用python和Tesseract实现光学字符识别(OCR)

Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
在上周的博客中我们学会了安装光学字符识别程序Tesseract,以及应用Tesseract程序来测试和评估OCR引擎在一小部分示例图像上的性能。
正如结果所示,当从背景中分离出前景文本时,Tesseract的效果最佳。实际上这是非常有挑战性的。因此,我们倾向于训练特定领域的图像分类器和识别器。然而,在我们将OCR应用于我们自己的项目之前,我们需要了解如何通过Python编程语言来实现Tesseract OCR。涉及OCR的示例项目可能包括构建一个移动文档扫描器,您希望从中提取文本信息,或者您正在运行扫描纸质医疗记录的服务,并且希望将信息放入符合HIPA的数据库。
在接下来的部分,我们将学习如何安装Tesseract OCR 和Python,然后编写一个简单的Python脚本来调用这些程序。本教程结束之后,您将能够将图像中的文本转换为Python字符串数据类型。
使用Tesseract-OCR和python
本文分成以下三个部分:
1、学习安装pythesseract软件包,以便我们可以通过Python编程语言访问Tesseract。
2、开发一个简单的Python脚本来加载图像,将图像转换成二进制文件,并将其传递给Tesseract OCR系统。
3、将在一些示例图像上测试OCR,并查看结果。
安装Tesseract + Python组合
我们先来看看pytesseract的安装。要安装pythesseract,我们将利用pip。
如果您正在使用虚拟环境(我强烈建议您分开不同的项目),请使用workon命令,然后紧跟虚拟环境的名称。在本例中,我们的虚拟环境名为cv。

接下来安装pillow和pytesseract

注意:pytesseract不提供真正的Python功能。相反,它只是为tesseract二进制文件提供一个接口。如果您查看GitHub上的源码,您将看到该库只是将图片写入磁盘上的临时文件,然后调用tesseract二进制文件并捕获结果输出。这绝对有点黑客,但是它为我们完成了这项工作。
我们来回顾一下从背景中分割前景文字的代码,然后利用我们刚刚安装的pytesseract
用Tesseract-OCR和python实现OCR
首先创建一个ocr.py文件:
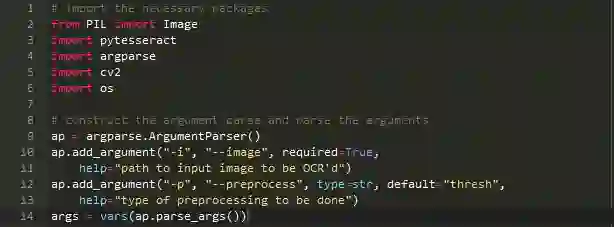
2到6行是导入的包,image类用以从硬盘加载PIL格式的的图像。
9到14行是命令行参数,主要有以下两个:
--image: 传递给OCR系统图片的路径
--preprocess: 预处理方法。此项是可选的,对于本教程,可以接受两个值:thresh或blur。
接下来,我们将加载图像,将其二进制化并将其写入磁盘。
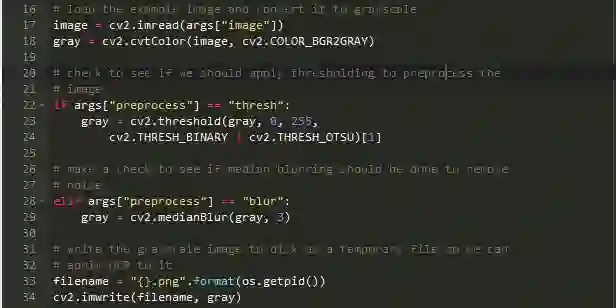
首先, 从磁盘加载图像到内存,然后将其转换为灰度图。接下来,根据我们的命令行参数指定预处理方法,设置阈值。在这里您可以添加更多高级预处理方法(取决于您的OCR的具体应用),不过这超出了本文的范围。
行22-24上的if语句执行阈值,以便从背景分割前景。我们使用cv2.THRESH_BINARY和cv2.THRESH_OTSU标志来执行此操作。有关Otsu方法的详细信息,请参阅官方OpenCV文档中的“Otsu二进制”。
稍后我们将在结果中看到,这种阈值方法可用于读取覆盖在灰色形状上的深色文本,或者,可以应用模糊方法。 28-29行在--preprocess标志设置为blur。应用blur可以帮助减少噪声,使Tesseract更容易正确地识别OCR图像。在预处理图像后,根据Python脚本的进程ID用os.getpi导出临时图像文件名。在使用pytesseract进行OCR之前的最后一步是将预处理的图像(灰色)写入磁盘,并使用上面的文件名保存它
最后我们可以使用Tesseract Python组合将OCR应用于我们的图像:
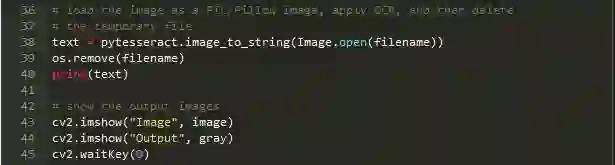
在第38行使用pytesseract.image_to_string将图像的内容转换成我们所需的字符串,文本。请注意,我们传递了对驻留在磁盘上的临时映像文件的引用。接下来是第39行的一些清理,删除临时文件。
第40行是向终端打印文字的地方。在您自己的应用程序中,您可能希望在这里进行一些额外的处理,例如拼写检查OCR错误或自然语言处理,而不是像本教程中一样将其打印到终端。
最后,第43行和第44行在单独的窗口中显示原始图像和预处理图像。第34行的cv2.waitKey(0)表示我们应该等到键盘上的键退出脚本之前被按下。
接下来看下结果。
Tesseract-OCR和python的结果
现在已经创建了ocr.py,是时候将Python 和 Tesseract应用到示例图像上实现OCR了。
在本节中,我们将尝试使用以下过程完成三个示例图像的OCR识别:
1、首先,对每幅图运行Tesseract二进制程序;
2、然后运行ocr.py(在通过Tesseract发送之前执行预处理操作)
3、最后,我们将比较这两种方法的结果,并记录错误的地方。
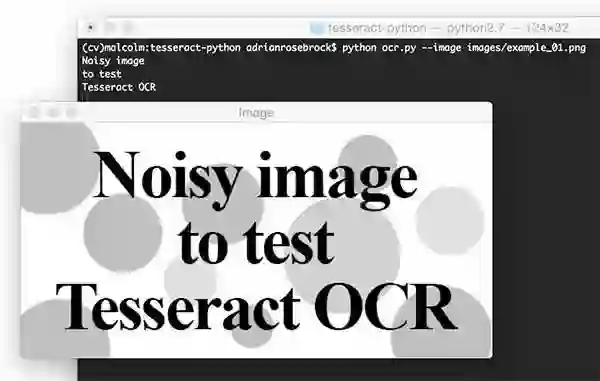
我们的第一个例子是关于“noisy”的图像。此图像包含我们所需的前景黑色文字,背景部分为白色,部分散布有人为生成的圆形斑点。这些斑点作为算法的“干扰物”。

