第四范式提出AutoSTR,自动搜索文字识别网络新架构

作者 | 第四范式
1
修复技术论文综述

论文地址:https://arxiv.org/pdf/2003.06567.pdf
代码地址:https://github.com/AutoML-4Paradigm/AutoSTR
招聘启事:http://www.cse.ust.hk/~qyaoaa/pages/job-ad.pdf
研究组介绍:http://www.cse.ust.hk/~qyaoaa/pages/group.html
2
背景
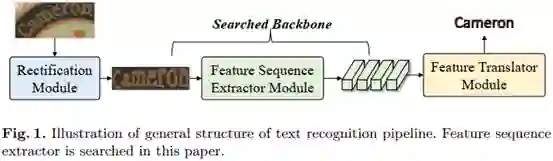 此前
,许多方法通过提高矫正模块的性能,提高了文本识别的准确性。
在特征翻译方面,受语音识别和机器翻译等其他seq-to-seq(序列到序列)任务的启发,基于CTC(Connectionist temporal classification)和Attention方法的翻译模块已进行了深入探索。
相比之下,对于文本识别任务,特征序列抽取器的设计则相对较少。
如何设计一个更好的特征序列抽取器在STR文献中还没有得到很好的讨论。
然而,其对文本识别性能有很大影响。
例如,只需将特征提取器从VggNet替换为ResNet,就可以获得显著的性能提升。
此外,特征序列抽取器承担着沉重的计算和存储负担。
因此,无论是有效性还是效率,特征序列抽取器的体系结构都应该引起业界的重视。
此外,直接迁移其他任务下的网络结构对于STR任务来说可能是局部最优的。
此前
,许多方法通过提高矫正模块的性能,提高了文本识别的准确性。
在特征翻译方面,受语音识别和机器翻译等其他seq-to-seq(序列到序列)任务的启发,基于CTC(Connectionist temporal classification)和Attention方法的翻译模块已进行了深入探索。
相比之下,对于文本识别任务,特征序列抽取器的设计则相对较少。
如何设计一个更好的特征序列抽取器在STR文献中还没有得到很好的讨论。
然而,其对文本识别性能有很大影响。
例如,只需将特征提取器从VggNet替换为ResNet,就可以获得显著的性能提升。
此外,特征序列抽取器承担着沉重的计算和存储负担。
因此,无论是有效性还是效率,特征序列抽取器的体系结构都应该引起业界的重视。
此外,直接迁移其他任务下的网络结构对于STR任务来说可能是局部最优的。
3
本文工作
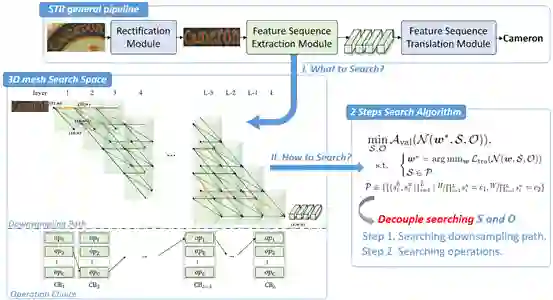
我们发现,对于STR具有重要意义的特征抽取器结构在此前的工作中还没有得到很好的研究。这促使我们设计一个数据相关主干网络来提高文本识别的性能,这也是将NAS引入STR的第一次尝试。
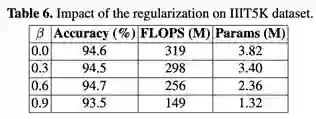
该工作为STR引入了一个特定域的搜索空间,该空间包含下采样路径和操作的选择,并提出了一种新的搜索算法将操作和下采样路径分离,从而在空间中进行有效的搜索。通过在搜索过程中加入一个额外的正则化器,在模型大小与识别精度方面进行了有效的权衡。
该工作对各种基准数据集进行了大量的实验。结果表明,AutoSTR可以发现data-dependent backbones,并以更少的浮点运算和模型参数获得最先进的方法。
(1)搜索目标
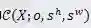 ,以下简称为
,以下简称为
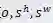 的卷积层。更具体来说,
的卷积层。更具体来说,
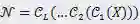 。经过深度卷积网络
。经过深度卷积网络
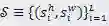 (对于卷积步长)和
(对于卷积步长)和
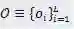 (对于卷积操作)控制。本文用
(对于卷积操作)控制。本文用
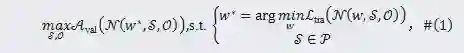
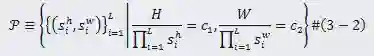
(2)搜索空间
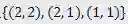 中选择,在整个下采样路径中
中选择,在整个下采样路径中
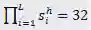 、
、
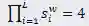 ,最终大小为
,最终大小为
 的输入文本图片被映射为长度
的输入文本图片被映射为长度
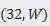 到
到
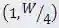 的连通路径表示下采样路径搜索空间中一种结构配置。本文的目标是在这样的3D网格搜索空间中找到一条路径,实现最佳的识别性能。
的连通路径表示下采样路径搜索空间中一种结构配置。本文的目标是在这样的3D网格搜索空间中找到一条路径,实现最佳的识别性能。
(3)搜索算法
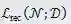 表示卷积网络
表示卷积网络

 、
、
 、
、
 、
、
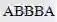 、
、
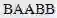 、
、
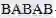 、
、
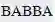 、
、
 、
、
 和
和
 。本文可以在这些典型的路径集合中进行小范围的网格化搜索,以找到最接近
。本文可以在这些典型的路径集合中进行小范围的网格化搜索,以找到最接近

