文因互联鲍捷:知识图谱发展关键阶段及技术脉络 | 公开课笔记
分享嘉宾 | 鲍捷(文因互联CEO)
出品 | AI科技大本营(公众号ID:rgznai100)
知识图谱是人工智能三大分支之一——符号主义——在新时期主要的落地技术方式。该技术虽然在 2012 年才得名,但它的历史渊源,却可以追溯到更早的语义网、描述逻辑、和专家系统。在该技术的的历史演变中,多次出现发展瓶颈,也多次以工程的方式突破了这些瓶颈。
AI科技大本营此次邀请到文因互联 CEO 鲍捷,作为知识图谱领域形成过程的亲历者之一,他对知识图谱的历史渊源进行了梳理,深度解析了该领域几次发展的主要技术突破,并分析了其工业落地的几个关键点。

鲍捷,文因互联 CEO,联合创始人。他曾是三星美国研发中心研究员,伦斯勒理工学院(RPI)博士后。他是中国中文信息学会语言与知识计算专委会委员,W3C 顾问委员会委员,中国计算机协会会刊编委,中文开放知识图谱联盟(OpenKG)发起人之一。他的研究领域涉及人工智能诸多方向,如自然语言处理、语义网、机器学习、描述逻辑、信息论、神经网络、图像识别等,已发表 70 多篇论文。
▌什么是知识图谱?
知识图谱到底是什么?坦白说我也没有特别好的答案,知识图谱从某种程度来说是一个营销名词,是 2012 年谷歌提出了这样一个项目叫“Knowledge Graph”。
一个有意思的定义是王昊奋老师提出来的:知识图谱旨在描述真实世界中存在的各种实体或概念。其中,每个实体或概念用一个全局唯一确定的ID来标识,称为它们的标识符。每个属性-值对用来刻画实体的内在特性,而关系用来连接两个实体,刻画它们之间的关联。
但是在实践中我们并不需要太过纠结什么叫知识图谱,什么不是知识图谱。有人问我说是否必须要用RDF(资源描述框架)才是知识图谱?或者说是不是必须用Neo4j图数据库才是知识图谱?其实不是。不在于你具体用了哪一种Syntax,哪一种数据存储的数据库。关键是它的本质是什么。
理解本质从了解知识图谱的演化过程入手。
▌知识图谱的演化
知识图谱这个概念是最近四、五年才为大家所知的,但是这个技术本身有非常深厚的发展基础,我把这个过程分成六个阶段,合并一下之后大概分成两个比较重要的阶段。
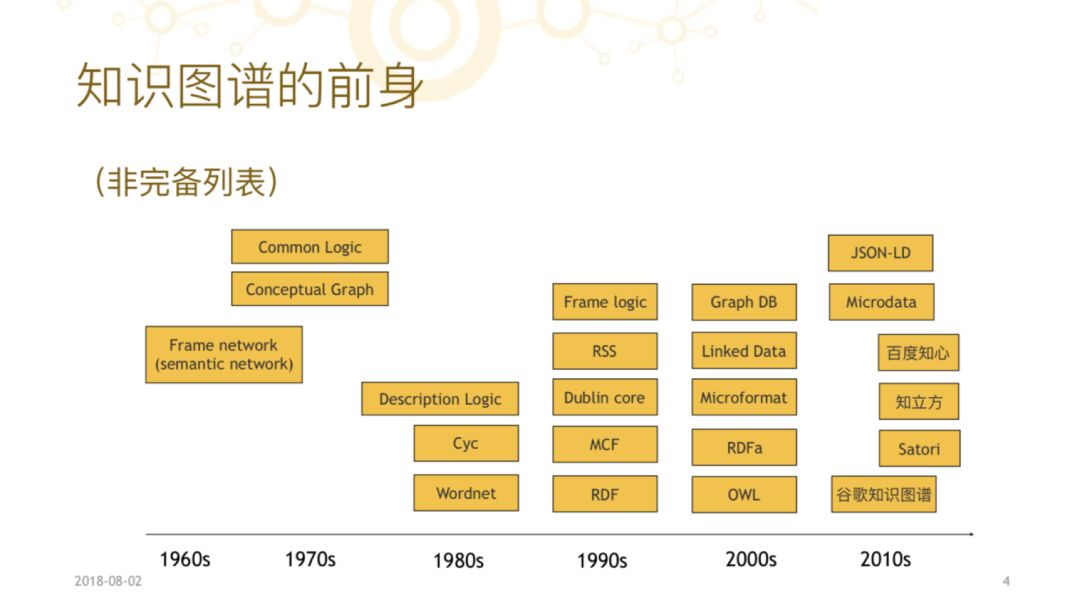
往前溯可以追溯到五六十年代前,因为在人工智能这个领域里,知识工程作为一个分支很早就有了。人工智能在大体上有三个比较大的分支,一个是神经网络,叫连接主义学派,另外一个叫统计或者经验主义学派,后来就衍生出了机器学习,最后一个知识工程这个方向,我们叫它理性主义或者符号主义,是从 1956 年这个学科形成时就有的分支。
在六十年代、七十年代的时候,知识工程这个领域往前发展,不断的产生出新的逻辑语言和新的实用方法,像描述逻辑是七十年代就兴起了的。在六十年代时就有一个叫“Frame Network”(aka “Semantic Network”),语义网络。注意,不是“语义网”而是“语义网络”,那个时候的语义网络跟现在的知识图谱非常像。所以这个是不断循环的,如果我们把六十年的学科发展抽象来看,实际上就是一个从简单到复杂、再从复杂回归简单的过程。
