搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了(二十三)

极市导读
最近,南京大学吴建鑫团队提出了一种新方法,只需2040张图片即可训练视觉 Transformer 模型。他们在 2040 张花的图像上从头开始训练,达到了96.7%的准确率,表明用小数据训练视觉 Transformer 模型也是可行的。另外在 ViT 主干下的 7 个小型数据集上从头开始训练时,也获得了 SOTA 的结果。>>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
42 仅用2040张图片训练出的视觉 Transformer 模型
(来自南京大学)
42.1 IDMM 原理分析
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
视觉 Transformer 模型在计算机视觉领域取得了巨大的成功,甚至大有取代 CNN 之势。但是相比 CNN,视觉 Transformer 模型缺乏卷积固有的归纳偏置 (inductive bias),因此造成训练需要更多的数据,通常要在大型数据集 JFT-300M 或至少在 ImageNet 上进行预训练,很少有人研究少量数据训练视觉 Transformer 模型。
最近,南京大学吴建鑫团队提出了一种新方法,只需2040张图片即可训练视觉 Transformer 模型。
他们在 2040 张花 (Flowers) 的图像上从头开始训练,达到了96.7%的准确率,表明用小数据训练视觉 Transformer 模型也是可行的。另外在 ViT 主干下的 7 个小型数据集上从头开始训练时,也获得了 SOTA 的结果。研究者还讨论了小数据集的迁移能力,发现从小数据集学习的表示甚至可以改善大规模 ImageNet 的训练。
42 仅用2040张图片训练出的视觉 Transformer 模型
论文名称:Training Vision Transformers with Only 2040 Images
论文地址:
https://arxiv.org/abs/2201.10728
42.1 IDMM 原理分析:
Transformers 作为卷积神经网络的替代品,已经广泛应用于视觉识别任务中。但是 Transformer 模型的缺点是 data-hungry, 当使用相同量级的数据集 (比如 ImageNet,128万 training data) 时,Transformer 的性能比相似计算量的 ResNet 模型更差。一种可能是因为它们不具备卷积模型固有的某些理想属性,像归纳偏置。这使得训练好 Transformer 模型需要更多的训练数据。
