采样算法哪家强?一个针对主流采样算法的比较

论文标题:
A Systematic Characterization of Sampling Algorithms for Open-ended Language Generation
论文作者:
Moin Nadeem (MIT), Tianxing He (MIT), Kyunghyun Cho (NYU), James Glass (MIT)
论文链接:
https://arxiv.org/abs/2009.07243
代码链接:
https://github.com/moinnadeem/characterizing-sampling-algorithms
文本生成离不开采样,一个好的采样方法可以兼顾生成文本的质量和多样性。但是,目前主流的各采样算法并没有得到充分的研究,它们的优劣也难以量化。
本文在语言模型上比较了当前主流的几个采样算法Top-K, Nucleus, Tempered,发现他们都满足三个关键性质,因此在效果上难分伯仲。
进一步的研究表明,满足这三个性质的其他采样算法也能够取得很好的效果,这就指出了文本生成所需的必要条件。
文本生成的两大要素:质量与多样性
文本生成我们之前已经讲过很多了,但是读者有没有发现,基本上所有的文本生成任务,所谓的“目标句子”都是唯一的,或者很少。
比如,一个语言模型已经生成了“The news says that”,那么它下面会生成什么呢?对人来说,完全可以大开脑洞续写,但是对于一个已经训练好的模型来说,它下面要生成的就已经固定了(如果采取定性解码算法,如每一步都取概率最大的词),则说这个模型的多样性很差。
所以,对于文本生成模型来说,我们想要尽量在质量和多样性之间保持平衡。采样算法就是一种追求这种平衡的技术。
在解码的时候,不按照模型本身得到的每个词的概率采样,而是进行一定的变换,然后再采样,如果采样范围缩小,那么多样性就减少,但质量也会提高,如果采样范围扩大,多样性就会增大,但质量也会降低。
那么如何设计这样的采样算法,使得最大化保持质量与多样性的平衡呢?
本文针对当前主流的几种采样算法进行了系统性的比较,观察它们的Q (Quality)-D (Diversity)平衡,其中质量由BLEU衡量,多样性由n-gram entropy衡量。
进一步进行观察研究发现,这几个采样算法都满足三个关键性质:(1)减熵性;(2)保序性;(3)保斜率性。而一旦某种采样算法不满足其中一条性质,那么它的Q-D平衡就会被打破。因此,这三条性质是保证采样算法保持Q-D平衡的必要条件。
总的来说,本文研究贡献如下:
系统性地比较了几种采样算法在文本生成上的效果,发现它们有很相似Q-D平衡性;
提出这几种采样算法成功的关键在于三条性质;
一旦不满足任意一条性质,则采样算法的表现就会显著降低;
启发未来采样算法的设计。
比较的采样算法
用于文本生成的采样算法很多,最简单的就是直接取概率最大的词,或者叫top-1采样。
本文主要比较了下述几种采样方法(注意向量 已经降序排列了,所以 ):
Top-k采样: 只考虑前 个概率最大的词,注意要把它们的概率重新归一化,即

Nucleus采样:也是只考虑前若干个概率最大的词,不过以一种概率累计式的方法,即,

Tempered采样:在原概率上增加一个温度项,即

Tempered Top-k采样:结合Top-k采样和Tempered采样,即

之后,我们就得到了一个用于采样的概率向量 。
采样算法的三个性质
在有了上述几个采样算法之后,我们可以发现,它们都满足下述三个性质:
减熵性(Entropy Reduction):变换后的概率分布始终小于变换前的概率分布,即 。
保序性(Order Preservation):元素排列的顺序不变,即 。
保斜率性(Slope Preservation):分布的“斜率”保持不变,即

保斜率性指出了,变换后的概率分布在概率的量级变化上是成比例的,而保序性则说明概率大的仍然概率大。
性质2的证明是显然的,性质3也只需要代入公式即可。比较麻烦的是性质1,有兴趣的读者可以参考原文附录B完成证明。
采样算法的设计
上面我们证明了所述的采样算法都满足这三条性质,那么,是不是所有满足这三条性质的采样算法都能有比较好的Q-D平衡呢?是不是只要不满足其中至少一条性质,就不会有好的效果呢?前者是充分条件,后者是必要条件。
为了证明必要条件,只需要举例说明即可,但是充分条件难以用例子证明,故在本节我们仍然是举例进行一定程度的说明。
为此,除了上述的几种算法外,我们还设计两类采样算法:一是不满足某些性质,二是满足所有性质。
不满足某些性质的采样算法
Target-Entropy采样:形式是Tempered采样,但其中的温度设定为让变换后的概率分布的熵恒定为一个常值,即

