模型压缩经典解读:解决训练数据问题,无需数据的神经网络压缩技术(四)

极市导读
目前很少有工作关注在无数据情况下的网络压缩,然而,这些方法得到的压缩后的网络准确率下降很多,这是因为这些方法没有利用待压缩网络的信息。本系列继续介绍2种无需训练数据的网络压缩方法,分别是面向更加鲁棒和多样化的的无训练数据模型压缩以及一种新的无需原始训练数据的对抗蒸馏方式。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
目录
1 更加鲁棒和多样化的无训练数据模型压缩技术 (ICASSP 2021)
(来自东北大学)
1.1 RDSKD 原理分析
1.1.1 DAFL 方法回顾:通过 GAN 生成无标注的训练图片
1.1.2 更加鲁棒和多样化的 DAFL 方法
1.1.3 实验结果2 无需原始训练数据的对抗蒸馏技术 (CVPR 2020)
(来自浙江大学,阿里巴巴)
2.1 DFAD 原理分析
2.1.1 Data-Free 模型压缩的方法分类
2.1.2 DFAD 对抗蒸馏方法
2.1.3 实验结果
上篇:
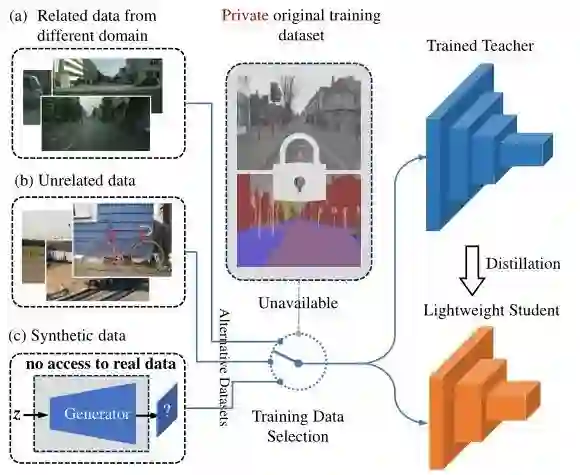
随着深度学习技术的发展,深度神经网络 (CNN) 已经被成功的应用于许多实际任务中 (例如,图片分类、物体检测、语音识别等)。由于CNN需要巨大的计算资源,为了将它直接应用到手机、摄像头等小型移动设备上,许多神经网络的压缩和加速算法被提出。现在的问题是这些神经网络的压缩和加速算法都有一个基本的假设,那就是:训练数据是可获得的。
但是实际情况是:在现实中的应用上,由于隐私因素的制约或者传输条件的限制,我们无法获得训练数据。比如:在医学图像场景中,用户不想让自己的照片 (数据) 被泄露;训练数据太多没办法传到云端,甚至是存储这些巨大量的数据集对于小型企业都是个难题;所以,使用常规的模型压缩办法在这些限制下无法被使用。
甚至,预训练网络的基本架构和参数都是未知的,就像一个黑盒,只能通过输入来获取输出信息。所以剪枝,量化等等常用的模型压缩方法就更无从下手了。
这个系列考虑的问题是:我们在做这些模型压缩、加速、搜索的时候,如何去保护用户的隐私。学术界可能不是很关心这个问题,因为很多训好的神经网络都是采用了一些公开的数据集。但在实际应用中,涉及到隐私的端侧 App 就会非常多,包括人脸解锁、语音助手、指纹识别、一些娱乐 APP 的应用,基本上都需要用户实时的采集一些自己的隐私数据去完成训练。如果我们想要获取这些隐私数据,用户很可能会感到焦虑。比如之前比较火的一键换脸的软件,面临的隐私问题也受到很大的关注度。
但是如果用户在本地训出的模型,比如人脸识别解锁,体验不好、或者人脸解锁比较慢,想让我们把他的AI模型做一个速度优化的时候,但他不想给我们人脸,只想把他自己的训好的AI应用给我们,这种情况下怎么去做一些模型压缩和加速?
