NLP中的自监督表示学习,全是动图,很过瘾的

作者:amitness
编译:ronghuaiyang
其实在自监督学习的概念提出之前,NLP中就已经运用到了这一思想。
虽然计算机视觉在自监督学习方面取得了惊人的进展,但在很长一段时间内,自监督学习一直是NLP研究领域的一等公民。语言模型早在90年代就已经存在,甚至在“自我监督学习”这个术语出现之前。2013年的Word2Vec论文推广了这一模式,在许多问题上应用这些自监督的方法,这个领域得到了迅速的发展。
这些自监督的方法的核心是一个叫做 “pretext task” 的框架,它允许我们使用数据本身来生成标签,并使用监督的方法来解决非监督的问题。这些也被称为“auxiliary task”或“pre-training task“。通过执行此任务获得的表示可以用作我们的下游监督任务的起点。
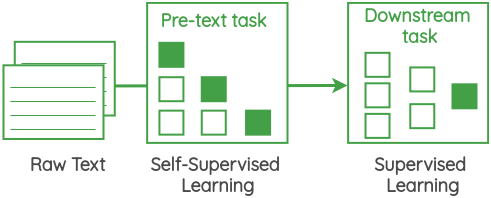
在这篇文章中,我将概述研究人员在没有明确的数据标注的情况下从文本语料库中学习表示的各种pretext tasks。本文的重点是任务的制定,而不是实现它们的架构。
自监督的方案
1. 预测中心词
在这个公式中,我们取一定窗口大小的一小块文本,我们的目标是根据周围的单词预测中心单词。
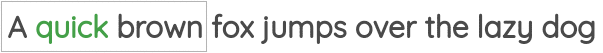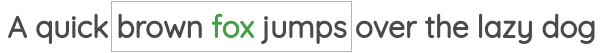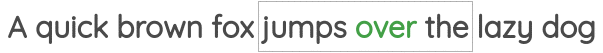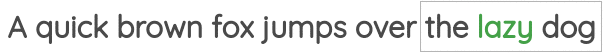
例如,在下面的图中,我们有一个大小为1的窗口,因此我们在中间单词的两边各有一个单词。使用这些相邻的词,我们需要预测中心词。

这个方案已经在著名的Word2Vec论文的“Continuous Bag of Words”方法中使用过。
2. 预测邻居词
在这个公式中,我们取一定窗口大小的文本张成的空间,我们的目标是在给定中心词的情况下预测周围的词。
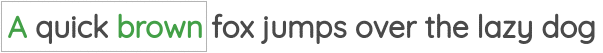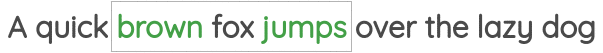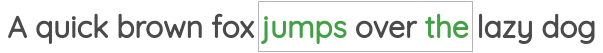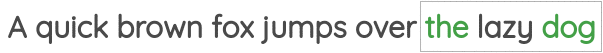
这个方案已经在著名的Word2Vec论文的“skip-gram”方法中实现。
3. 相邻句子的预测
在这个公式中,我们取三个连续的句子,设计一个任务,其中给定中心句,我们需要生成前一个句子和下一个句子。它类似于之前的skip-gram方法,但适用于句子而不是单词。
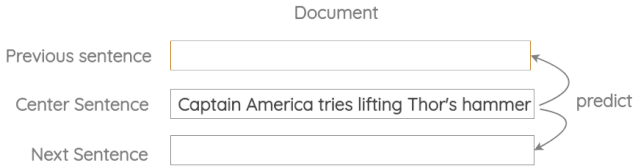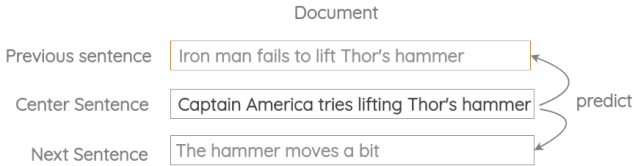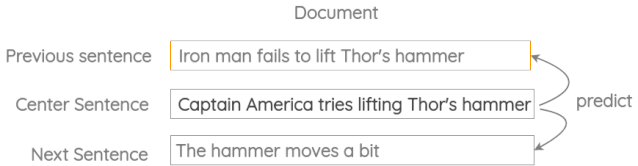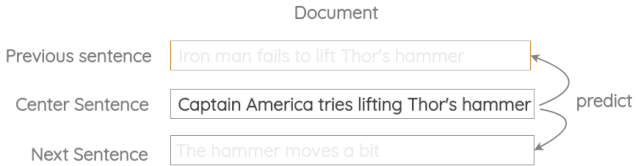
这个方案已经在Skip-Thought Vectors的论文中使用过。
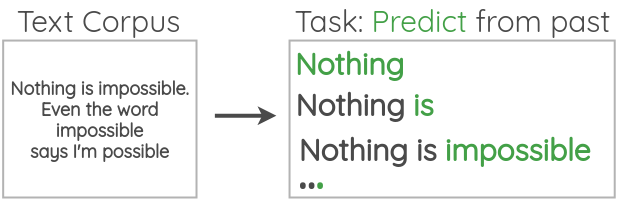
4. 自回归语言建模
在这个公式中,我们取大量未标注的文本,并设置一个任务,根据前面的单词预测下一个单词。因为我们已经知道下一个来自语料库的单词是什么,所以我们不需要手工标注的标签。

