最新论文解读 | 神经网络“剪枝”的两个方法

编译 | AI科技大本营
参与 | 刘 畅
编辑 | 明 明
【AI科技大本营导读】本文介绍了两篇自动学习神经网络架构方向的最新方法,他们主要是通过计算扔掉一些参数/特征来实现的。第一篇L0方法看起来像是一个更简单的优化算法,第二篇Fisher修剪法论文来自于作者及其实验室。
第一篇论文:《Christos Louizos, Max Welling, Diederik P. Kingma (2018) Learning Sparse Neural Networks through $L_0$ Regularization》
论文地址:https://arxiv.org/abs/1712.01312
第二篇论文:《Lucas Theis, Iryna Korshunova, Alykhan Tejani, Ferenc Huszár (2018) Faster gaze prediction with dense networks and Fisher pruning》
论文地址:https://arxiv.org/abs/1801.05787
第二篇论文的标题中提到的修剪,其含义是在神经网络中减少或控制非零参数的数量,或者是在神经网络中需要用到的特征图数量。从更抽象的层面来看,至少有三种方法可以做到这一点,而修剪方法只是其中之一:
正则化该方法修改了目标函数/学习问题,因此优化过程中有可能会找到一个带少量参数的神经网络。Louizos等(2018)做了这方面的工作。
修剪该方法是在一个庞大的网络上,删除在某种程度上冗余的特征或参数。(Theis et al,2018)的工作就可以作为一个例子。
生长第三种方法知名度比较低,从小型网络开始,按生长标准逐步增加新的单元。
▌为什么要剪枝?
修剪网络有各种各样的原因。 最显然的原因是希望保持相同性能的同时能降低计算成本。而且删除那些在深度网络中没有真正使用的特征,也可以加速推理和训练过程。你也可以将修剪看作是一种结构探索:即找出在每层中需要多少个特征才能获得最佳性能。
第二个原因是通过减少参数数量,也就是减少参数空间中的冗余,可以实现提升模型的泛化能力。正如我们在近期关于深度网络泛化能力的研究中所看到的那样,参数的原始数量(L_0 norm)实际上并不能预测其泛化能力。也就是说,根据经验,我们发现修剪网络有助于提升泛化能力。同时,深度学习社区正在开发新的参数相关量来预测/描述泛化。 Fisher-Rao norm就是一个很好的例子。有趣的是,Fisher修剪(Theis et al,2018)被证明与Fisher-Rao norm之间有很好的相关性,这可能意味着修剪,参数冗余和泛化之间,有着更深层次的关系。
▌L_0 正则化
我发现Louizos等人(2018年)关于L_0的论文非常有趣,它可以被看作是几个月前我在机器学习食谱(译者注:博客作者另外的博文,地址http://www.inference.vc/design-patterns/)中所写的机器学习问题转换的直接应用。这是一个很好的例子,说明如何使用这些一般的想法,将一个棘手的机器学习优化问题转化为可以实际运作的模型。
所以我将这篇文章总结为以下步骤,每个步骤逐步改变着模型优化问题:
1、首先从难以优化的损失函数开始:在常用的损失函数上加上L_0范数,两者线性组合。 L_0范数简单的计算了向量中的非零项,它是一个不可微分的常量函数。 所以这是一个非常困难的组合优化问题。