目前很少有工作关注在无数据情况下的网络压缩,然而,这些方法得到的压缩后的网络准确率下降很多,这是因为这些方法没有利用待压缩网络的信息。为了解决这一问题,本文继续介绍2种无需训练数据的网络压缩方法,分别是面向更加鲁棒和多样化的的无训练数据模型压缩以及一种新的无需原始训练数据的对抗蒸馏方式。
1 更加鲁棒和多样化的无训练数据模型压缩技术 (ICASSP 2021)
论文名称:Robustness and Diversity Seeking Data-Free Knowledge Distillation
论文地址:
https://arxiv.org/pdf/2011.03749.pdf
1.1 RDSKD 原理分析:
这篇 RDSKD 来自东南大学,所基于的 baseline 是华为诺亚方舟实验室于 ICCV 2019 提出了在无数据情况下的网络蒸馏方法 DAFL,是 DAFL 算法的改进版本。
它的特点是:
-
待压缩网络看作一个固定的判别器 。
-
用生成器 输出的生成图片代替训练数据集进行训练。
-
设计了一系列的损失函数来训练生成器 和学生网络,目的是生成更加真实,类别多样性和样本间多样性更高的训练数据。
-
使用生成数据结合蒸馏算法得到压缩后的网络。
1.1.1 DAFL 方法回顾:通过 GAN 生成无标注的训练图片
知识蒸馏方法获得学生网络
蒸馏算法最早由Hinton提出,待压缩网络 (教师网络) 为一个具有高准确率但参数很多的神经网络,初始化一个参数较少的学生网络,通过让学生网络的输出和教师网络相同,学生网络的准确率在教师的指导下得到提高。
从结构和参数的角度看,如上文所述,待压缩的大网络的结构和参数都是未知的,这就使得我们无法通过剪枝或者量化等经典的神经网络压缩方法进行模型压缩,我们唯一已知的就是待压缩的大网络的输入和输出接口。
从训练数据的角度看,DAFL 的训练样本是由生成器 生成的,是没有标签的,所以没法通过有监督的方式学习学生网络,基于这两点,作者引入了教师学生网络学习范式,利用蒸馏算法实现利用未标注生成样本对黑盒网络的压缩。
令 和 分别代表教师和学生网络的输出,作者使用 KL 距离来使得学生网络的输出符合教师网络的输出,具体的损失函数为:
式中, 和 分别代表教师和学生网络的输出。通过引入教师学生算法,作者解决了生成图片没有标签的问题,并且可以在待压缩网络结构未知的情况下对其进行压缩。
通过 GAN 生成无标注的训练图片
从训练数据的角度看,在整个网络压缩的过程中,我们都没有任何给定的训练数据,在此情况下,神经网络的压缩变得十分困难。所以作者通过 GAN 来输出一些无标注的训练图片,以便于神经网络的压缩。生成对抗网络 (GAN) 是一种可以生成数据的方法,包含生成网络 与判别网络 ,生成网络希望输出和真实数据类似的图片来骗过判别器,判别网络通过判别生成图片和真实图片的真伪来帮助生成网络训练。
具体而言,给定一个任意的噪声向量 (noise vector) ,生成器 会把它映射成虚假的图片 ,即 。另一方面,判别器 要区分来的一张图片是真实的 还是生成器伪造的 ,所以,对于 GAN 而言,它的目标函数可以写成:
这个目标函数 的优化方法是 。就是每轮优化分为2步,第1步是通过 gradient ascent 优化 的参数,第2步是通过 gradient descent 优化 的参数。然而,我们会发现传统的 GAN 需要基于真实数据 来训练判别器,这对于我们来说是无法进行的。所以基于传统的 GAN 训练方法 2 式是不行的。
许多研究表明,训练好的判别器 具有提取图像特征的能力,提取到的特征可以直接用于分类任务,所以,由于待压缩网络使用真实图片进行训练,也同样具有提取特征的能力,从而具有一定的分辨图像真假的能力。而且这个待压缩网络我们是已有的。于是,我们把待压缩网络作为一个固定的判别器 ,以此来训练我们的生成网络 。
首先,待压缩网络作为一个固定的判别器 ,我们就认为它是已经训练好参数的判别器 ,我们利用它来训练生成器的基本思想是下式:
式中, 就是已经训练好参数的判别器,生成器 的参数经过3式持续优化使得 逐渐上升,代表着生成器的输出越来越能够骗过判别器。
但是,在传统GAN中,传统的判别器 的输出是判定图片是否真假 (Real or Fake?),只要让生成网络生成在判别器中分类为真的图片即可训练,但是,我们的待压缩网络为分类网络,其输出是分类结果 (1-num_classes),所以待压缩网络无法直接作为一个固定的判别器 。因此需要重新设计生成网络的目标。通过观察真实图片在分类网络的响应,作者提出了以下损失函数。
1) 伪标签交叉熵损失
在图像分类任务中,神经网络的训练采用的是交叉熵损失函数,在训练完成后,真实图片在网络中的输出将会是一个one-hot的向量,即分类类别对应的输出为1,其他的输出为0。于是,我们希望生成图片也具有类似的性质。给定一组任意的噪声向量 ,它们通过生成器 之后得到的生成图片是 ,这里 。
现在把这些生成图片 输入给待压缩的网络,通过 得到输出 ,预测标签就是通过 计算得到 。定义伪标签交叉熵损失为:
其中 就是标准的交叉熵函数,由于生成图片并没有一个真实的标签,我们直接将其输出最大值对应的标签设定为它的伪标签。伪标签交叉熵损失的意思就是对于一张生成的图片,它的标签就按照教师网络的输出来决定,这是训练生成器 的第1个损失。
2) 信息熵损失函数
为了让神经网络更好的训练,真实的训练数据对于每个类别的样本数目通常都保持一致,例如MNIST每个类别都含有 6000 张图片。于是,为了让生成网络产生各个类别样本的概率基本相同,作者引入信息熵,信息熵是针对一个概率分布而言的。假设现在有概率分布 ,概率分布 的信息熵的计算方法就是:
概率分布 越均匀,信息熵 就越大。极限情况当 时,信息熵 取极大值 。所以信息熵损失函数定义为:
其中 为标准的信息熵,信息熵的值越大,对于生成的一组样本经过待压缩教师网络的输出特征 来讲,每个类别的数目就越平均,从而保证了生成样本的类别平均。
1.1.2 更加鲁棒和多样化的 DAFL 方法
DAFL 方法的问题是对超参数的选择很敏感,几个损失函数 , , 和蒸馏的损失函数 的超参数需要仔细调节才能够训练出有效的 GAN 模型。虽然在特定环境下有效,但 DAFL 对超参数选择很敏感,甚至可能无法收敛。
根据上文描述可知,DAFL 的损失函数One-hot Loss 设计的目的是提高生成的样本真实性,信息熵损失 的目的是提高不同类别样本的多样性。One-hot Loss 会使得教师模型的输出比较 "sharp",也就是接近独热编码。信息熵损失 会使得教师模型的输出比较 "smooth",也就是远离独热编码。这些相互冲突的目标导致训练损失的高度波动,导致DAFL的训练不稳定。
本文作者通过精心设计一些损失函数以解决这个问题。根据本文作者的经验观察,DAFL 生成的样本在每个类中都太相似了。这类似于 GAN 中的模式坍塌问题。可以类似于 GAN 模型增加一个 mode seeking regularizer[1] 来解决。受此启发,作者提出一个新的 loss 来增加类内生成样本的丰富度。
3) 多样性导向的正则化损失函数
提高生成样本的多样性对于学生模型的训练至关重要。为了防止生成的样本彼此过于相似,类似于 GAN 模型增加一个 mode seeking regularizer[1] 来解决:
所以信息熵损失函数定义为:
其中 为教师模型。
对于两个 latent code 和 ,希望在 和 生成的图片教师模型输出相似的同时,尽量拉开 和 的距离。
损失函数部分对应代码 (来自作者官方 github):
for epoch in range(args.n_epochs):
for i in range(120):
generator.train() # have effect
z1 = Variable(torch.randn(int(args.batch_size/2), args.latent_dim)).to(device)
