东南大学王萌:“神经+符号”学习与多模态知识发现

分享嘉宾:王萌博士 东南大学 助理教授
编辑整理:盛泳潘 重庆大学 助理研究员
出品平台:DataFunTalk
导读:近年来,多模态一词在知识图谱、计算机视觉、机器学习等领域逐渐引起越来越多的关注。从认知科学角度看,个体感知、认知外界多模态信息进而形成知识的过程,通常是多种感官同时对信息进行处理和融合,这也对应着神经网络与符号知识两类人工智能方法。本文将介绍东南大学认知智能研究所在多模态知识发现的最新工作,并介绍神经网络方法与传统的符号知识结合相关研究进展。
具体将围绕以下几部分展开:
引言——两个例子
为什么符号知识很重要
“神经”+“符号”学习
多模态知识发现
首先按照我自己的风格,先举两个和本次分享主题相关的例子。

第1个例子是现在非常火的GPT-3(据相关报道,GPT-3已开源,大家可以用其提供的预训练语料与计算资源所学习到的浅层知识)。这个例子是去年在KR 2020会议上Marcus所举的。“一个人倒了一杯蔓越莓汁,然后漫无目的地用汤勺去搅拌了一些葡萄汁在里面,它看起来不错。你尝试去闻,因为你感冒了,所以闻不到任何味道。因为你非常渴,所以你喝了它。”之后紧跟着一句话,“你现在死了”。对应上图中的黑色字体,是GPT-3自动生成的。
这个例子很有意思,GPT-3从上面这段文本中学习到/认为的新的知识是:葡萄汁是有毒的。实际中,一个零经验的人都可以从网上或自身的历史经验中得到一个结论:蔓越莓/葡萄汁是没有毒的,你之所以闻不到它们是因为你感冒了。从中我们看到,被视为异常强大的GPT-3在这样一个简单的生物医学的推理场景下依然会犯很低级的错误。这还是给我们带来了很多思考:符号知识/知识表示在神经学习系统中是非常重要的。

第2个例子是和多模态相关的,谈到神经和符号,我们知道神经系统在视觉以及一些非结构化的文本任务上取得了长足的进步。这个例子来源于NeurIPS’2020,Facebook公司提出的一个任务,说明在很多时候我们都需要多种模态的数据来共同处理。

Bengio在2020年的ICLR上做了一个keynote,包括国内的唐杰老师、肖仰华老师,都在提系统1到系统2的转变,如上图(左)。上图(右),我们追溯至1986年Marvin Minsky(图灵奖获得者)的《社会心智》这本书,他在这本书中同样提到了人类大脑中的不同认知结构,它们对于外界所传达信息的接收能力与反应方式也是不同的。

