基于知识图谱的推荐系统总结
| 作者:阳光明媚
| 单位:华东师范大学
摘要
1 引言
在信息爆炸的社会,人们面对的信息量呈指数级增长。如何构建高效的推荐系统,从海量信息中准确的挑选出对用户有价值,用户感兴趣的信息成了一个至关重要的问题。当下,推荐系统已经在电商,社交平台,个性化内容推荐等,领域发挥了重要作用,成了现代互联网应用场景中不可或缺的一部分。
传统的推荐系统主要包括基于协同过滤的推荐系统,基于内容的推荐系统,以及混合推荐系统。协同过滤算法是从相似度度量出发,考虑物品或者用户之间的相似度进行推荐。基于内容的推荐系统则需要建模用户偏好和物品的特征,相比于协同过滤,基于内容的推荐模型在推荐时会考虑物品的特征。基于协同过滤的方法容易遇到冷启动或者数据系数的问题,而混合推荐按系统可以利用基于内容的推荐系统中的用户与物品信息来缓解协同过滤算法的这一问题。
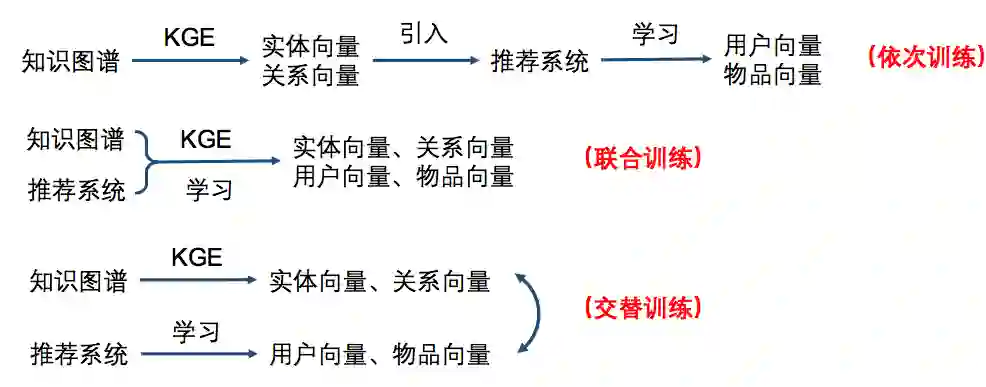
知识图谱可以用来表示实体之间的关系,如推荐系统中物品与物品、用户与物品、用户与用户之间的关系。这些关系信息可以表示用户偏好与物品相似度等信息,将这些信息引入推荐系统中可以显著缓解推荐系统面临的冷启动与数据稀疏问题。近期出现了一大批研究如何利用知识图谱提升推荐系统性能的工作。从模型结构角度来看,知识图谱与推荐系统的结合有三种形式:依次训练、联合训练、交替训练,下文将对这三种结合形式下的主要工作进行综述。
2 依次训练
依次训练指的是知识图谱首先通过embedding得到实体与关系向量,然后引入推荐系统学习用户向量与物品向量,进行模型训练。知识图谱的embedding与推荐系统的训练是依次进行的。依次训练的代表方法为Deep Knowledge-aware Network (DKN)。
Hongwei et al. DKN: Deep Knowledge-Aware Network for News Recommendation. WWW, 2018.
