一举刷新单、多模型史上最佳成绩,BLENDer 是怎么做到的?
2020 年 11 月 19 日,腾讯微视「BLENDer」模型凭借「81.6,86.4,70.8」的成绩,登上了多模态领域权威榜单 VCR 的榜首。
这项最新成果来自腾讯微视视频理解团队。在这个之前,榜单的纪录保持者是百度、微软、Facebook 等知名机构。
![]()
BLENDer(BimodaL ENcoDer)创造了 VCR 排行榜的单 / 多模型最佳成绩,而提交模型的出发点仅是验证团队的多模态算法。
当人们谈到「腾讯微视」,或许想到的是一款「短视频 App」,它经常出现在微信朋友圈里,同时也是很多人的装机必备软件……
既然是视频业务,就肯定会涉及到内容审核、内容创作等,视觉常识推理(Visual Commonsense Reasoning,VCR)解决的就是让机器「秒懂内涵」的问题。所以,在走近腾讯微视技术团队之前,更应该深入了解一下 VCR 这个任务。
2018 年,来自华盛顿大学和艾伦人工智能研究所的 Rowan Zellers、Yonatan Bisk、Ali Farhadi、Yejin Choi 四位学者联合发起了一项 VCR 任务,该数据集包括 11 万个电影场景中的 29 万个多项式选择题,是当前图像理解和多模态领域层次最深、门槛最高的任务之一。
VCR 任务包括问答 (question answering) 和解释 (rationale) 两个子任务。在问答子任务上,计算机需要结合问题(如图中人物动作、意图等)和与问题相关的图片进行理解,通过四选一进行回答;在解释子任务上,计算机需要在此基础上通过四选一给出第一部分答案的解释。
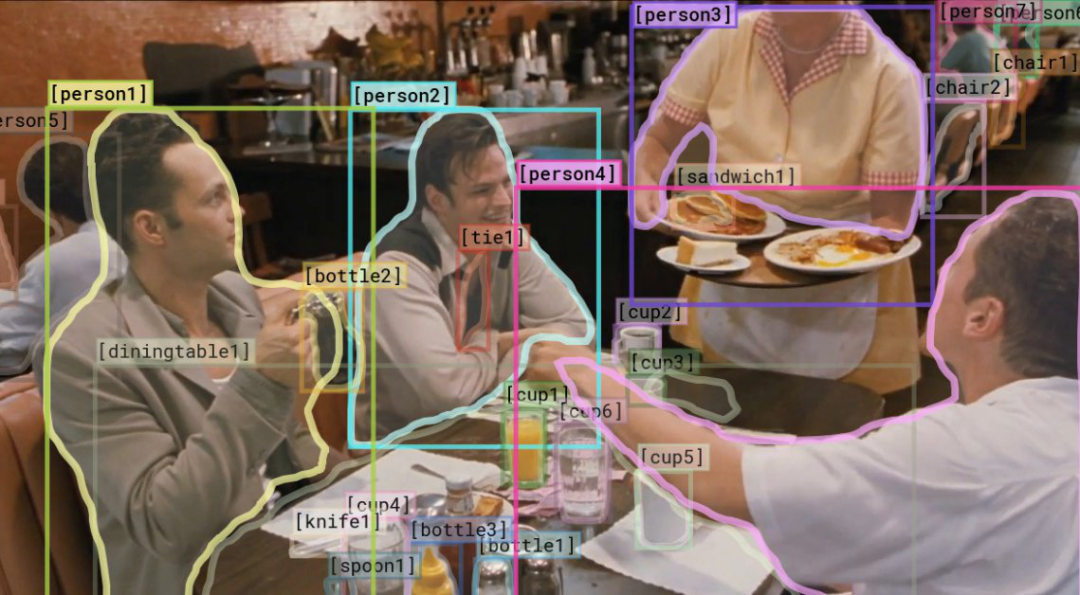
以下图为例,模型需要回答两轮问题。两道题都答对,才能获得最终得分。
第一个问题:为什么 person 4 要指向 person 1?
![]()
正确答案是,person 4 在告诉 person 3,person 1 点了薄饼。(这对于人类来说是很容易解读的)
给出答案后,计算机还需要回答:「为什么这样判断?」比如该示例的第二道问题,正确答案是:
person 3 正在上菜,但他不知道这些食物都是谁点的。
对于人类来说,只需要看一眼图片,就能比较容易地理解出图片的内涵,比如行为、目标、精神状态,甚至人物之间的关系。但这种任务对于机器视觉系统来说是比较困难的,需要更高层次的认知和常识推理能力。
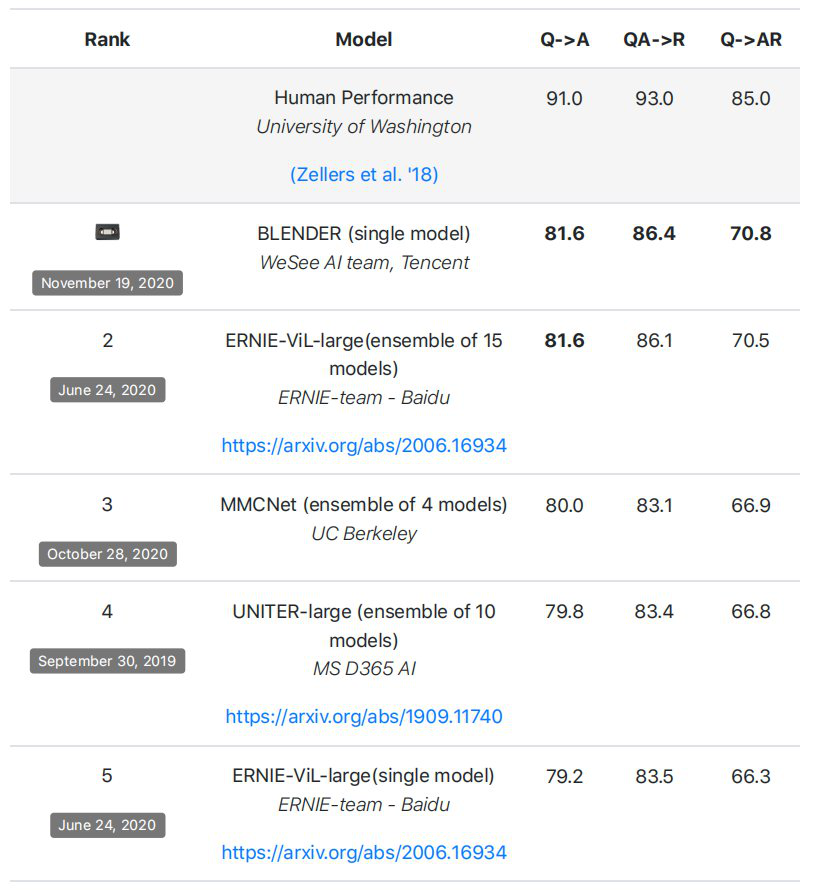
这项高难度任务已经吸引了微软、谷歌、Facebook、百度等多个科技公司的团队参与。此前,这一任务的众多纪录保持者包括 ERNIE-ViL-large(15 模型集合)、UNITER-large(10 模型集合)等。
![]()
但现在最强的是 BLENDer,凭借单模型同时刷新了此前榜单上的单、多模型效果。
![]()
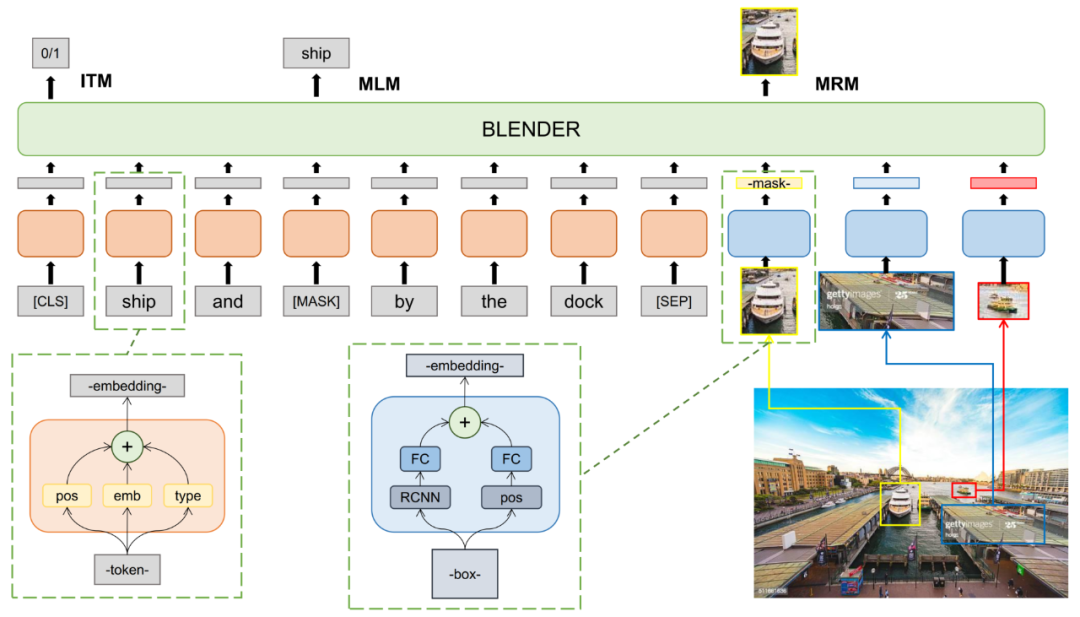
BLENDer 基于当前主流的 one stream 的视觉语言 BERT 模型,该模型的学习过程分为三个阶段:
第一阶段在大约 150w 对图片及其描述的样本上进行预训练,采纳了 Masked Language Modeling (MLM), Masked Region Modeling (MRM)和 Image-Text Matching (ITM)三组预训练任务,如图所示。
第二阶段在 VCR 的训练集上进行进一步的预训练,继续采用第一阶段的 MLM 和 MRM 任务。