例如,我们可以通过预测给定前一个单词的下一个单词来将任务设置为从左到右的语言建模。
我们也可以用这个方案来通给定未来的单词预测之前的单词,方向是从右到左。

这个方案已经使用在许多论文中,从n-gram模型到神经网络模型比如神经概率语言模型 (GPT) 。
5. 掩码语言建模
在这个方案中,文本中的单词是随机掩码的,任务是预测它们。与自回归公式相比,我们在预测掩码单词时可以同时使用前一个词和下一个词的上下文。

这个方案已经在BERT、RoBERTa和ALBERT的论文中使用过。与自回归相比,在这个任务中,我们只预测了一小部分掩码词,因此从每句话中学到的东西更少。
6. 下一个句子预测
在这个方案中,我们取文件中出现的两个连续的句子,以及同一文件或不同文件中随机出现的另一个句子。

然后,任务是区分两个句子是否是连贯的。

在BERT的论文中,它被用于提高下游任务的性能,这些任务需要理解句子之间的关系,比如自然语言推理(NLI)和问题回答。然而,后来的研究对其有效性提出了质疑。
7. 句子顺序的预测
在这个方案中,我们从文档中提取成对的连续句子。然后互换这两个句子的位置,创建出另外一对句子。

我们的目标是对一对句子进行分类,看它们的顺序是否正确。

在ALBERT的论文中,它被用来取代“下一个句子预测”任务。
8. 句子重排
在这个方案中,我们从语料库中取出一个连续的文本,并破开的句子。然后,对句子的位置进行随机打乱,任务是恢复句子的原始顺序。
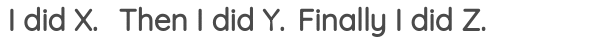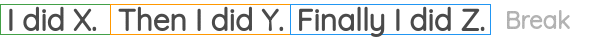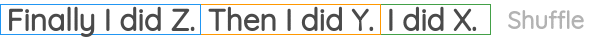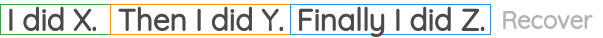
它已经在BART的论文中被用作预训练的任务之一。
9. 文档旋转
在这个方案中,文档中的一个随机token被选择为旋转点。然后,对文档进行旋转,使得这个token成为开始词。任务是从这个旋转的版本中恢复原来的句子。

它已经在BART的论文中被用作预训练的任务之一。直觉上,这将训练模型开始识别文档。
10. 表情符号预测
这个方案被用在了DeepMoji的论文中,并利用了我们使用表情符号来表达我们所发推文的情感这一想法。如下所示,我们可以使用推特上的表情符号作为标签,并制定一个监督任务,在给出文本时预测表情符号。
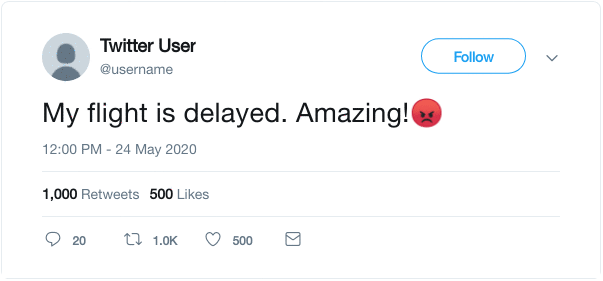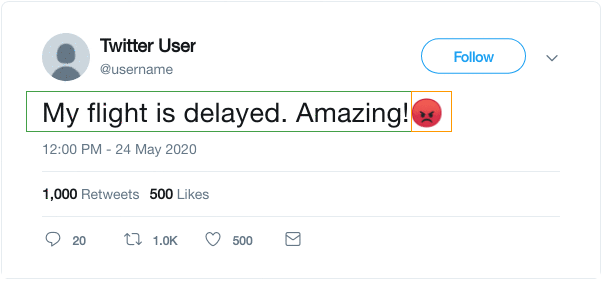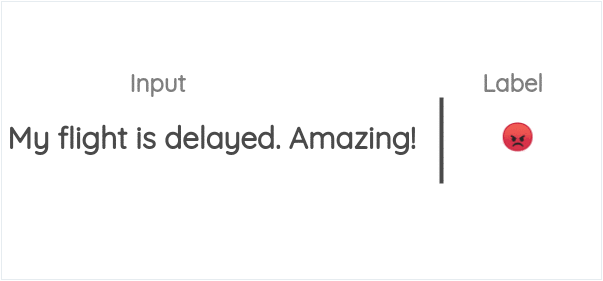
DeepMoji的作者们使用这个概念对一个模型进行了12亿条推文的预训练,然后在情绪分析、仇恨语言检测和侮辱检测等与情绪相关的下游任务上对其进行微调。

英文原文:https://amitness.com/2020/05/self-supervised-learning-nlp/
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。





