边做边思考,谷歌大脑提出并发RL算法,机械臂抓取速度提高一倍!
选自arXiv
作者:Ted Xiao 等
机器之心编译
机器之心编辑部
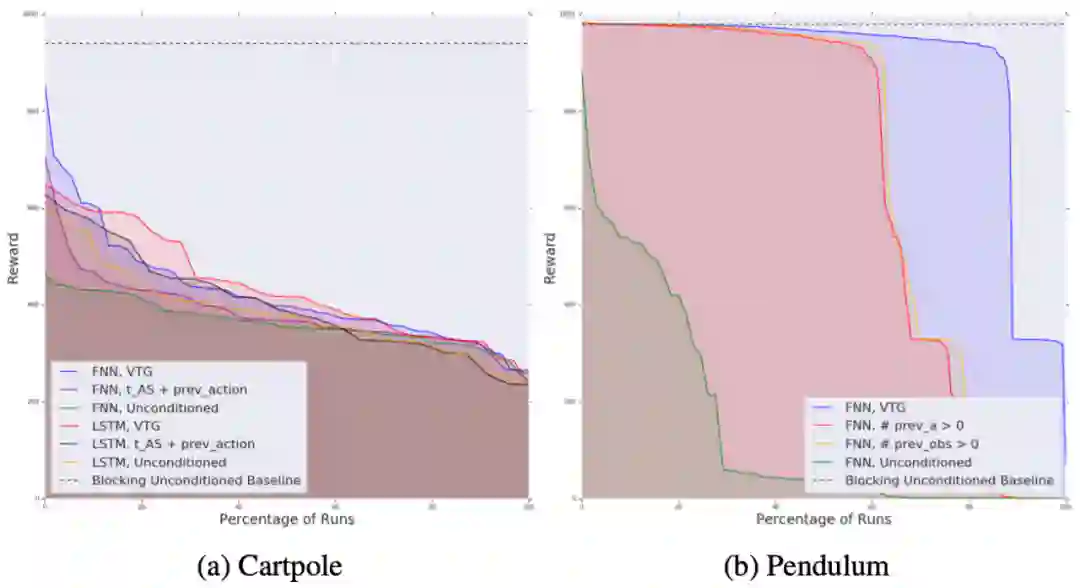
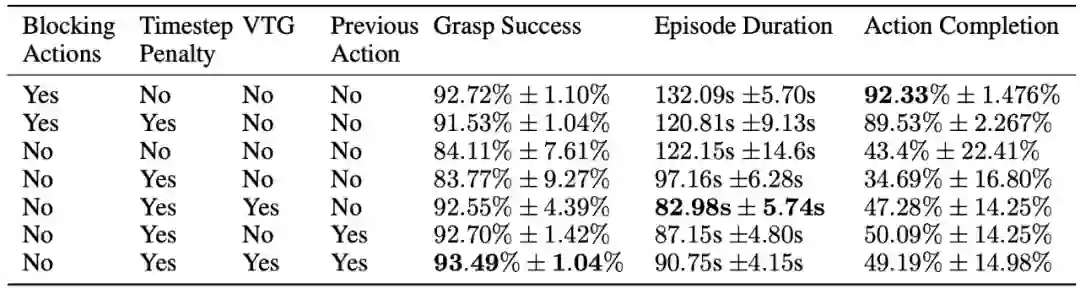
RL 算法通常假设,在获取观测值、计算动作并执行期间环境状态不发生变化。这一假设在仿真环境中很容易实现,然而在真实机器人控制当中并不成立,很可能导致控制策略运行缓慢甚至失效。为缓解以上问题,最近谷歌大脑与 UC 伯克利、X 实验室共同提出一种并发 RL 算法,使机器人能够像人一样「边做边思考」。目前,该论文已被 ICLR 2020 接收。



