COLING 2022 | CogBERT:脑认知指导的预训练语言模型

©作者 | 陈薄文
单位 | 哈尔滨工业大学
来源 | 哈工大SCIR

论文作者:
论文链接:

介绍
本文研究了利用认知语言处理信号(如眼球追踪或 EEG 数据)指导 BERT 等预训练模型的问题。现有的方法通常利用认知数据对预训练模型进行微调,忽略了文本和认知信号之间的语义差距。为了填补这一空白,我们提出了 CogBERT 这个框架,它可以从认知数据中诱导出细粒度的认知特征,并通过自适应调整不同 NLP 任务的认知特征的权重将认知特征纳入 BERT。

▲ 图1. 人类眼球动作捕捉数据示意图

随着预训练模型的出现,当代人工智能模型在诸多任务上得到了超越人类的表现。随着预训练模型取得越来越好的结果,但是研究人员对于预训练模型却并没有知道更多。
然后,我们在眼动数据中过滤掉统计学上不重要的特征(这意味着具有这些特征的单词的人类注意力并不明显高于/低于单词的平均注意力)。随后,我们通过在不同的 NLP 任务上进行微调,将这些经过认知验证的特征纳入 BERT。在微调过程中,我们将根据不同的 NLP 任务,为每一类特征学习不同的权重。

方法
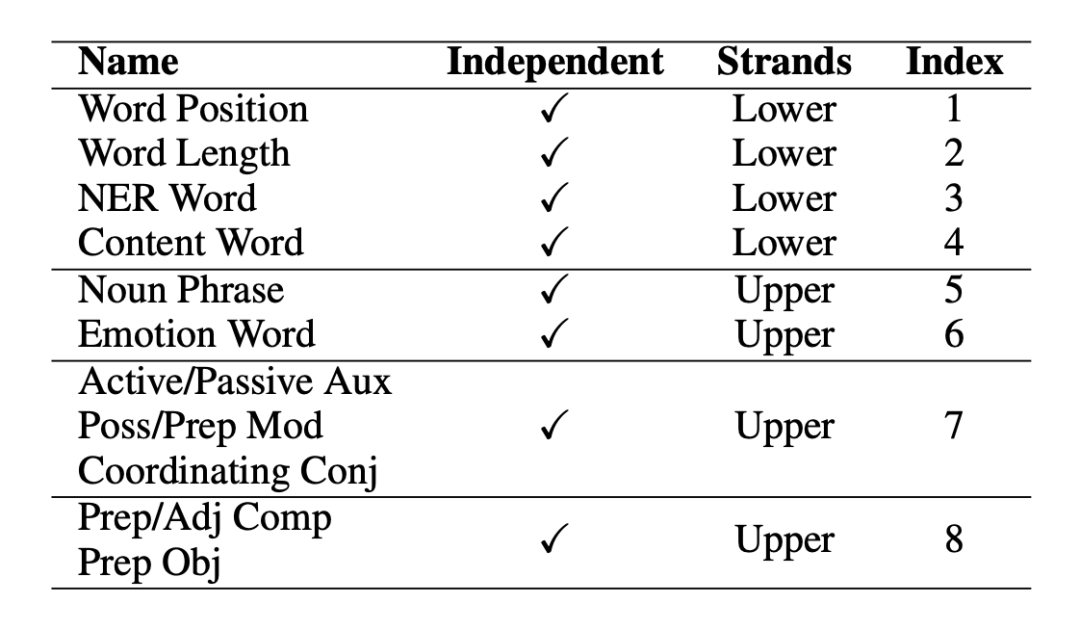
3.2 加权认知特征向量学习
▲ 图2. 加权认知特征向量学习模型
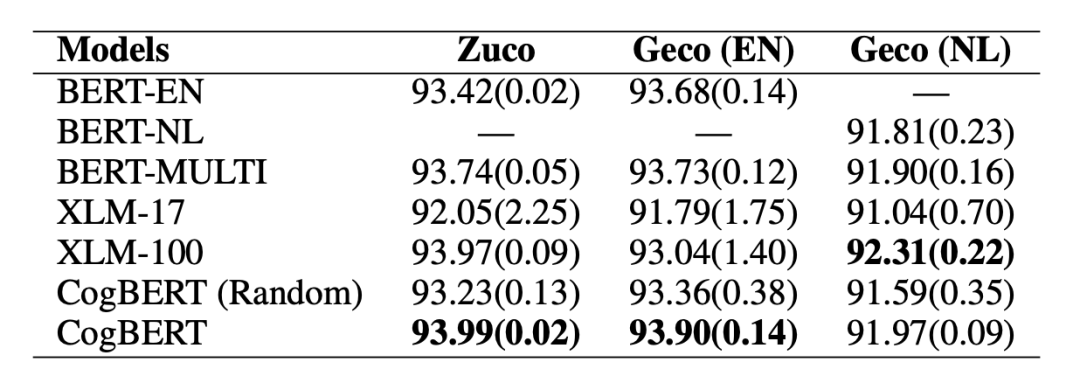
我们可以通过使用 spaCy 工具从文本中提取特征。然而,这些特征不应该被赋予相同或随机的权重,因为它们对适应人类对句子的理解的贡献是不同的。因此,如图 2 所示,给定一个输入句子,我们训练一个四层的 Bi-LSTM [3],将每个单词嵌入到一个加权的八维认知特征向量。根据前述的心里语言学理论,我们认为认知特征可以解释人类眼动信息的分配。因此,我们使用眼球追踪数据(Zuco 1.0、Zuco 2.0 和 Geco)[4,5,6] 的眼球动作信息中的关注次数 (nFix) 作为监督信号来训练 Bi-LSTM 模型。
