不可不知的数据科学入门数学指南
选自dataquest
想要入坑数据科学而又不知如何开始吗? 先看看这篇使用的数据科学入门数学指南吧!
朴素贝叶斯
线性回归
Logistic 回归
K-Means 聚类
决策树
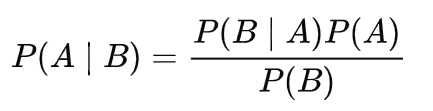
P(A|B) 是一个条件概率。即在事件 B 发生的条件下事件 A 发生的概率。
P(B|A) 也是一个条件概率。即在事件 A 发生的条件下事件 B 发生的概率。
P(A) 和 P(B) 是事件 A 和事件 B 分别发生的概率,其中两者相互独立。
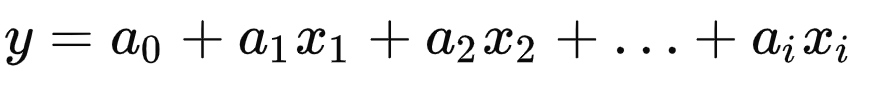
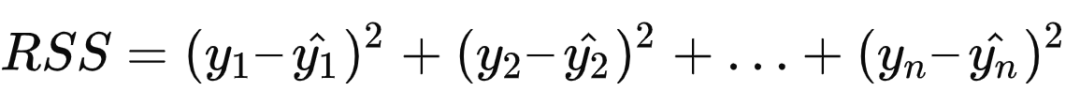
逻辑回归
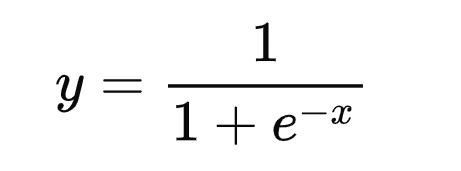
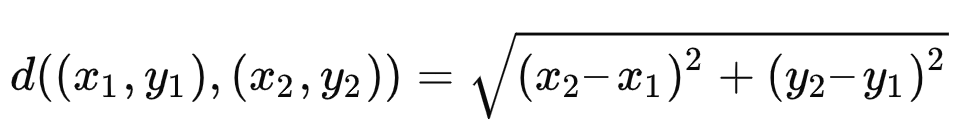
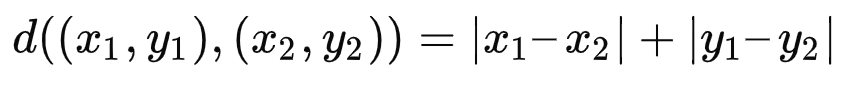
决策树
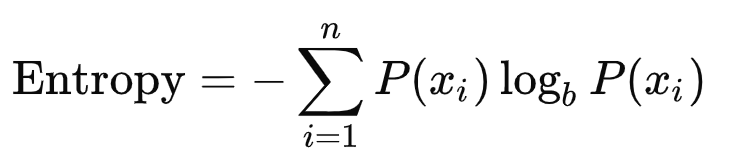
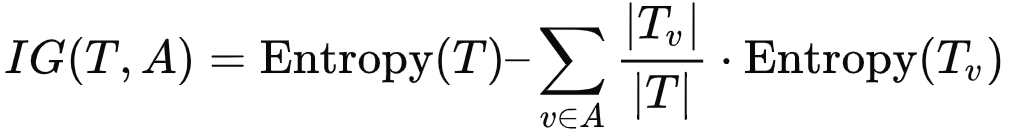
登录查看更多
相关内容

Arxiv
7+阅读 · 2018年11月15日




相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2018年11月15日