模型压缩经典解读:隐私保护模型压缩技术Nasty Teacher,无惧模型“被蒸馏”!

极市导读
知识蒸馏作为一种模型压缩的重要技术,若被不恰当的利用,就会带来一系列的知识产权问题。本文提出了一个 "龌龊的教师模型"。相比常规 Teacher 模型,该模型在正常使用时性能保持不变或者略有下降,而在被知识蒸馏时得到的学生模型的性能很差,使得不法分子无法提供 KD 的手段完美地复制教师模型。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
深入浅出的模型压缩:你一定从未见过如此通俗易懂的Slimming操作
模型压缩经典解读:解决训练数据问题,无需数据的神经网络压缩技术
深入研究模型压缩经典Ghostnet:如何用少量计算生成大量特征图?
目录
1 避免模型被蒸馏,加强知识产权保护的 Nasty Teacher (ICLR 2021)
(来自加利福尼亚大学)
1.1 Nasty Teacher 原理分析
随着深度学习技术的发展,深度神经网络 (CNN) 已经被成功的应用于许多实际任务中 (例如,图片分类、物体检测、语音识别等)。由于 CNN 需要巨大的计算资源,为了将它直接应用到手机、摄像头等小型移动设备上,许多神经网络的压缩和加速算法被提出,其中知识蒸馏 (KD) 就是一种广泛使用的技术。然而,在某些情况下,这种技术更多的是一种"诅咒"而不是"祝福"。知识蒸馏的一个问题是知识产权 (Intellectual Properties, IPs) 被侵犯的风险,即使是我们发布的预训练模型没有开放源代码,可执行软件或是 API (Executable software or APIs),即模型完全是个黑箱。这其中包含多种原因:其一,Teacher 模型往往是开发者花费了很多的人力财力成本得到的,开发者有权利维持技术壁垒;其二,这些预训练模型包含着私有数据或者开发者不想去公开的数据,这些数据或信息在法律上或道德上被禁止公开共享。
但是,居心不良者依然可以通过 KD 的方法完美地 "复制 (replicate)" 一个出新模型,绕过知识产权的保护,达到某种目的。从这个意义来看,知识蒸馏作为一种模型压缩的重要技术,若被居心不良者不恰当的利用,就可以轻易盗取研究者花很多时间、精力和设备训练好的模型,带来一系列的知识产权问题。无数据 KD 方法是指不通过原始数据就能够完成模型的蒸馏,这一技术更加加剧了这个问题。无数据 KD 方法通过 Reverse Engineering 的方式从黑盒模型中恢复潜在的私人的训练数据,威胁所有者的数据隐私和安全。所以 KD 带来的问题可以总结为:
问题1: Data-Driven KD 方法被居心不良者利用,可以轻易地盗取研究者花很多时间、精力和设备训练好的模型。
问题2: Data-Free KD 方法被居心不良者利用,可以从黑盒模型中恢复潜在的私人的训练数据,威胁所有者的数据隐私和安全。