它违反了减熵性。
Random-Mask采样:随机抹去一些词后形成的概率分布,即

显然,它违反了保序性。
Noised Top-k采样:在原来的top-k得到的概率分布上再加上有序噪声分布,即

由于 本身也是有序的,所以不违反保序性,但是它违反了保斜率性。
满足所有性质的采样算法
Random Top-k采样:这里的 是随机产生的,即

Max-Entropy采样:和Target-Entropy采样类似,只是要保证减熵性:

实验
接下来就是要以绘制Q-D散点图的方式看这些采样算法的实际效果。自动测评指标有corpus-BLEU(衡量质量Q)与self-BLEU(衡量多样性D),人工测评则是在1-5之间打分(衡量质量Q)和使用n-gram entropy(衡量多样性D)。模型采用GPT-2,分别在Gigaword与Wiki103上微调。其他细节请参考原文。
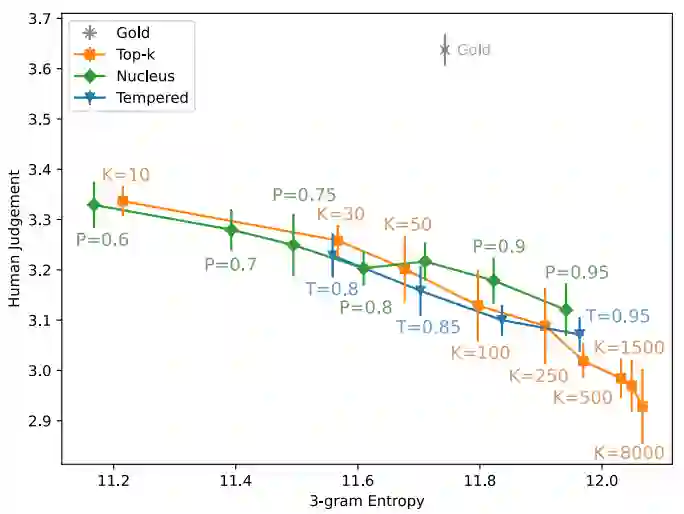
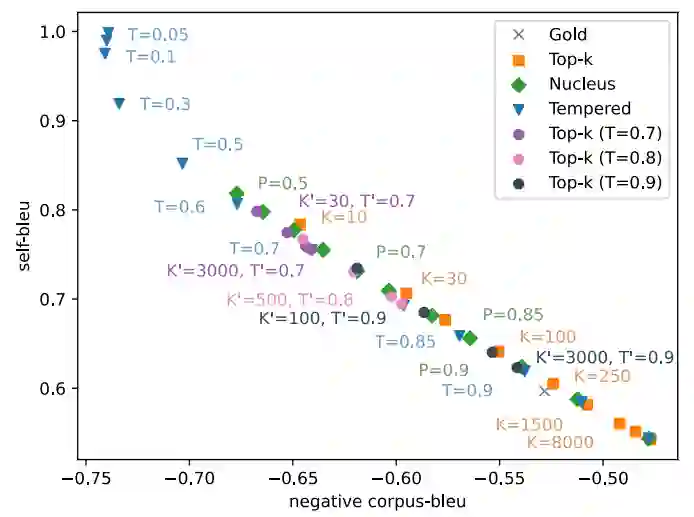
首先来比较当前主流采样算法的Q-D平衡,下面两个图依次是人工测评和自动测评结果。可以看到,无论是人工测评还是自动测评,这几个算法的表现都没有显著差异。
在一个算法内部,调整不同的超参可能有不同的结果,但从所有算法的总体趋势和表现来看,它们还是很相似的。
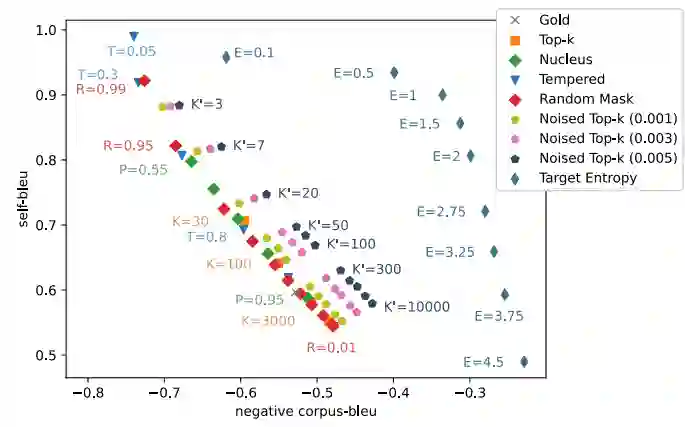
那么,对我们设计的不满足某些性质的采样算法来说,它们的表现又如何呢?其结果如下图所示。可以看到,违反了减熵性的Target Entropy表现最差;Noised Top-k效果随着噪声的增加而效果变差;而Random Mask的效果和现有的算法表现相近。上述观察说明,在保序性这个条件上可以略有放松,但是在减熵性和保斜率性上不能放宽。