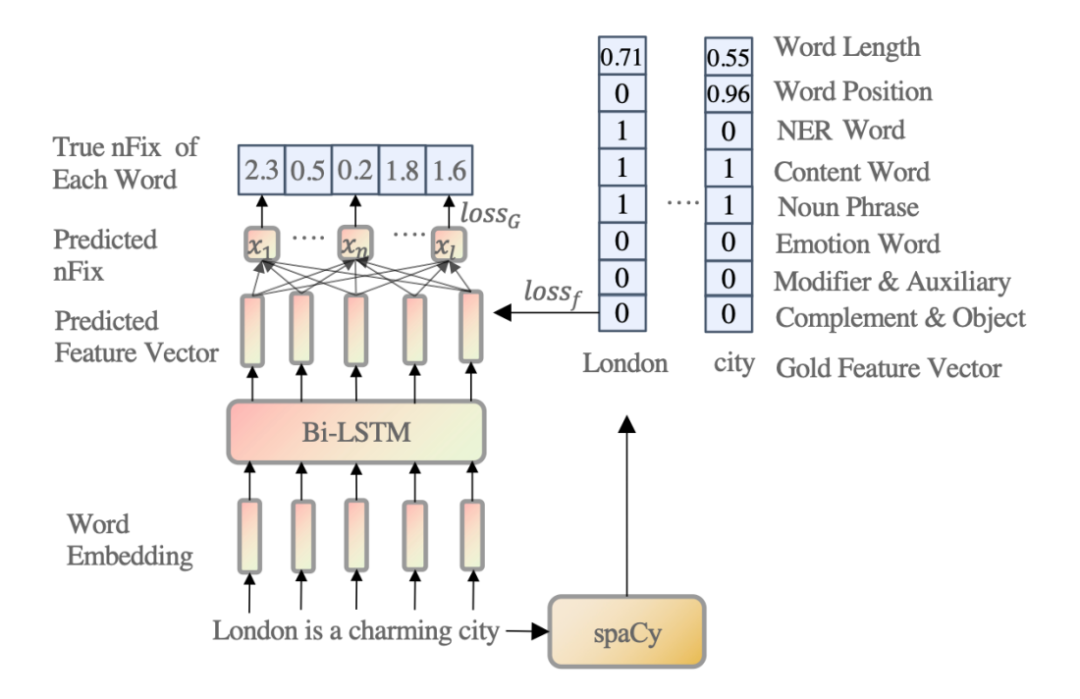
▲ 图3. 特征向量融入预训练语言模型
对于每个上层特征(即 NP chunk、情感词、Mod\&Aux 和 Obj\&Comp),我们可以从 Bi-LSTM 模型中分别为其生成一个初始的特征矩阵。如果相邻的词组成了一个上层特征,它在特征矩阵中的值是由 Bi-LSTM 模型得到的相邻词的平均特征得分,而其余数值都填为 0。同时对于每一个特征,会有一个经由高斯采样出的权重每个特征进行放缩,用来提来该特征在该条数据或者任务当中的重要性。
经由上述过程生成的特征矩阵经过放缩后分别被卷积神经网络进行处理用于提取特征形成基于特征的注意力矩阵,同时为了保留原始的模型注意力信息和特征的注意力矩阵,本文添加了一个门控向量,该向量会分别与模型原本的注意力矩阵和特征注意力矩阵进行相乘并求和,求得一个原注意力矩阵和当前注意力矩阵的线性加权。
同时可以注意到,本模型当中,底层特征将会融入在预训练模型的底层,而高层特征则会融入在预训练模型的高层。

本文在多个数据集上进行了大量的实验,实验结果包括了 GLUE Benchmark [7], CoNLL2000 Chunking [8] 以及 Eye-tracking [9] 和模型本身的一些分析。
4.2 基线方法
1. BERT 不进行迁移,直接在目标领域上进行预测。RoBERTa 微调源领域模型的全部参数进行领域适应;
2. fMRI-EEG-BERT 一种认知数据增强的预训练语言模型,利用了核磁共振与脑电磁场数据;
3. Eye-tracking BERT 一种认知数据增强的预训练语言模型,利用了眼球动作捕捉进行微调后再在下游任务上微调;