对上述内容感兴趣的同学或朋友们,我建议大家可以看看以上三本书。中间这本书是一个诺贝尔经济学奖获得者写的一本关于认知科学理论的书,其中有一些很有意思的题目让你去做,你会发现人脑在处理这些相同或类似的任务时,所产生的差异也是非常明显的。哪怕是非常接近的任务,有的任务你可能需要思考很长的时间才能完成,有的任务你可能在直觉上一下子就能判断出来。我想这可能也对应现实世界中的一些应用场景,可以帮助你找到答案。
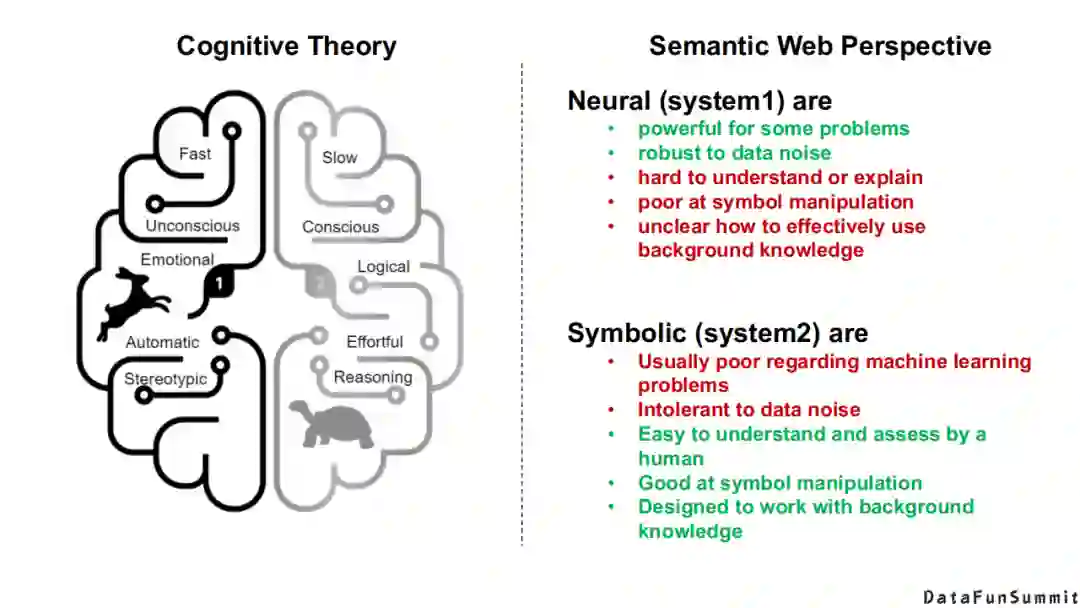
从本质上来讲,Bengio还是从认知学的理论去讨论我们应该用哪一种系统学习的机制。从知识图谱/语义网络的角度来看,毫无疑问,现有的神经系统特别擅长处理特定场景的问题,如车牌识别、语义识别、机器翻译、图像分析等等,并且对于数据噪声的鲁棒性也比较高,这也是神经系统能够识别“千变万化”的手写体数字的优势之所在。但是,它很难去解释或做原子级的操作,以及很难利用传统的背景知识。传统的符号系统很难处理机器学习问题,对于数据噪声的容忍性低,但是它很容易被理解并且被人所评估,以及融入表现背景知识的设计。
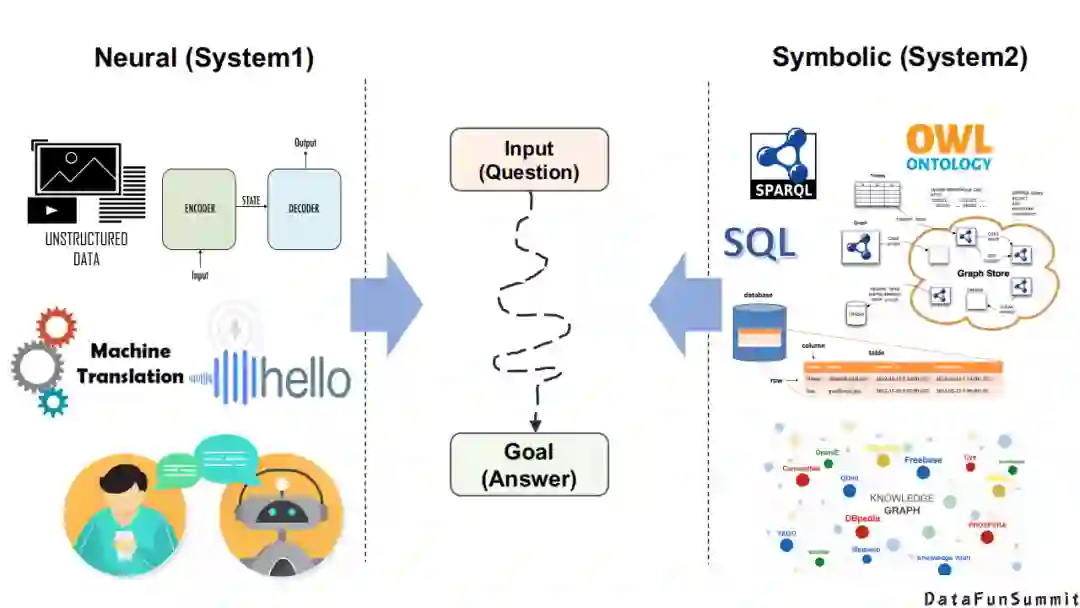
从本质上讲,神经系统和符号系统的目标都是一致的,即输入一个问题(Input(Question)),产生一个答案(Goal(Answer))。区别在于它们擅长处理的数据类型不一样,神经系统可能擅长于处理非结构化的文本、语音、图片等,通常采用的是端到端的方式;符号系统擅长处理数据库以及定义的模式/语义规则/推理规则、图数据库、图谱等等。但是从任务的输入、输出的角度来讲,它们都是一致的。
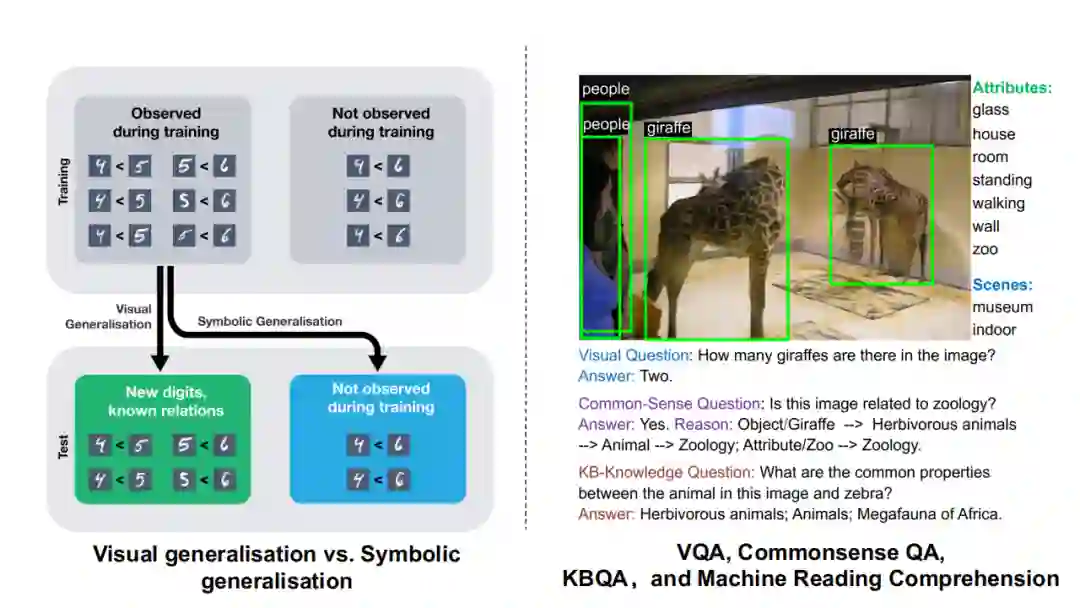
基于此,我们会发现这两种系统各有特点。上图(右)是一个视觉问答(VQA)的例子,针对“图中有几只长颈鹿?”这一问题,可以回答:图中有两只长颈鹿,但是如果问:“长颈鹿和斑马的关系?”这一问题,如果仅通过从大量的样本中来学习,我相信是很难得到“它们都是非洲草原上的草食类动物”这一事实。上图(左)是一个经典的手写体识别例子,如果我们只用神经系统去训练,我们只能判断新样本中4<5,5<6这样从来没有见过的手写体和它们之间的比较。但是对于符号之间的运算,却很难推断出4<6这个运算过程。而对于符号系统而言,它的泛化能力是非常强的,你只需要写一个运算符的传递性规则,便可以得到想要的运算答案。
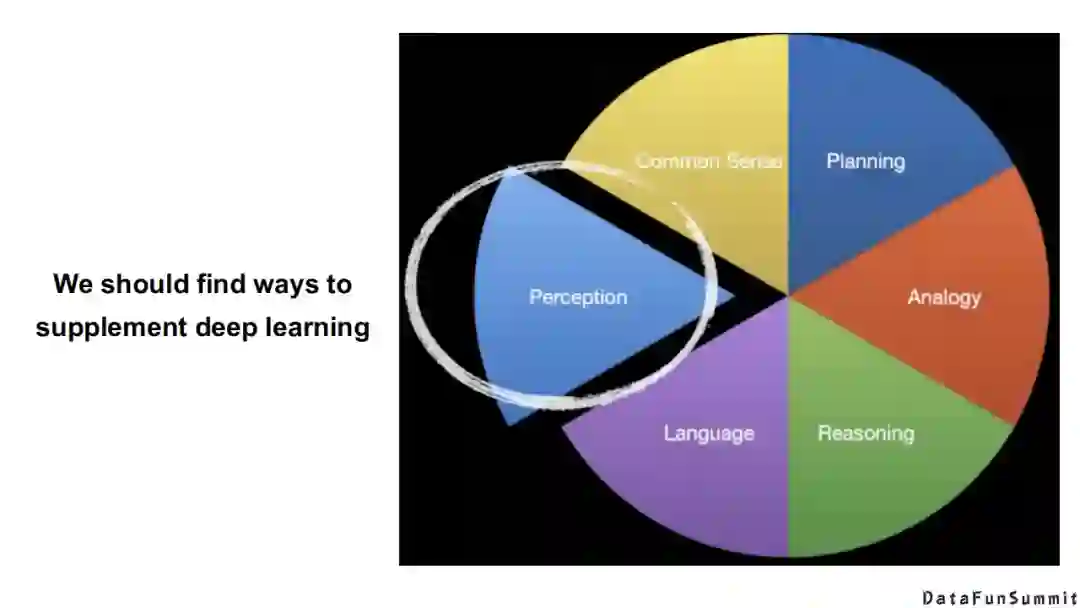
这里提到的“神经”+“符号”并不是说它们两者是对立的。我一直在跟踪前沿的工作,我不是想说“符号系统”有多么的好,而是说我们现在需要的是找到所有可能的方式去补充深度学习目前所出现的问题。这也是我本次分享的核心出发点。从上图中可知,目前现有的神经系统模型主要还是集中在感知或语言方面,而人类的符号知识包含了大量的常识,我们如何能够将它们用在神经系统里面,这方面的研究具有无限的潜力。
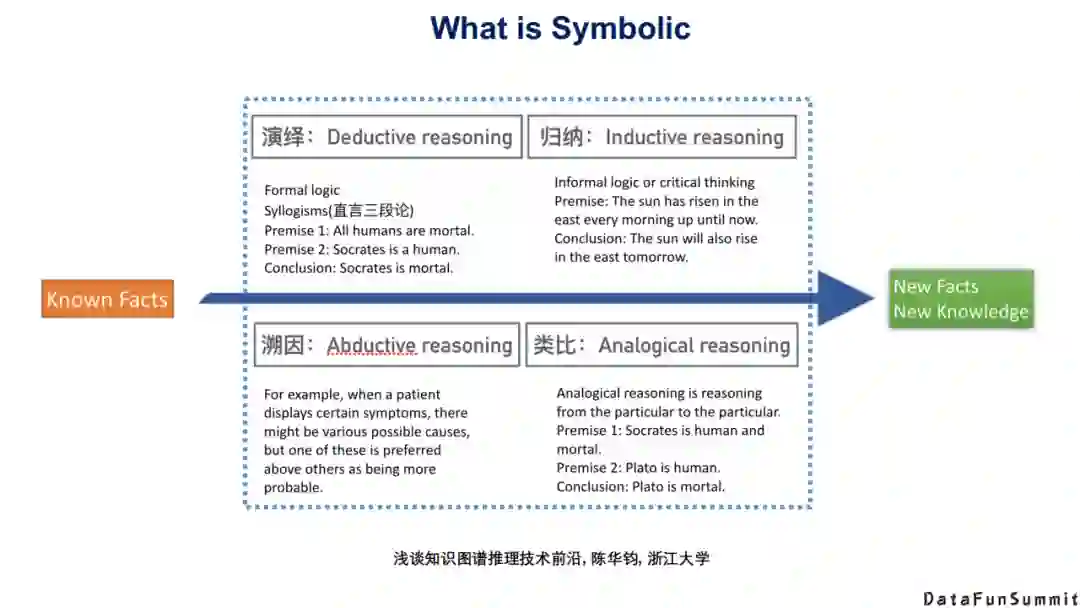
到底什么是符号/符号知识?在浙江大学陈华钧老师的演讲中提到,符号推理的四种类型是:演绎(Deductive reasoning)、归纳(Inductive reasoning)、溯因(Abductive reasoning)、类比(Analogical reasoning)。

G.Marcus在2020年的KR会议上也对符号知识进行了概括,他说符号知识可以分为几类,例如变量、实例,在变量/实例上的操作,以及绑定(binding)。符号知识的泛化能力从何而来?根据Gary F.Marcus这本书中提出的观点,这主要得益于变量的强大之处,也就是说,当我们能在一个符号系统中定义有代表性的变量时,它其实是永无止境的泛化(open-ended generalization)。

哪些知识是可以形式化出来的,像上述提到的变量、实例是可以定义出来的,哪些又是很难去描述的。我们知道,人类知识中其实有很多“本能”信息(innate),例如喜怒哀乐,它从某种程度上来说也是一种知识。但是它们很难用我们的符号体系去概括,这就涉及到一些心理学上的知识。这里我也给大家一个参考,Elizabeth Spelke是哈佛大学一个长期从事计算机科学与心理科学研究的教授,如果你想找到答案,也可以从他的研究中获取到一些资源。

概括而言,符号知识包括:对一类对象的表示(Representationsof objects),一些结构化的代数层级的表示(Structured, algebraicrepresentations),定义在变量上的运算(Operations over variables),一些单词级别的区别(A type-token distinction),对于集合、地点、路径、轨迹、障碍物以及一些持久性质个体的表达能力(A capacity to represent sets, locations, paths, trajectories,obstacles and enduring individuals),一种表示对象属性的方式(A way of representing the affordances of objects),大量的时空信息(Spatiotemporal contiguity/conservation of mass),因果关系(Causality),平均变量(Translational invariance)和成本效益分析能力(Capacity for cost-benefit analysis)。以上可视为对常见的符号知识的系统性的总结。大家可以思考下,根据自己的背景知识,是否可以将上述中的每一类嵌入到神经学习系统中来。

说的再远一些,还有一些很难去定义的符号知识,例如一些习惯的选择(Habitat selection),对危险、恐惧的反应,以及正义(Justice),性别以及一些传统意义上的人类的本能。当然,致力于知识表示的科学家们还一直在探索。我们需要思考现有的知识表示是否还有缺陷,在S.Pinker 1994年出版的一本书中提到这样一句话“人类在解决任何一个现实世界中的问题时,上图中所列出的机制/知识/本能至少要用到其中五种”。这引发了我们的思考,启发我们根据上述知识列表去神经系统中探索还缺乏哪些知识,以及如何更好地引入它们。

符号系统不单单是表示问题,符号知识也是与方法相关的。但现在为止,AI系统已经有很多种类型了,我们在选择知识表达时应紧密联系实际场景,一个核心的问题是,在一个“神经”+“符号”的结合系统中,面向一个给定的问题,或是一个给定的人来选择一个最合适的知识表达,这样最终可以实现两个目的:一是帮助研究者跳出传统的知识图谱/知识表示的思维,进而帮助其获得全新的知识理解(New understanding/ insights);二是让研究者的神经系统更加个性化(Personalizationof system)。
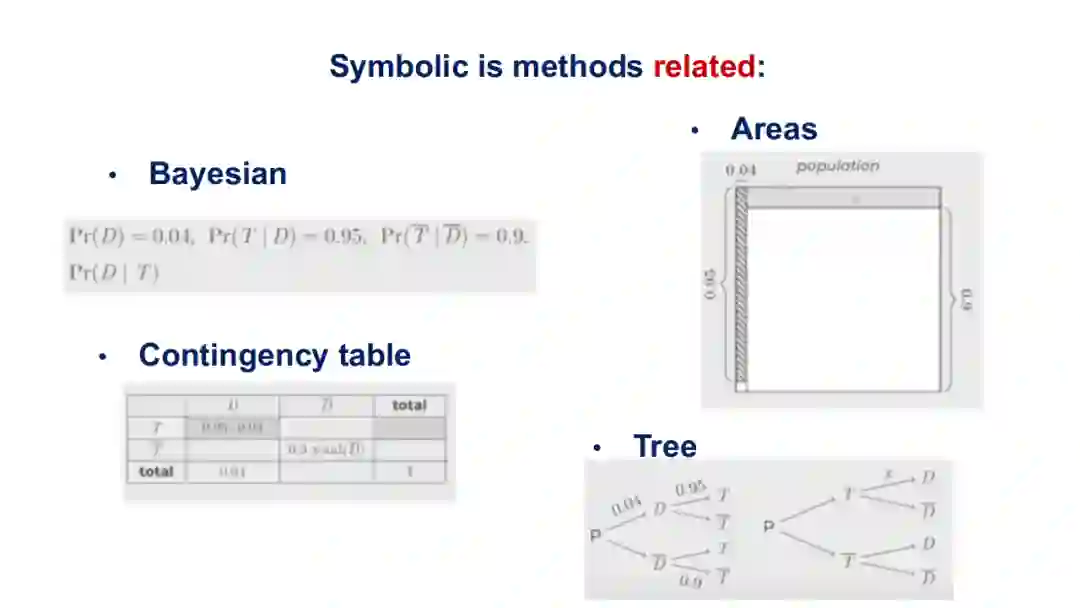
这里举个例子,对于在医疗领域中诊断高血压的问题:“人群中大概有0.04的人,一个患慢性病的老人患高血压的概率为0.95等等”,在上图中,可以分别从贝叶斯公式、代数层级的面积求法、邻接列表、决策树模型的层面给出了这一预测问题的知识表示形式。因此,我们不应该将知识表示固化于三元组,而要看解决问题时所采用的方法。换句话而言,在神经网络中有很多种方法,对于每种方法都应该设计它对应的知识表示。

基于上述设计思想,我们可以充分利用人类世界中的不同知识,这些知识上的不同操作方式,不同个体对于该问题的不同思考,核心的目的是能够根据不同的人,不同的任务选择相应的符号知识与推理规则,最后将知识嵌入到模型之中(With symbols model use, inferences model enable, and knowledge modelencode)。

在知识表示学习的会议ICLR上,每年都会有精彩的分享。在2020年,其中一个令我印象深刻的报告是关于社交符号知识(Social SymbolicKnowledge)的。在很多神经系统中都应考虑到社会知识的作用,这一方面已经有了一些工作,但是对于做“神经”+“符号”的研究者而言,我觉得在社交符号知识方面的研究还是比较空缺的。现在更多的研究还是集中在事实类的知识,例如姚明的身高是多少,美国总统是拜登等。然而在表情识别等情感分析任务中存在大量的社会常识/知识,在ICLR的这个报告中,给我们详细说明了在哪些场景中,我们可以将哪些社会上的浅规则/知识来嵌入到神经学习的系统中。再者,对于知识图谱构建,我们是否能提出一个基于社会常识的知识图谱构建框架,这也是一个值得去探索的方向。
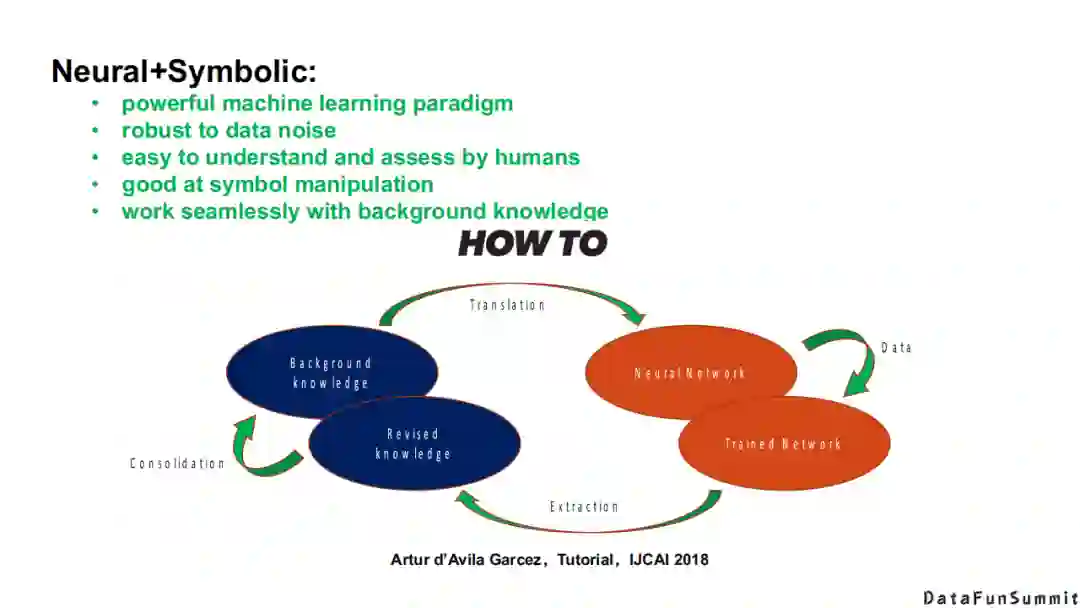
总结一下,我们期望的目标是能够实现一个“神经”+“符号”的系统,在这个系统中,我们可以集成“神经”+“符号”的所有优点,最终来完成既定的任务。在IJCAI 2018的一个辅导报告(tutorial)中,专门介绍了如何来结合“神经”+“符号”,本质上这是一个循环的过程。
下面,我将给大家介绍“神经”+“符号”的学习方法。
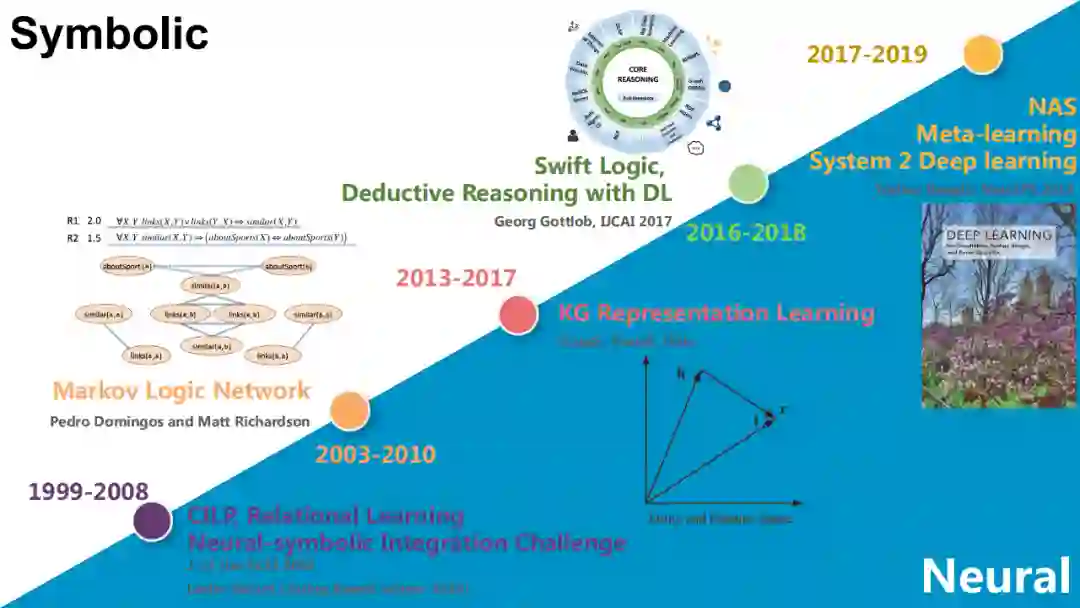
我在IJCAI 2018辅导报告的基础上,进一步总结了“神经”+“符号”学习方法的演化过程。现在还没有任何一个系统敢宣称:我的系统集合了“神经”+“符号”的全部优势,大家更多的是在自己的任务上借鉴或是利用另外一个系统某一个环节的优点,这导致现有的“神经”+“符号”学习都是侧重一方而忽略另一方的。
纵观这一研究的历史,从2010年开始,图灵奖获得者Leslie Valiant就是在做“神经”+“符号”的整合学习,也出版了一系列的、可称为“Relational Learning”的专著;再往上走,就是马尔科夫逻辑网络(MarkovLogic Network),它其实是将一些神经的方法嵌入到传统的马尔科夫网络的构建过程中;2013-2017年,知识图谱表示学习是一个非常火热的方向,至今仍有很多研究者在从事相关研究,其在本质上更侧重于神经系统方法,但同时也引入了很多符号知识;2016-2018年,牛津大学的Georg Gottlob等人提出敏捷逻辑(Swift Logic)的相关概念,在深度学习框架下嵌入了很多可推理的组件(DeductiveReasoning with DL);Yoshua Bengio所倡导的Deep Learning 2,以及我所介绍的多模态知识图谱都属于这个领域。
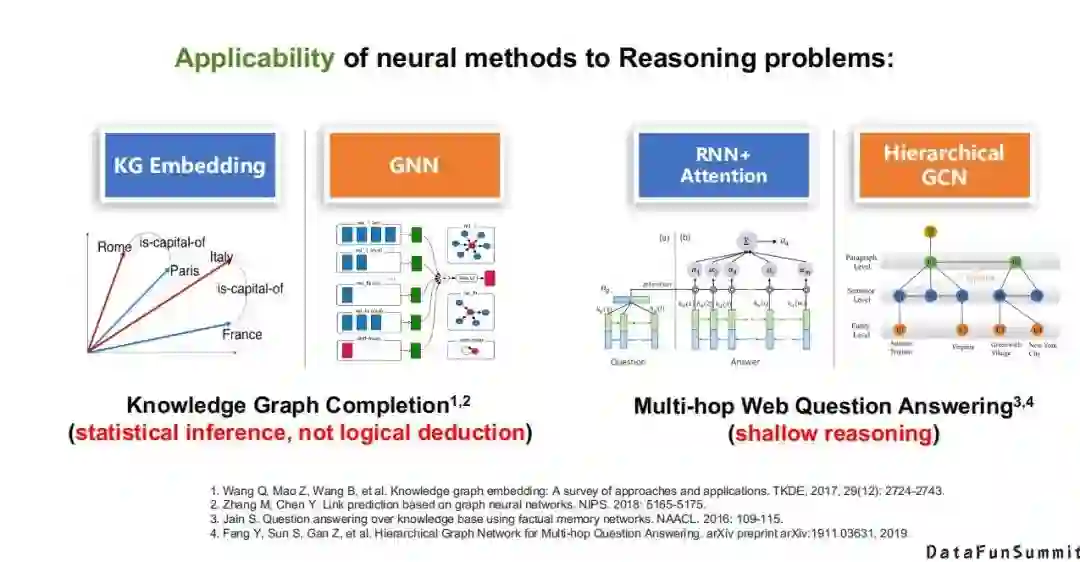