论文地址:https://arxiv.org/abs/2004.06089
项目网页:https://sites.google.com/view/thinkingwhilemoving
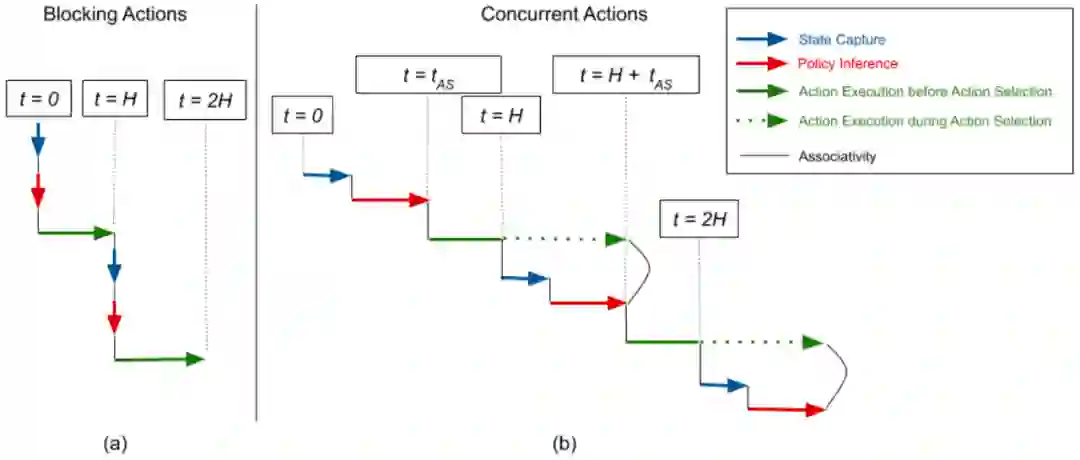

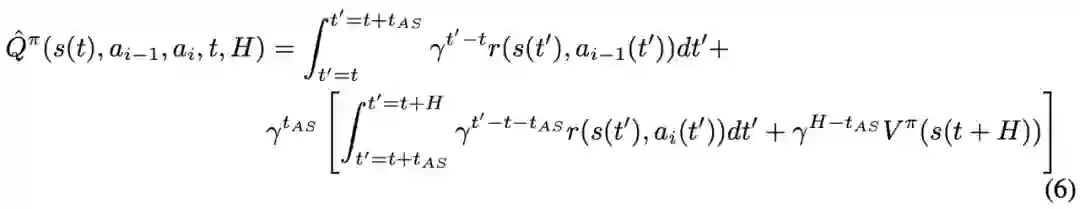
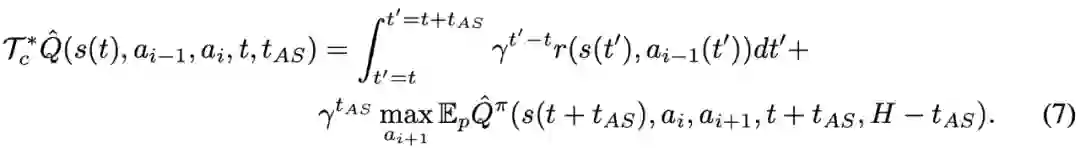
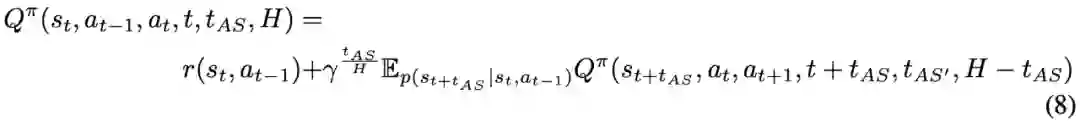
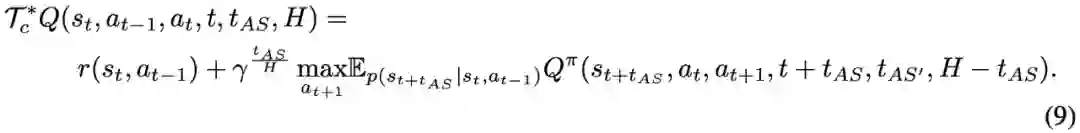


登录查看更多
相关内容






相关VIP内容
相关资讯
相关论文