从最终得到的结果来看,好像我们现在得到的知识图谱跟六十年代就已经有的语义网络非常像,但这种像只是表面上的。因为在发展过程中,我们构造了一个庞大的工业体系,以及如何从各种各样的文档、各种各样的数据里集中编辑、生成知识图谱的一整套工业链。所以一个技术不能只看它的定义,而是要看它相关所有实践过程中工业体系的总和。今天知识图谱的技术无论从深度还是广度上,都远远超越六十年代的语义网络技术。
八十年代、九十年代、到两千年,这中间还有非常多中间技术,我们从中选些重要的事情说一下。
▌语义网络
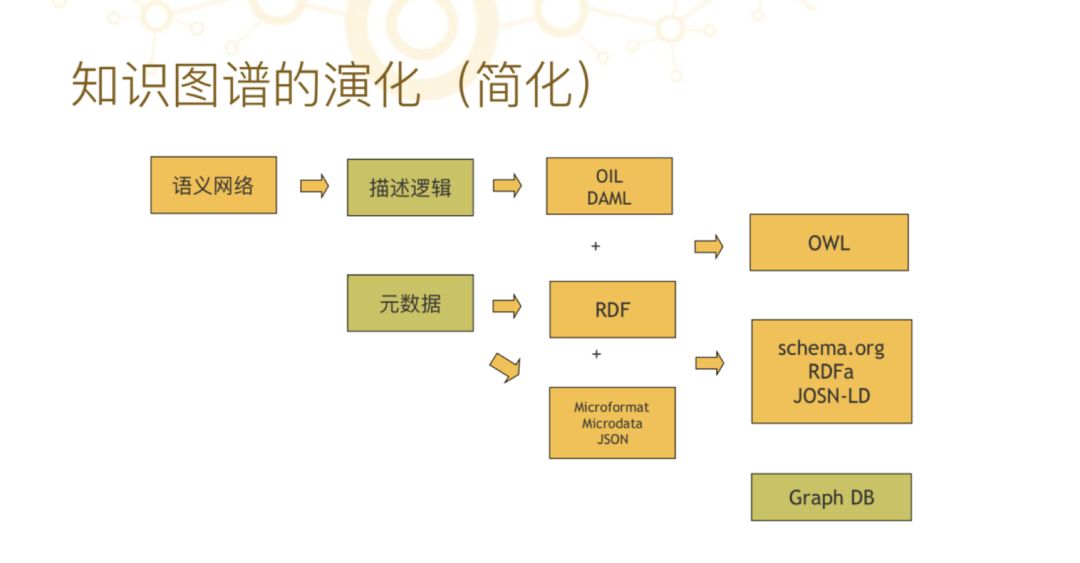
这张图是对前面那张图的抽象,我们选其中发展过程中最重要的节点。六十年代有一种东西叫“语义网络”,语义网络在七十年代、八十年代时演化成了描述逻辑。为什么会有这种变化?因为语义网络本身只是一种表征,并不具备推理能力。语义网络+推理变成了新的逻辑系统,叫“描述逻辑”,描述逻辑到两千年前后跟 Web 技术结合在一起,形成了新的语言,比如 OIL 、DAML。
另外一个分支是 1995 年前后有了元数据,从元数据学科衍生出一个分支叫 RDF,后来 RDF 和 DAML 合并起来就变成了 OWL。下面还有一些更工程的内容,包括 schema.org、RDFa、JOSN-LD、GraphpDB,这都是最近 5、6 年兴起的新技术。这些技术的总和就构成了我们所称的“知识图谱”技术,但只是其中一部分。
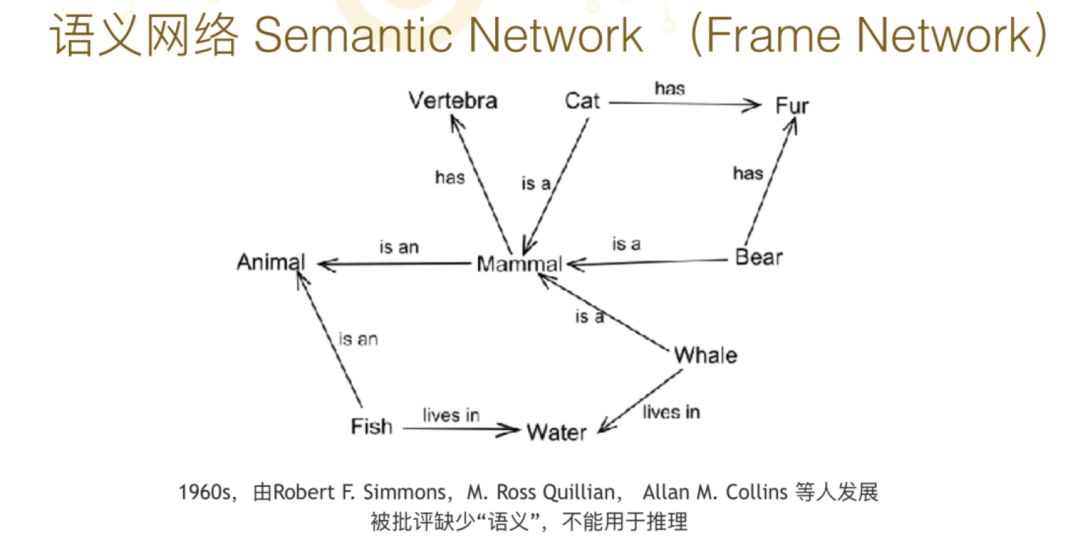
给大家看一个语义网络,语义网络其实就是一个网络。这张图上有各种不同的概念,比如中间的 Mammal 是哺乳动物,猫(cat) 是一种哺乳动物,猫有毛;熊是哺乳动物,熊也有毛;鲸是一种哺乳动物,鲸在水里面生活;鱼也在水里面生活,也是一种动物;哺乳动物是一种脊椎动物,也是动物的一种。
所有这些节点和边的总和就构成了一个网络,每一条边上都有一些标志的,用术语来说就是“有类型的边”,这种“有类型的边”连在一起的节点叫“语义网络”,概念是非常简单的。
六十年代时自然语言处理和知识表现的大拿批评这种语义网络,说这个东西没办法用于推理,用术语来说是最后没有“semantics”。这里涉及很多关系,什么叫 semantics?有的学者认为 semantics 必须是有一套严格的语义定义,这通常是用模型论来定义,或者过程方法来定义。其实也有更浅的对语义的理解,万事万物之间的关系就是语义。比如我们打开字典,字典是用一些词定义另外一些词,这就是语义。
我们在这样的语义网络里,如何定义一个词的意义?其实我们是做不到的。比如在这个语义网络里,居于中间位置的词是“哺乳动物”,它到底是什么?我们很难让计算机理解什么是真正的哺乳动物,很难通过它的内涵含义来理解。对于计算机而言,它只能知道万事万物之间的联系,也许这对于机器自动处理来说就够了。所以语义网络尽管没有所谓的语义,我们还是把它称为语义网络的原因,因为语义就是关系。
▌描述逻辑
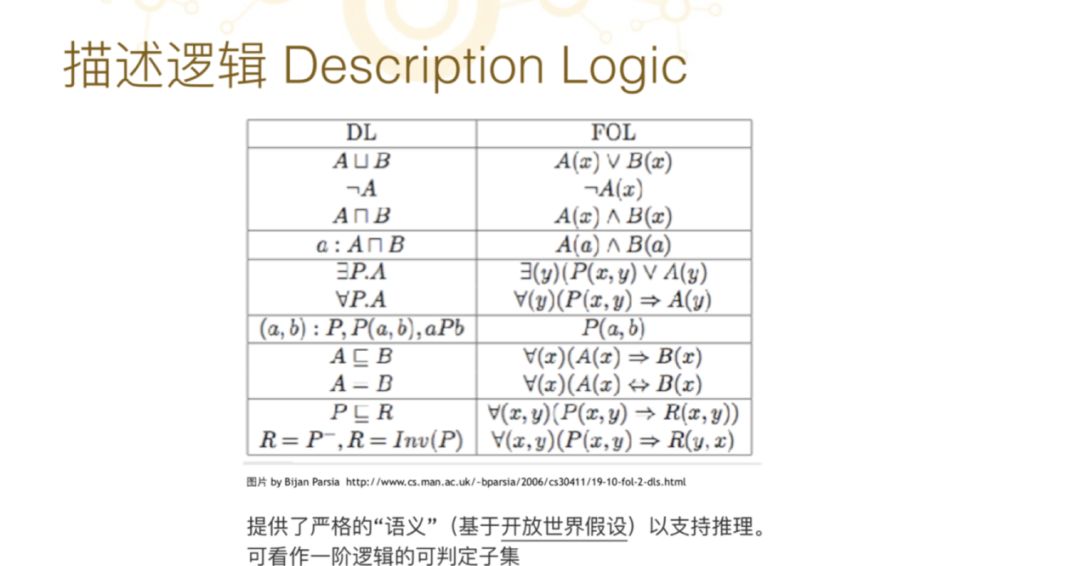
到了八十年代时,描述逻辑就已经比较成熟了。描述逻辑是逻辑的一种,我在这里面列了一张表,这是描述逻辑和一阶逻辑 (FOL 逻辑)之间的对应。如果大家没有逻辑基础也不用害怕,因为这个图本质上是讲很基础的逻辑定义。