对于这个问题,一种解决方案如 Swin Transformer,PVT,T2T-ViT,CvT 等等将卷积结构引入 Transformer 模型中,为其提供归纳偏置。这些架构享受了这两种模式的优点,Self-attention 模块建模 long-range dependencies,而卷积模块建模 short-range dependencies。
然而,ImageNet 仍然是一个大规模数据集,在小数据集 (例如,仅仅 2040 张图像) 上训练时,这些网络的行为是什么仍然不清楚。从数据、计算和灵活性的角度来看,我们不能总是依赖这样的大规模数据集。
IDMM 的全称是 Instance Discrimination with Multi-crop and CutMix (IDMM),基于下面这几个 paper:
Rethinking self-supervised learning: Small is beautiful (ArXiv:2103.13559)
Discriminative unsupervised feature learning with convolutional neural networks (NeurIPS 2014)
IDMM 的贡献:
本质上是一种 Self-supervised Training Transformer 的方法,在7个小数据集上 SOTA。对于 ImageNet 数据集,使用小数据集预训练,ImageNet 数据集作 Fine-tune,也能够展示出不错的迁移性能。Self-supervised Training 的介绍可以参考下面的链接:
Self-Supervised Learning 不仅是在 NLP 领域,在 CV, 语音领域也有很多经典的工作。它可以分成3类:Data Centric, Prediction (也叫 Generative) 和 Contracstive。
其中,Contracstive learning 的范式又叫做 non-parametric instance discrimination,例如 SimCLR 和 MoCo。non-parametric instance discrimination 一般采用双分支的结构。另一些方法使用参数化的单分支结构,例如:
[PIC]: Parametric instance classification for unsupervised visual feature learning (NeurIPS 2020)
IDMM 的原理 (Parametric instance discrimination):
在理解 IDMM 之前,首先需要明确的一点是 IDMM 所使用的这种 Self-supervised Learning 的做法叫做 Parametric instance discrimination。这种方法最大的特点就是把每个输入当做为一类,也就是说每个 instance 的 label 都是不一样的。这么做的原因也很好理解:因为 Self-supervised Learning 不是有监督学习,它是没有标签的嘛,所以我们就人为地给每个数据打一个标签,把每个输入都当做为一类。比如我的数据集有 张图片,那就认为这个数据集有 个不同的类别。以这种做法为标志的自监督学习方法就称之为:Parametric instance discrimination。
IDMM 的原理可以概括为:"小数据集上进行自监督学习 + 几个辅助的 Data Augmentation 策略"。我们分三步介绍:
-
为什么研究在小数据集上进行 ViT 自监督学习 -
Parametric instance discrimination 方法 -
几个辅助的 Data Augmentation 策略
为什么研究在小数据集上进行 ViT 自监督学习
从模型特征上看,ViT 模型因为缺乏 CNN 的归纳偏置先验,所以更加 data-hungry,对数据要求更不易满足。
从计算复杂度上看,大规模数据集,大量的训练 Epochs,和复杂骨干网络的结合意味着 ViT 训练的计算成本极高。这种现象使得 ViT 成为少数机构研究人员的特权。
从灵活度上看,Pretraining + 下游任务 Fine-tuning 的范式有时会变得很麻烦。例如,我们可能需要为同一任务训练10个不同的模型,并将其部署到不同的硬件平台上,但在大规模数据集上预训练10个模型是不切实际的。此外,当我们需要在终端设备上部署不同尺寸的模型时,从头开始的训练提供了更好的 Accuracy-Parameter 权衡。
Parametric instance discrimination 方法
那么,为什么要使用 Parametric instance discrimination 的方法,而不是 Non-parametric instance discrimination 的自监督学习方法 (MoCo,SimCLR 等等) 咧?