为了防止知识蒸馏的这种有害影响,本文想做的事情是想办法训练出一个不易被蒸馏的教师模型 (Undistillable Teacher Model),作者称这种教师模型为 "龌龊的教师模型 (Nasty Teacher)"。Nasty Teacher 的特点是:相比常规 Teacher 模型,在正常使用时性能保持不变或者略有下降,而在被知识蒸馏时得到的学生模型的性能很差,使得不法分子无法提供 KD 的手段完美地复制教师模型,从而做到保护模型所有者知识产权的作用,保护模型所有者的隐私。
总的来说,Nasty Teacher 的概念与对深度学习系统的后门攻击 (Backdoor Attack) 有关,它以一种 "Inperceptible" 的方式创建了一个实现 "对抗性" 目标的模型。然而,尽管后门攻击的目的是在特定输入触发时操纵或破坏中毒模型本身的性能,但 Nasty Teacher 的目标是破坏由此蒸馏或者衍生出来的学生网络的性能。构建一个Nasty Teacher 的主要目的是为了模型保护教师模型的知识产权。Nasty Teacher 和后门攻击的主要区别是:
-
后门攻击只能由预定义的模式触发,而 Nasty Teacher 的目标是使蒸馏操作得到的学生模型的性能很差。 -
后门攻击往往会毒害模型本身,而 Nasty Teacher 旨在破坏其他学生网络,同时保持教师模型自己的表现。 -
Nasty Teacher 的目标是防止知识泄露,以保护发布的知识产权,属于防御视角,而后门攻击倾向于通过触发攻击信号来破坏系统,属于攻击视角。
1.1 Nasty Teacher 原理分析
知识蒸馏通过从一个或多个训练有素的 "教师" 网络中提炼知识,以帮助 "学生" 网络的训练过程。通过模仿教师网络的软概率输出,学生网络能够吸收教师网络之前学习到的知识,并且学生网络的性能通常优于那些仅使用标签进行训练的网络。设预训练好的教师模型为 ,学生模型为 ,其中 和 分别代表网络的参数。设训练样本为 , 表示样本 通过网络 的输出结果。则学生模型 可以通过下式进行学习:
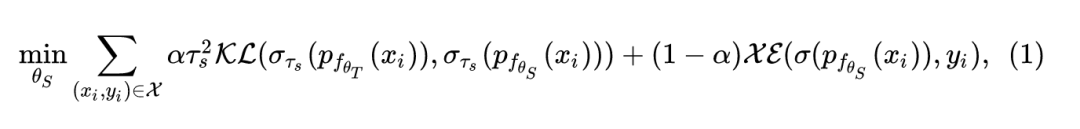
式中,
和
分别代表 Kullback-Leibler 距离 (K-L divergence) 和 Cross-Entropy loss,
代表温度 (temperature)。
Nasty Teacher 的训练目标是努力创建一个特殊的教师网络,其表现与正常的教师网络几乎相同,但是任何学生网络都无法从中提取知识。作者提出了一种简单而有效的算法,称为 "自我破坏知识蒸馏 (Self-Undermining Knowledge Distillation)"。
自我破坏知识蒸馏 (Self-Undermining Knowledge Distillation)
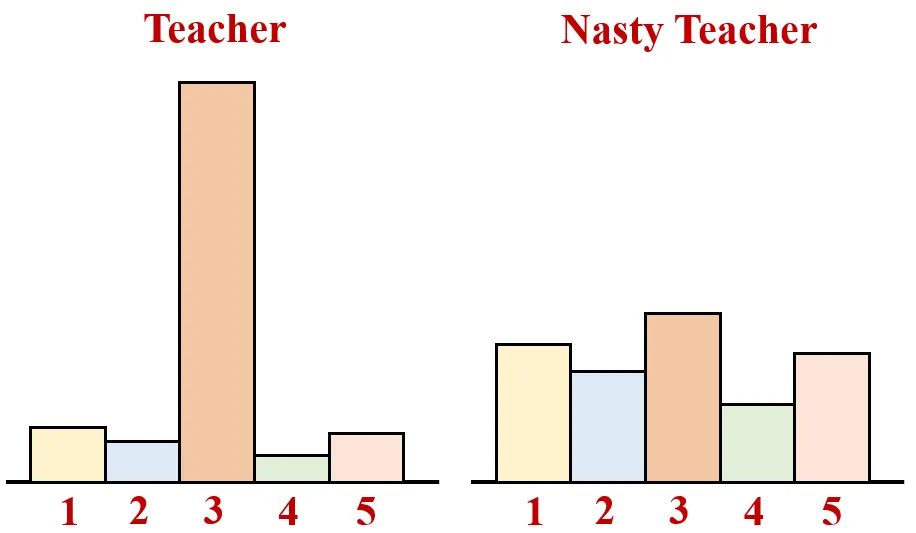
其原理可以通过下图1直观地看到。如图1所示,传统教师模型训练希望教师模型的输出如图1左侧所示,正确的累的概率尽量大,不正确的类别的概率尽量小。自我破坏知识蒸馏,同时保持其正确的类,最大限度地干扰其不正确的类,以便没有有益的信息可以从教师模型中提取出来,如下式所示。
