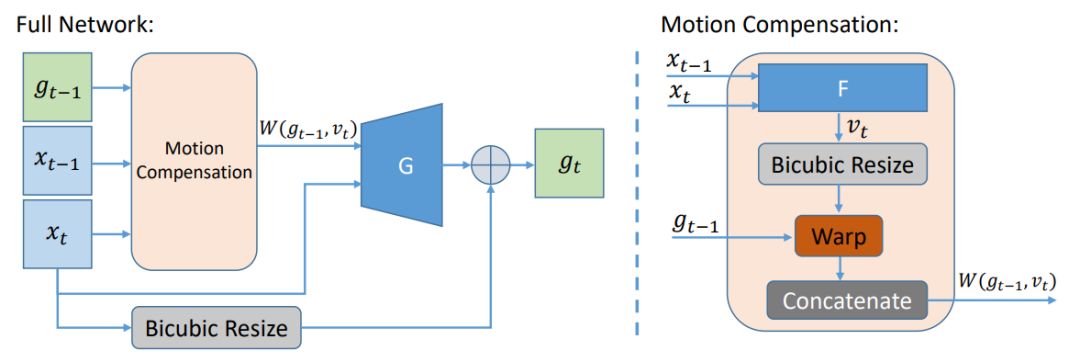
图 2:具备动态补偿(motion compensation)的循环生成器。
该研究提出的判别器结构如图 3 所示。它接收了两组输入:真值和生成结果。
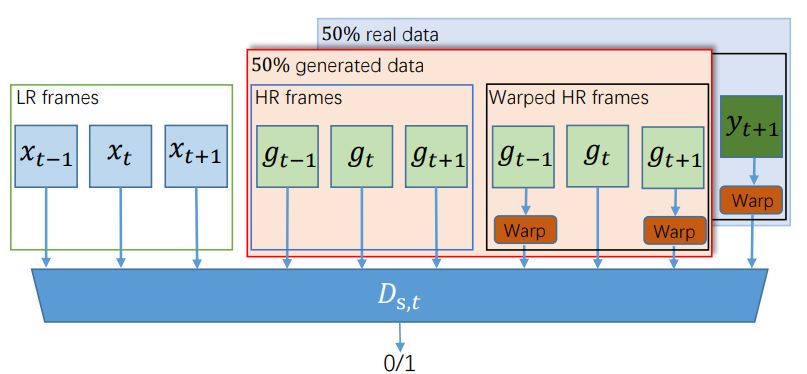
图 3:时空判别器的输入。
损失函数
为了移除不想要的细节长期漂移,研究者提出一种新型损失函数「Ping-Pong」(PP) 损失。

图 4:a)不使用 PP 损失训练出的结果。b)使用 PP 损失训练出的结果。后者成功移除了漂移伪影(drifting artifact)。
如图 4b 所示,PP 损失成功移除了漂移伪影,同时保留了适当的高频细节。此外,这种损失结构可以有效增加训练数据集的规模,是一种有用的数据增强方式。
该研究使用具备 ping-pong ordering 的扩展序列来训练网络,如图 5 所示。即最终附加了逆转版本,该版本将两个「leg」的生成输出保持一致。PP 损失的公式如下所示:
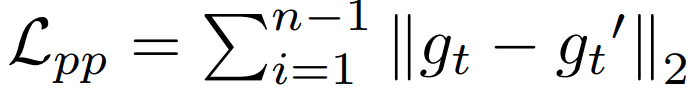
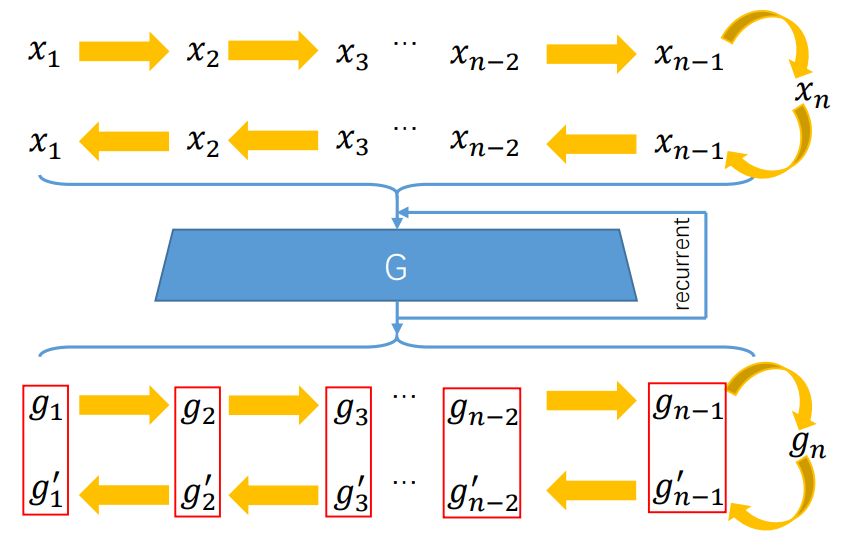
图 5:使用该研究提出的 Ping-Pong 损失,g_t 和
实验结果
研究者通过控制变量研究说明了 L_(G,F) 中单个损失项的效果。
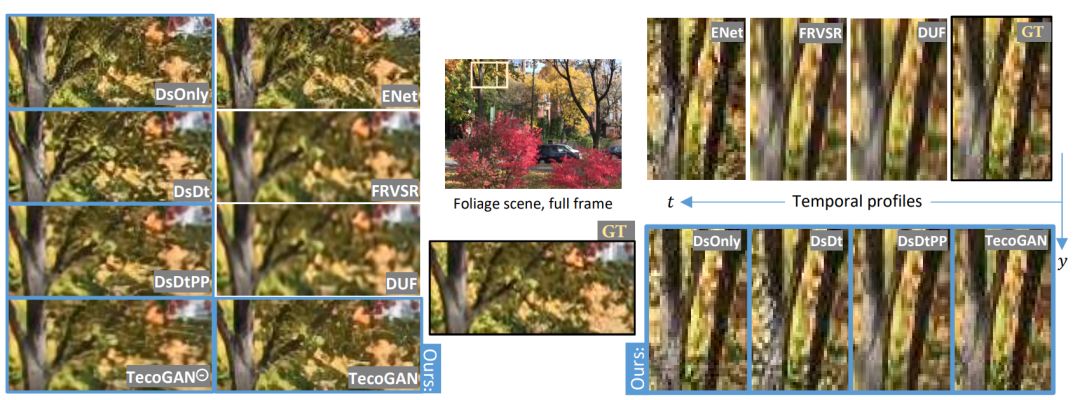
图 6:树叶场景对比。对抗模型(ENet、DsOnly、DsDt、DsDtPP、
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按关注极市平台
觉得有用麻烦给个在看啦~