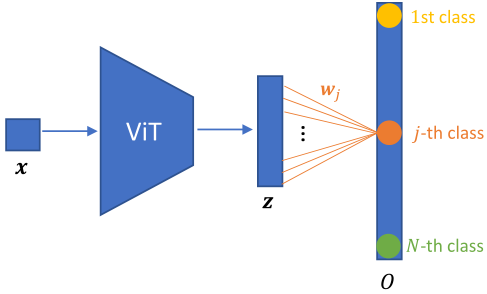
如上图1所示,假设输入图片 送入网络 ,得到输出的特征是 ,式中 为图片的数量。之后通过一个 FC 层 作为分类器完成分类任务,其中 为特征的维度, 为数据集的类别数,正好与图片的数量相等。最终的输出结果为 。我们把这个过程统称为 Parametric Instance Discrimination。
对于 Parametric Instance Discrimination 而言,损失函数一般是:
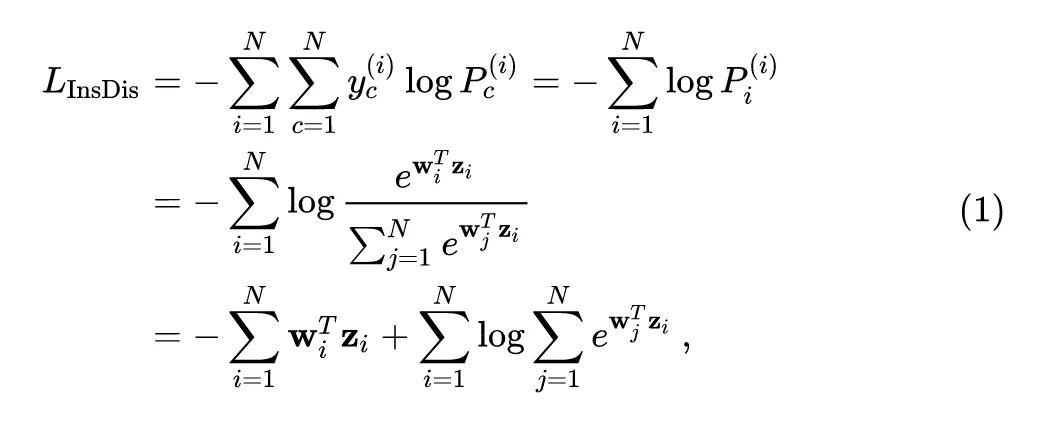
式中的角标 代表 instance 的索引,角标 代表类别的索引。因为 Instance Discrimination 任务数据集的类别数,正好与图片的数量相等,故这种任务的标签有一定的规律,即: 。
下面我们再分析 Contracstive learning 范式的损失函数:
对于每张输入图片 ,有2个 positive pairs,分别为 (对应的特征分别是 )。Contracstive learning 范式的损失函数可以写成:
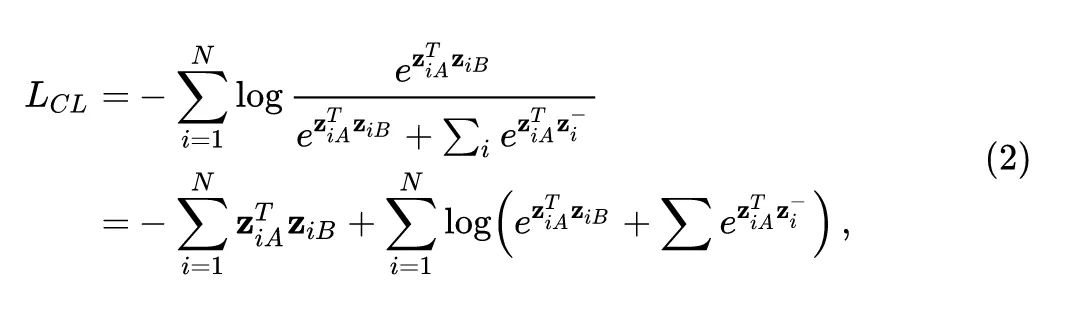
式中, 代表所有的 negative pairs,即所有 的 和 。对于2式,我们考虑第 项:

那么对于 instance discrimination 任务,若我们设置 ,则上式3变为:
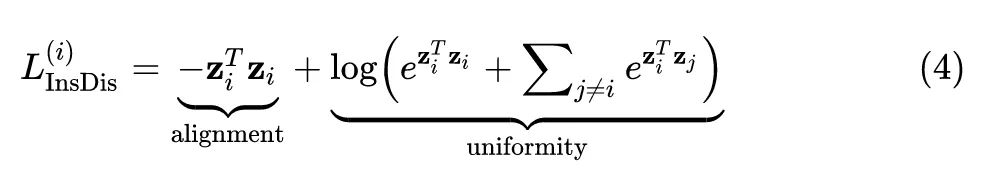
对比上式3和4不难发现都是有2项:alignment 和 uniformity,且结构相似。上式3和4的优化目标都是希望那些 positive pairs 之间的距离更接近些,negative pairs 之间的距离更远些。因此,作者得出结论,当设置 时,Instance discrimination Loss 近似等于 Contracstive learning Loss。
换句话说,Contracstive learning 是 Instance discrimination 的一种特殊情况,即:每个 被设置为当前批次中 的特征 (即,Contracstive learning 是 一种 Non-parametric 的 Instance discrimination)。相比之下,实例识别中的可学习的 FC 层 至少有两个优点:
-
正如许多 Contracstive learning 方法 (如 SimCLR ) 验证的那样,在特征之后采用额外的 Projection head (MLP) 对于学习良好的表征至关重要。然而,这个投影头对于 Instance discrimination 却不是必要的,因为 Instance discrimination 自带的可学习的 FC 层 。 -
找到 Instance (类) 之间潜在的相似之处。现在作者考虑 DeepClustering,它的聚类损失可以重新表述如下:
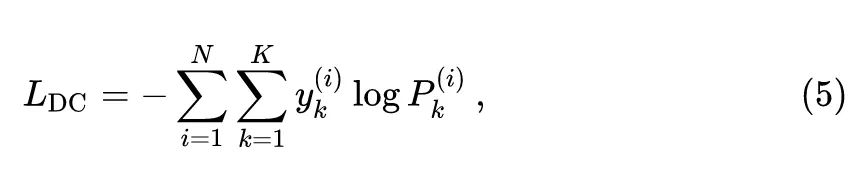
式中, 代表聚类的数量, 代表第 个实例是否属于第 个类别, 代表第 个实例属于第 个类别的概率。令 代表第 个类别中的样本数量,如果我们将会所有的 设置为相同,即:对于所有 都有 ,则有:
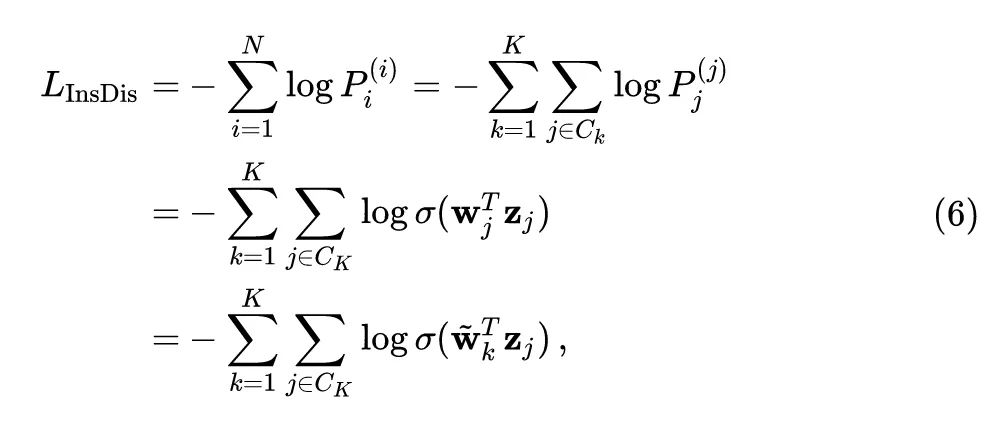
式中, 是 softmax 函数。类似地,上式5可以变为:
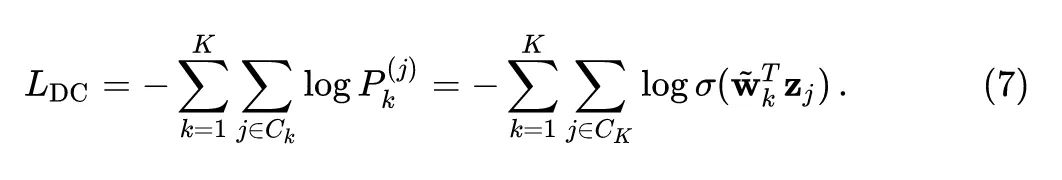
因此,当我们适当地设置权重 时,Instance discrimination 相当于 DeepClustering,这可以找到 Instance (类) 之间潜在的相似之处。
几个辅助的 Data Augmentation 策略
梯度分析
考虑上式1中的第 项:
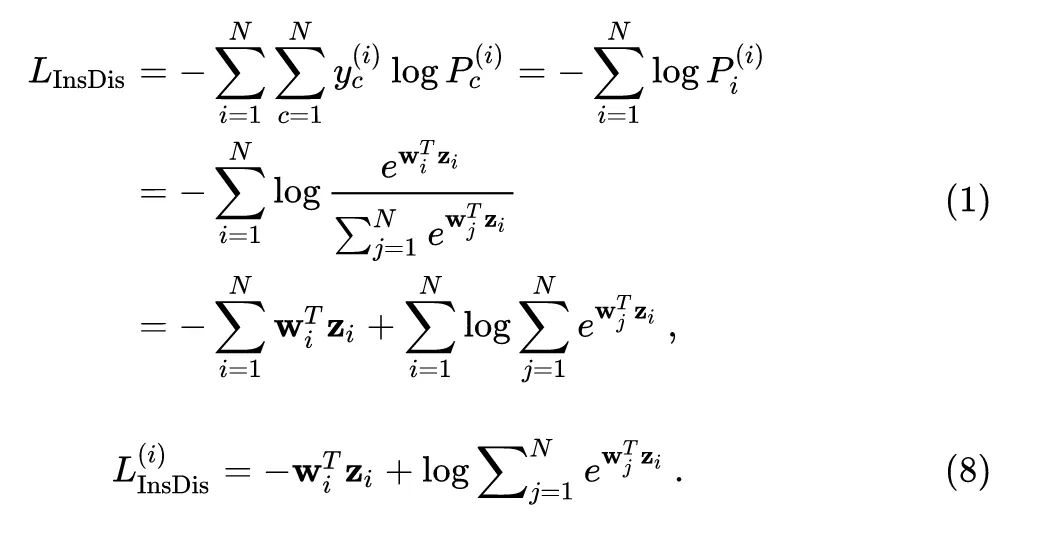
目标函数对 的导数可以写成:
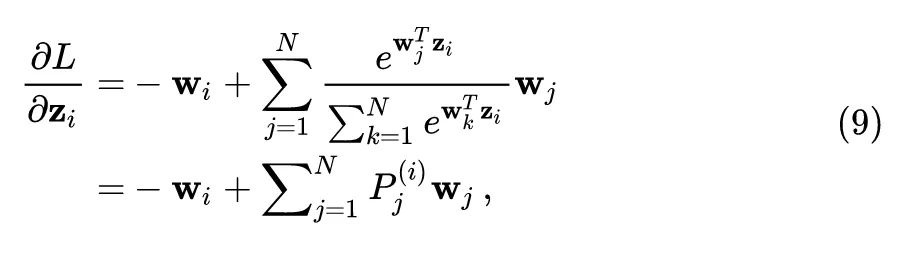
目标函数对 的导数可以写成:
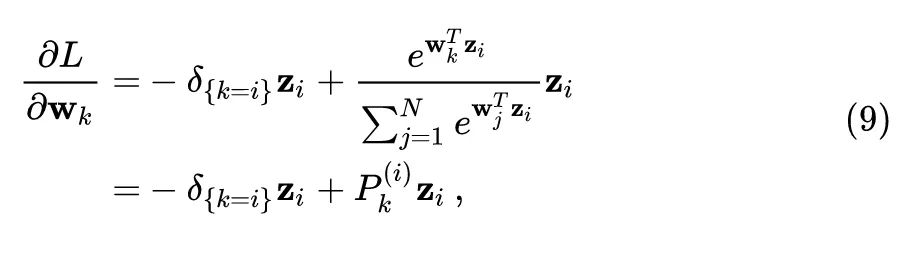
注意到对于 Instance discrimination 任务而言通过 很大,所以一般有 ,因而 。
所以这意味着对于 的更新将会非常不频繁 (infrequent updating problem)。因为本文使用小数据集,所以使用 CutMix 和 label smoothing 技术使得 的更新变得更加频繁些。
使用了 label smoothing 技术之后,数据集的标签变成了:
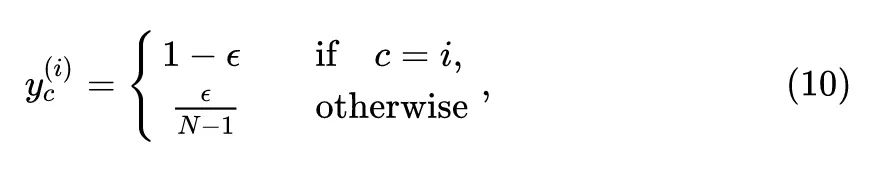
式中, 代表 smoothing factor,默认设为0.1。至此,Instance discrimination 任务的损失函数从1式变为11式:
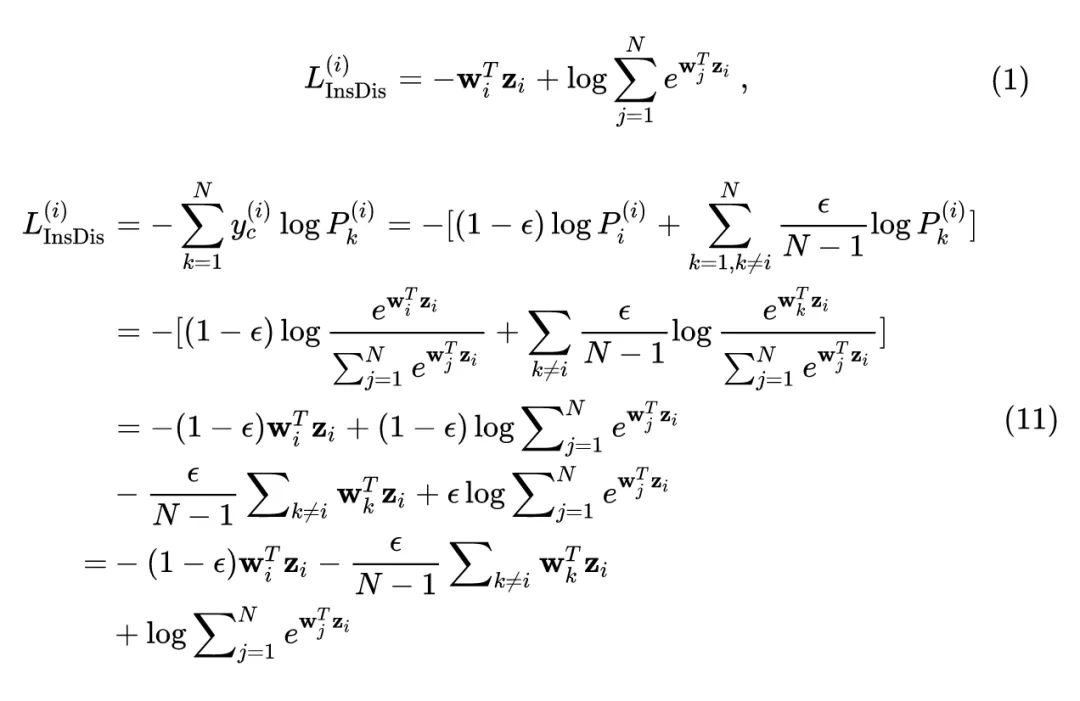
使用了 CutMix 技术之后,上式变成了:
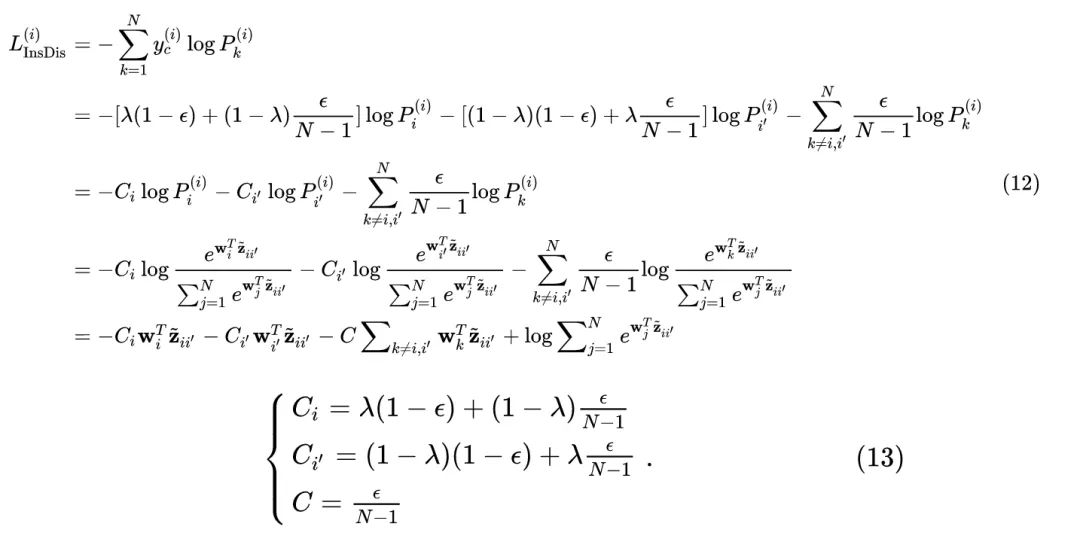
式中, 是 Cutmix 的超参数, 是 Cutmix 的另一个 instance, 是这个 instance 和 Cutmix 得到的 instance 的混合输出特征。
目标函数对 的导数可以写成:
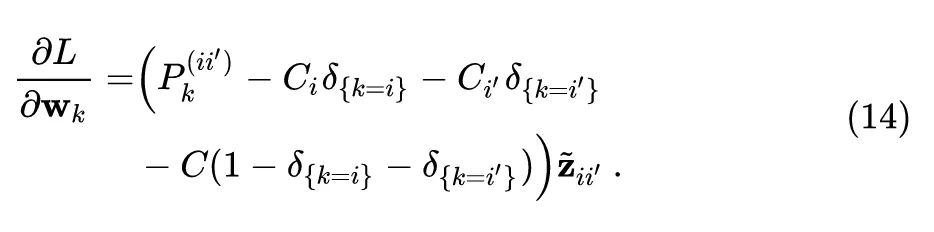
如果我们设置 ,则有 , 。因此对于那些 的负样本而言 ,则 依然可以得到有效的更新,减轻了上面的对于 的更新将会非常不频繁 (infrequent updating problem) 的问题。
综上所述,IDMM 一共使用了以下的策略:
-
Small resolution:小分辨率对小数据集很有用。 -
Multi-crop:和 Contrastive Learning 的方法一致,使用了同一张图片的多个 Crops,如上式3所示,这样能够同时捕捉 Feature alignment 和 uniformity。 -
CutMix and label smoothing:如上文分析,使用 CutMix 和 label smoothing 技术使得 的更新变得更加频繁些。
所以综上所述,IDMM 的全称是 Instance Discrimination with Multi-crop and CutMix,它本质上是一种以 Instance Discrimination 的自监督方式训练视觉 Transformer 模型的方法。Instance Discrimination 的自监督方式假设数据集的每一张图片1都是一个类别,即:数据集图片的数量和类别数量一致。除此以外,IDMM 使用了 Small resolution,Multi-crop,CutMix and label smoothing 技术,辅助进行自监督训练。本文最大的亮点是 "小数据集上进行自监督学习 + 几个辅助的 Data Augmentation 策略",所以取了题目:Training Vision Transformers with Only 2040 Images (刚好是用的7个小数据集尺寸最小的 Flowers 的数据集大小)。难得的地方是作者从梯度计算的角度理论分析了为什么几个辅助的 Data Augmentation 策略对于 Instance Discrimination 的自监督学习是有效的,给出了不错的解释。
Experiment
小数据集从头训练实验结果
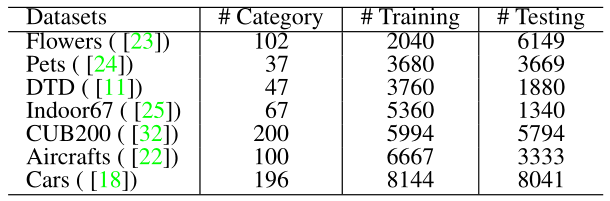