我们有了一个描述逻辑之后,就可以用计算机来做一些自动推理的工作。八十年代到九十年代,描述逻辑学者们一直都在寻找如何让计算机更好的进行逻辑推理,一些比较可判定的所谓计算机不会死机的那些问题的总和,这种语言称为“描述逻辑”。
▌OWL
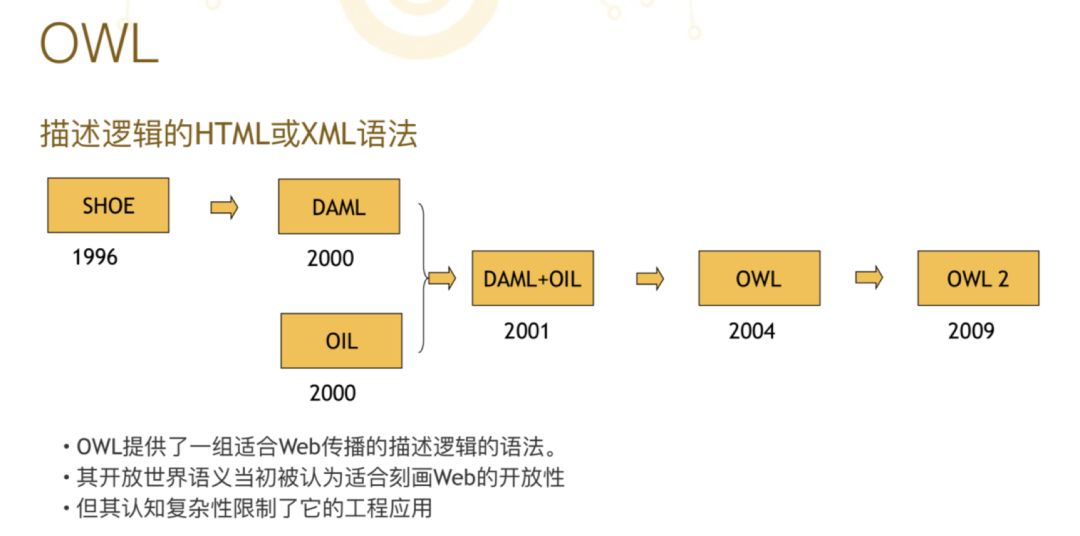
到九十年代时描述逻辑成为知识表现领域的一种非常显学、非常重要的分支,正好这时互联网兴起了。到了 1995 年前后开始了真正知识图谱化的第一步,开始把描述逻辑用互联网的语言来重新来表征,有人用 HTML,也有人用 XML。1999 年马里兰大学开始发布了第一个这样的语言,叫“SHOE”。后来这个语言被美国的国防部高等研究所资助了一个项目叫“DAML”,这就是第一个在美国这边把知识表现语言放在网上一种官方的努力。
与此同时,在欧洲也有一个非常相似的努力叫“OIL”,大西洋两岸的同行们一看,大家做的事情非常相似,于是在 2001 年时 W3C 开始把两边的努力汇总在一起,出现了一个语言叫“DAML+OIL”。到了 2004 年时 W3C 进一步协调大家的努力,合并了一个新的语言叫“OWL”,2009年发布了第二版,叫“OWL2”。
从九十年代到 2009 年这十几年期间,这个领域不断向上、向好积极发展,在那个时候我们曾经认为 OWL 是描述这个世界非常好的一种工具,因为它对于机器处理是非常友好的,所以我们就希望把它放到互联网上去,让更多人用到,但是这个设想后来并没有实现。
▌W3C OWL 工作组的瓶颈
这里多说几句 OWL,因为我是 OWL 工作组的一员,所以知道一些早期的事情。OWL有两个工作组,最早的一个工作组是在 2000-2004 年之间,我赶上的是 2007-2010 年的第二个工作组,这个工作组的使命是把现有的 OWL 语言进一步完善,提供所谓更强的表达力,或者在机器处理上比如要进行语义数据的查询,我们应该用什么样的,什么可以用、什么不能用、什么能说、什么不能说、什么对机器是友好的,OWL 工作组就是做这个事情。
我们写了 10 来个文档,加在一起 600 多页纸,花了两年时间做这个事情。OWL 工作组除了大学里来的人,还有一些企业的成员,包括 IBM、Oracle、惠普等等,还有一些小的创业公司。
那个时候我们这个领域遇到了一些瓶颈的,就是 OWL 这个语言或者语义网整个领域,在 2000 年前后是大家非常寄予厚望的,就好像现在大家对于深度学习寄予厚望一样。但是往前走到 2006 年前后遇到了瓶颈,就是没有人真的去产生这样的数据,大多数日常场景用不到语义。于是这时候就产生了内部的路线斗争,叫“SEMANTIC Web or semantic WEB”,就是到底我们是加强语义呢?还是加强互联网属性呢?有两组不同的人不断进行争执。
当然,还有很多其他的分歧,包括我们到底该怎么去定义什么叫“简单”,大家没有一致的意见。所以我们最终生成的文档从学术角度来说是非常有价值,但是对于工业应用特别是 C 端的互联网应用没有达到预期。
小结 :从弱语义到强语义的尝试(逻辑)
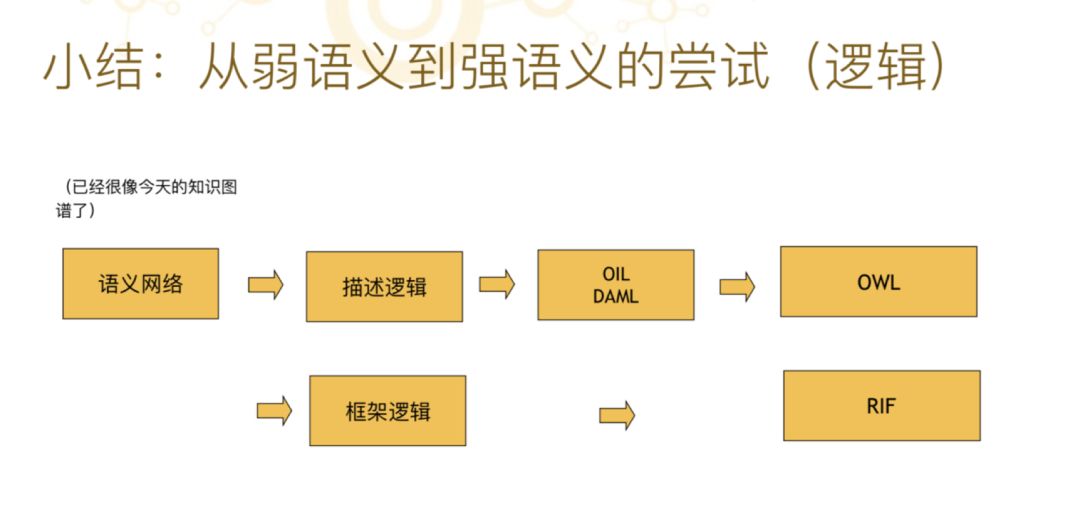
前面这一段大体总结了知识图谱技术发展的前两个大的阶段历史,一个是从六十年代到九十年代,早期知识图谱的原型,包括语义网络等等,后面一系列的技术。