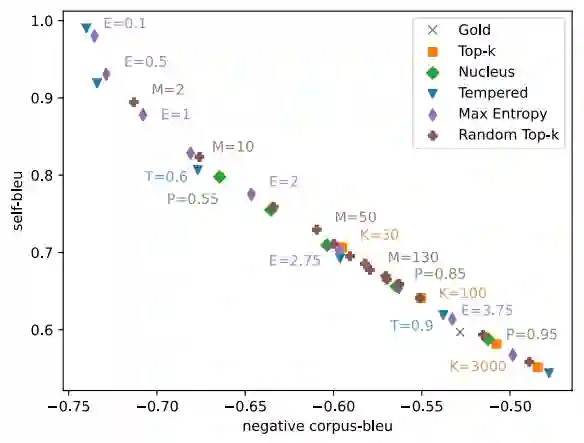
下图是设计的满足所有性质的采样算法的表现。可以看到,所提出的Max Entropy和Random Top-K完全和现有算法保持一致。
实际上,在人工测评上这些算法的表现趋势也都和自动测评一致。
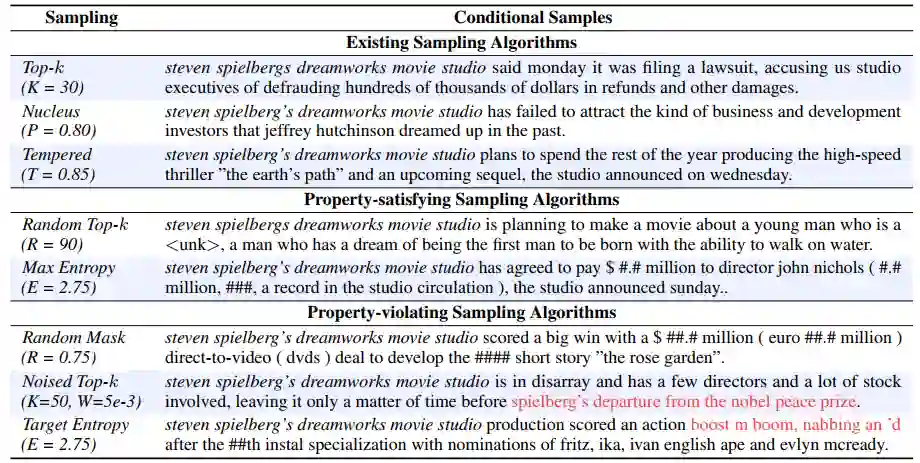
下面来看一下不同算法具体生成的文本是怎样的,如下表所示。各个算法都调整超参数,使得它们的self-BLEU相似(即多样性相似),因此可以更直观地比对所生成文本的质量。
可以看到,满足全部性质的算法所生成的文本大致还是流畅连贯的,但是对违反某些性质的算法而言,总有不连贯的地方,导致其质量较低。也就是说,某些性质对文本质量有重要影响。
小结
本文从文本生成的角度比较系统地研究和比较了几种主流采样算法的效果,在发现他们的Q-D平衡都相似的情况下,提出了它们都满足的三种性质,从而猜测这三种性质对所生成文本的质量和多样性有重要作用。
为了验证这个猜想,本文设计了两组采样算法,一组全部满足这些性质,另一组不满足某些性质,然后比较它们的效果。
结果发现,不满足某些性质的采样算法的确在Q-D平衡上表现更差,即使控制相同的多样性,所生成的文本质量也较低,这印证了这三种性质在某种意义是的确是保障采样算法Q-D平衡的必要条件。
值得一说的是,尽管本文提出了这样的假设,并从经验上进行了验证,但该理论仍然属于猜想,究竟是不是这三个性质起决定作用,还是其背后更本质的数学原理在起作用,目前都尚没有定论。
本文算是给采样算法为何能提高文本质量与多样性的研究开了一扇门,以更好地指导采样算法的设计。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。