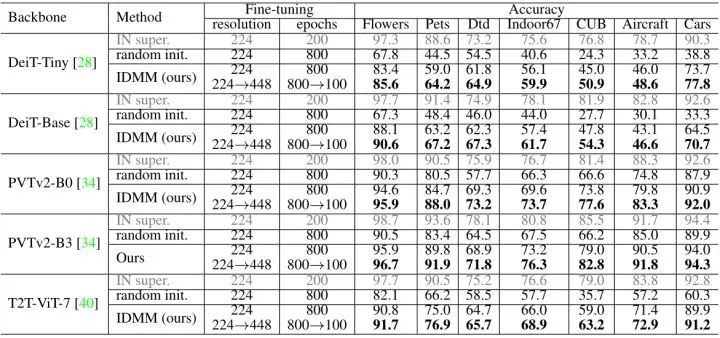
作者首先在下图2所示的7个小数据集上进行实验。这些实验中作者从头训练 Transformer 模型,但是也依然包含2个阶段:Pretraining 和 Fine-tuning,只是使用的数据集都是小数据集。Pretraining 阶段遵循上面所描述的自监督学习的方式,不使用任何标签;而 Fine-tuning 阶段为有监督学习,使用 Cross-Entropy Loss。
接下来就是详细的实验细节:
Pretraining 阶段: AdamW 优化器,112×112 resolution,800 Epochs,batch size=256,lr=5e-4,weight decay=1e-3。
Fine-tune 阶段: AdamW 优化器,224×224 resolution,200 Epochs,batch size=256,lr=5e-4,weight decay=1e-3。
结果如下图3所示。即使从头开始训练,SSL 预处理也很有用,并且所有 SSL 方法的性能都优于随机初始化。IDMM 在所有这些数据集上都达到了最高的精度。当图像数量较少时 (例如花和宠物),IDMM 的优势更加明显。
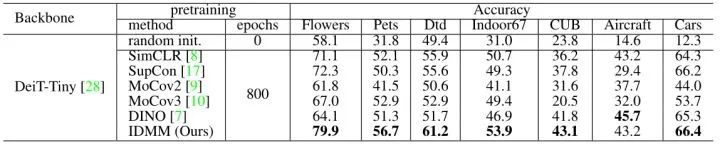
之后,作者又尝试了 Fine-tune 更长的 Epochs,以尝试获得更好的结果。之前的实验是在分辨率为224×224的情况下 Fine-tune 200 Epochs,现在改为在分辨率为224×224的情况下 Fine-tune 800 Epochs,并再在分辨率为448×448的情况下 Fine-tune 100 Epochs。结果如下图4所示。而且,IDMM 方法从头开始训练得到的性能和使用ImageNet 预训练模型的性能之间的差距已经大大缩小,这表明从头开始训练甚至对于 ViT 模型也是有希望的。
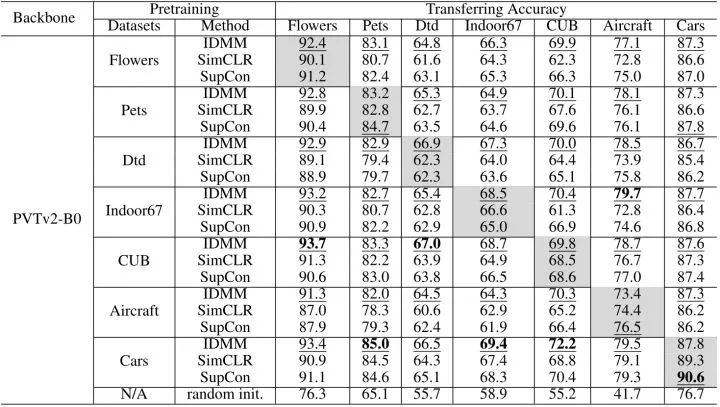
小数据集预训练之后的迁移性能实验
在研究了 ViT 模型的小数据集从头训练实验结果之后,作者又研究了不同方法小数据集预训练之后在小数据集 (Flowers 等) 上的迁移性能,结果如下图5所示。从图5中可以得到下面结论:
即使在小数据集上预训练,ViT 模型也具有很好的迁移性能。这意味着我们可以使用来自小数据集的预训练模型来转移到不同领域的其他数据集,以提高性能。
与 SimCLR 和 SupCon 相比,IDMM 在所有这些数据集上都具有更高的传输性能这可能要归功于可学习的全连接层 。