z2 = Variable(torch.randn(int(args.batch_size/2), args.latent_dim)).to(device)
z = torch.cat((z1, z2), 0)
optimizer_G.zero_grad()
gen_imgs, state_G = generator(z)
gen_imgs1, gen_imgs2 = torch.split(gen_imgs, z1.size(0), dim=0)
outputs_T1, features_T1, *activations_T1 = teacher(gen_imgs1, out_feature=True, out_activation=True)
outputs_T2, features_T2, *activations_T2 = teacher(gen_imgs2, out_feature=True, out_activation=True)
outputs_T = torch.cat((outputs_T1, outputs_T2))
# one-hot loss
pred = outputs_T.data.max(1)[1]
loss_one_hot = criterion(outputs_T, pred)
# information entropy loss
mean_softmax_T = torch.nn.functional.softmax(outputs_T, dim=1).mean(dim=0)
loss_information_entropy = (mean_softmax_T * torch.log(mean_softmax_T)).sum()
softmax_o_T1 = torch.nn.functional.softmax(outputs_T1, dim=1)
softmax_o_T2 = torch.nn.functional.softmax(outputs_T2, dim=1)
lz = torch.norm(gen_imgs2 - gen_imgs1) / torch.norm(softmax_o_T2 - softmax_o_T1)
loss_diversity_seeking = 1 / (lz + 1 * 1e-20)
loss = torch.exp(loss_one_hot - loss_oh_prev) + torch.exp(loss_information_entropy - loss_ie_pre) + loss_diversity_seeking
loss.backward()
optimizer_G.step()
if i == 1:
loss_oh_prev = loss_one_hot.detach()
loss_ie_pre = loss_information_entropy.detach()
print("[Epoch %d/%d] [loss_kd: %f] " % (epoch, args.n_epochs, loss.item()))
with open(args.output_file, 'a') as f:
f.write(str(epoch) + ',' + str(i) + ',' + str(loss_one_hot.item()) + ',' + str(loss_information_entropy.item()) + ','
+ str(loss_diversity_seeking.item()) + ',' + str(loss.item()) + '\n')
f.close()
最后,我们将这三个损失函数 (4,6,7式) 组合起来,就可以得到我们生成器总的损失函数:
式中, 和 是上一个 epoch 的 和 值,使用这样的指数形式的目的是降低超参数的敏感性,使得对超参数的选择更加鲁棒。根据指数函数的性质,当 和 的值显著增加时,会得到很大的惩罚值,而当 和 的值减小时,指数损失函数又接近线性。通过优化以上的损失函数,我们可以持续地减小 和 。
对应代码:
loss = torch.exp(loss_one_hot - loss_oh_prev) + torch.exp(loss_information_entropy - loss_ie_pre) + loss_diversity_seeking
通过优化以上的损失函数,训练得到的生成器可以和真实的样本在待压缩网络具有类似的响应,从而更接近真实样本,且提高了生成数据的多样性。
1.1.3 实验结果
作者在MNIST、SVHN、CIFAR10三个数据集上分别进行了实验。
GAN 的 Generator 的架构和 DAFL 保持一致,每个 epoch 固定为 120 个 iteration,不同数据集的实验设置如下图1所示。
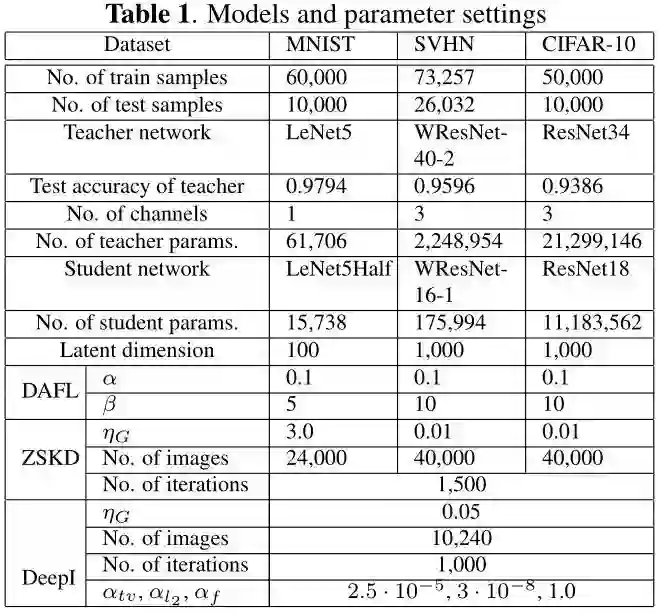
MNIST 实验
MNIST 数据集: 10类,60000 training+10000 testing。
教师模型使用 LeNet-5,通道数目减半作为学生模型 (LeNet-5-HALF)。
SVHN 实验
SVHN 数据集: 10类,73257 training+26032 testing。
作者还在 SVHN 数据集上进行了实验,使用的教师和学生模型分别为 WResNet-40-2 和 WResNet-16-1。
CIFAR 实验
CIFAR-10 数据集: 10类,50000 training+10000 testing。
作者还在 CIFAR-10 数据集上进行了实验,使用的教师和学生模型分别为 Resnet-34 和 Resnet-18。
以上3个数据集的实验结果如下图2所示。显然,RDSKD 和 DAFL 在测试准确性以及生成图像的质量和多样性方面都比 Deep Inversion 和 ZSKD 表现得更好。一般而言,生成图片的 IS/FID/LPIPS 分数越好,学生模型的精度越高。但是最好的 IS/FID/LPIPS 分数并不总是保证最好的学生网络。这是因为知识蒸馏需要的输入数据不仅要求它们的真实性,还要求它们的输出通过 KD 的可传递性。在 RDSKD 中,生成的样本足够真实,但略有失真 ,如下图3中的 RDSKD 和 DAFL 生成的 MNIST 训练数据。这种失真在提高 KD 性能方面起着关键作用。
另外,尽管 RDSKD 的学生模型最佳精度与 DAFL 相同(例如,当 时,MNIST 为 0.976),但在不同的生成器学习率 下,RDSKD 比 DAFL 更稳定,这表明 RDSKD 的学习率比 DAFL 更容易调整,SVHN 数据集和 CIFAR-10 上也是如此。
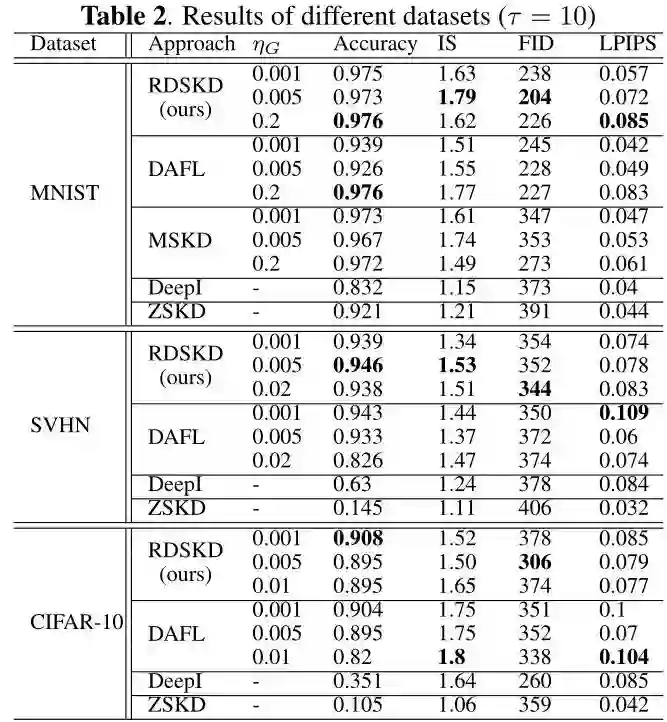

作者同时可视化了不同方法的 的值,如下图4所示。发现当 方差较大时,测试精度较高,而 均值对学生网络的精度没有显著影响。本文所提出的多样性导向的正则化损失函数允许生成器生成更多样的图像,这些图像跟随真实图像的分布,防止过拟合,并且有助于更高的测试精度。
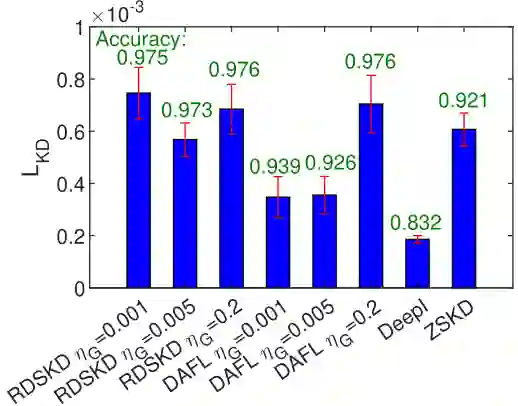
对比实验:
下图4是不同 Epochs 数训练生成器时,学生模型的精度和生成图像的 LPIPS 分数。生成器训练不是越长越好的, 此外由于生成的图像更加多样化,与真实数据分布更加匹配,因此 RDSKD 在不同 Epochs 数的表现比 DAFL 表现得更好、更稳定。
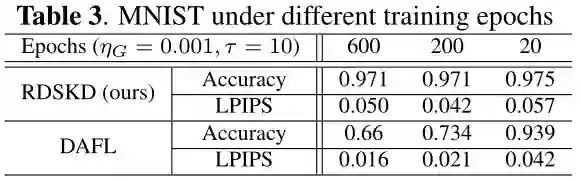
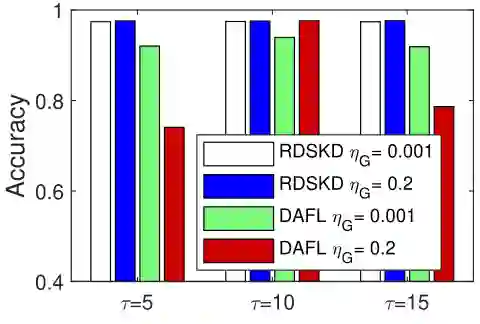
下图5描述了 RDSKD 和 DAFL 在 MNIST 上不同蒸馏温度 和生成器学习率 的比较,作者对比了 以及 这6种情况。显然,RDSKD 对温度的变化和学习率的变化都表现得更鲁棒。