从 2001-2006 年或者 2007 年这段时间,是不断加强语义网所谓的语义的过程,就是从弱语义到强语义,从语义网络到描述逻辑,一直发展到 OWL,并行还有另外其他一些,比如基于框架逻辑还有另外一个语言叫“RIF”。这十几年时间都一直不断在加强语义表现的表达力,但最后证明这个做法是不太妥当的。
▌元数据框架到 RDF
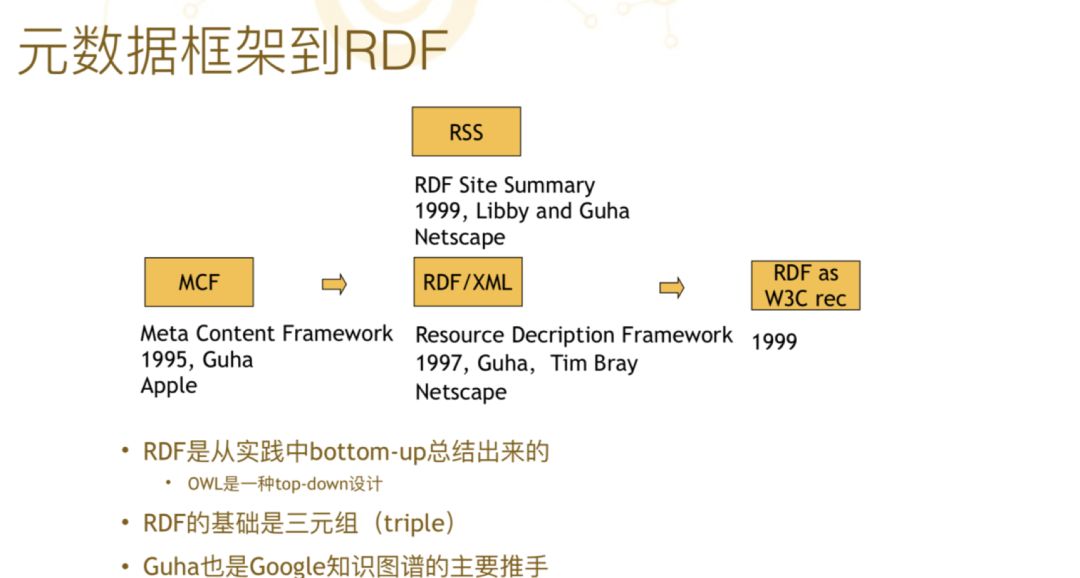
我们讲过,除了学术性非常强的描述逻辑 OWL 分支之外,知识图谱还有另外一个分支是来自于元数据框架的。这个工作最早是 Guha 在 Apple 做的,Guha 这个人是非常值得关注的,因为某种程度上他是“知识图谱之父”,在 1995 年时他在 Apple 发明了一个语言叫“MCF”,因为他那时候面临一些问题,就是怎么去表征多媒体的数据,特别是图像的数据,所以他就发明了一整套的元数据表征方法。
到了 1997 年时 Guha 跟Tim Bray 做了 RDF/XML。1999 年网景公司发明了 RSS 语言,这个东西现在新一代的朋友们不一定知道了,回到 10 年前时看新闻都是用 RSS 订阅的,其实 RSS 的第一个 R 就是 RDF。后来他们改了其他的名字,从本源上来讲,技术刚刚开始的时候这个技术是 RDF 的应用。1999 年 RDF 被 W3C 收编了,变成了国际标准。
▌RDF
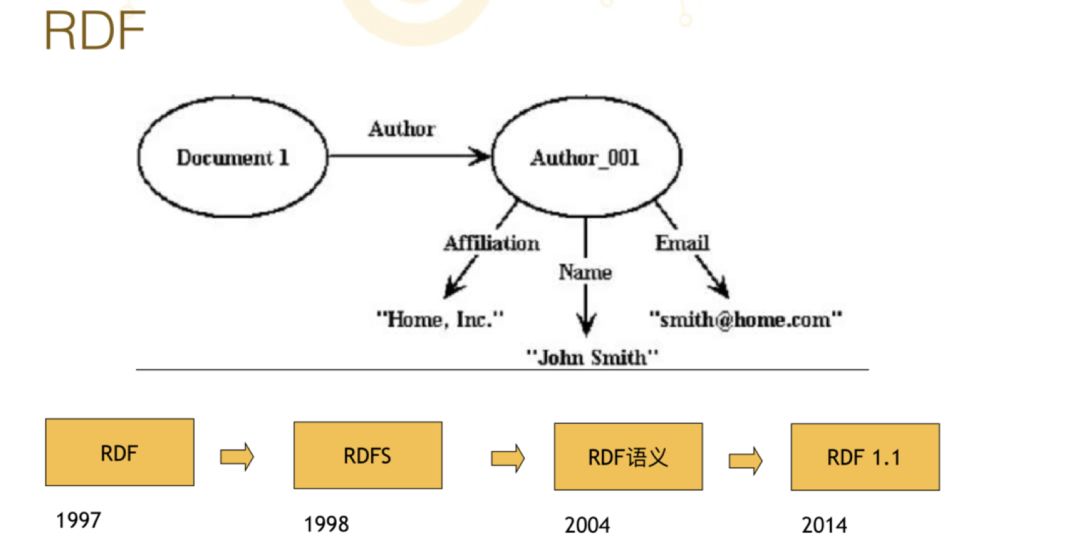
什么是 RDF?这里给一个例子,它是非常简单的语言,本质上是三元组,主语、谓语、宾语就是个三元组。比如“我叫鲍婕”,“我”是主语,“是”是谓语,“鲍捷”是宾语。在 RDF 这个框架下,万事万物各种复杂的关系最后都被拆分成三元组,如果从图形来表示,三元组就是一个主语、一个谓语,中间有一条线一个箭头是宾语,可以把各种各样的模型都分解成这样的三元组。
从 1997 年有了 RDF,1998 年有了 RDFS,2004 年逻辑学家给 RDF 加了一个语义,因为他们认为 RDF 必须要能够推理,所以 2014 年进一步加强,最后有了 RDF1.1,这是 RDF 大概 20 多年的发展史。
小结:从弱语义到强语义的尝试(元数据)

RDF 和一开始提到描述逻辑方法是不一样的,因为描述逻辑方法是从实验室里来的,它想构造一个庞大的体系,构建一个完美的知识表现语言,然后再寻找它的落地。
而 RDF 从一开始就是一个从实践出发的、自底向上的一个语言。RDF 相对于 OWL 而言,是一个更加偏工程的、应用更多的语言,现在有很多人在用 RDF。我们日常生活中所遇到的绝大多数网站,现在都有某种类型的元数据,其中相当一部分就是用 RDF 不同的变种来实现的,所以 RDF 总的来说是一个比较成功的技术,因为它是来自于现实的技术。
▌关联数据 Linked Data
从 2001 年这个领域正式形成,到 2006 年时语义网的技术堆栈已经变得非常复杂了。1999 年时有一个所谓的“语义网蛋糕模型”,对语义网不同的技术做了罗列。2006 年时语义网技术已经复杂到没有人看得懂,没有办法用二维表达,必须用一个三维的图才能够把语义网所有的技术放在里面。这就带来了一个严重的问题,就是绝大多数的企业、开发者很难理解,无从下手。
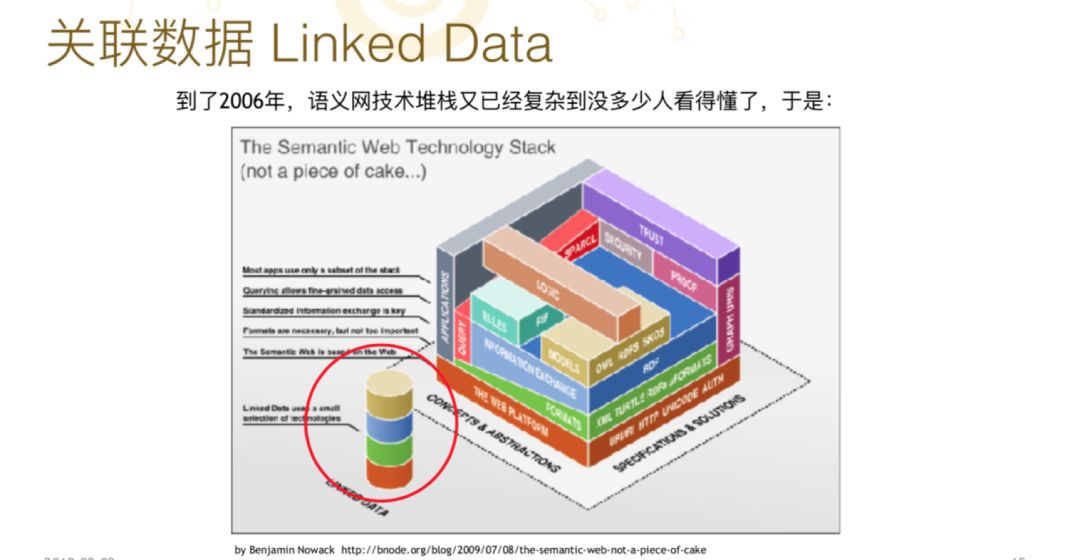