第三阶段进行最后的 finetune,输入 VCR 提供的 question, answer 和 rationale 以及 box feature,在[CLS] token 的输出进行 Q->A 和 QA->R 的二分类。以上所有阶段的 box feature 都采用的 BUTD 算法提取的 res-101 feature,除了 flip 没有采用其他增强手段。
相比以往的参赛模型,BLENDer 加入了人物物体关系推理、噪声对抗训练以及针对性更强的 MLM,最终,BLENDer 将三项问答准确率提高到了 81.6, 86.4, 70.8 的水平,单模型表现即超越此前单、多模型效果。具体技术方案细节,团队会在近期开源相关代码、模型和文章。
一直以来,腾讯微视高度关注技术研发,腾讯微视产品也为人工智能技术落地提供了广泛的应用场景。
视频理解团队更是长期深耕多模态语义理解领域,持续进行技术突破和落地,将相关技术应用在海量图像、视频、文本等跨媒体信息的认知推理中。
同时,团队也从业务出发不断探索前沿领域,并将人工智能技术应用到短视频生态中,贯穿内容创作、内容审核以及内容分发的各个环节。
在内容创作环节,腾讯微视将 3D 人脸、人体、GAN 等 AI 技术结合 AR 技术辅助用户进行内容创作,让创作过程更加便捷、有趣和普惠;在视频审核环节,腾讯微视借助图像检测、分类、多模态理解等 AI 技术精准识别视频内容,提升审核效率,使得用户生产的内容最快时间触达消费者,目前腾讯微视内容处理效率已经持平业界领先水平;而在视频分发环节,腾讯微视借助 AI 技术从非结构化的图像、音频、文本数据中提取结构化信息输出,如标签、特征等,支撑分发精准匹配用户。
未来,人工智能将具备更加多元、深度的交流学习能力,而技术的创新和精进将进一步推动 AI 技术在短视频业务中智能交互场景的落地。
![]()
点击「阅读原文」,即可获取相关职位信息。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com