2 无需原始训练数据的对抗蒸馏技术 (CVPR 2020)
论文名称:Data-Free Adversarial Distillation
论文地址:
https://arxiv.org/pdf/1912.11006.pdf
开源地址:
https://github.com/VainF/Data-Free-Adversarial-Distillation
2.1 DFAD 原理分析:
2.1.1 Data-Free 模型压缩的方法分类
Data-Free 模型压缩的方法主要可以归结为3类[2]:
-
噪声优化 (Noise optimization) -
数据重建 (Generative reconstruction) -
对抗探索 (Adversarial exploration)
噪声优化 (Noise optimization) 方法的特点是分为2步:第一步是优化噪声数据,使之优化成为可以拿来训练的样本。第二步是知识蒸馏。这种方法的典型代表是 Deep Inversion,Deep Dream,解读如下:
模型压缩经典解读:解决训练数据问题,无需数据的神经网络压缩技术
数据重建 (Generative reconstruction) 方法的特点是通过 GAN 的生成器输入随机噪声,并生成训练样本。期间通过若干精心设计的损失函数,以教师模型为判别器来指导生成器的训练。得到的训练样本同时用于知识蒸馏。这种方法的代表是 DAFL 和上一节的 RDSKD,解读如下:
模型压缩经典解读:解决训练数据问题,无需数据的神经网络压缩技术...(下)
对抗探索 (Adversarial exploration) 方法的代表就是本文 DFAD。数据重建 (Generative reconstruction) 类的 DAFL 方法的假设是 "合适的样本通常会使教师模型的输出可信度很高 (输出接近独热编码)"。本文作者认为这个假设不十分合理。此外,这些现有的无数据模型压缩方法只考虑了固定的教师模型,忽略了来自学生网络的信息。
2.1.2 DFAD 对抗蒸馏方法
本文提出了一种对抗蒸馏的方法,框图如下图7所示。
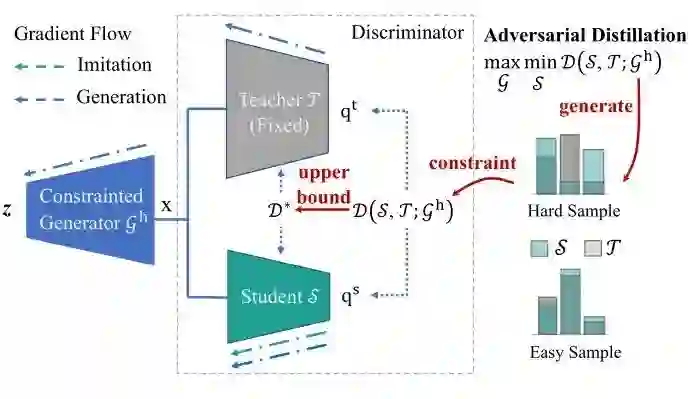
定义预训练好的教师模型为 ,待优化的学生模型为 。定义一个数据生成器 用于产生训练数据。作者把训练数据分为2种:hard sample 和 easy sample,如上图7所示。hard sample 就是 teacher 和 student 模型输出的类别明显不同的样本,easy sample 就是 teacher 和 student 模型输出的类别相同,但是概率分布不同的样本。作者通过下式来衡量 teacher 和 student 模型的差异 (Discrepancy):
式中, 是输出的类别数,比如 CIFAR-10 就是10。我们发现作者通过教师和学生模型输出分布的 范数来衡量二者的差异。很明显,hard sample 的 teacher 和 student 模型的差异更大,即有:
式中, 指的是全部数据空间的均匀分布,上式的意思是 hard sample 的 teacher 和 student 模型的差异高于平均。
接下来对抗蒸馏的想法是:
-
学生模型通过不断学习,使得一些 hard sample 渐渐转变成为了 easy sample。 -
生成器需要不断产生一些新的 head sample。 -
这两个过程不断迭代,以同时训练生成器和学生模型。
对抗训练过程的两个阶段:模仿阶段 (the imitation stage) 和 生成阶段 (the generation stage),这个过程类似于 GAN,只是 Teacher 和 Student 模型一起作为 Discriminator。
模仿阶段 (the imitation stage)