到了 2006 年时我们的“神”Tim Berners-Lee 出来思考这个问题,他想与其要求大家现在把数据搞得很漂亮,不如让大家把数据公开出来。只要数据能够公开出来,数据能够连在一起,我们就会建立一个生态,这套想法他称为“关联数据”。

他提出了数据发布的基本原则,上图是我从他的博客上面提取出来的,我也非常推荐大家好好看他的博客“Design Issues”,Tim Berners-Lee 会提前 20 年时间去想人类的未来是什么样的,我们的 Web 到底应该遵循什么样的原则。
在关联数据的定义上,他定义了几层什么是好的关联数据:第一是在网上,一颗星;二是机器能够自动读,这就有两颗星;三是尽可能用一个公有的格式,不要是某个公司私有的,这样能够促进公开交换,做到这点就有三颗星;因为是 W3C 提出来的,必须用 RDF,用 RDF 就有四颗星;如果 RDF 有 ID 把它连在一起就是五颗星。这就是 Tim Berners-Lee 提出的关联数据的五星标准。
小结:从强语义到弱语义的尝试(关联数据)
2006 年之所以 Tim Berners-Lee 要推进这个转变,就是因为他当时看到了有些风险。语义网的头 5 年时间并不是特别成功,因为没有人愿意发布数据,这时候 Tim Berners-Lee 出来带领大家调整方向,不要再去强调很强的语义和推理了,可能一个比较弱的语义或者一个结构化本身就已经足够了,这就是 Tim Berners-Lee 用“关联数据”概念再次盘活了这个领域。
▌新的综合:交换语言
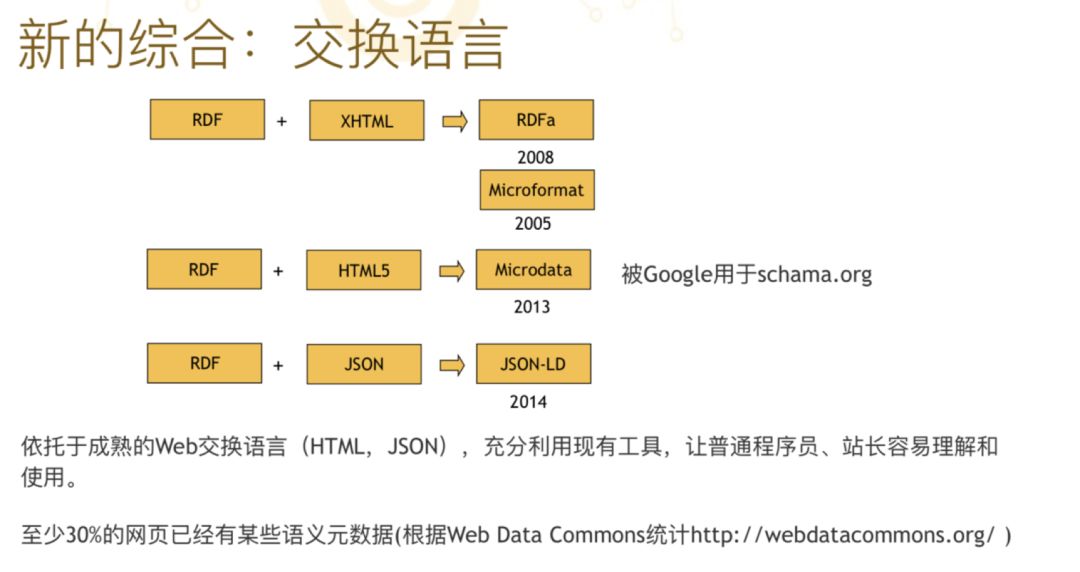
这张图上总结了知识交换语言一系列的发展,刚才提到 RDF,RDF+HTML,变成了 RDFa,还有另外一种叫 Microformat,这都是非常多网站上已经用到的元数据语言。RDF+HTML5 就变成了 Microdata,RDF+JSON 就变成了 JSON-LD。所以传统的 RDF semantics 就是基于 XML 的 semantics,现在不太多见了,因为那个东西非常复杂,学习成本非常高。
现在我们看到的大部分 RDF 从概念上是 RDF 的变种,但是语法形式在网站上打开元代码看都有元数据。大概 3 年前统计,有 30% 的网页已经有语义数据了,现在应该至少超过一半的网站都有语义数据,所以 RDF 是很成功的一个东西。
▌新的综合:存储语言(图数据库)
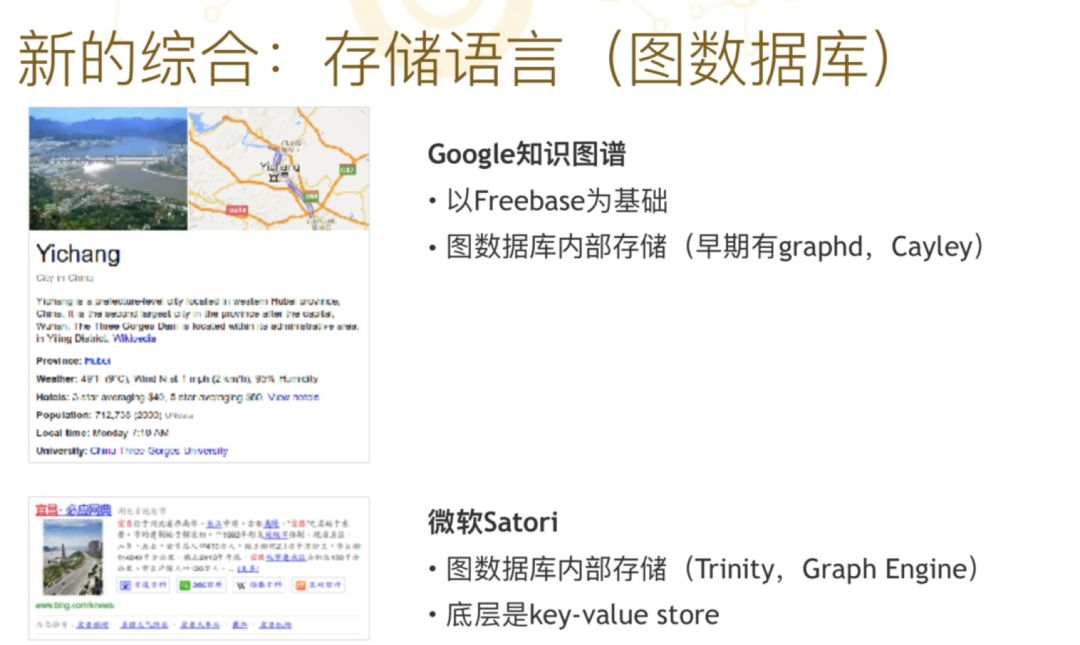
当数据多了以后面临另外一个问题,就是如何去存储和操作知识图谱的应用数据。大公司和小公司各自有自己不同的解决方案,统称为“图数据库”。为什么语义网的数据库称它为“图数据库”?前面几张 PPT 讲到 RDF 时,其实 RDF 就是各种事情之间的关联,我们把这种关联画出来,变成很大的一个图,很自然的就用图数据库进行知识图谱的存储。所以谷歌、微软各个大厂都有自己的图数据库,至少是定制化的数据库。
图数据库这件事情上后来产生了两个新的流派,一个流派叫“RDF 数据库”,另外一个叫“属性图数据库”,虽然同样是图,但两种数据库关联系统的定义是完全不一样的。因为 RDF 这种图本质上强调推理逻辑;而属性图要放开很多,而且属性图发展过程中工程化做得非常好。
小结:从强语义到弱语义的尝试(图数据库)
