李沐:漫谈在线学习:在线梯度下降

在线凸优化
回顾下上次聊的专家问题,在

")
")


虽然WM的理论在上个世纪完成了[Littlestone 94, Freund 99],将其理论拓展到一般的凸的函数还是在03年由Zinkevich完成的。当时Zinkevich还是CMU的学生,现在在Yahoo! Research。话说Yahoo! Research的learning相当强大,Alex Smola(kernel大佬),John Langford(有个非常著名的blog),这些年在large scale learning上工作很出色。
回到正题。我们提到在online learning中learner遭受的累计损失被记成")


")


在线梯度下降
Zinkevich提出的算法很简单,在时刻
),")
")
")

")

=\arg\min_{u\in\mathcal{H}}\|w-u\|")
先来啰嗦几句其与离线梯度下降的区别。下图是一个区别示意图。在离线的情况下,我们知道所有数据,所以能计算得到整个目标函数的梯度,从而能朝最优解迈出坚实的一步。而在online设定下,我们只根据当前的数据来计算一个梯度,其很可能与真实目标函数的梯度有一定的偏差。我们只是减少
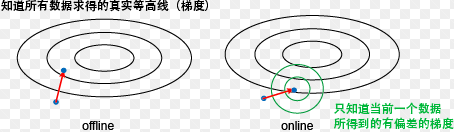
那online的优势在哪里呢?其关键是每走一步只需要看一下当前的一个数据,所以代价很小。而offline的算法每走一个要看下所有数据来算一个真实梯度,所以代价很大。假定有100个数据,offline走10步就到最优,而online要100步才能到。但这样offline需要看1000个数据,而online只要看100个数据,所以还是online代价小。
于是,我们很容易想到,offline的时候能不能每一步只随机抽几个数据点来算一个梯度呢?这样每一步代价就会很少,而且可能总代价会和online一样的少。当然可以!这被称之为Stochastic Gradient Descent,非常高效,下回再谈把。
在这里,+\lambda \Omega(w)")


\le\delta")
")



Regret Bound分析
记投影前的")
")



")

由于
-\ell_t(w^*)\le \langle\nabla_t,w_t-w^*\rangle \le \frac{1}{2\eta_t}\big(\|w_t-w^*\|^2 - \|w_{t+1}-w^*\|^2\big) + \frac{\eta_t}{2}\|\nabla_t\|^2.")
取固定的
\le \frac{1}{2\eta}\|w_1-w^*\|^2+\frac{\eta}{2}\sum_{t=1}^T\|\nabla_t\|^2")




\le LD\sqrt{T}.")
这个bound可以通过设置变动的学习率
浙大90后女黑客在GeekPwn2017上秒破人脸识别系统!