2.1 问题定义与背景知识
DKN针对的是新闻推荐问题,以往的新闻推荐系统仅从新闻文本的语义表示方面进行学习,没有考虑新闻之间在知识层面的联系。而这种联系包含了用户的偏好或者新闻之间的相似度的信息,可以用来帮助推荐系统更准确的推荐用户感兴趣的新闻。在新闻推荐的问题中,给定一个用户的历史点击的新闻标题 

知识图谱的表示形式是包含实体节点与关系的三元组(h, r, t) ,其中h表示头节点,t表示尾节点,r代表二者之间的关系。有了知识图谱的三元组表示之后,需要得到对实体与关系的编码表示,同时希望保留节点之间的关系,即希望编码表示存在类似h+r=t这样的关系。目前主要通过translation-based方法实现这一目的,此类方法又包括TransE ,TransH ,TransR。其中TransE的训练目标为:

直观上,即希望训练embedding之后得到的表示能够满足h+r-t=0。但是现实中h+r的值可能是不唯一的,是一对多的关系,其他更高级的translation-based方法对这一点进行了改进。
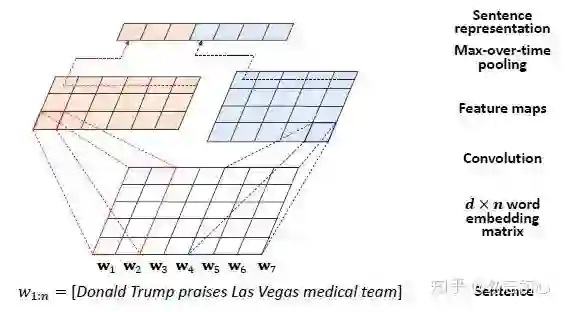
在提取句子特征上,本文使用了最近流行的CNN方法KCNN 。具体的,将每个句子映射到一个 
2.2 模型介绍
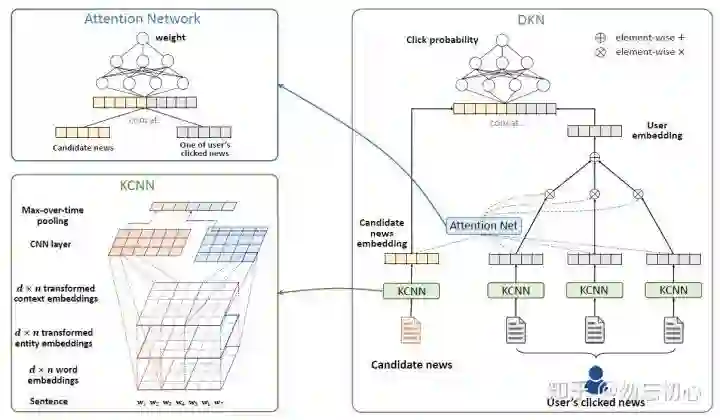
模型的整体架构如图二所示,输出包括候选新闻与用户的历史点击行为。首先通过知识蒸馏的方法,提取出新闻的标题文本的实体的向量与词向量。在获得了标题中的单体与对应的实体向量之后,为了减少embedding过程中的信息损失,利用了一个实体的上下文实体来表示该单词,将原实体向量与实体的上下文向量映射到一个空间里,得到映射的向量之后,作为标题单词向量的扩充,然后用KCNN进行处理。对于处理之后的待选新闻表示,与用户历史点击新闻表示,作者对每一篇历史点击的新闻标题表示与待选新闻表示之间进行了attention操作,根据注意力权重对历史点击新闻表示进行加权平均。最终将历史点击新闻表示与待选新闻表示进行拼接,最后在通过一个深度神经网络输出点击率。
3 联合训练
联合训练指的是同时进行知识图谱的embedding与模型的训练。这里介绍的联合训练的方法为RippleNet。
Hongwei et al. Ripplenet-Propagating user preferences on the knowledge graph for recommender systems. CIKM, 2018.
3.1 问题定义与背景知识
RippleNet的输入包括用户U与物品V的表示,以及用户与物品之间的交互关系 

在RippleNet的论文中将基于知识图谱的推荐系统分为了两类:基于嵌入的方法和基于路径的方法。其中基于潜入的方法指的是将通过知识图谱学习到的实体与关系表示直接嵌入原先的实体向量用于推荐系统训练。而基于路径的方法则通过挖掘知识图谱中用户与物品间的各种关联模式来提供辅助信息,在这里的图是异质图,关联模式是meta-path。异质图可以理解为,图中的节点的类别或关系的类别有不只一类;meta-path指的是图中的一段路径,在异质图中两个节点间可能有多条潜在的meta-path,这种基于路径的信息能够更加直观的描述知识图谱中的信息,但是meta-path需要手工设计。