2、应用变分优化方法将不可微的函数转化为可微函数。这通常是通过在参数$ \ theta $上引入一个概率分布p_ {\ psi}(\ theta)。即使目标对于任何 \ theta 参数都是不可微的,但是在 p_ {\ psi} 下的平均损失可能是可微的w.r.t.$\$ PSI。为了找到最优\ psi ,通常可以使用一个增强(REINFORCE)梯度估计器,从而得到优化的策略。 但是这种方法通常具有高方差,因此我们会用步骤三的方法。
3、将重构造参数(reparametrization)技巧应用于pψ上,以此构造一个低方差梯度估计器。但是,这只适用于连续变量。为了处理离散性,我们转向步骤四。
4、使用concrete relaxation,通过连续近似逼近离散随机变量。现在我们有一个较低的方差(与REINFORCE相比)梯度估计器,可以通过反向传播和简单的蒙特卡罗采样来计算。 您可以在SGD(Adam)中使用这些梯度,也正是这篇论文做的工作。
有趣的是,步骤3并没有提到优化策略或变分优化之类的东西。取而代之的出发点是基于不同连接的spike-and-slab先验。我建议阅读这篇论文时,可以考虑到这一点。
作者表明这确实在减少参数数量方面起了作用,并且与其他方法相比更有优势。根据这些步骤,思考从一个问题转换到另一个问题,让您也可以概括或改进这个想法。例如,REBAR或RELAX梯度估计器相比其他的估计器,它能够达到无偏差和低方差的效果,而且这种方法在这个问题上也可以有很好的效果。
▌Fisher修剪法
我想谈的第二篇论文是来自我们自己实验室的。(Theis等人,2018)这篇论文不是纯粹的方法,而是关注于具体应用,即如何构建一个快速神经网络来预测图像显着性。修剪网络的方法来源于在Twitter上裁剪照片的原理。
我们的目标也是为了降低网络的计算成本,特别是在迁移学习环境中:当使用预训练的神经网络开始构建时,您将继承解决原始任务所需的大量复杂性计算,而这对于解决你的目标任务可能是多余的。我们的高级(high-level)修剪方法有一个不同之处:与L0范数或组稀疏度不同,我们用一个稍微复杂的公式来直接估计方法的前向计算时间。这个公式是相邻层间相互作用的每层参数数量的二次函数。有趣的是,这样做的结果是网络结构是厚层和薄层间的交替运算,如下所示:
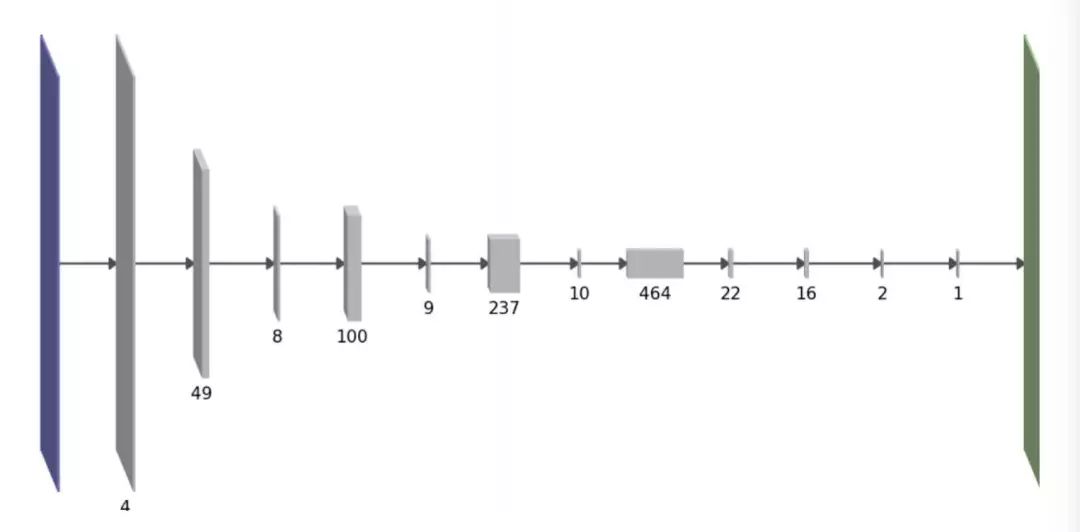
我们使用一次去掉一个卷积的特征图的方法,来修剪训练好的网络。选择下一个待修剪特征图的一个原则是尽量减少由此造成的训练损失增加。从这个原则出发,利用损失函数的二阶泰勒展开式,再做出更多的假设,我们能得到下面关于参数θi的修剪关系:
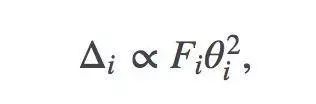
Fi表示Fisher信息矩阵的第i个对角线值。虽然上面的公式去除了单个参数,但是我们可以延伸到如何去除整个特征图。而修剪是通过去除每个迭代中具有最小Δ的参数或特征映射,并且在迭代间再重新训练网络来实现的。欲了解更多详情,请参阅论文。
除了论文中提到的内容之外,我想指出一下Fisher修剪法与我之前在这个博客上讨论过的想法之间的一些联系。
Fisher-Rao范数
第一个联系是Fisher-Rao范数。假设某一分钟Fisher矩阵信息是对角的,在理论上这是一个大而且不合理的假设,但是在应用中简化了它,就得到了能用于实践的算法。有了这个假设,θ的Fisher-Rao范数变成:
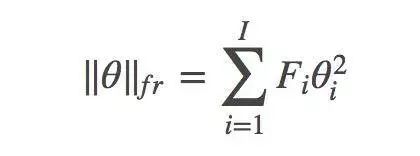