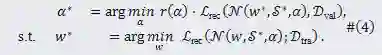
4
实验结果
(1)实验对比
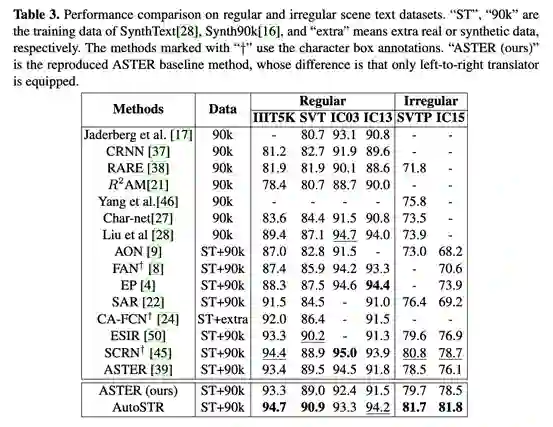
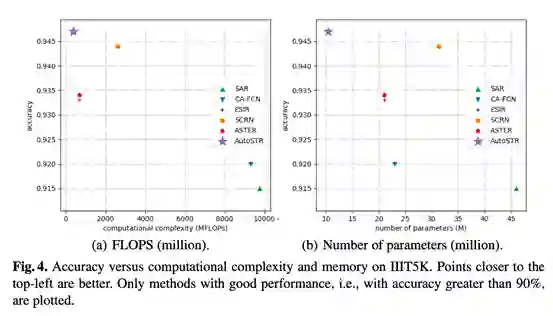
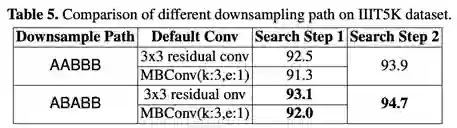
(2)AutoSTR主干网络在性能、准确性、计算方面均有提升
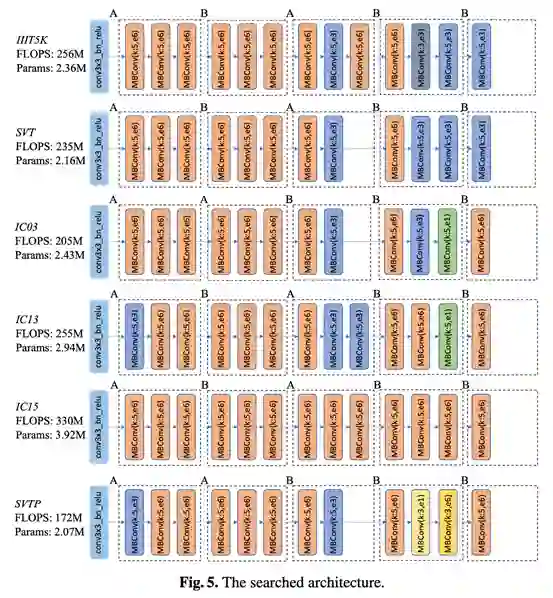
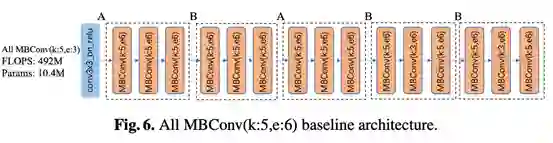

(3)AutoSTR在计算复杂度和准确度上有效权衡
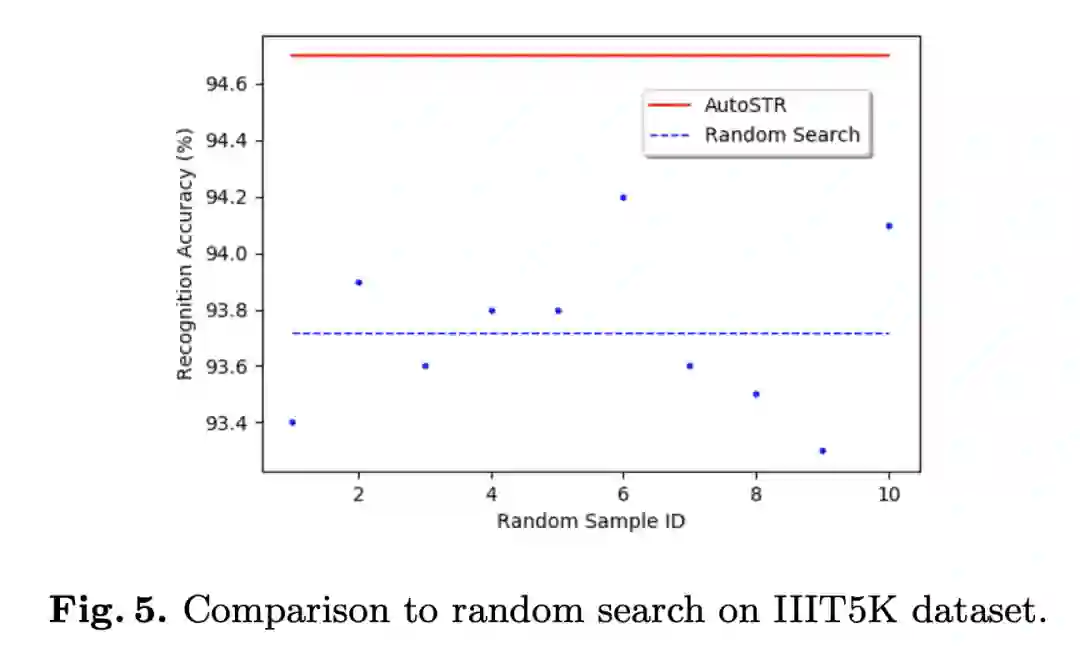

阅读原文,直达“ KDD”小组,了解更多会议信息!
登录查看更多
相关内容
Arxiv
0+阅读 · 2020年10月15日
Arxiv
5+阅读 · 2018年7月16日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2020年10月15日
Arxiv
5+阅读 · 2018年7月16日