在图数据库的尝试当中,我们再次把语义给弱化了,从强语义到弱语义,因为如果我们用强语义就用 RDF 数据库,如果我们允许有弱语义就可以用图数据库。最后证明,图数据库的发展速度远远快于 RDF 数据库。所以从实践当中总结出来的东西总是有生命力的,如果只是基于纯理论的思考设计出来的东西通常是没有生命力的。
Lean semantic Web

在整个领域发展过程中,我慢慢也有一些思考。后来我有一个博客叫“语义噪声”,这里记录了很多我对语义网大大小小事情的想法。那天统计了一下,加在一起大概有 300 多页纸的内容,如果有空了会整理出来给大家看。
这里我列举了一些跟今天讲课内容关系比较紧密的东西,包括为什么语义网会不断的去简化,为什么链接数据最后要演化成所谓的知识图谱。我之前的博客里都写过,欢迎大家去看一看。
还有 github 上,大连理工大学的耿新鹏博士把我博客文章整理到 github 上了,大家不用翻墙就可以看得到了。
▌总结
其实知识图谱从 2012 年谷歌提出之后,它进入了新的综合的过程。知识图谱在理论上并没有特别大的进步,因为这些工程包括逻辑推理几十年来一直都是这样。进步的地方在哪里?通过实践发现,我们要想实现一个人工智能非常复杂的分支,其实是没有办法用那种学院派办法来做的。我们只有理论结合实际,甚至从实践中出发总结出产品来、总结出语言来,这样东西的生命力远远大于一群专家坐在屋子里讨论出来的。
知识图谱的领域从 2006 年往前一直不断从弱语义到强语义的发展过程中,这个阶段最后被证明是不太成功的。2006 年之后这个领域不断的强调工程、强调应用、强调数据、强调跟实践最相关的东西,语义也进一步弱化,又从强语义再次回归到弱语义。2012 年谷歌的知识图谱是完全抛弃掉语义的。
从二十年来的历史表明,从实践中总结的方法要优于从顶向下设计的方法。如果你有一个很好的想法或者一个很好的语言,并不能保证别人就能够用起来,除了要贴合用户的需求之外,还有大量工具工作和生产工具的工作,这就形成了产业链。
所以在知识图谱领域,我们不能狭隘看它的某一种语言或者某一种技术,它是一个体系的,就是一大堆结构化数据从生产到存储到检索的全流程工具丰富程度,才决定这个技术能不能落地。简单的优于强大的,太过复杂的比如 OWL 最终用不起来,反而比较简单的的像 RDF、最近比较火的 JSON-LD 用得越来越多。越简单越好,这就是 20 年来最核心学习到的东西。
▌展望
知识图谱从 2015 年之后,就在实践中应用越来越广泛。经过这几年培育,在不同的领域里,像医疗、法律、金融都已经有比较好的公司建立起市场口碑了。相信知识图谱还会向更多其他的垂直领域进行渗透。
我们这几年时间最主要的工作,不管在中国,还是在美国,都是促进了知识图谱工具的建设。这是我今天晚上第三次强调工具了,如果你离开一整套的工具链条的话,比如校验工具、编辑工具、检索工具、推理工具,开发是非常难做的。
知识图谱本质上来说是一种程序,它是为了机器理解世界是什么时写的一种程序。知识工程和软件工程一样,需要很多人在一起协作才能够做好。我们经过这几十年软件工程总结出一整套的打法来,可以让比较笨的人或者专业度不那么强的人,也可以去做开发工作。对于知识工程而言,目前没有达到那个点,这就是为什么知识工程那么贵的原因。但是我相信今后一段时间内工具的建设会不断改善,我们自己也在做一些工具,将来会提供给大家用。