使用上周学到的Tesseract二进制程序,可以将OCR应用于未预先处理的图像:

本例中Tesseract表现良好,没有错误。
现在来确认新创建的脚本ocr.py是否能正常工作

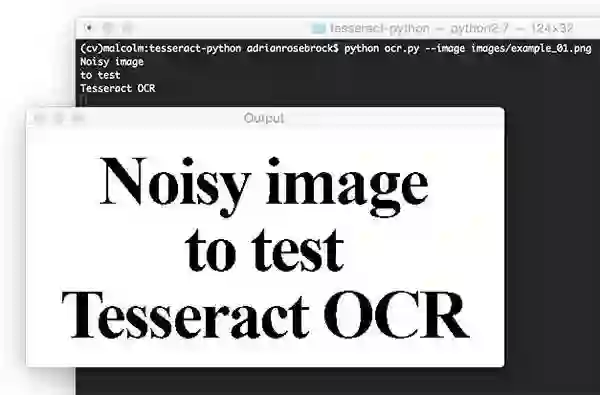
正如在此截图中可以看到的,阈值图像非常清楚,背景已被删除。我们的脚本将图像的内容正确的打印到终端。
接下来测试Tesseract和我们的预处理脚本在杂乱背景中的图像效果。

下面我们可以看到tesseract的输出

不幸的是,Tesseract没有成功地识别出图像中的文本。然而,通过在ocr.py中使用"blur"预处理方法,我们可以获得更好的结果:

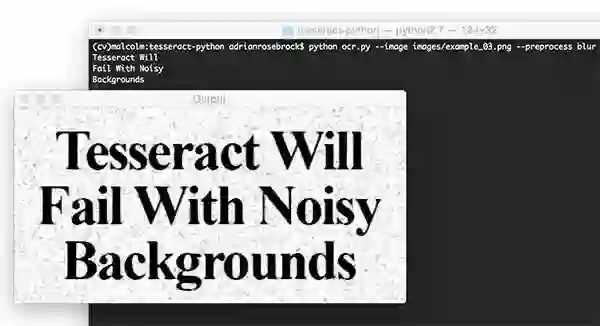
成功!我们的模糊预处理步骤使Tesseract正确地输出我们所需的文本。最后,让我们试试另一个更多文字的图片。

上面的图片是我的书“Practical Python and OpenCV”中的部分截图 ,让我们看看Tesseract处理这个图片的效果
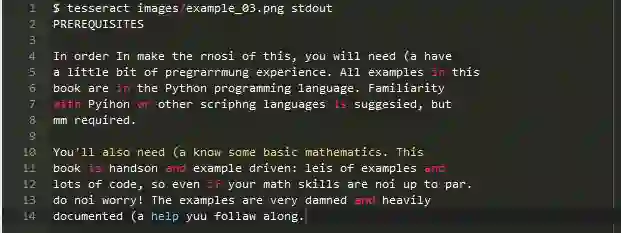
随后用ocr.py测试图像:
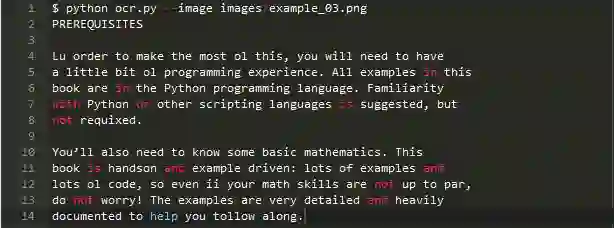
注意两个输出中的拼写错误,不止有“In”,“of”,“required”,“programming”和“follow”。
这两者的输出不一样;然而有趣的是,预处理版本只有8个字错误,而未预处理的图像具有17个字错误(超过两倍的错误)。看来我们的预处理有助于获得干净的背景!Python 和 Tesseract在这里做了一个合理的工作,但是我们再次看到这个库作为一个现成分类器的局限性。
我们可以通过Tesseract获得一个可接受的结果,但是最好的结果来自对真实世界图像中出现的特定字符集训练的自定义分类器。不要让Tesseract OCR的结果阻止您进行下一步的愿望,只需按照实际需求,让Tesseract表现出更加的效果。记住,没有一个真正“现成”的OCR系统,它需要你不断的探索尝试。
注意:如果您的文本需要旋转,您需要进行额外的预处理,就像在之前的博客文章中对纠正文本偏斜所做的那样。没有的话您就可以构建一个不错的移动文档扫描程序,而且OCR系统集成到其中。
总结
在今天的博文中,我们学习了如何使用Python编程语言应用Tesseract OCR引擎。这使我们能够在我们的Python脚本中应用OCR算法。最大的缺点是Tesseract本身的局限性。当背景中的前景文本非常干净时,Tesseract的效果最好。
此外,背景与文字需要尽可能高的分辨率(DPI),并且输入图像中的字符在分离之后不会出现“像素化”。如果文字出现像素化,那么Tesseract将难以正确识别文本,即使在理想条件下拍摄的图像(PDF截图)也会出现同样的问题。
虽然OCR不再是一门新技术,但仍然是计算机视觉文献研究的活跃领域,特别是当将OCR应用于现实世界的无约束图像时。深度学习和卷积神经网络(CNN)可以使我们获得更高的准确性,但是我们还远远没有看到“接近完美”的OCR系统。此外,由于OCR在许多领域具有许多应用,所以一些最佳的OCR算法都是商业化的,需要许可才能应用到自己的项目中。
在将OCR应用于自己的项目时,我的主要建议是首先尝试Tesseract,如果结果不合适就转移到Google Vision API。如果Tesseract和Google Vision API都没有获得合理的准确性,您可能需要重新评估数据集,并决定是否值得培养自己的自定义字符分类器,尤其是你希望检测并识别非常具体的字体。这些特定字体的示例包括信用卡上的数字,支票底部找到的帐户和路由号码,或图形设计中使用的风格化文本。
非常感谢你能分享这个系列的光学字符识别(OCR)博客文章!
英文原文:http://www.pyimagesearch.com/2017/07/10/using-tesseract-ocr-python/
译者:咋家




