摘要
近年来,图上的无监督网络表示学习(unsupervised network representation learning,简称UNRL)方法取得了显著进展,包括灵活的随机游走方法、新的优化目标和深度架构。
然而,没有一个共同基准来系统地比较嵌入方法来理解它们对于不同的图和任务的性能。我们认为,大多数的UNRL方法不是建模和利用节点的邻域,就是我们所说的节点上下文信息。这些方法在定义和对上下文的利用上有很大的不同。
因此,我们提出了一个框架,将各种方法——基于随机游走、矩阵分解和基于深度学习——转化为一个统一的基于上下文的优化函数。我们根据这些方法的异同对它们进行了系统的分类。我们将研究它们之间的差异,稍后我们将用这些差异来解释它们(在下游任务上)的性能差异。
我们进行了一项大规模的实证研究,考虑了九种流行的UNRL技术和11个具有不同结构属性的真实数据集,以及两个常见的任务——节点分类和链接预测。
我们发现,对于非属性图,没有一种方法是最好的,合适的方法的选择取决于嵌入方法的某些性质、任务和底层图的结构性质。此外,我们还报告了在评价UNRL方法时常见的缺陷,并对实验设计和结果解释提出了建议。
https://www.zhuanzhi.ai/paper/3bff20b724a72f2f8ae5f17cfc0b7ce9
引言
在过去的五年里,无监督的网络嵌入方法在图上又有了发展,[10],[19],[21],[30]。这主要是由于使用基于神经网络方法的建模和优化技术的改进,以及它们在各种预测和社会网络分析任务中的效用,如链接预测[13],顶点分类[6],推荐[35],知识库补全等。
尽管这些方法取得了成功,但目前还缺乏对不同嵌入方法之间差异的深入系统研究。以往的工作主要集中在利用统一的理论框架[14]、[22]来研究不同嵌入方法之间的相似性。正如我们在实验中所展示的(参见第7节),每种新方法的评估研究主要集中在它们表现良好的实验机制上,而忽略了它们可能表现欠佳的场景。据我们所知,在不同实验条件下比较这些方法的综合性大规模研究完全缺失了。因此,一个基本的实际问题在很大程度上仍未得到解答:从比较的角度来看,对于不同的图类型和不同的下游任务,哪一种节点的无监督网络表示学习(Unsupervised Network Representation Learning, unl)方法是最有效的?
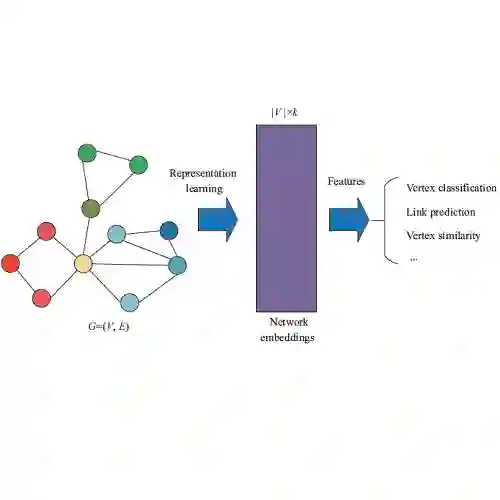
在本文中,我们首先提出了一个共同的框架来填补这一空白,该框架聚焦于不同的UNRL研究方法之间的差异。其次,我们使用九种嵌入方法(参见表2),使用不同的范式——随机漫步、边缘建模、矩阵分解和深度学习——包括一些最早的学习网络表示的方法,到最近的基于深度学习的方法和11个数据集(参见表3)。在本工作中,我们只考虑转导场景中的无监督方法。
我们理解非监督学习方法的共同框架是受到这样一种观察的启发:大多数非监督学习方法都是在一个辅助邻域图上运行的,在这个辅助邻域图中,相似的顶点共享一条边。我们称这样的图为上下文图,对于任何源顶点v,它的单跳邻居称为上下文。根据嵌入方法,一个顶点可以与另一个顶点相邻,可以通过截断随机游走到达,或者是在同一个社团/簇中等等。在本文中,我们在我们的统一框架中研究了各种各样的方法-例如,在我们的统一框架中使用随机游走[6],[21],[30],[37],邻域建模[28],矩阵分解[19],[22]和深度学习[7],[32],这些方法可以被理解为优化在各自的上下文图上定义的通用形式的目标函数。这使我们能够理解这些方法之间的差异,这些差异是由于它们对上下文的建模而产生的。
在本研究的评估中,我们探讨了不同嵌入方法之间的概念差异,从而导致下游任务的表现差异。首先,使用具有不同结构特征的图,我们讨论了几种方法的效用。我们从社交网络、论文引用网络和协作网络中精心选择了11个具有不同属性的大型网络数据集(5个无向数据集和6个有向数据集)。为了关注复现性和大规模的分析,我们在四个受欢迎的任务——节点分类, 链接预测、聚类和图像重建进行实验。此外,除了对大量模型进行大规模研究外,我们还发现早期方法的实验设置存在局限性。特别是,在有向图的情况下,早期的工作大多只检查一对节点之间是否存在一条边,而忽略了这条边的方向性。
我们的研究强调了不同图和任务特征下方法的优势和劣势。我们相信,我们的研究结果可以作为研究人员和行业从业者在选择广泛的嵌入方法时的指南。我们研究的一些关键发现如下:
-
在有向图的链接预测中,建议在学习表示以及在任务中使用顶点作为源和有上下文的角色的方法。
-
在选择具体的方法时,建议考虑聚类系数、传递性、互易性等结构性质。
-
一个简单的基于直接邻域的分类器可以为许多数据集提供更好的或可比的性能。