▌相关资料
下面是是跟语义网有关的参考资料,我刻意没有去列近期的东西,因为绝大多数重要的东西在 2012 年前就有了,2012 年之后的东西没有那么太必要搞明白,我们优先把这个领域本源的东西看一下,相信对大家是有价值的。如果大家对英文还 OK,我建议大家读读 W3C 一系列标准,包括 RDF 有一个入门指南写得非常好,OWL 也有一个入门指南是我参与写作的。
总的来说,到目前为止知识图谱在中国没有特别好的书来讲,王昊奋、漆桂林、陈华钧老师他们正在写。其他的包括知识抽取、知识检索工具的总结在W3C上也有,欢迎大家去看一看,可以解惑。
The Semantic Web
知识表示 + 知识推理理
RDF:https://www.w3.org/TR/2004/REC-rdf-primer-20040210/
RDFa: https://www.w3.org/TR/rdfa-core/
JSON-LD: https://www.w3.org/TR/2014/REC-json-ld-20140116/
RDFS:https://www.w3.org/TR/2014/REC-rdf-schema-20140225/
OWL:
https://www.w3.org/TR/2004/REC-owl-features-20040210/
https://www.w3.org/TR/2012/REC-owl2-primer-20121211/
Prov:https://www.w3.org/TR/prov-overview/
More Inference & Reasoning:
RIF:https://www.w3.org/TR/rif-primer/
SPARQL based reasoning: http://vos.openlinksw.com/owiki/wiki/VOS/VirtSPARQLReasoningTutorial
Description Logic Primer: https://arxiv.org/abs/1201.4089
知识检索
SPARQL:https://www.w3.org/TR/sparql11-overview/
SPARQL Tools: https://www.w3.org/2001/sw/wiki/SPARQL
知识抽取
Information Extraction:
https://web.stanford.edu/~jurafsky/slp3/21.pdf
NER:
http://www.cfilt.iitb.ac.in/resources/surveys/rahul-ner-survey.pdf, https://nlp.cs.nyu.edu/sekine/papers/li07.pdf
Entity Linking:
http://dbgroup.cs.tsinghua.edu.cn/wangjy/papers/TKDE14-entitylinking.pdf
Book: https://www.w3.org/2001/sw/wiki/Books
答听众问:
Q:请问 cat 和 cats 是两个不同的对象吗?如果是,cat 的 has是不是在 cats 中变成 have 了?
A:通常我们在知识建模时不太会有 cats 这个概念,一般来说只有 cat 这个概念,因为 cat 本身就是一个集合,那个集合本身就意味着它有可能是多个元素组成的集合。
Q:图情学中的知识图谱 mapping knowledge domain 与人工智能中的知识图谱有什么关联?
A:这是个非常有趣的问题,因为我刚刚回到中国时搜知识图谱,搜到的文章都是图书馆学上面的,这两个技术从内涵、外延、历史都没有关系。
Q:能不能将机器学习中的特征通过某种映射,使其成为高维向量,从而和知识图谱的 entity 和 event 结合起来,这个映射的高维向量如何训练比较好?
A:这个问题非常专业。在知识图谱的学习过程中确实有向量的表示方法,目前比较多的实践是基于深度学习的方法,但这很复杂的,很难用一句话来解决,特别是映射的高维向量如何训练比较好,这件事情可能要离线的看看论文,我推荐大家看刘知远老师的工作,国际上他在这方面做得最好的。
Q:请问语义定义如果是关系,但是语义类的相交并不代表语义中包含实体的属性全包含,该如何区分呢?
A:“如果语义定义是关系”这是一个不严格的定义,你后面说的“语义类的相交并不代表包含实体的属性全包含”是一个强语义的关系,一个是讲弱语义,一个是讲强语义,其实我们不太做这种区分。
因为当我们认同弱语义定义时,在工程上是允许各种特例存在的,因为一旦进行强语义建模时,一方面是精确,但重要的是成本升上去了,所以我们在不精确和成本之间做一个衡量,这个问题不是太重要,不用抠这个字眼。
Q:强弱语义有定义吗?有标准吗?
A:“强语义”、“弱语义”是我自己杜撰出来的东西,目前应该没有官方的定义吧。根据我自己的定义,如果你是依靠描述逻辑的,我们称它为强语义。如果没有的话,像图数据库、属性图,就是弱语义。
Q:知识图谱如何可以运用到移动端产品中?有哪些好的应用案例可以讲讲?
A:Siri 这种问答引擎,现在几乎所有语音助手类的产品背后都有知识图谱。大家在淘宝上会遇到机器人客服,就是因为后面有商品类的知识图谱。大家日常生活各行各业、各个方向目前都已经被知识图谱影响到了。比如大家用智能音箱,你可以跟它对话,这件事情能发生就是因为有知识图谱。像我们在做金融的应用,所有的股民也都是被知识图谱服务到的。
各行各业都有,至于是不是移动端的产品,当有人问我某某领域或者某某产品能不能用到知识图谱的话,我都会说“能”,知识图谱是数据库往前的一个延伸,所以一定能够用得到。
Q:2015 年之后出现过哪些开源的知识图谱工具?
A:我觉得之后的这两年没有看到特别好的知识图谱工具,更多都是很早之前就有了。但在 NLP 上还是有很多发展的,最近很多老师做了开源的工作,像刘知远做了向量化的学习、表征学习都开源了,这是很好的工作。传统的语义网应该没有太多新的工具,主要是集中在知识表现、知识提取方面。
Q:知识图谱的典型应用是什么?对自然语言处理有什么关联和促进吗?
A:知识图谱的典型应用,像问答是最典型的,像流程自动化、客服,像我们现在做的自动化监管、自动化审计、自动化报告,总之,凡是需要结构化数据的地方都是知识图谱的应用。
对自然语言处理有什么关联和促进?自然语言处理里一个细分分支是知识提取,知识提取是知识图谱生成的前提条件之一,这是两者之间最主要的联系。就像知识计算专委会是放在中文信息协会下面的,有这个历史渊源。
Q:知识图谱入门从何学起,有什么好的教学视频或者书吗?
A:小象学院上王昊奋做了第一期的教学视频,后来其他老师在做第二期,大家可以从那开始看。
Q:从文本到知识图谱比较关键的技术是什么?前期的 schema 对知识图谱建构的影响有多大?
A:比较关键的技术是关系抽取、实体链接技术。前期的 schema 对构造的影响有多大?这个见仁见智,有些特别强调 schema top down 设计的人,他们可能认为对这个问题的影响比较大。从我自己的工程实践来说,我觉得影响不大。
Q:在垂直领域构建知识图谱,有没有经验性的套路?
A:总的来说,先做搜索,然后再做实体抽取,然后再把实体连在一起,这是最常见的套路。
Q:知识表示有哪些方法比较常用?
A:知识表示就是各种结构化的方法,从逻辑上来讲,大体有两大类,一块是描述逻辑,另外一块是 Logic program,这是从学术角度的知识表示最常见的,或者一套是更偏数据库的方法,一套是更偏互联网的方法,具体很难讲得清楚。
Q:基于知识图谱的问答有什么特定的流程吗?
A:大体流程都是先做语义理解,然后把语义理解的结果变成一个结构化表示,然后再把中间的结构化表示映射到数据库上去,形成一个查询计划。细节都各家不同,但大的原则都是这样子。
--【完】--
转载声明:本文转载自「AI科技大本营」,搜索「rgznai100」即可关注。
添加微信群小助手微信号 wenyinai42,附上姓名、所属机构、部门及职位,审核后小助手会邀请您入群。

文因商务合作
请另联系微信号:wenyinba



