通用句子编码(USE)的可视化解释

作者:Amit Chaudhary
编译:ronghuaiyang
如何把句子编码成向量,并包含其语义信息,也是NLP中的一个非常基础的任务,USE兼顾了这个任务中的准确性和可用性。
随着像BERT及其变体的transformer模型席卷了NLP研究社区,人们可能很想用最新最好的模型来解决一个问题,然后宣布它已经解决了。然而,在工业上,我们需要考虑计算和内存的限制,甚至可能没有一个专用的GPU来进行推理。
因此,在你的NLP解决问题的工具箱中保持简单和有效的模型是有用的。Cer et. al提出了一种称为“通用句子编码器”的模型。
在这篇文章中,我将解释“Universal Sentence Encoder(通用句子编码器)”背后的核心思想,以及它如何从监督和非监督数据混合语料库中学习固定长度的句子嵌入。
目标
我们想学习一种模型,它可以将一个句子映射到固定长度的向量表示。这个向量对句子的含义进行编码,因此可以用于后续任务,比如搜索类似的文档。

为什么要学习句子嵌入?
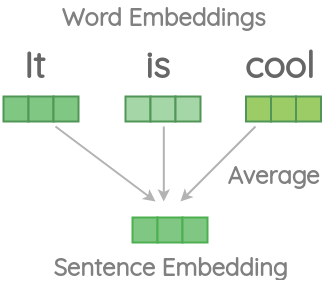
一种简单的句子嵌入方法是将单词在句子中的嵌入量平均,并将平均值作为整个句子的表示。这种方法有一些挑战。
让我们通过使用spacy库的一些代码示例来理解这些挑战。我们首先安装spacy并创建一个nlp对象来加载它们模型的中间版本。
# pip install spacy
# python -m spacy download en_core_web_md
import en_core_web_md
nlp = en_core_web_md.load()
-
挑战1:信息损失
如果我们使用平均单词向量来计算下面给出的文档的余弦相似度,那么即使第二个句子只有一个单词
It,并且与第一个句子的意思不一样,相似度仍然很高。>>> nlp('It is cool').similarity(nlp('It'))
0.8963861908844291 -
挑战2:和顺序没有关系
在这个例子中,我们交换了一个句子中单词的顺序,从而得到一个具有不同意义的句子。但是,平均单词向量得到的相似度是100%。
>>> nlp('this is cool').similarity(nlp('is this cool'))
1.0
我们可以通过手工的特征工程来解决这些挑战,比如跳过停止词,根据单词的TF-IDF分数来给单词加权,在平均时添加bi-grams来引入顺序。
另一种思路是训练一个端到端模型,可以让我们得到句子嵌入:
如果我们可以训练一个神经网络来找出如何最好地组合单词embeddings呢?
通用句子编码(USE)
在较高的层次上,这个想法是设计一个编码器,将任何给定的句子总结为一个512维的句子嵌入。我们用同样的嵌入来解决多个任务,并根据它在这些任务上所犯的错误,更新句子嵌入。由于相同的嵌入必须在多个通用任务上工作,因此它将只捕捉最有信息的特征,并丢弃噪声。直觉上,这将得到一个通用的嵌入,可以普遍迁移到广泛的NLP任务,如相关性,聚类,释义检测和文本分类。
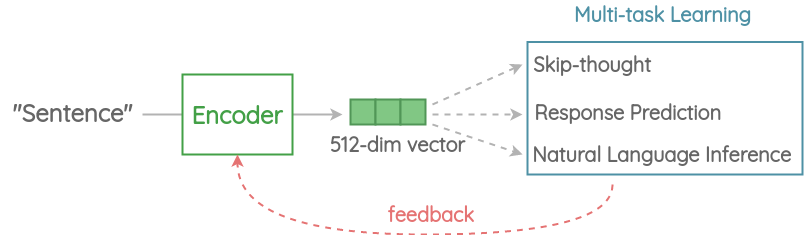
现在让我们深入挖掘通用句子编码器的每个组成部分。
