CVPR22|DDM-Net:端到端的通用事件边界检测模型,prepared for 更精细的视频理解

极市导读
本文介绍南京大学-媒体计算组(MCG-NJU)和商汤科技-智能视频组合作完成,发表在 CVPR 2022 上的通用事件边界检测模型 DDM-Net。DDM-Net 在 Kinetics-GEBD 和 TAPOS 两个标准数据集上分别实现了 14% 和 8% 的显著提升,并能够在测试集上超过 LOVEU Challenge@CVPR2021 的第一名。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/abs/2112.04771
代码地址:https://github.com/MCG-NJU/DDM(整理代码ing,近期开源)
TL;DR: 通用事件边界检测(Generic Event Boundary Detection,GEBD)是视频理解中一项重要而富有挑战性的任务,其目的是模拟人类,感知视频中各事件的边界。这项任务的主要挑战是感知多样化的通用事件边界。为了应对通用事件边界的多样性,学习其复杂的语义,我们做出了以下三点优化:首先,我们构建了一个特征库来存储空间和时间的多层次特征,为多尺度差分计算做好准备。其次,为了缓解以往方法在时序建模上的不足,我们基于密集差分图(DDM)来获取更全面的时序上下文信息。最后,我们通过渐近注意力来聚合外观和运动特征。结果是,DDM-Net 在 Kinetics-GEBD 和 TAPOS 两个标准数据集上分别实现了 14% 和 8% 的显著提升,并能够在测试集上超过 LOVEU Challenge@CVPR2021 的第一名。
一、任务背景
伴随着网络视频数量的大幅增长,视频理解任务变得愈发重要。此前的认知科学研究表明,人类会通过感知事件的边界,将视频划分为若干语义接近的子单元。在这样的背景下,通用事件边界检测(Generic Event Boundary Detection,GEBD)任务被提出,目标是模仿人类观看视频的认知模式,检测出若干事件的边界,将视频分割成若干小段。
和经典的时序动作检测(Temporal Action Detection,TAD)任务相比,GEBD 任务有两个突出的不同点:
1. TAD 的目标是检测 Untrimmed Video 中的动作片段,输出若干个(动作开始时刻,动作结束时刻)的时序框,而 GEBD 的目标是检测视频中的事件边界,输出若干个分割时间点。
2. TAD 中的边界主要是背景片段和动作片段的分界点(动作开始点:背景->动作,动作结束点:动作->背景),而 GEBD 中的边界则更多元,包括动作的变化(Change of Action)、镜头的变化(Shot Change)、视频中动作主体的变化(Change of Subject)、环境的变化(Change in Environment)等等。
GEBD 任务最主要的评测指标是 F1-score@0.05,如果预测边界落在真实边界的 [-0.05*video_length, 0.05*video_length] 区间内则预测正确,否则预测错误。
二、研究动机
GEBD 任务中的通用事件边界,语义是非常丰富多元的,包含动作、镜头、环境的变化。我们认为,GEBD 任务的一大难点是建模通用事件边界的 diverse patterns:Spatial Diversity: 主要指外观(Appearance)上的多样性,比如 low-level 的事件边界(环境、颜色、亮度的变化)和 high-level 的事件边界(人物的出现/消失)。Temporal Diversity: 主要指运动(Motion)上的多样性,比如动作以及动作主体的变化。此外,不同动作的持续时间和速度也不同。由此可见,时空的多样性、复杂性将会影响通用事件边界的准确检测。因此,我们构建时空多尺度特征,以更好地感知多样的事件边界。
GEBD 任务和时间线上的变化强相关,运动信息是检测事件边界的关键。此前的方法广泛将光流(Optical Flow)作为运动表征,来提取时间维度上的信息。但是,光流只关注了两个连续帧之间的局部运动线索,不足以帮助模型感知不同的事件边界。作为对比,本文的 DDM 对于一个邻域内的任意两帧计算 pair-wise 的运动表征,获取更全面的运动信息,以帮助事件边界的检测。
此外,视频理解先前的双流方法通常采用简单的融合方案,缺乏 Appearance 和 Motion 特征之间的交互。我们基于 transformer 实现 Appearance 和 Motion 特征之间的交互,进一步提升模型的性能。
三、方法介绍
下面介绍我们的模型 DDM-Net。
DDM-Net 采用了滑动窗口(Sliding Window)范式,即基于一定步长以及 overlap 的滑动时序窗口,评估各个时间点的边界概率。具体地,我们基于 [t-w*s, ... t-s, t, t+s, ... t+w*s] 这些帧组成的 clip,来判定第 t 帧的边界概率。为什么这么做呢?因为模型无法通过第 t 帧本身来判定其是否为边界,模型只有借助第 t 帧前后的 temporal contexts,才可以预测出第 t 帧的边界置信度。此外,这种范式还有一个好处:无需基于离线的完整视频进行预测,可以应用于在线视频流。在窗口较小的情况下(e.g, w=2),可以达到准实时的 inference 效果。
DDM-Net 主要包含 3 个阶段:构建多层次的时空特征库、计算多层次的密集差分图以及基于渐进注意力的特征融合。首先,采样的片段被送入 backbone 网络和时序卷积层,提取多层次的特征;然后,在多层次特征上 pair-wise 地计算采样片段中每一对视频帧的特征差异,构建多层次的密集差分图;最后,基于渐进的注意力机制更好地学习片段内权重,实现 Appearance 和 Motion 特征的融合。
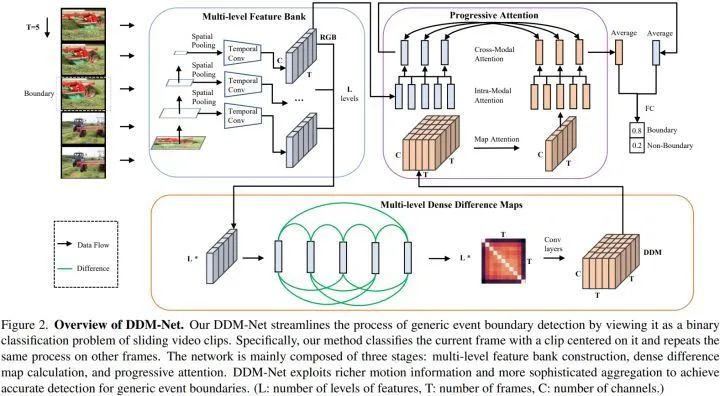
多层次的时空特征库(Multi-level Spatio-Temporal Feature Bank)
GEBD 中的边界 pattern 在空间和时间上都具有多样性:空间上,low-level 的边界主要是环境、颜色、亮度的变化,基于分辨率较小、感受野较大的特征图(feature map)就能够较好地感知,而 high-level 的边界涉及到细节信息,需要利用分辨率较大、感受野较小的特征图;时间上,动作变化的持续时间是多样的,因此也需要利用不同感受野的时序特征。
具体地,我们在 backbone 的 层特征(如 ResNet50 的 layer3 和 layer4,分辨率分别为 14*14 和 7*7)上执行 spatial average pooling,得到 个时序特征序列(batch*C*T)。然后,对于每个时序特征序列,我们利用时序卷积得到具有不同时间感受野的 个时序特征序列。因此,总共有 个时序特征序列,用于后续的多层次密集差分计算。值得注意的是,基于 layer4 计算得到的时序特征序列也被作为 Appearance 特征,随后与密集差分图融合。
密集差分图(Dense Difference Map, DDM)
此前的方法常用 光流、RGB difference 来近似运动表征,但这些稀疏的运动表征仅仅计算了相邻帧之间的运动线索。为了缓解稀疏运动表征时序上下文建模能力不足的问题,我们基于上述多层次的时空特征库,计算了密集差分图 DDM。给定一个 帧的采样片段,基于这个片段的时序特征序列,我们计算每一对帧之间的特征差(feature difference),得到一张 的 DDM。与长度为 的稀疏运动表征序列相比, 的密集运动表征图提供了更全面的时序上下文线索。举例来说,一处 A 片段 -> B 片段的事件边界位于采样片段的第 6 帧,稀疏运动表征序列中可能只有一个元素是较为显著(salient)的(第 5 帧 -> 第 6 帧 or 第 6 帧 -> 第 7 帧),而 DDM 中则有多个元素是 A 片段和 B 片段的 feature difference(第 1 帧 -> 第 7 帧,第 1 帧 -> 第 10 帧,第 4 帧 -> 第 7 帧,第 4 帧 -> 第 10 帧),因而这些元素都较为显著。相较于光流和 RGB difference,DDM 包含了更丰富的时序上下文信息,更全面地描述了当前帧周围的运动模式,使我们的方法能够更好地感知时间变化,区分边界和非边界。
渐进注意力(Progressive Attention)
之前的双流网络通常利用简单的特征聚合和融合方式,例如特征的线性融合、concatenation。然而,这些简单的后融合方式缺乏特征之间的交互,影响方法的性能上限。因此,我们使用了渐进式注意力来更好地聚合外观和运动特征,包括 Map-Squeezed Attention、Intra-Modal Attention 和 Cross-Modal Attention。
Map-Squeezed Attention 的作用是将 的 DDM 压缩为 的运动特征,从而与 的外观特征对齐。具体地,DDM 在每个通道是一张 的 map,第 i 行对应的是第 i 帧和窗口内其他各帧的 difference,我们基于第 i 帧的外观特征聚合第 i 行的元素,得到第 i 帧在window-level 的运动表征;Intra-Modal Attention 模块中,我们利用两组 learnable queries,分别学习(cross-attention)和增强(self-attention) 外观和运动特征中的关键信息;Cross-Modal Attention 分别包含两个 co-attention transformer,第一个 co-attention transformer 的 Q 是上一步输出的外观 queries,K 和 V 是上一步输出的运动 queries,第二个 co-attention transformer 则相反。因此,DDM-Net 分别基于外观/运动 queries 的 guidance,实现了特征的交互以及窗口内部的特征 re-weight。最后,我们将两组 query 进行聚合,通过 FC 得到当前窗口的边界置信度。
四、实验结果
在公平比较的 setting 下,DDM-Net 在 GEBD 的两个数据集(Kinetics-GEBD 和 TAPOS) 上都大幅超越了之前的方法,取得 SOTA 的结果。
1. Kinetics-GEBD
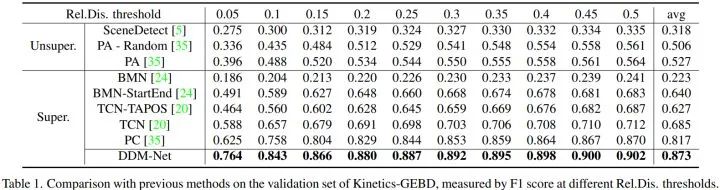
DDM-Net 在 F1-score 上显著优于之前的方法。特别是,在 F1-score@0.05 的指标上,DDM-Net 实现了从 62.5% 到 76.4% 的显著提升。此外,DDM-Net 可以在只替换 backbone 的情况下(ResNet50 -> CSN,未使用 model ensemble,音频数据,辅助的人体检测框等 bells and whistles),超过 CVPR 2021 LOVEU Challenge 的第一名方案。
2.TAPOS
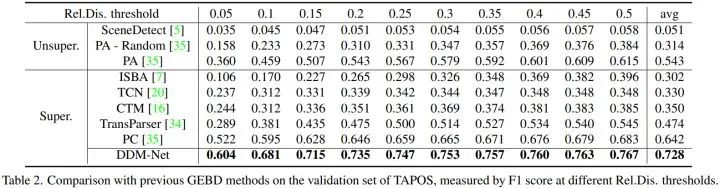
由于 DDM-Net 能够学习复杂的语义,区分子动作之间的细微变化,因此在 TAPOS 上也获得了 SOTA 的性能,将 F1-score@0.05 从 52.2% 提升到 60.4%。
五、讨论
1. 通用事件边界检测(GEBD)任务的意义?
目前,长视频理解仍然是一项挑战。由于显存受限,模型无法完成一个超长视频的 inference。因此,将长视频拆分成短视频,并汇总短视频的理解内容是一项解决方案,而 GEBD 任务恰好提供了拆分视频的依据。此外,我们认为边界处的内容是值得关注的,这意味着视频的内容出现了变化。这种变化信息是具有指导意义的,可以为安防、直播等场景提供重要线索。
2. 对于通用事件边界检测任务的标准数据集,边界是如何标注的?实际场景中,我们又可以怎样定义边界?
时序边界并不是一个非常客观的定义。因此,Kinetics-GEBD 采用了多位 annotator 的标注(这种标注方式变得愈发流行),通过 redundancy 来保证标注的 correctness 和 objectiveness。而实际场景中,边界的定义则由需求决定:假设我们需要一个精细的时序分割结果,那么就需要标注细粒度、数量较多的边界;假如我们只需要一个粗糙的时序分割结果,那么就需要标注粗粒度、数量较少的边界。如果定义不满足需求,则有可能出现“欠分割”和“过分割”的边界标注情况。
3. 为了落地应用,如何进一步提升方法的效率?
在 DDM-Net 中,我们采用了基于 Sliding Window 的 dense prediction 范式,即预测视频中多个 timestamp 的边界置信度,得到 video-level 的边界置信度序列后,进行去重处理。考虑到视频特征的冗余性(feature slowness),可以增大 Sliding Window 的步长,以及窗口内部各帧间的采样间隔,从而减少视频内的窗口数量,以提升效率。当然,更稀疏的采样也会轻微降低方法的性能,需要基于实际场景中性能和效率的 tradeoff 来定夺。此外,由于本方法的 Sliding Window 较小,因此 pair-wise 的差分计算不会带来很大的开销。
六、可视化分析
下图可视化和比较了 DDM-Net 和 baseline 方法 PC 的边界预测结果。

第一行的视频涉及几个不同的镜头,DDM-Net 可以感知镜头的变化并准确预测边界,而 PC 的预测并不准确。
第二行的案例具有挑战性,因为只有演奏手左手的位置发生了变化。DDM-Net 可以捕捉细微的动作变化,而 PC 则 miss 了所有的真值。
第三行的案例是镜头变化和动作变化的组合,且相机出现了抖动。DDM-Net 的误检更少,体现了方法的鲁棒性。
全面的 Ablation study、方法中的细节和实验可视化请参考我们的论文和代码 :)
感谢大家的阅读!
公众号后台回复“画图模板”获取90+深度学习画图模板~


# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