3.2 模型介绍
整体模型如图三所示。Ripple意为波纹,正如模型所示,输入用户的点击历史作为“波纹”的中心,在每一次迭代时将波纹扩展开来得到新一层的“波纹”集合(不包括之前的“波纹”),随着“波纹”的扩散,用户对新的“波纹”集合中的内容的偏好也会减弱,用户对新得到的“波纹”集合。输入物品的embedding表示,基于应用场景可以选择不同的表示,将物品的表示与此时的波纹集合进行关联,通过下式计算关联概率:

然后通过此概率对尾实体(新的“波纹”) 
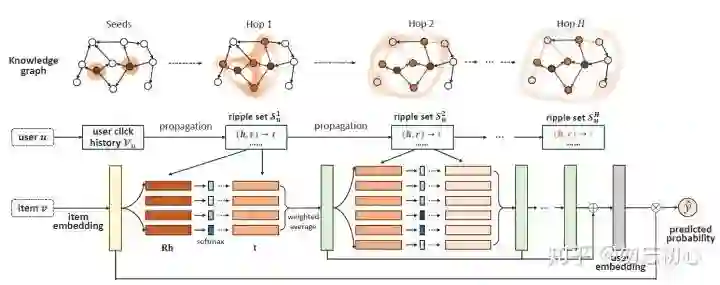
相比于传统的基于mta-path的方法,RippleNet可以根据关联概率来自动的挖掘可能的解释路径,避免了手动设计meta-path。一个可以预见的问题是,随着“波纹”的传播,“波纹”集合可能变得很大,可能会影响模型发现用户的潜在兴趣,文中没有提出直接解决这一问题的方法,但是讨论这种现象的一个潜在好处:用户可能有多个路径来到达同一实体,这些并行路径可以增加模型中用户对重叠的实体的兴趣,类似于真实物理世界中波的合成。
4 交替训练
交替训练任务中,对知识图谱的特征学习任务和模型的点击率预测任务交替进行训练。这方面的工作有MKR。MKR的问题定义与RippleNet的问题定义相同,且所需背景知识前文都已涉及。但是MKR的模型结构非常新颖,下面我们直接开始介绍MKR的模型。
Hongwei et al. Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation. WWW, 2019.
4.1 模型介绍
与其他结合了知识图谱的推荐系统模型不同,如图四所示,MKR包含知识图谱编码模型、推荐模型、交叉压缩模型这三部分。知识图谱编码部分按照常规的做法,输入知识三元组来有监督的学习尾部表示。推荐模型部分输入用户和物品的表示,最终预测用户对物品的点击率。MKR模型的重点在于交叉压缩模型部分,即图四的C部分。
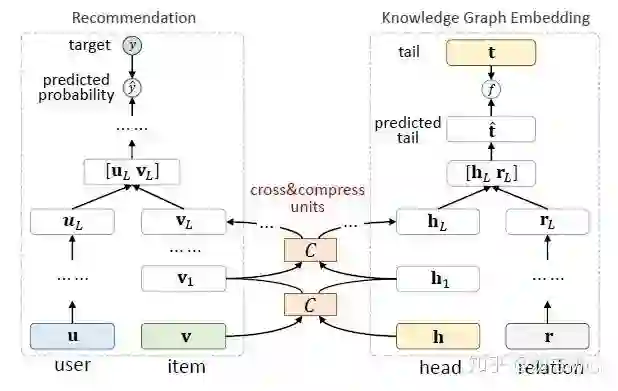
交叉压缩模型的结构如图五所示,将知识图谱边编码模型的头节点与推荐模型的物品编码作为输入。首先,将两个向量相乘得到交叉向量 
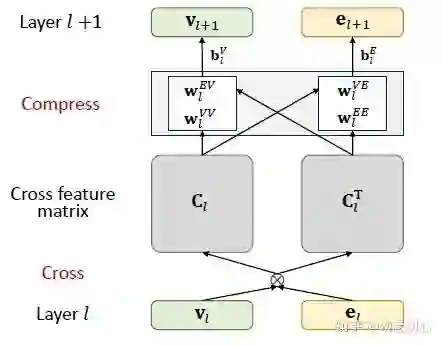
文中认为,交叉压缩模型应该只存在于网络的底层,因为交叉压缩模型是一个信息融合的过程,在网络的深层,特征已经逐渐变得具体,使得信息发生有效融合的可能性降低。
5 总结与展望
本文从从模型结构角度,介绍了利用知识图谱增强推荐系统性能的三种方法。在深度学习时代,除开模型大小、数据量、算力等偏硬件的因素,决定模型性能的主要因素就在于模型结构的设计。从早些年的卷积神经网络,循环神经网络及其改版,到近几年的对抗生成网络,transformer、attention,都表明巧妙的模型(网络)结构设计能带来意料之外的效果。
6 参考文献
用bib做的参考文献,挪到微信太麻烦了,都是一些很经典的论文,很容易搜出来的,就直接贴图了:





