谷歌大脑QT-Opt算法,机器人探囊取物成功率96%,Jeff Dean大赞
郭一璞 发自 凹非寺
量子位 报道 | 公众号 QbitAI
用于工业生产中的普通机器人,往往只会“给鸡抓鸡,给狗抓狗”,像一个对生活失去了向往的流水线工人,重复着日复一日不用动脑的苦劳力。
但,谷歌大脑昨天发了一个新的算法,让这些穷苦的机械臂开始从事“脑力劳动”:
从一群物品中,抓起需要的东西。
比如从拼好的积木组合里,抓单个积木:

所使用的方法是深度强化学习,将大规模分布式优化和新型拟合深度Q学习算法——QT-Opt相结合,来让机器人从过去的每一次训练中学习,获取经验。
7个葫芦娃的4个月修炼
这次训练的参与“队员”有7名,他们用10个GPU开始训练:

△ 一根藤上7个机器人
每个机器人由一个带双指夹具的机械臂和一个RGB摄像头组成:

为了让机器人尽快get新的探囊取物技能,谷歌大脑的工作人员准备了1000样不同的物品用来训练:

仔细看一眼,其中包括各种形状、大小、材质不一的物体:


训练的过程首先从工作人员手动设计的策略开始,逐步切换到深度强化学习模型。
从论文上发现,原理大概是这样的:
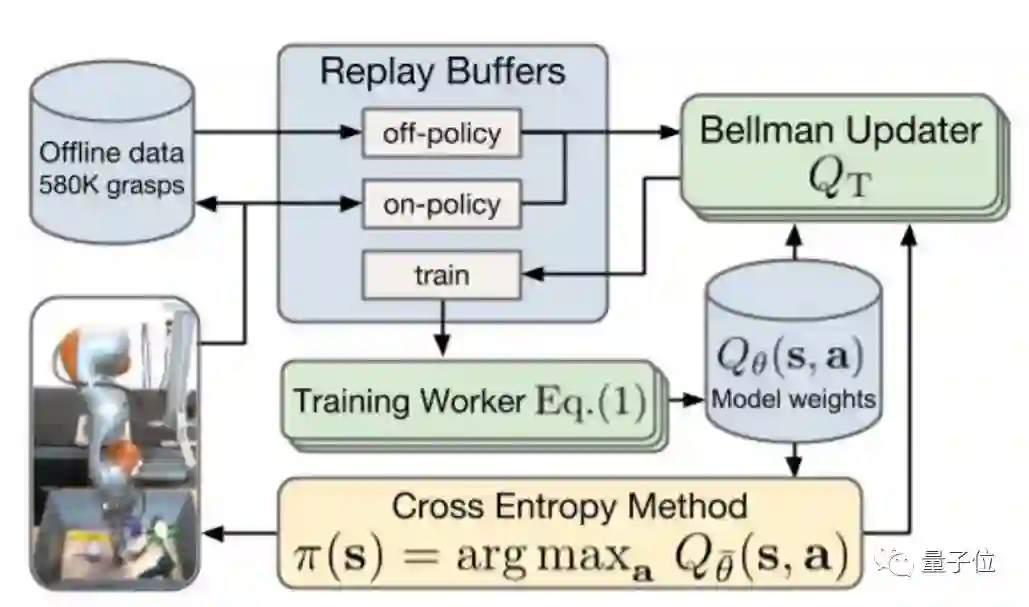
学有所成
经过4个月的训练后,7位机器人迎来了他们的“考试”:成绩不错,在700次试验中,机器人找东西抓起来的成功率高达96%,比此前监督学习方法78%的成功率提升了很多。
Jeff Dean觉得它们棒棒的:
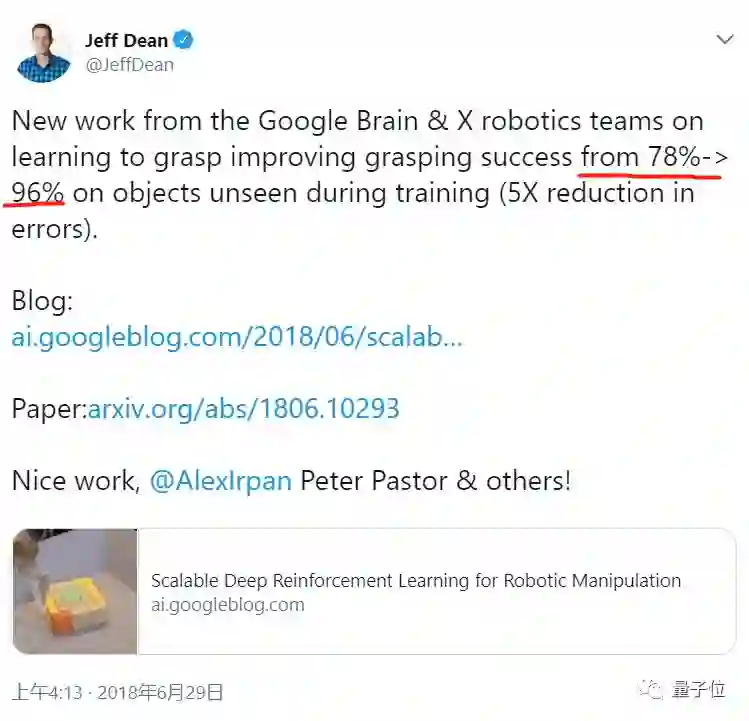
△ 凌晨4点的北京,Jeff老师发推夸奖自家机器人
除了提升准确率之外,经过QT-Opt算法训练过的机器人还主动get了4个新技能:
会破除阻碍
如果目标物体和其他东西连在一起,机器人会主动把它分开然后抓取。
比如前面示范的抓积木,机器人可以把影响自己发力的其他积木推开,再抓自己需要的那块积木。

“筷功”强
如果碰到难抓的东西,比如外形奇特或是外表光滑的物品,机器人会分析角度,重新定位,然后牢牢抓住不松手。

随手抓也要分析挑选
如果机器人一下子抓住了一堆东西,它可以自己选出需要的物品,在举起手臂之前牢牢的抓住它。
抢我的一定抢回来
如果人为的把机器人已经抓起来的物体拿掉,它还会锲而不舍的再抓一遍:

重要的是,以上这些技能都不是人为设置的,均是在训练过程中,机器人自行get到的。
最后,谷歌还提供了一个视频,来讲述7位机器人盆友的心路历程:
△ 《谷歌大脑:机器人进化论》
最后,附论文传送门~
QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation
作者:Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, Sergey Levine
谷歌博客地址:
https://ai.googleblog.com/2018/06/scalable-deep-reinforcement-learning.html
arXiv:
https://arxiv.org/abs/1806.10293
— 完 —
加入社群
量子位AI社群18群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot8入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot8,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态