令 和 分别表示 Nasty 教师模型及其对应的 counterpart。自我破坏训练旨在最大限度地扩大 和 Nasty 教师模型之间的 KL 距离:
式中,前一项
就是 Cross-Entropy Loss,旨在维持 Nasty 教师模型的性能;后一项
是希望最大限度地扩大
和 Nasty 教师模型之间的 KL 距离。这样一来,Nasty 教师模型既能够正确地完成分类任务,又不至于输出太 "sharp"。结果如下图1所示,自我破坏教师模型训练的结果如图1右侧所示。Nasty 教师模型这样非常均匀的输出使得很难对其进行有效地蒸馏。
是温度超参数。
对于教师模型对应的 counterpart 的选择,可以直接选择与教师模型相同的架构。至于更新规则, 的参数通常是预先训练好的,在对抗性训练时固定,只更新 的参数。请注意,所选温度 不必与 相同。
实验结果
数据集和模型:
CIFAR-10:教师模型:ResNet-18。学生模型:5-layer plain CNN,ResNetC-20,ResNetC-32
CIFAR-100, Tiny-ImageNet:教师模型:ResNet-18, ResNet-50 and ResNeXt-29。学生模型:MobileNetV2 , ShuffleNetV2,ResNet-18
实验设置:
温度:CIFAR-10: 。CIFAR-100, Tiny-ImageNet: 。
超参数 :CIFAR-10:0.004,CIFAR-100:0.005,Tiny-ImageNet:0.01
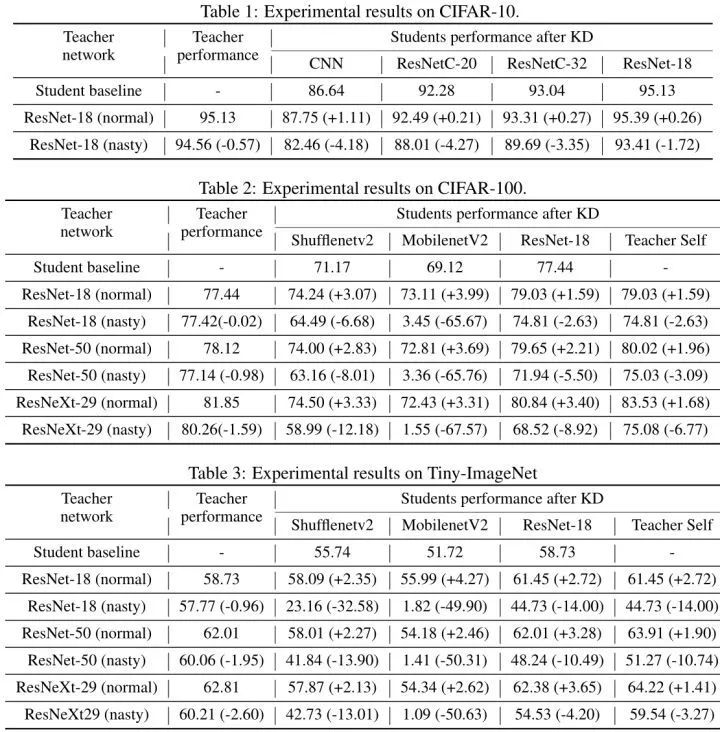
实验结果如上图2所示。上表展示了正常老师模型和 Nasty Teache r在各个数据集上的性能比较,可以发现正常的教师模型和 Nasty Teacher 模型精度相差较少,至多有2%的 Accuracy Drop。而根据 Nasty Teacher 得到的学生模型精度明显比正常老师模型蒸馏出来的精度低。一个正常的教师模型,通过知识蒸馏得到的学生模型比单独训练的学生模型涨点可达4%。但是一个 Nasty 的教师模型,通过知识蒸馏得到的学生模型却不如单独训练的学生模型,准确率下降幅度在1.72% 到 67.57% 不等。MobilenetV2 比 ResNet-18 更容易受到提取有毒知识的毒害,因为轻量级网络打算更多地依赖教师的指导。
可视化结果
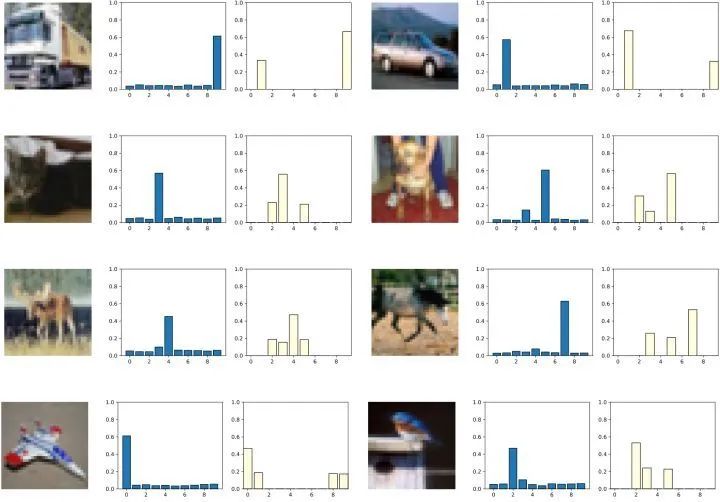
下图3是标准教师模型和 Nasty 教师模型的输出 logits。我们注意到 Nasty 教师模型的 ResNet-18 的输出由多个峰值组成,其中标准教师模型 ResNet-18 持续输出单个峰值。这和图1的结论一致。
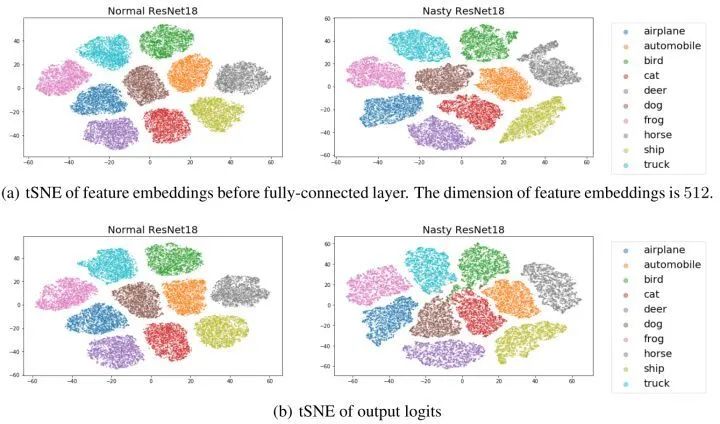
T-SNE 可视化结果
Nasty 教师模型的 ResNet-18 和正常教师模型的 ResNet-18 的特征空间类间距离表现相似,这与我们的目标一致,即 Nasty 教师模型应该表现得与正常教师模型相似,这也说明了为什么Nasty Teacher的精度和正常的差不多。但是输出 logits 有很大的偏移。