详细来说,第一类将神经系统直接应用于推理任务中的方法就是表示学习,它其实是在用神经的方法解决浅层的关系预测问题(在符号系统中,它们本质就是简单的推理问题),但是我们知道,在知识图谱表示学习中,基本上全部都是用神经网络或统计学习的方法去解决这个任务。还有现在流行的图神经网络,如GCN,GNN等,它们都是在用神经的方法去解决浅层的推理问题。但是我想说的是,这里的推理更多侧重的是统计上的推理,而不是逻辑上的演绎推理。所以这里值得我们做更深层的探讨,是否可以让神经系统去做更高级别的推理。
再比如多跳问答,相比而言,单跳问答是一个复杂的推理或复杂的问题,然而在传统的符号知识领域中,它依然是一个浅层的推理。在多跳问答中,常使用循环神经网络+注意力机制(RNN+Attention)或层次图卷积网络(Hierarchical GCN)来解决这一问题。
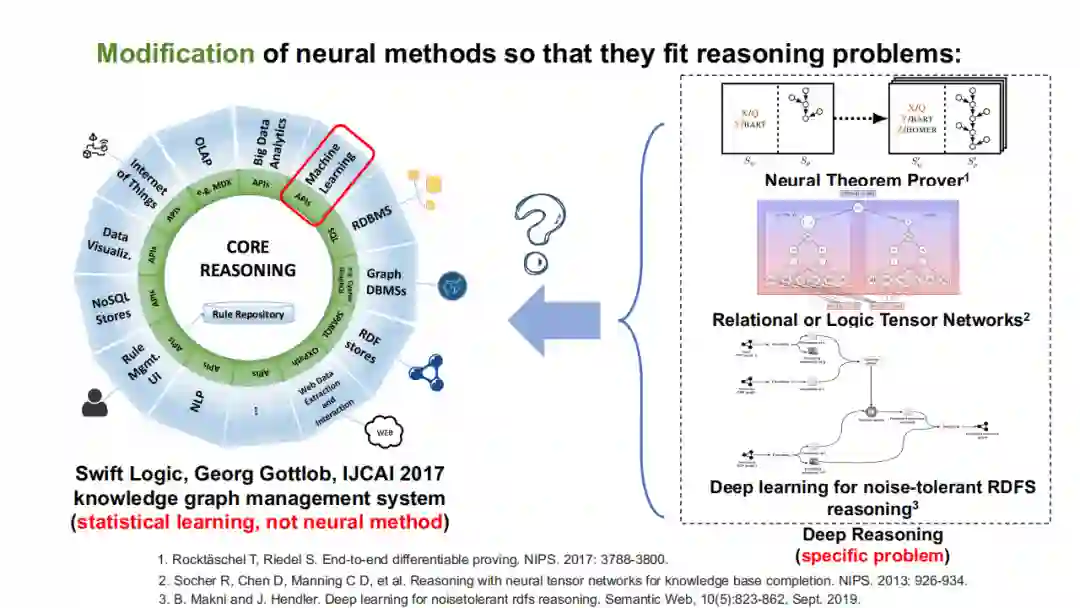
还有一种思路是通过改进神经网络方法,使其能够更好地嵌入到推理问题中。上文中提到的敏捷逻辑(Swift logic),逻辑张量网络(Logic Tensor Network),以及错误容忍的RDF推理(noise-tolerant RDF reasoning)。这些工作极具代表性,它们并不是直接将神经网络与符号相互分离,而是尝试在某些环节,如数据不完整性、张量网络的规则学习过程中引入一些神经的方法,但是在本质上它们还是符号推理系统。
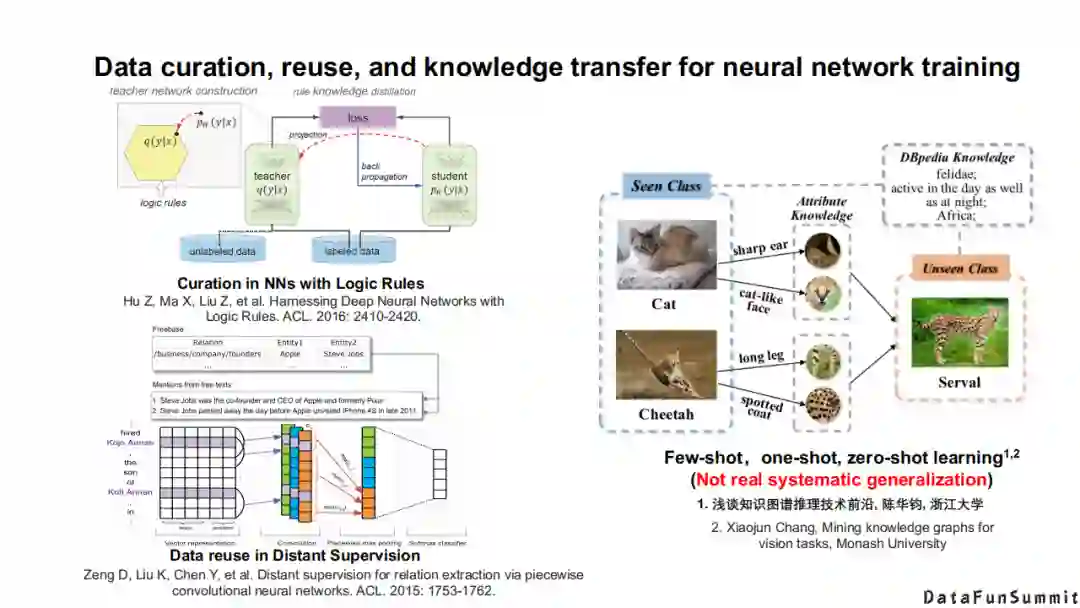
还有一类方法主要还是在做神经系统面临的问题,主要是通过引入符号知识来提升神经网络的效果。其中具有代表性的问题包括:信息编审问题,如知识蒸馏(有老师网络和学生网络的过程,在这些过程中就可以嵌入一些逻辑的规则),远程监督(在自然语言处理的过程中将知识图谱作为监督信息,并且在这其中去思考降噪的问题)。在计算机视觉领域,本质上还是在用符号知识的迁移去解决一些小样本、零样本的问题。
在NLP场景中嵌入知识的三种常见方法:

第一个是韩先培老师组的一个工作,他们将WordNet、Wikipedia、脚本知识(script knowledge)、相关性(relatedness)这些统称为符号知识。第一步是在一个自然语言任务中(如故事结尾预测任务)找出相关的规则或推断,然后去学习是否满足特定规则的得分函数,最后通过注意力机制去学习所有得分函数的聚合,得以对句子进行推断或故事结尾的预测(请见《Reasoning with Heterogeneous Knowledge for Commonsense MachineComprehension》一文)。这里总结一下:这类方法先去发现一些规则,然后从损失函数的级别去判断这些规则是否都有效,最后结合注意力机制进行选择。