用这种形式写下来,你就能看到FR范数与Fisher修剪法之间的联系了。根据所使用的Fisher信息矩阵的特定定义,您可以近似解释FR范数,如下:
当删除一个随机参数,训练日志可能(Fisher经验信息)会按预期下降
或者当删除一个参数,由模型(Fisher模型信息)定义的条件分布的近似变化
在现实世界中,Fisher信息矩阵并不是对角的,这实际上是理解泛化的一个重要方面。首先,只考虑对角线值使Fisher修剪与网络的某些参数(非对角线雅可比矩阵)之间有些联系。但是也许在Fisher-Rao范数和参数冗余之间有更深层次的联系。
弹性权重巩固(Elastic Weight Consolidation)
使用对角Fisher信息值来指导修剪也与(Kirkpatrick等,2017)提出的弹性权重巩固有相似之处。在EWC中,Fisher信息值用于确定哪些权重能够在解决以前的任务中更重要。而且,虽然算法是从贝叶斯在线学习中推导出来的,但是你也可以像Fisher修剪那样从泰勒展开的角度来决定。
我用来理解和解释EWC的一个比喻是共享硬盘。(提醒:与其他所有的比喻一样,这可能完全没有意义)。神经网络的参数就像是某类硬盘或存储卷。训练神经网络的任务过程包括压缩训练数据并将信息保存到硬盘上。如果你没有机制来保持数据不被复写,那么该硬盘就将被复写。在神经网络中,灾难性遗忘是以同样的方式发生。EWC就像是一份在多个用户之间共享硬盘的协议,而用户不需要复写其它用户的数据。 EWC中的Fisher信息值可以被看作软件层面的不复写标志。在对第一个任务进行训练之后,我们计算出Fisher信息值,该值表示该任务的关键信息是由哪些参数存储的。Fisher值较低的是冗余的参数,其可以被重复使用并用来存储新的信息。在这个比喻中, Fisher信息值的总和就是衡量了硬盘容量的大小,而修剪实际上就是丢弃了硬盘上不用于存储任何东西的部分。
总结
在我看来,这两种方法/论文本身都很有趣。 L0方法看起来像是一个更简单的优化算法,可能是Fisher修剪的迭代,一次删除一个特征方法更可取。然而,当你在迁移学习中,从一个大的预训练模式开始时,Fisher修剪则更适用。
作者| FerencHuszár
原文链接
http://www.inference.vc/pruning-neural-networks-two-recent-papers/?nsukey=z6NQe6fC2toltaVCEoqq6242x7AScSRUSIk3%2FLoeKf00ExXKTajTwEDOasmj3OZI0jZbDeeDMHzvIKeD9vp8d%2FyH488zjFxznt3z2vIzLtnhaSVmWtcGHHF9ySKsvx8eBmmJRUjYz2oj2pykWs4mALvrFL%2BDxuKQFZ7xveeDramYMpnf1iHKWfj60GBlO7%2FORv7jpBNOz8hIs2i7pmtw4A%3D%3D
新一年,AI科技大本营的目标更加明确,有更多的想法需要落地,不过目前对于营长来说是“现实跟不上灵魂的脚步”,因为缺人~~
所以,AI科技大本营要壮大队伍了,现招聘AI记者和资深编译,有意者请将简历投至:gulei@csdn.net,期待你的加入!
如果你暂时不能加入营长的队伍,也欢迎与营长分享你的精彩文章,投稿邮箱:suiling@csdn.net
如果以上两者你都参与不了,那就加入AI科技大本营的读者群,成为营长的真爱粉儿吧!后台回复:读者群,加入营长的大家庭,添加营长请备注自己的姓名,研究方向,营长邀请你入群。




☟☟☟点击 | 阅读原文 | 查看更多精彩内容