1. Tokenization
首先,使用Penn Treebank(PTB) tokenizer 将句子转换为小写字母并标记为token。
2. Encoder
这个组件将句子编码为固定长度的512维的嵌入。在本文中,提出了两种基于精度与推理速度之间权衡的架构。
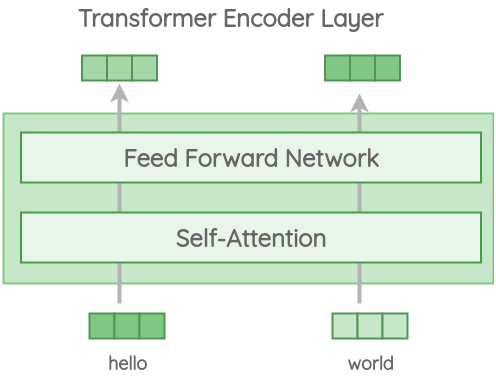
变体1: Transformer Encoder
在这个版本中,我们使用了原始的Transformer架构中的编码器部分。该结构由6层堆叠Transformer层组成。每一层都有一个自注意模块,然后是前馈网络。
自我注意过程在生成每一个单词表示时,都将语序和周围的上下文考虑在内。输出上下文相关的单词嵌入以元素形式添加,然后除以句子长度的平方根,以考虑句子长度的差异。我们得到一个512维的向量作为句子嵌入的输出。
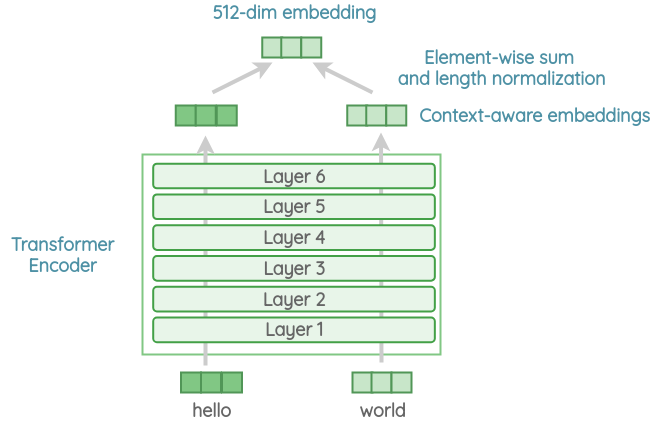
该编码器对下游任务有更好的精度,但由于结构复杂,内存和计算资源的使用更高。同时,计算时间随着句子长度的增加而显著增加,因为自注意力的时间复杂度随着句子长度的增加而增加O(n^2^)。但对于短句,它只是稍微慢一些。
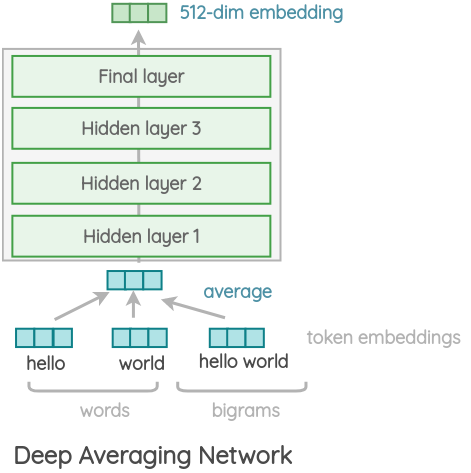
变体2:Deep Averaging Network(DAN)
在这个更简单的变体中,编码器基于Iyyer等人提出的架构。首先,将一个句子中单词的嵌入和bi-grams平均在一起。然后通过4层前馈深度DNN,得到512维句子嵌入输出。单词和bi-grams的嵌入是在训练中学习的。
3. 多任务学习
为了学习句子嵌入,在SNLI语料库上训练出共享参数的编码器,同时进行一系列非监督任务和监督训练。任务如下:
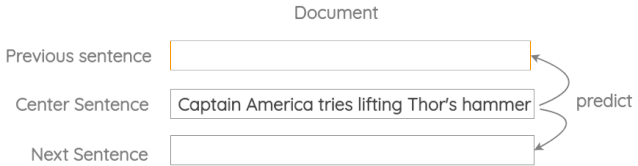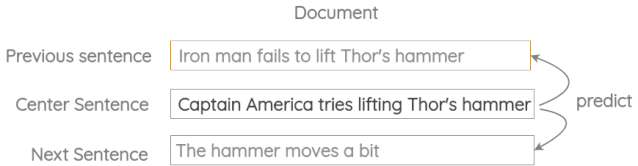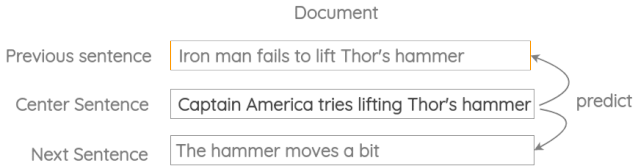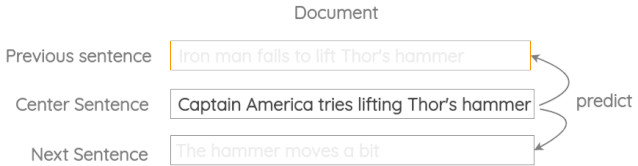
a. Modified Skip-thought
Kiros et al.的原始论文的想法是用当前句预测前一句和下一句。
b. 对话输入-回答预测
在这个任务中,我们需要在一组正确的响应和其他随机抽样的响应中预测给定输入的正确响应。该任务的灵感来自Henderson等人,他们提出了一个可扩展的电子邮件回复预测架构。这也推动了“Inbox by Gmail”的“Smart Reply”功能。作者使用一个从网络问答页面和讨论论坛得到的语料库。
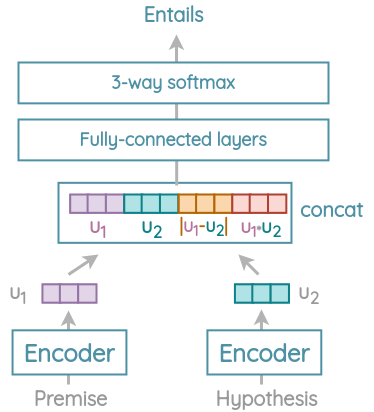
c. 自然语言推理
在这个任务中,我们需要预测一个假设是否与前提相关联,是否与前提相矛盾,或者是否中立。作者使用了来自SNLI语料库的57万对句子来训练使用该任务。
| Premise | Hypothesis | Judgement |
|---|---|---|
| A soccer game with multiple males playing | Some men are playing a sport | entailment |
| I love Marvel movies | I hate Marvel movies | contradiction |
| I love Marvel movies | A ship arrived | neutral |
使用共享的Transformer/DAN编码器对句子进行编码,得到输出的512维的嵌入u1和u2。然后,使用L1距离和点积(角度)把它们拼接起来。将此拼接向量通过全连接层,应用softmax得到隐含类/矛盾类/中性类的概率。
基于SNLI学习句子嵌入的想法似乎是受到了InferSent论文的启发,尽管作者没有引用它。
4. 推理
通过以上任务对模型进行训练后,可以将任意句子映射为固定长度的512维句子嵌入。它可以用于语义搜索、释义检测、聚类、智能回复、文本分类和许多其他NLP任务。
结果
需要注意的是,在USE论文中没有一个章节是关于与其他的句子嵌入方法在标准基准上的比较。这篇论文似乎是从工程学的角度出发,从Gmail和谷歌Books的Inbox等产品中汲取了经验。
实现
预训练的“通用句子编码器”模型可通过Tensorflow Hub获得。你可以使用它来获得嵌入,也可以使用它作为Keras中预先训练好的模型。你可以参考我的文章tutorial on Tensorflow Hub:https://amitness.com/2020/02/tensorflow-hub-fortransfer-learning/来学习如何使用它。
总结
因此,通用语句编码器是一个强大的基线,以尝试比较精确度增益较新方法的计算开销。我个人将其用于语义搜索、检索和文本聚类,它在准确性和推理速度方面提供了良好的平衡。
参考文章
Daniel Cer et al., “Universal Sentence Encoder”
Iyyer et al., “Deep Unordered Composition Rivals Syntactic Methods for Text Classification”
Ryan Kiros et al., “Skip-Thought Vectors”
Matthew Henderson et al., “Efficient Natural Language Response Suggestion for Smart Reply”
Yinfei Yang et al., “Learning Semantic Textual Similarity from Conversations”
Alexis Conneau et al., “Supervised Learning of Universal Sentence Representations from Natural Language Inference Data”

英文原文:https://amitness.com/2020/06/universal-sentence-encoder/#why-learned-sentence-embeddings
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇