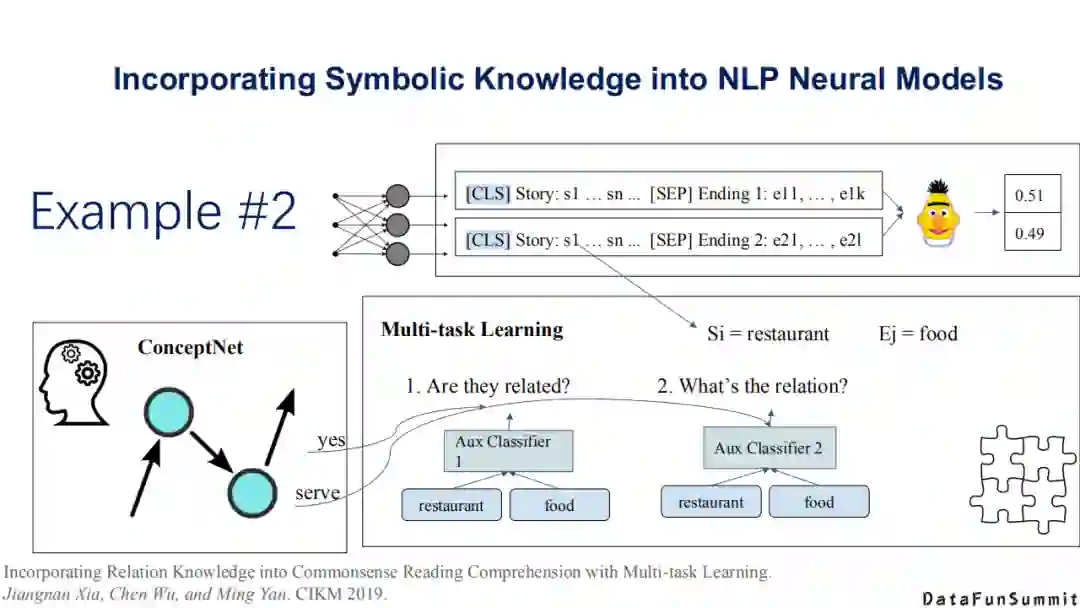
第二类方法是将问题抽象为多任务学习(multi-tasklearning)的任务(请见《Incorporating Relation Knowledge intoCommonsense Reading Comprehension with Multi-task Learning》一文)。这篇文章的最大贡献在于:作者提出了一个概念网络(ConceptNet)。作者认为在整合多类型的知识时会有多个整合的损失函数(lossfunction),因此提出了一个全新的符号知识,称为ConceptNet,最后将其抽象为一个多任务学习的过程。
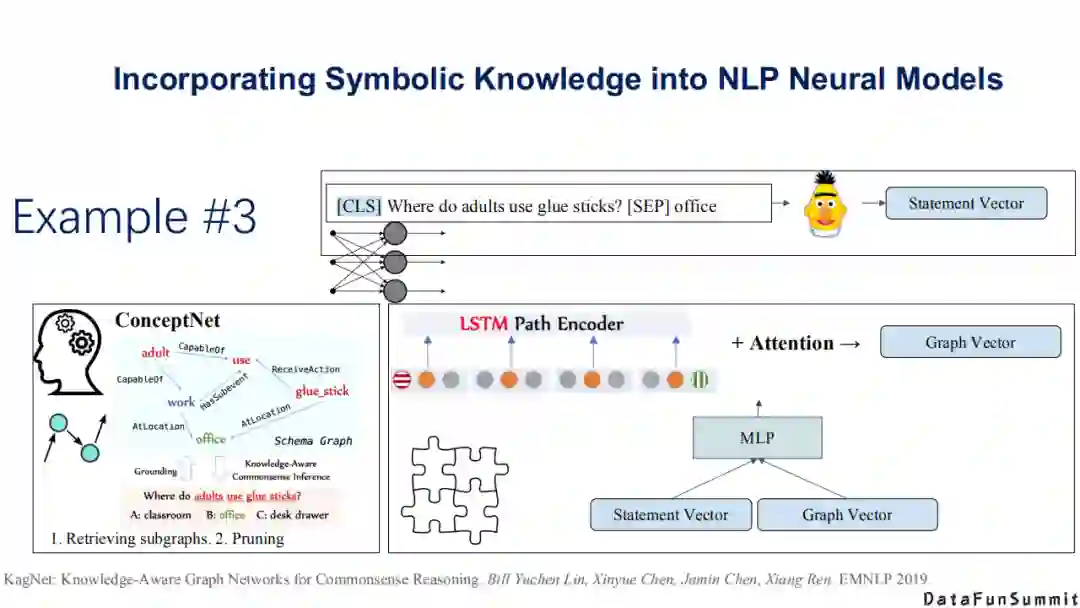
第三个工作也比较有代表性(请见《Knowledge-AwareGraph Networks for Commonsense Reasoning》一文),它类似于自监督学习的过程,并结合最近流行的图神经网络(GNN)来做常识知识推理。上述三类方法是目前做的比较好的,说明如何在神经系统中嵌入符号知识的方法。
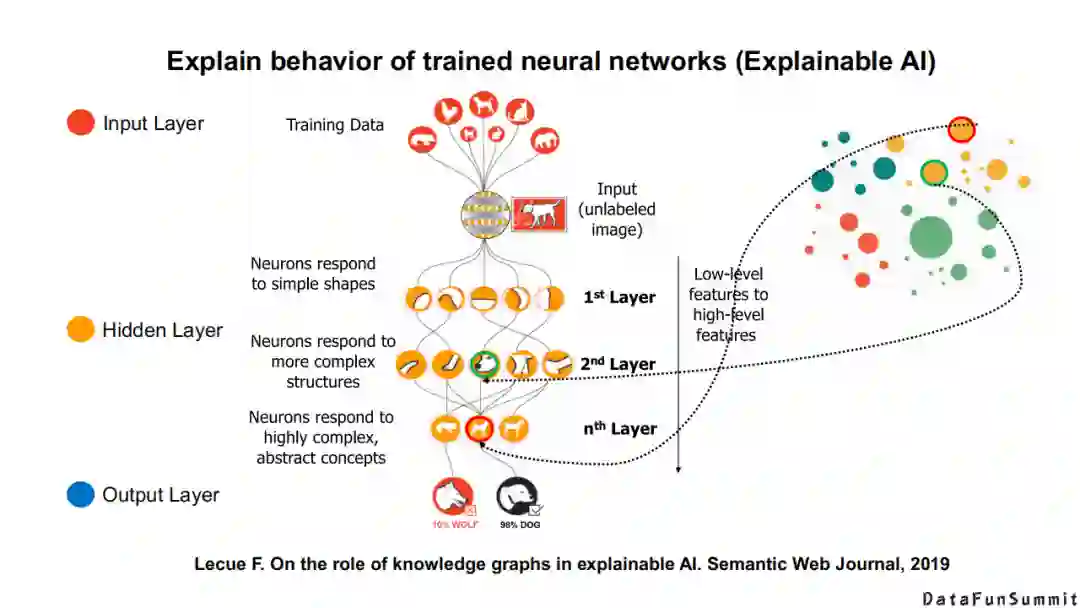
此外,符号知识还能帮助我们更好地解释神经网络的输出结果,以及提供更好的可解释性。这些都是“神经”+“符号”学习的特点。
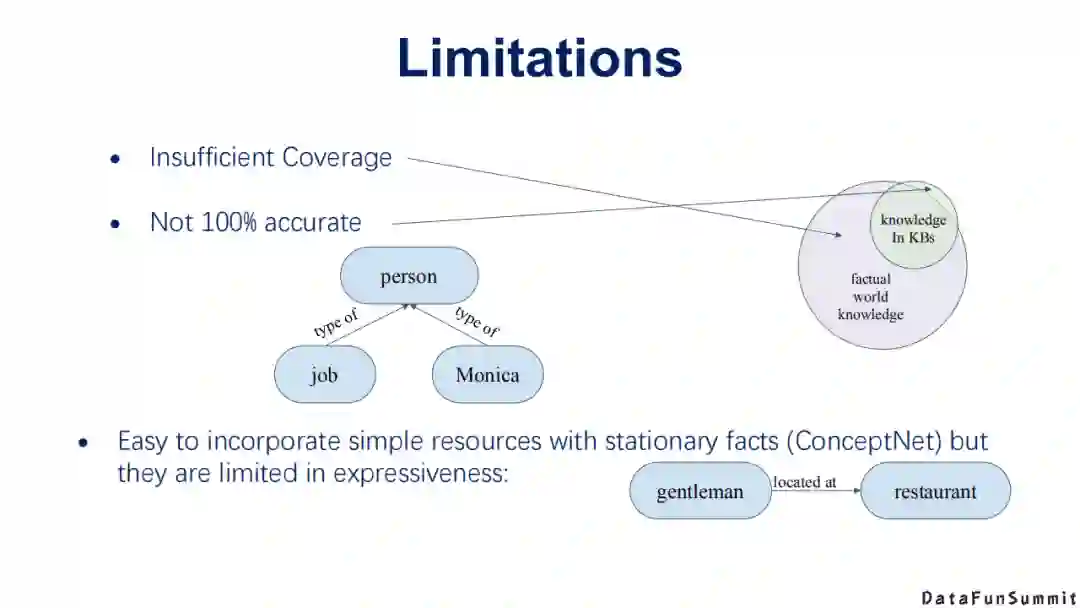
现有的“神经”+“符号”网络也存在一些缺陷:
我们现在所定义或拥有的知识是不完整的,即我们嵌入到模型中的实际上是很缺失的知识。我们真实的世界往往服从开放世界假设,那么我们会面临嵌入的知识是不存在、不正确,还是因为构建过程而导致的缺失问题。
嵌入的知识也不一定是百分之百正确的。
我们可以嵌入一些简单的资源,但是这些资源的表达能力是比较弱的,例如其依然受限于三元组形式的表达能力。
“神经”+“符号”学习也是未来多模态知识发现中的一个探索。
1. 多模态知识图谱
在今年的NLPCC上我已经对多模态知识图谱做过相应的介绍,下面我做一些简单的回顾。
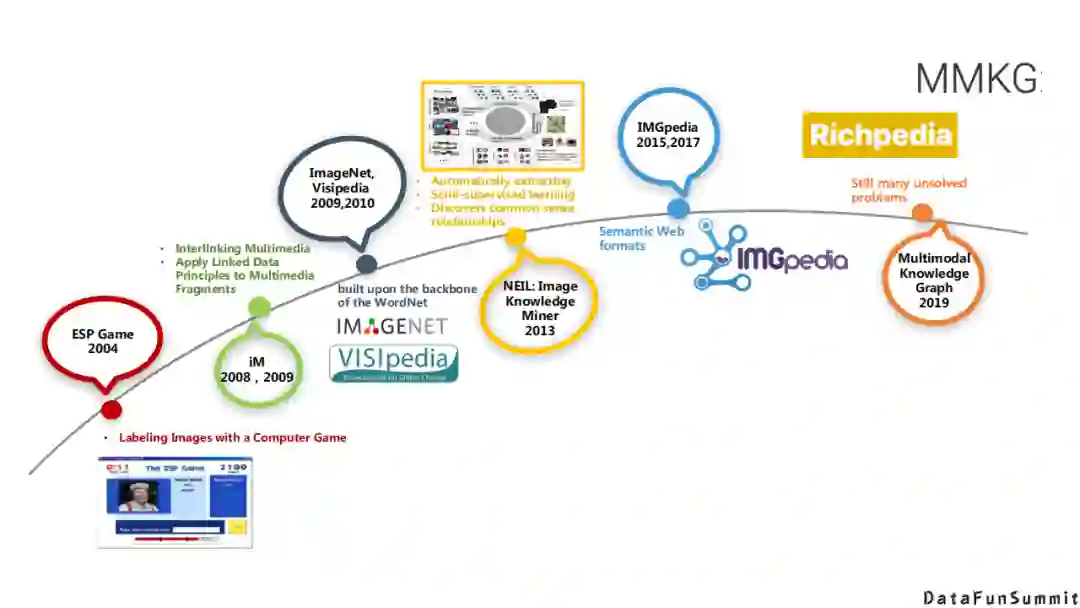
首先多模态知识发现与多模态知识图谱不是一个新的问题,从2004到2019年,在每一个阶段,研究者都有不同的定义。
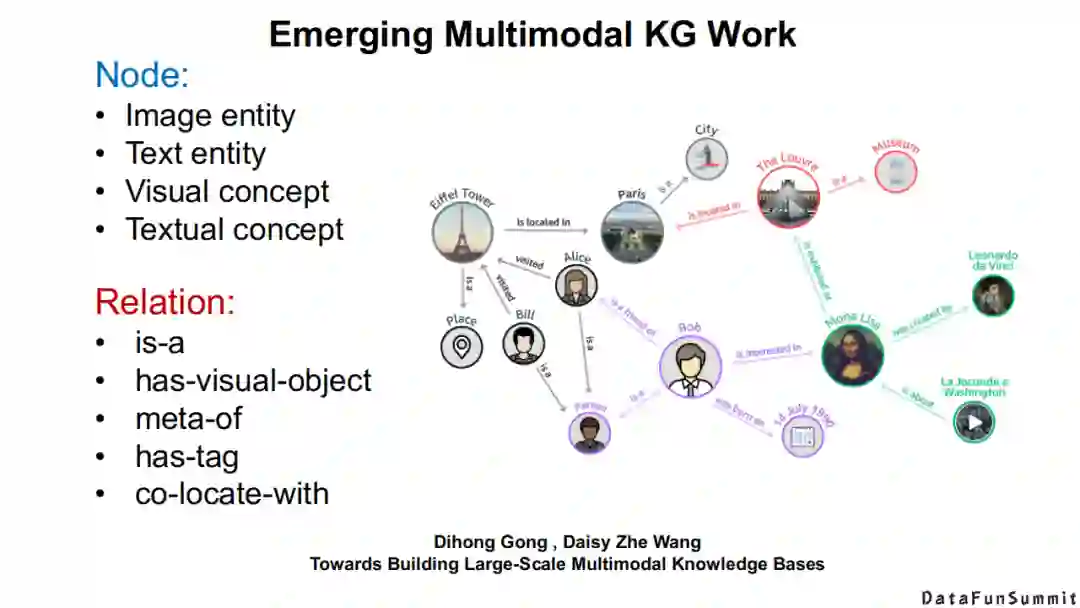
