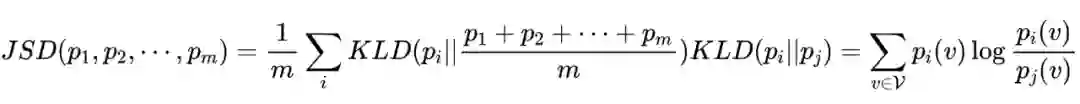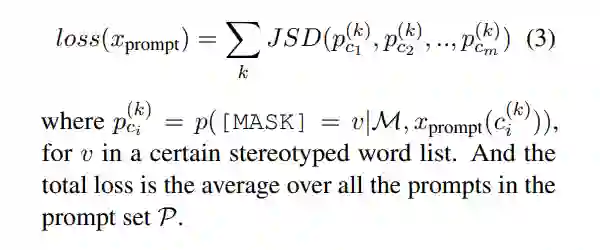![]()
Background
去除偏见问题一直在真实对话系统中一直收到广泛的关注,在大型人类产生的语料库上训练的预训练语言模型,很多模型继承了类似人类的偏见和不想要的社会定型,例如,在 mask filling 任务中,BERT 将句子“The man/woman had a job as [MASK]”中的 [MASK] 分别替换为“经理/接待员”,反映了职业的性别偏见。
我们认为这种 PLM 中编码的刻板印象就是 bias,这样的 bias 很难在常规的评价指标(F1,ACC,GLUE 等)中体现,职业性别偏见只是其中之一,还有许许多多的其他偏见(种族偏见,国家偏见等),它们会在下游 NLP 任务中传播甚至放大,例如情绪分类,文本分类任务,心理测量分析等。
尽管消除偏见迫在眉睫,但这对于掩码模型仍十分挑战,因为被编码的偏见信息很难被识别。为应对这一挑战,以前的工作试图使用额外的语料库来检索语境化 embedding 或定位偏见,进行相应的去偏。例如使用外部语料库来定位包含人口学特定词(如男人和女人)或刻板印象词(如经理和接待员)的句子,然后使用不同的去偏损失来减轻偏见。
然而使用外部语料来消除 PLM 的偏见,在很大程度上依赖于语料的质量。结果表明,不同的语料对去偏的结果有不同的影响:有些外部语料确实减轻了偏见,而有些则为 PLMs 引入了新的偏见。这是因为用于去偏的语料库可能对 PLMs 中编码的偏见没有足够的覆盖。此外,我们对如何定量评估语料库中的偏见水平的理解仍然有限。然而,在没有外部语料库的 PLMs 中减轻偏差是一个研究空白。
为了填补这个空白,ACL 2022 的一篇文章中提出了一种 Auto-Debias 的方法来减轻预训练语言模型中的偏见。与以往使用外部语料对预训练模型进行微调的去偏工作不同,作者通过 prompt 直接探测预训练模型中编码的偏差。具体来说,作者提出了一个变种的束搜索方法,以自动搜索有偏见的提示语使模型填空的结果在不同的人口群体中差异最大,除此以外,本文还通过一个分布排列损失来减轻偏见。
实验结果表明,Auto-Debias 的方法可以大大减少偏见,包括性别和种族偏见,在预训练的语言模型如 BERT、RoBERTa 和 ALBERT 中。此外,在 GLUE 基准的实验证明,公平性的改善并没有降低语言模型的理解能力。
![]()
论文标题:
Auto-Debias: Debiasing Masked Language Models with Automated Biased Prompts
论文链接:
https://aclanthology.org/2022.acl-long.72/
论文代码:
https://github.com/Irenehere/Auto-Debias
![]()
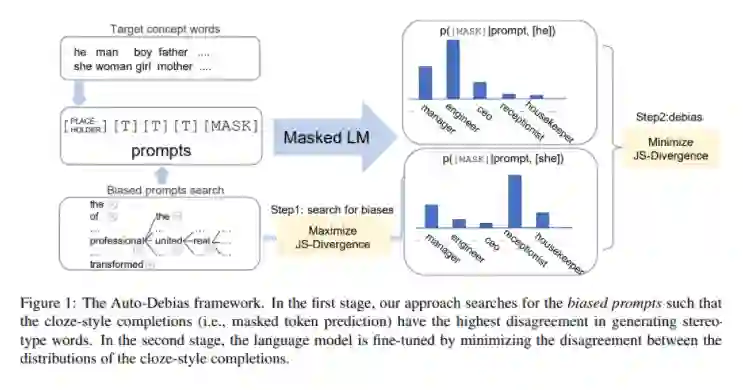
本文的框架如下图所示,将 Auto-biased 方法分为两个阶段:
1. 自动生成有偏见的 prompt,这样 cloze-style 的填空形式在生成关于人口统计群体的刻板印象词时有最大的分歧。
2. 在我们获得有偏的 prompt 后,我们通过分布对齐损失来消除语言模型的偏差,其动机是 prompt 填空的结果应该独立于不同的人口统计特定单词的选择。
![]()
2.1 Task Formulation
目标概念
:与人口统计学群体有关的成对标记(例如,他/她,男人/女人)。
属性词
:关于目标概念的刻板 token(例如,经理、接待员)。
为了减轻模型的偏差,作者希望预测 [MASK] 的输出分布应该有条件地独立于 m 元组
中任何目标概念的选择。因此,作者对去偏的目标是使条件分布 尽可能地相似。
2.2 Finding Biased Prompts
![]()
为了解决这个问题,作者提出了 Finding Biased Prompts 的方法,如算法 1 所述,即波束搜索算法的一种变体算法,针对不同人口群体的最有偏见的 prompt,作者的动机是寻找在 [MASK] 位置生成属性词 W 时分歧最大的提示。
其中 JSD 是 Jensen-Shannon 散度,是一种对称和平滑的 KL 散度,他衡量了两个分布的一致性:
2.3 Fine-tuning MLM with Prompts
在我们得到有偏差的 prompts 后,作者对 M 进行微调以纠正偏差,我们的损失目标是最小化预测的 [MASK]token 分布之间的分歧,假定给定一个 prompt 模板
,则定义损失为
![]()
Experiments
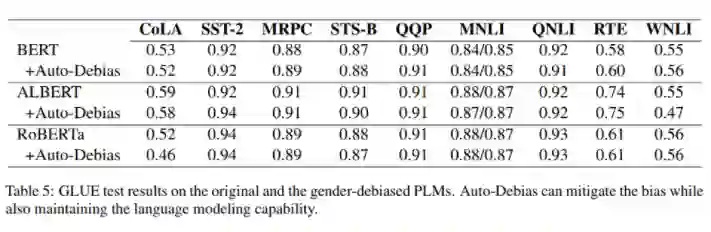
在实验中,本文评估了 Auto-Debias 在减轻三种流行的掩码语言模型(BERT、ALBERT 和 RoBERTa)的性别和种族偏见方面的表现。本文还在 GLUE 任务中评估了去偏模型。结果显示,自动去偏方法可以有效地缓解偏差,同时保持语言模型的能力。
3.1 Debiasing strategy benchmarks:
1. Prtraining:CDA,一种数据增强方法,生成性别平衡的数据;Dropout,增加 PLM 中的 dropout:BERT 增大,ALBERT 添加,重新预训练。英语维基百科,100k 步,3.5h on 8*16 TPU
2.
Post-hoc
:Sent-Debias
从句子表征中去除估计的性别方向。FairFil 使用对比学习方法来纠正句子表征中的偏差。
3. Fine-tuning:Context-Debias
提出通过一个损失函数对 PLM 进行去偏,鼓励属性词和目标概念正交。DebiasBERT 使用均衡损失来均衡特定性别词的关联。
3.2 Evaluating Biases: SEAT
SEAT 利用诸如 "This is a[n]
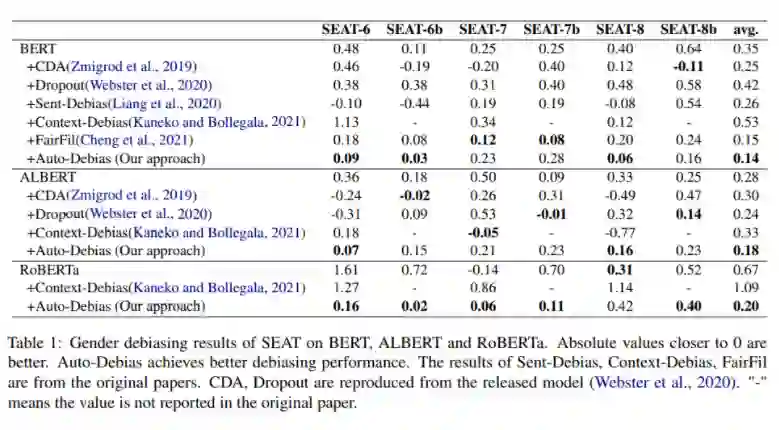
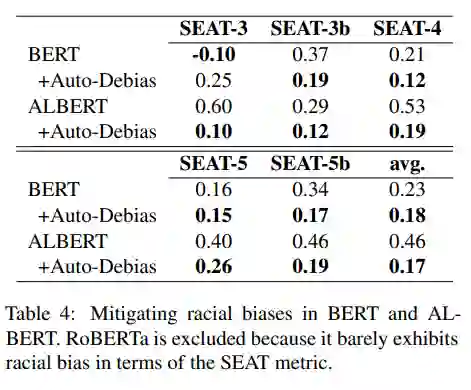
" 这样的简单模板来获得一个单词的上下文独立的嵌入,它允许测量两个特定人口统计学词汇(如男人和女人)与刻板印象词汇(如事业和家庭)之间的关联。一个理想的无偏见的模型应该在特定人口统计学词汇和它们与刻板印象词汇的相似性之间表现出无差异。SEAT 的绝对值越接近 0,说明偏差越低。在实验中,按照先前的工作,作者使用 SEAT 6、6b、7、7b、8 和 8b 来测量性别偏见。另外,作者使用 SEAT 3、3b、4、5 和 5b 来测量种族偏见。
Gender debiasing of SEAT on BERT、ALBERT and RoBERTa
![]()
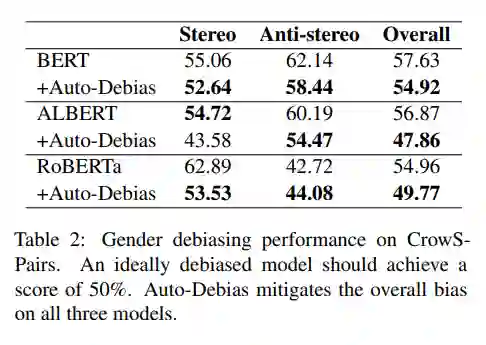
Gender debiasing on CrowS-Pairs
该数据集包含一组句子对,从语义上讲,这些句子对的距离最小,只是每对句子中的一个句子被认为比另一个句子更有偏见。CrowS-Pairs 基准指标衡量的是语言模型将更多的可能性分配给被认为是更多刻板印象的句子的句对的百分比。一个理想的模型预计将达到 50% 的分数。
![]()
![]()
![]()
![]()
调整超参可以使 SEAT 分数很接近于 0,但影响模型的 NLU 性能。此外,词表也有一些局限性,如何拓宽是未来工作的可能方向。
总结:
本文针对“不利用外部语料库的 PLMs 的 debias”问题出发,提出了 Auto-debias 方法,相比于前人去偏工作,Auto-debias 既不利用外部数据,也无需手中构建刻板印象单词的 list,简单高效。并且其中的 Biased Prompts 的方法与分布对齐损失作为两个核心创新点,通过互补的形式很好地结合,实验效果更也证明它有效地减少了性别和种族偏见。我认为这样的方法值得迁移到 NLP 其他领域。
![]()
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()