4. CogBERT (Random) 本论文所提出的模型,但是特征分数并未经由一阶段进行生成,而是随机生成的。
4.3 实验结果与分析
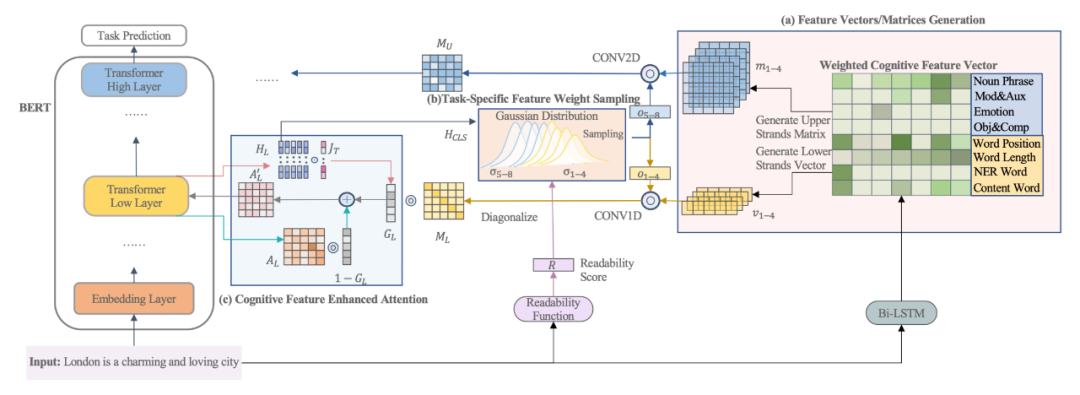
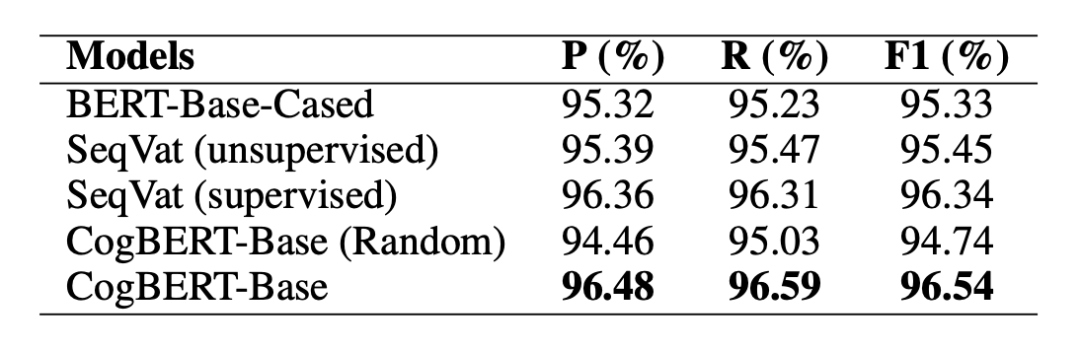
如表 2 所示,本文所提出的模型能够在所有任务上超越模型的原本基线,同时超越大多数的认知增强的预训练语言模型,并能够在大多数任务上达到或者超越经由语法增强的预训练语言模型,体现了本文所提出模型的有效性。
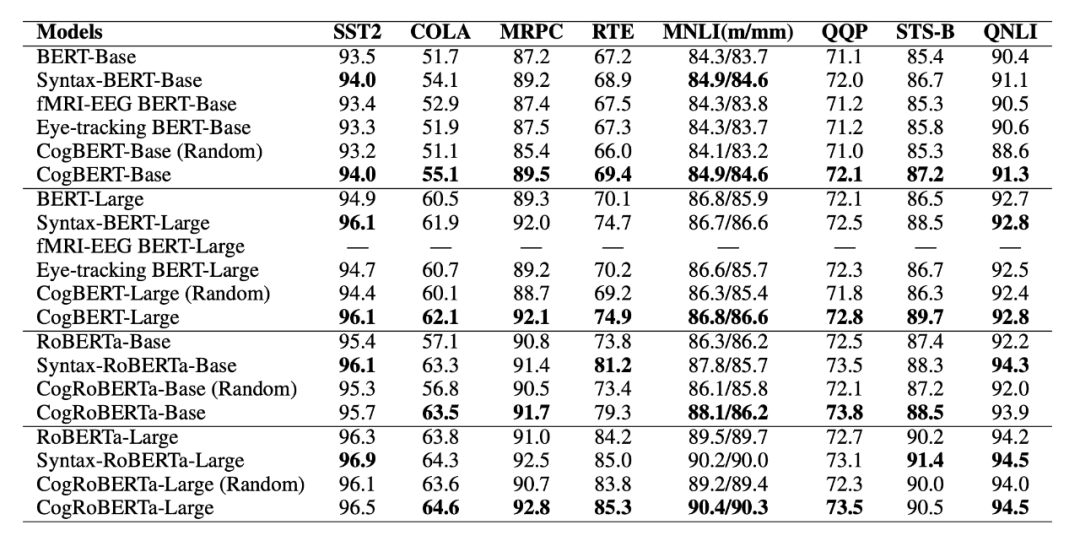
▲ 表2. GLUE Benchmark实验结果
在对于模型本身的分析方面,首先展示在模型学习中不同任务里,不同特征所得到的权重。在 COLA(语法可接受性)上,本文的模型对语法相关特征给出了高权值。在 MRPC(转述句识别)上,模型认为命名实体是最为重要的特征,即可能如果两个句子并不在描述同一个实体,那么两个句子大概率不是转述句。在 RTE(文本蕴含)中,模型认为名词短语是最为重要的特征,这可能意味着如果两个句子具有类似的名词短语结构,那么两个句子具有较大的概率是蕴含关系。在 CoNLL 2000 Chunking 和 CoNLL 2003 NER 任务当中,模型可以很直观的给出名词短语和实体词为最重要特征,符合了任务的设计。

▲ 表5. 特征权重分析实验结果
我们观察到,替换下层或上层的认知特征会降低模型的性能,而去除所有层的认知特征会进一步影响模型的性能。我们还注意到,尽管可读性对于我们的模型来说没有认知特征那么重要,但去除它也会损害模型的性能。不分层的融入特征意味着我们将所有的特征整合到 BERT 的每一层,不分层的糟糕表现表明,以分层的方式整合特征是认知引导的 NLP 的一个有效方法。
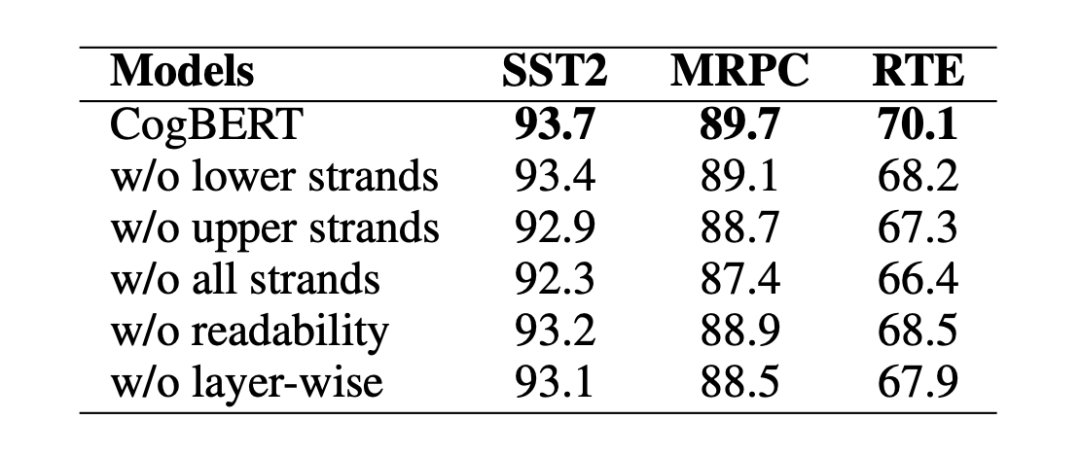
▲ 表6. 消融实验结果
在本文中,由于下层特征融入到预训练模型的底层,而上层特征融入到高层当中,因此有必要去寻找合适的分层边界。本文量化地讨论了 BERT 的哪一层应该是下层和上层认知特征的边界,并对 SST2、MRPC、QNLI 和 STS-B 任务的开发集进行了比较实验,并在图中说明了结果。Y 轴是不同 NLP 任务的性能。X 轴是层数。例如,如果层数为 6,我们将下层的认知特征纳入 BERT 的 1-6 层,将上层的认知特征纳入其余层。
研究发现,当层数边界在 4 左右时,所有任务都达到了最佳性能,这意味着 BERT 的低层更适合纳入下层认知特征,而当我们将上层认知特征纳入更高的层数时,它们更有用。这些结果可以有效地指导未来认知强化预训练模型的研究,同时也进一步验证了前人关于预训练模型的相关研究 [10]。
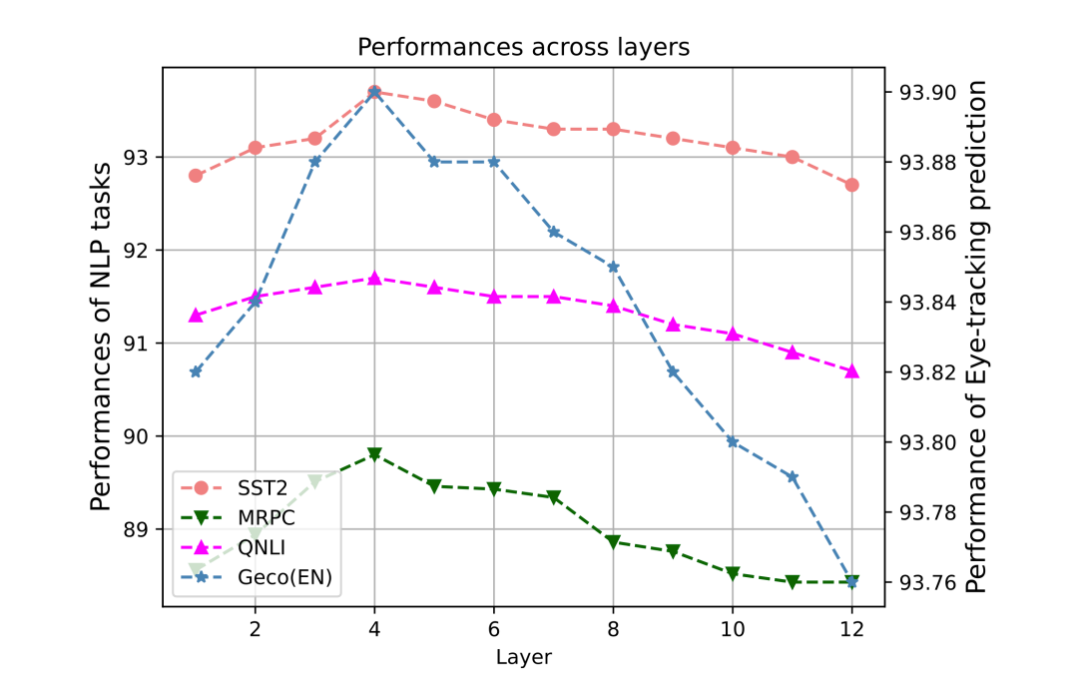
▲ 图4. 任务表现与特征层数分析图
为了定性地分析我们方法的有效性,我们将 CogBERT 的注意力可视化,并与 BERT 和人类进行比较。我们从 SST2、NER 和 MRPC 任务中选择案例。为了与人类的认知进行比较,给定一个特定的 NLP 任务,我们要求四个注释者在阅读句子时突出他们的注意词。对于 BERT 和 CogBERT,我们从预训练模型的较高层次中选择注意力得分,这可以捕捉到任务的特定特征。SST2 和 NER 的注意力可视化图。
图 (a) 展示了 CoNLL-2003 NER 任务的注意力可视化,说明 CogBERT 像人类一样对 NER 词 "Asian Cup"、"Japan"和 "Syria"给予了更多的关注,而 BERT 对这些词的关注很少。图 (b) 说明了 SST2 任务的注意力可视化,显示 CogBERT 捕获了关键的情感词`fun'和`okay',而这两个词从人类的判别行为来说对人类的判断也很重要。