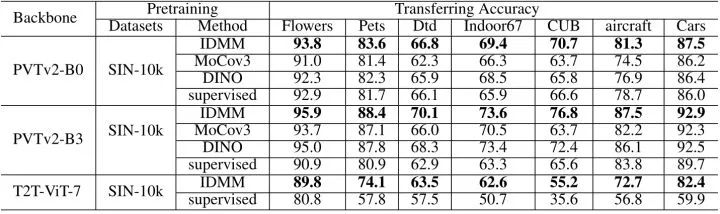
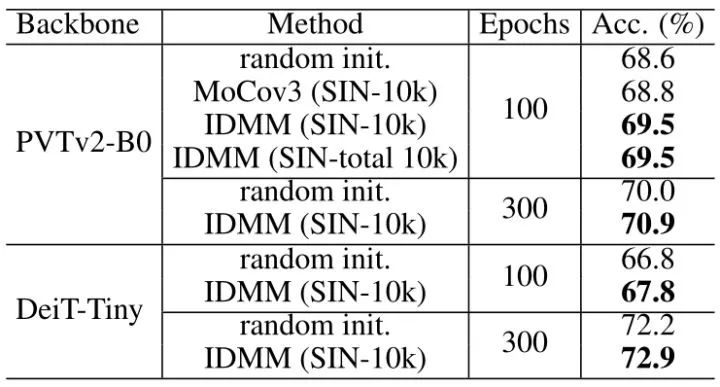
下图6展示了不同方法在 Small ImageNet (SIN-10k) 上预训练之后在小数据集 (Flowers 等) 上的迁移性能。Small ImageNet 是从 ImageNet 里面采样了10000张图片 (每一类随机采样10张,一共10k张) 之后形成的小数据集。通过对 SIN-10k 上的模型进行预训练,作者评估了迁移到小数据集上的迁移性能 (如图6所示) 以及迁移到 ImageNet 上的迁移性能 (如图7所示)。IDMM 比这些比较方法有很大的优势,并且在 SIN-10k 上学习的 Representation 可以作为传输到其他数据集时的良好初始化。值得一提的是,对于 ImageNet,即使不采用每一类随机采样10张 (共10k张),而是只保证一共随机采样10k张 (SIN-total 10k) 的设定,性能也不发生变化。可以看出,采样时是否使用标签 (平衡与否) 对结果没有影响。
总结
IDMM 的全称是 Instance Discrimination with Multi-crop and CutMix,它本质上是一种以 Instance Discrimination 的自监督方式训练视觉 Transformer 模型的方法。Instance Discrimination 的自监督方式假设数据集的每一张图片1都是一个类别,即:数据集图片的数量和类别数量一致。除此以外,IDMM 使用了 Small resolution,Multi-crop,CutMix and label smoothing 技术,辅助进行自监督训练。本文最大的亮点是 "小数据集上进行自监督学习 + 几个辅助的 Data Augmentation 策略",所以取了题目:Training Vision Transformers with Only 2040 Images (刚好是用的7个小数据集尺寸最小的 Flowers 的数据集大小)。难得的地方是作者从梯度计算的角度理论分析了为什么几个辅助的 Data Augmentation 策略对于 Instance Discrimination 的自监督学习是有效的,给出了不错的解释。
公众号后台回复“数据集”获取30+深度学习数据集下载~

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选