对比实验
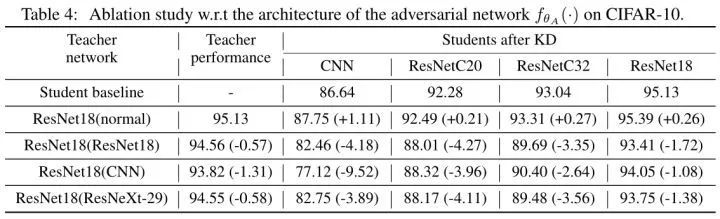
对比实验1:不同教师模型对应的 counterpart 的选择
如下图5所示,展示了不同教师模型对应的 counterpart 模型结构的性能。训练方法对不同结构的 是具有泛化性的。比如我们正常训练教师模型 ResNet-18,并使用这个正常的教师模型进行知识蒸馏的话,学生模型 (CNN,ResNetC20,ResNetC32,ResNet18) 等都会涨点,说明知识蒸馏技术可以偷窃模型。但是若使用 ResNet18 作为 counterpart ,并使用这个 Nasty 的教师模型进行知识蒸馏的话,学生模型 (CNN,ResNetC20,ResNetC32,ResNet18) 等都会掉点。
对比实验2:不同学生模型的选择
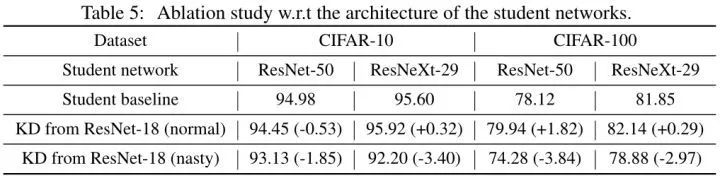
传统知识蒸馏一般是从一个复杂度更高的教师模型蒸馏得到一个复杂度更低的学生模型,但是之前也有工作证明以一个简单网络为 Teacher,复杂网络为 Student 也能够提升复杂网络的性能,这种情况称之为 Reversed KD。所以作者尝试了几种教师和学生模型,如下图6所示。
使用一个简单网络 ResNet-18 或者 Nasty ResNet-18 为 Teacher,使用复杂网络 ResNet-50 或者 ResNeXt-29 为 Student,得到的结果如下。若教师模型是被正常训练得到的,则在大多数情况下,复杂度更低的教师模型蒸馏得到的复杂度更高的学生模型的精度会有提升。但是若教师模型是被 Nasty 训练得到的,学生模型精度会有大幅下降。以上实验现象说明 Nasty Teacher 对于 Reversed KD 也同样有效。
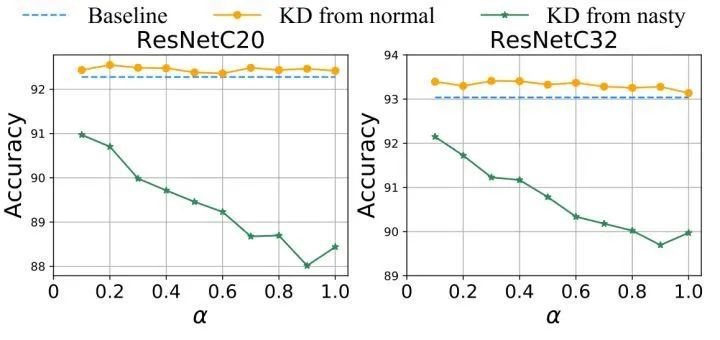
对比实验3:优化目标中不同参数 的选择
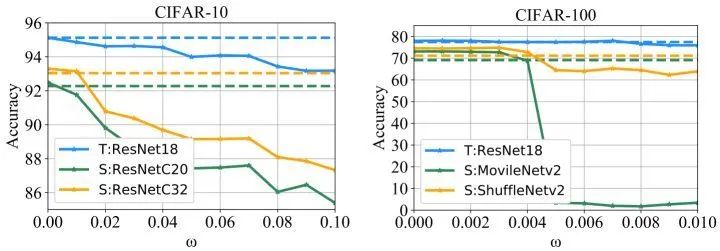
如下图所示是优化目标中式2中不同参数 的选择的影响。教师模型是 ResNet-18,学生模型使用 ResNet-C20 或者 ResNet-C32。实验发现: 越大,则教师模型变得越 toxic,蒸馏得到的学生模型的性能也就越差。但是随之而来的问题是教师模型的性能也会越来越差。
对比实验4:蒸馏时不同参数 的选择
作者对式1中蒸馏目标函数的 做了对比实验。参数 用于平衡知识蒸馏过程中标签和教师模型重要性的占比, 越大,代表知识蒸馏中的教师模型越重要。作者取 分别为0.0到1.0之间的各个值,得到的结果如下:发现当 时学生模型性能最差。作者还观察到,当从 Nasty Teacher 那里提取信息时,一个较小的 值可以帮助学生网络表现得相对更好。然而,较小的 值也使学生较少依赖老师的知识,因此从知识蒸馏本身获益较少。
Data-Free 实验结果