相比之下,BERT 未能关注这些词。这些实验结果表明,尽管预训练模型在众多 NLP 任务中取得了可喜的改进,但它们离人类智能的水平还很远。通过学习人类阅读中的注意力机制,认知引导的预训练模型可以提供一种接近人类认知的有效方法。
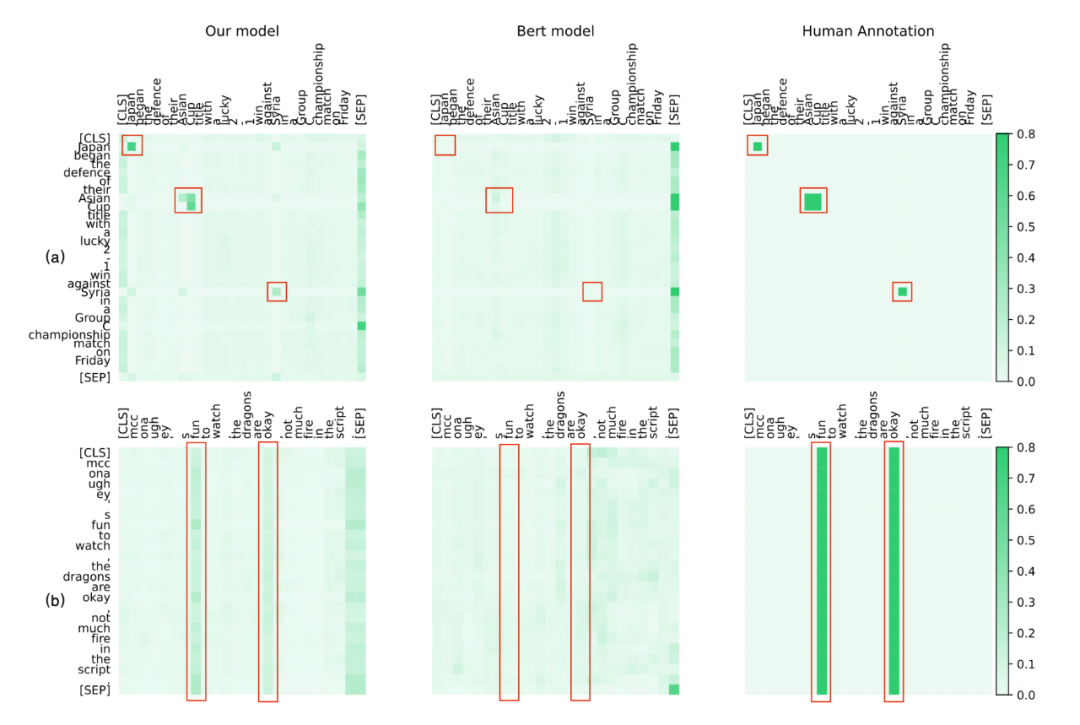
▲ 图5. 注意力可视化

结论

参考文献
[2] Matthew Honnibal and Ines Montani. 2017. spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing.
[3] Hochreiter, Sepp & Schmidhuber, Jürgen. (1997). Long Short-term Memory. Neural computation. 9. 1735-80. 10.1162/neco.1997.9.8.1735.
[4] Nora Hollenstein, Jonathan Rotsztejn, Marius Troen-dle, Andreas Pedroni, Ce Zhang, and Nicolas Langer. 2018. Zuco, a simultaneous eeg and eye-tracking re- source for natural sentence reading. Scientific Data, 5:180291.
[5] Nora Hollenstein, Marius Troendle, Ce Zhang, and Nicolas Langer. 2020. Zuco 2.0: A dataset of physiological recordings during natural reading and annotation.
[6] Uschi Cop, Nicolas Dirix, Denis Drieghe, and Wouter Duyck. 2016. Presenting geco: An eyetracking corpus of monolingual and bilingual sentence reading. Behavior Research Methods, 49.
[7] Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In the Proceedings of ICLR.
[8] Erik Sang and Sabine Buchholz. 2000. Introduction to the conll-2000 shared task: Chunking. Proc of CoNLL-2000 and LLL-2000.
[9] Nora Hollenstein, Federico Pirovano, Ce Zhang, Lena Jäger, and Lisa Beinborn. 2021. Multilingual language models predict human reading behavior.
[10] Ian Tenney, Dipanjan Das, and Ellie Pavlick. 2019.BERT rediscovers the classical NLP pipeline. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4593–4601, Florence, Italy. Association for Computational Linguistics.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
点击「关注」订阅我们的专栏吧