the imitation stage 固定住生成器 的参数,只更新 Student 模型的参数。更新的方法是尽量降低学生模型和教师模型之间的差异。那么这种差异衡量的方式有很多种,比如早期的 KD 方法采用的是 KL Divergence 或者 MSE Loss 来衡量教师和学生模型的差异。MSE Loss 对于有数据的知识蒸馏情况是非常有效的,但是在数据是生成的的情况下,这两种 loss 会产生衰减的梯度,使生成器的学习失效。因此,本文作者采用 Mean Absolute Error (MAE Loss):
采用这种 loss 之后,设学生模型的输出是 ,教师模型的输出是 ,Mean Absolute Error 对学生模型参数的梯度可以计算为:
当学生模型和教师模型十分接近时,即 接近0时,梯度也不会衰减为0。
直觉上,这个阶段和 KD 非常相似,但目标略有不同。在 KD 中,学生可以贪婪地从老师产生的 soft-target 中学习,因为这些目标是从真实数据中获得的,它们包含着对特定任务有用的知识。然而,在 data-free 的设置中,我们无法访问任何原始训练数据。生成器合成的假样本不保证有用,尤其是在训练开始的时候。
生成阶段 (the generation stage)
the generation stage 固定住 Student 模型的参数,只更新生成器 的参数。它受到了人类学习过程的启发,在这个过程中,基础知识是在一开始学习的,然后通过解决更具挑战性的问题来掌握更高级的知识。因此,在这个阶段,我们鼓励生成器产生更多困难的训练样本。实现这一目标的一个简单方法是简单地将负的 Mean Absolute Error 作为优化生成器的目标,也就是通过更新生成器的参数,使得学生模型和教师模型的差异拉大。
梯度反向传播会先通过 Teacher 和 Student 所组成的 Discriminator,那么在这个过程中梯度不能够消失,否则生成器无法得到良好的训练,所以才有16式的 MAE Loss。在对抗训练开始时,来自 Teacher 的梯度是不可缺少的,因为随机初始化的 Student 实际上无法提供什么有用的信息。
但是,若直接使用17式训练,可能是不稳定的,因为此时生成器倾向于生成一些 "异常" 的训练样本,这些样本通过 Teacher 和 Student 时,会产生极其不同的预测标签。它恶化了对抗性训练过程,使数据分布发生剧烈变化。因此,确保生成的样本正常至关重要。为此,作者建议将 MAE 的对数值作为生成阶段的损失函数,即将17式变为:
采用18式的好处是:当生成器产生的样本较难,使得 Teacher 和 Student 输出差距很大时,损失函数的梯度很小。它减缓了生成器的训练,使训练更加稳定。若没有对数项,当Teacher 和 Student 输出差距很大时,损失函数的梯度很小依旧很大,使得我们需要仔细调整学习率,让训练尽可能稳定。
两阶段训练的算法概括为下图8。

经过若干步骤的训练,系统将理想地达到一个平衡点,此时 Student 已经掌握了所有困难样本,生成器也无法产生一些样本使得两个模型 Student 和 Teacher 的输出有较大的差异,在这种情况下,Student 在功能上与 Teacher 相同。
在对抗训练中保持稳定是至关重要的。在模仿阶段 (the imitation stage),作者对学生模型进行 次更新,再更新一次生成器,以保证其收敛性。然而,由于没有训练得很好的生成器输出的训练样本不能保证对我们的任务有用,所以 的值不能设置得太大。作者发现 可以使训练稳定。此外,作者建议在密集预测任务 (如分割任务) 中使用自适应损失 。在分类任务中,仅使用少量样本来计算生成损失,并且统计信息不准确,因此更倾向于使用 。
2.1.3 实验结果
DFAD 方法在图像分类和语义分割2个任务上进行了实验。
分类任务数据集:
MNIST:Teacher:LeNet-5,Student:LeNet-5-Half
CIFAR10:Teacher:ResNet-34,Student:ResNet-18
CIFAR100:Teacher:ResNet-34,Student:ResNet-18
Caltech101:Teacher:ResNet-34,Student:ResNet-18
分割任务数据集:
CamVid:Teacher:DeepLabV3 (ResNet-50 Backbone),Student:DeepLabV3 (Mobilenet-V2 Backbone)
NYUv2:Teacher:DeepLabV3 (ResNet-50 Backbone),Student:DeepLabV3 (Mobilenet-V2 Backbone)
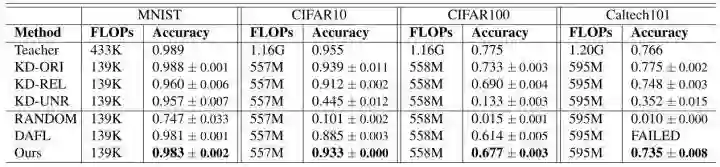
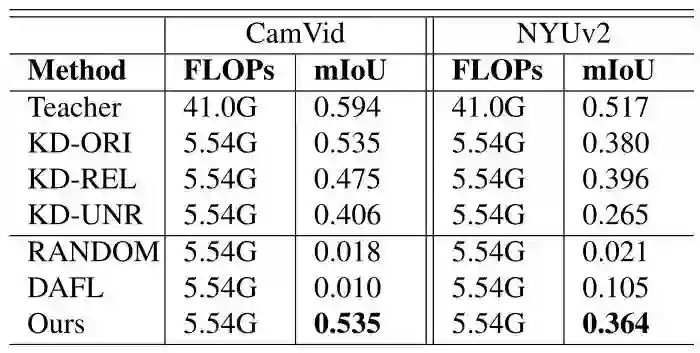
实验结果如下图7所示。上面一部分是有数据知识蒸馏的实验结果,下面一部分是 data-free 的设置。KD-ORI需要原始的训练数据,而 KD-REL 和 KD-UNR 则使用一些未标记的替代数据进行训练。在 KD-REL 中,训练数据应该与原始训练数据相似。然而,替代数据和原始数据之间的领域差异是不可避免的,这将导致知识的不完整,所以 KD-REL 的精度略低于 KD-ORI。表格的第二部分显示了 data-free 蒸馏方法的结果。CIFAR 数据集 batch size 设置为256,Caltech101 数据集 batch size 设置为64。我们的对抗性学习方法在无数据方法中达到了最高的准确率,其性能甚至可以与那些数据驱动的方法相媲美。请注意,我们将Caltech101的数据集 batch size 设置为64,在这种情况下,DAFL 方法失败了。
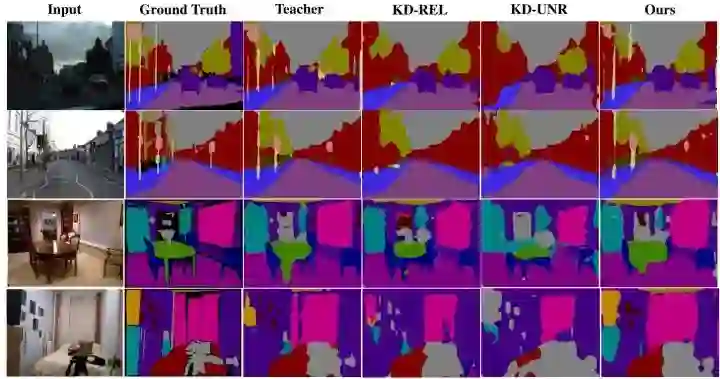
DFAD 方法生成的图片如下图8所示,上面的部分是生成器生成的图片,下面的是真实数据集的图片。

语义分割实验中,作者采用 ImageNet pretrained ResNet-50 来初始化 Teacher,并从头开始训练所有 Student。数据驱动方法中的所有模型都是用128×128裁剪图像训练的。对于无数据方法,直接生成128×128的图像进行训练。下图9,10显示了用不同方法获得的学生模型的性能。可以看到,在 CamVid 上,DFAD 即使与需要原始的训练数据的 KD-ORI 相比也获得了有竞争力的学生模型性能。在 NYU v2 上,DFAD 超越了 KD-UNR 和所有无数据方法。
小结
本文介绍了2种无需数据的知识蒸馏方法,RDSKD 通过多样性导向的正则化损失函数来提高生成样本的多样性,并证明对于学生模型的训练至关重要。DFAD 提出了一种对抗蒸馏的策略,对抗训练过程的两个阶段:模仿阶段 (the imitation stage) 和 生成阶段 (the generation stage),这个过程类似于 GAN,只是 Teacher 和 Student 模型一起作为 Discriminator。
参考
-
^ab[1] https://openaccess.thecvf.com/content_CVPR_2019/papers/Mao_Mode_Seeking_Generative_Adversarial_Networks_for_Diverse_Image_Synthesis_CVPR_2019_paper.pdf -
^[2] https://arxiv.org/abs/2112.15278
-
https://pytorch.org/tutorials/beginner/introyt/autogradyt_tutorial.html)
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选