Data-Free KD 方法
是指不通过原始数据就能够完成模型的蒸馏,这一技术使得只根据教师模型,而没有原始训练数据的情况下获得学生模型成为可能,典型的方法是 DAFL 和 DeepInversion。Data-Free KD 方法通过 Reverse Engineering 的方式从黑盒模型中恢复潜在的私人的训练数据,威胁所有者的数据隐私和安全,解读链接如下:
https://zhuanlan.zhihu.com/p/385866470
https://zhuanlan.zhihu.com/p/395992657
https://zhuanlan.zhihu.com/p/453382920
作者使用 DAFL 和 DeepInversion 作为 Baseline 模型,实验设置与原始论文完全一致。Data-Free KD 方法可以根据给定的教师模型,在没有原始训练数据的前提下蒸馏得到学生模型。为了验证本文方法的性能,也应该在根据给定的 Nasty 教师模型,在没有原始训练数据的前提下蒸馏得到学生模型。
DAFL Baseline:
教师模型和学生模型分别设置为 ResNet-34 和 ResNet-18。超参数设置为 。对于 CIFAR-10 数据集,使用正常 ResNet-34 为教师模型,在无数据情况下,学生模型可以获得92.49% Accuracy。但是若使用 Nasty 的 ResNet-34 为教师模型,在无数据情况下,学生模型只可以获得86.15% Accuracy,体现出 Nasty 教师模型对知识产权的保护作用。
DeepInversion Baseline:
基于DeepInversion,作者还在图8中展示了可视化效果,其中图像是通过逆向工程生成的,包括正常 ResNet-34 为教师模型和 Nasty 教师模型。结果显示,从正常的 ResNet-34 生成的图像能够实现高视觉保真度,而从 Nasty 的 ResNet-34 生成的图像由失真的噪声甚至虚假的类别组成。这个可视化展示了 Nasty 教师模型如何防止通过 Inversion 方法进行非法的数据重建。

总结
本文提出了一种保护模型知识产权的方法。居心不良者依然可以通过 KD 的方法完美地 "复制 (replicate)" 一个出新模型,绕过知识产权的保护,达到某种目的。从这个意义来看,知识蒸馏作为一种模型压缩的重要技术,若被被居心不良者不恰当的利用,就可以轻易盗取研究者花很多时间、精力和设备训练好的模型,带来一系列的知识产权问题。本文方法通过训练出一个不易被蒸馏的教师模型 (Undistillable Teacher Model),作者称这种教师模型为 Nasty Teacher。特点是相比常规 Teacher 模型,在正常使用时性能保持不变或者略有下降,而在被知识蒸馏时得到的学生模型的性能很差,使得不法分子无法提供 KD 的手段完美地复制教师模型,从而做到保护模型所有者知识产权的作用,保护模型所有者的隐私。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选