其中具有代表性的工作包括,Heng Ji等老师率先提出了到底什么是多模态知识和多模态知识图谱。他们对多模态知识图谱的节点和关系给出了自己的定义。
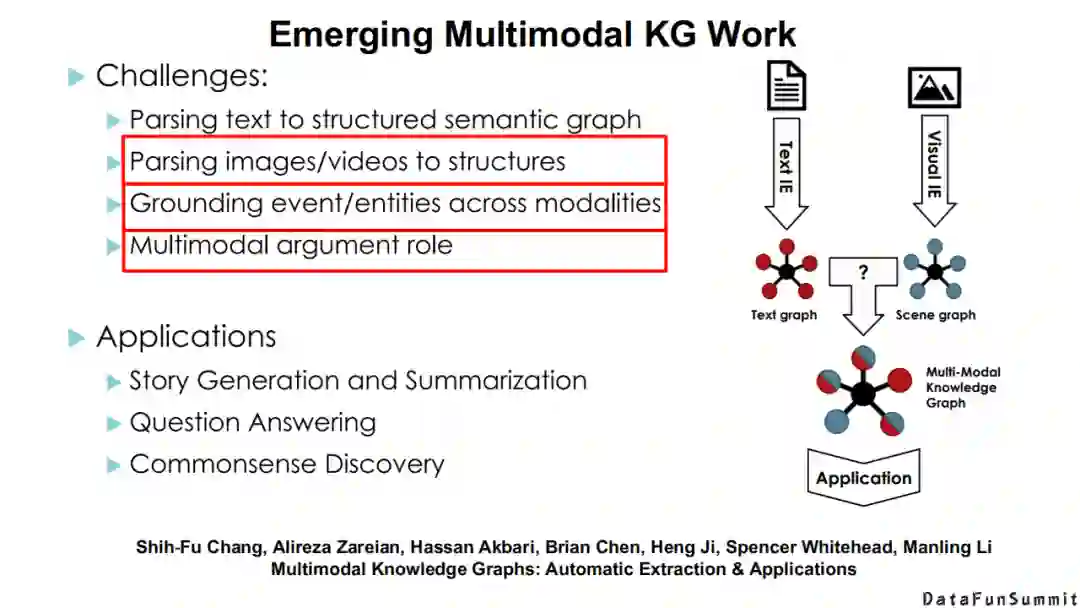
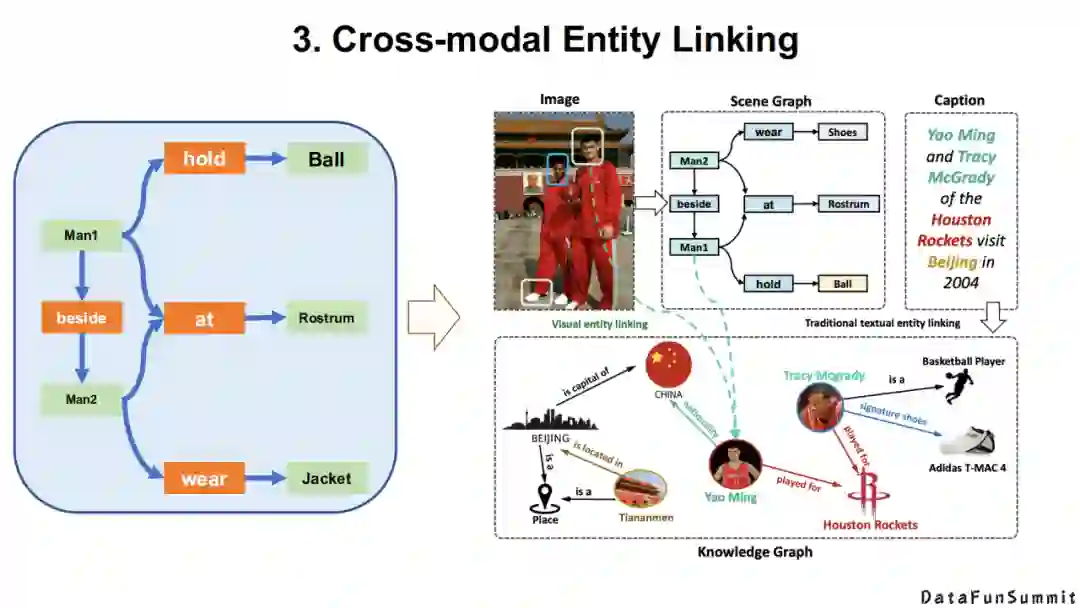
他们总结了在将文本知识与场景知识融合过程中所面临的一些挑战。专门提到了不同模态知识的精准对齐是多模态知识发现中的一个核心问题。
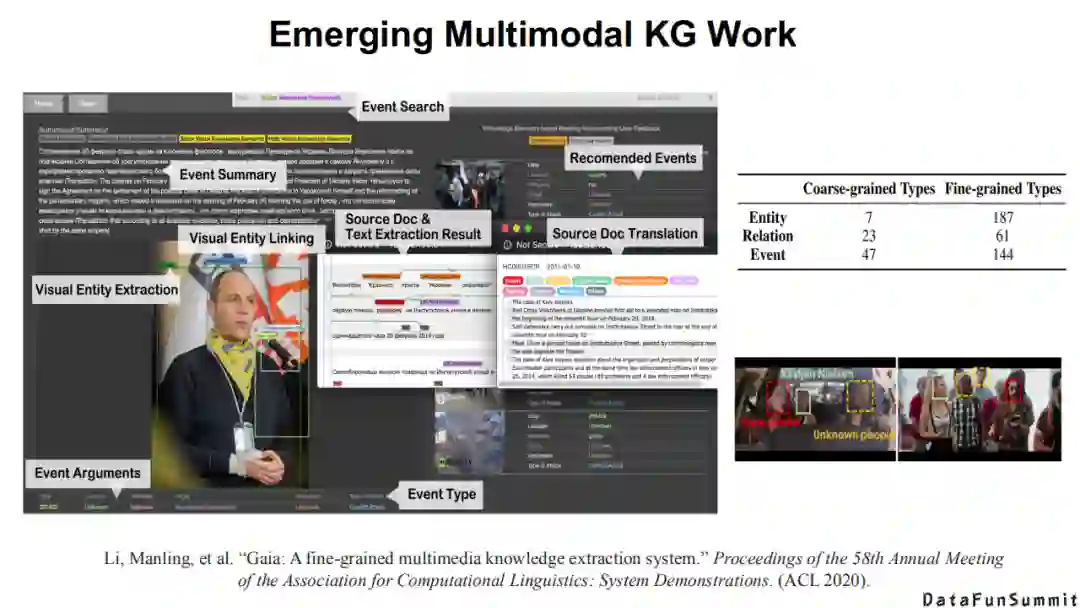
在去年的ACL会议上,他们详细介绍了一个多模态知识发现的系统。
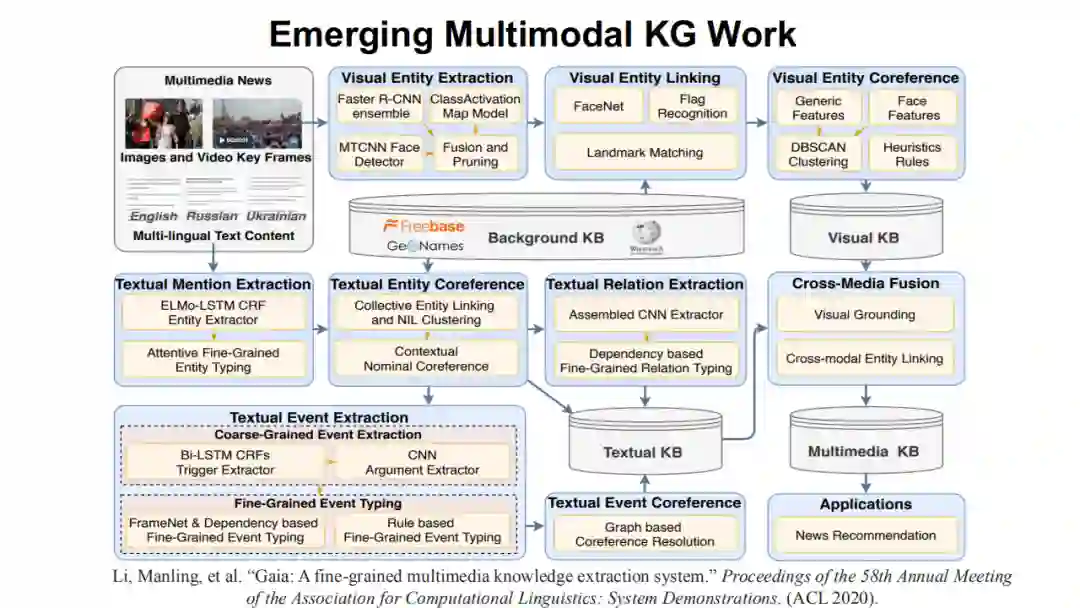
上图为该系统的主要架构,我们可以发现:多模态知识发现其实是一个庞大的工程,因为每种模态的知识都有不同的抽取方法,不同模态的知识还涉及对齐以及联合学习等核心问题。
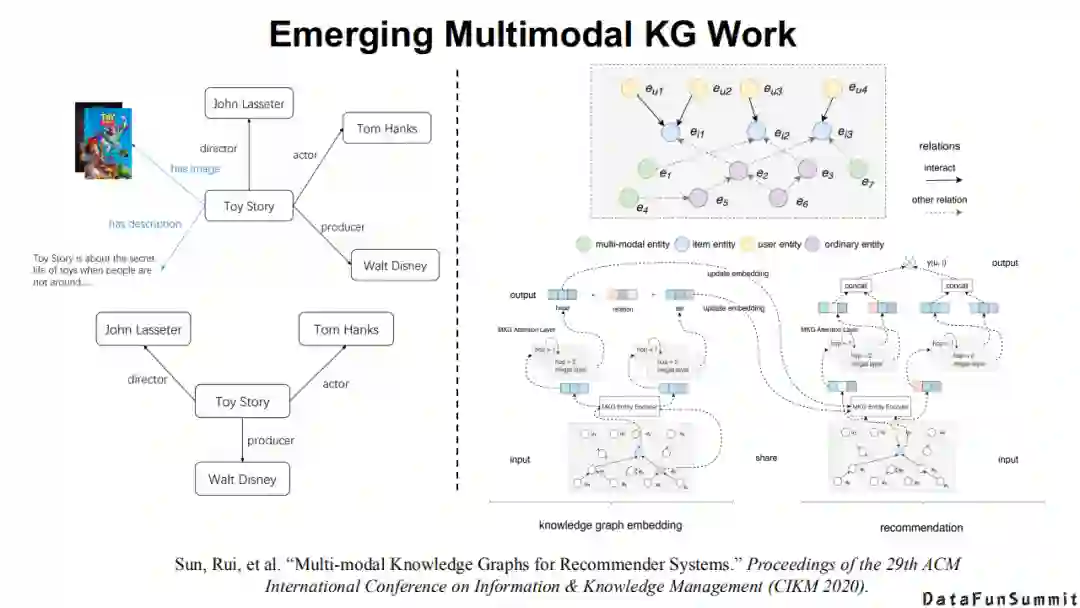
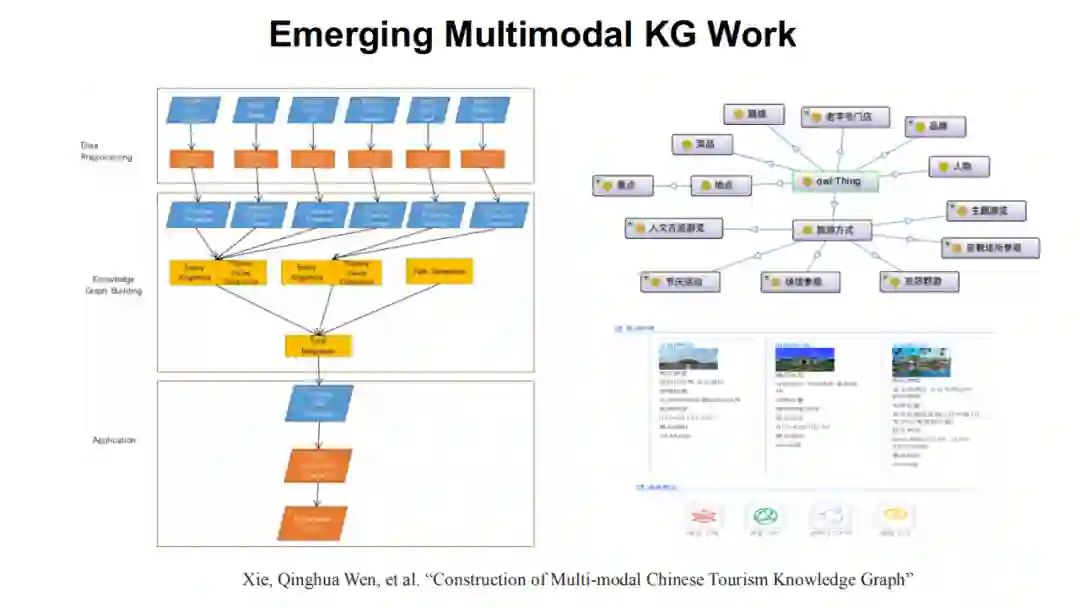
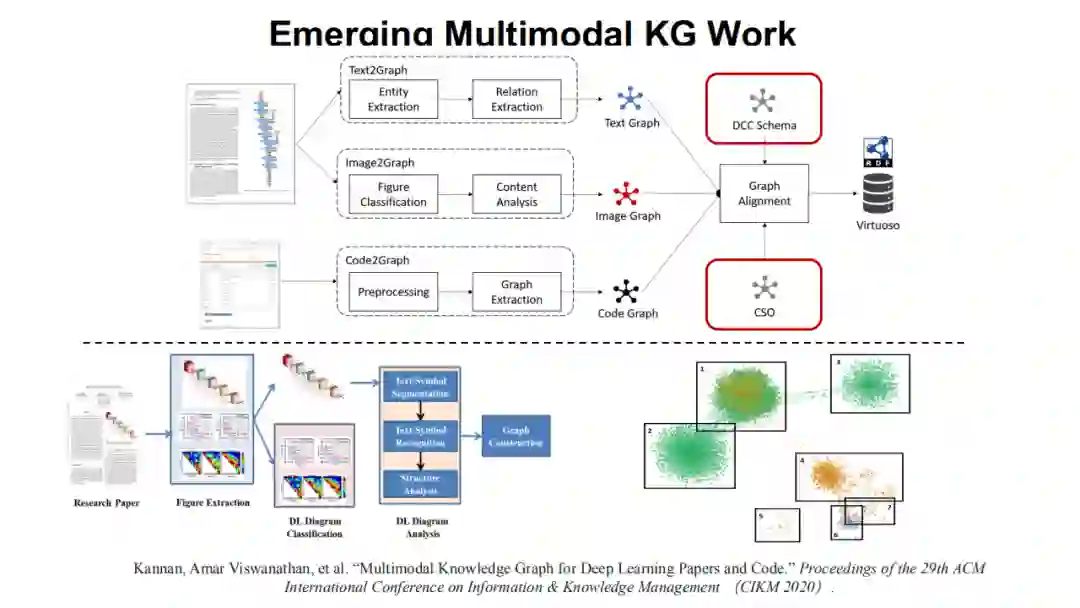
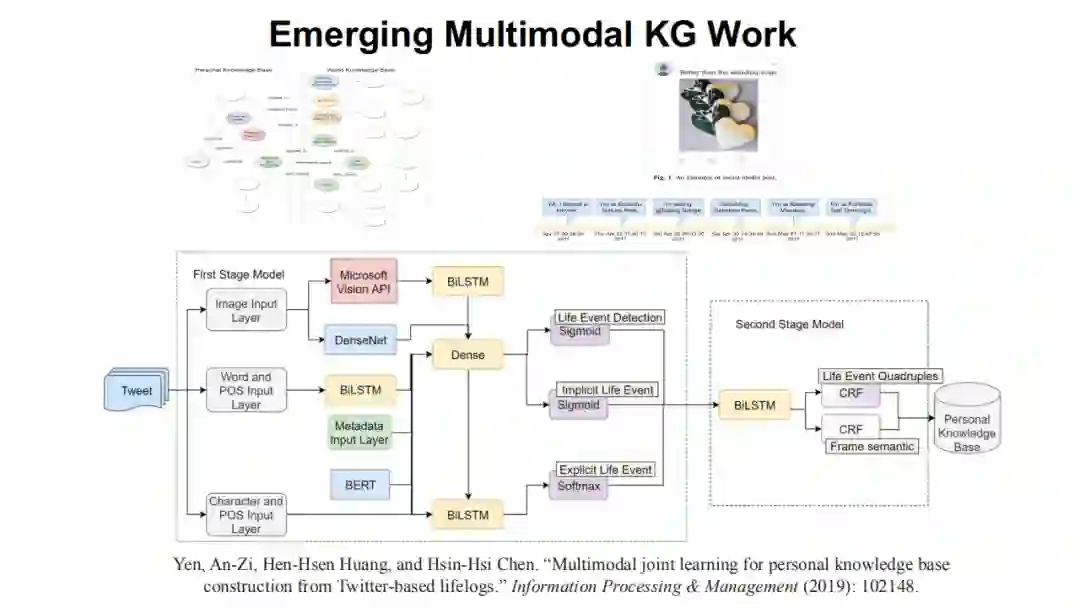
大家可以顺着去发现在推荐系统(请见《Multi-modalKnowledge Graphs for Recommender Systems》一文)、旅游场景(请见《Constructionof Multi-modal Chinese Tourism Knowledge Graph》一文)、软件工程(请见《Multimodal Knowledge Graph for Deep Learning Papers and Code》一文)以及个人生活场景(请见《Multimodal joint learning for personal knowledge base constructionfrom Twitter-based lifelogs》一文),都可以发现多模态知识发现和多模态知识图谱过程中不同知识和神经系统相结合的一些探索。
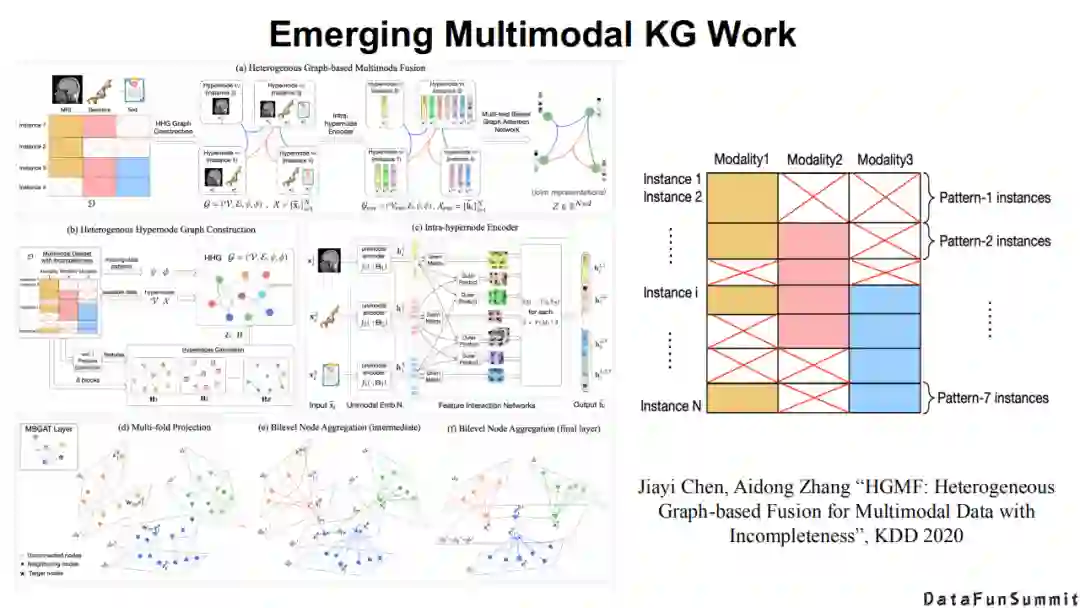
以及在多模态知识的表征学习方面,都可以看到各有侧重的方法(请见《HGMF:Heterogeneous Graph-based Fusion forMultimodal Data with Incompleteness》一文)。
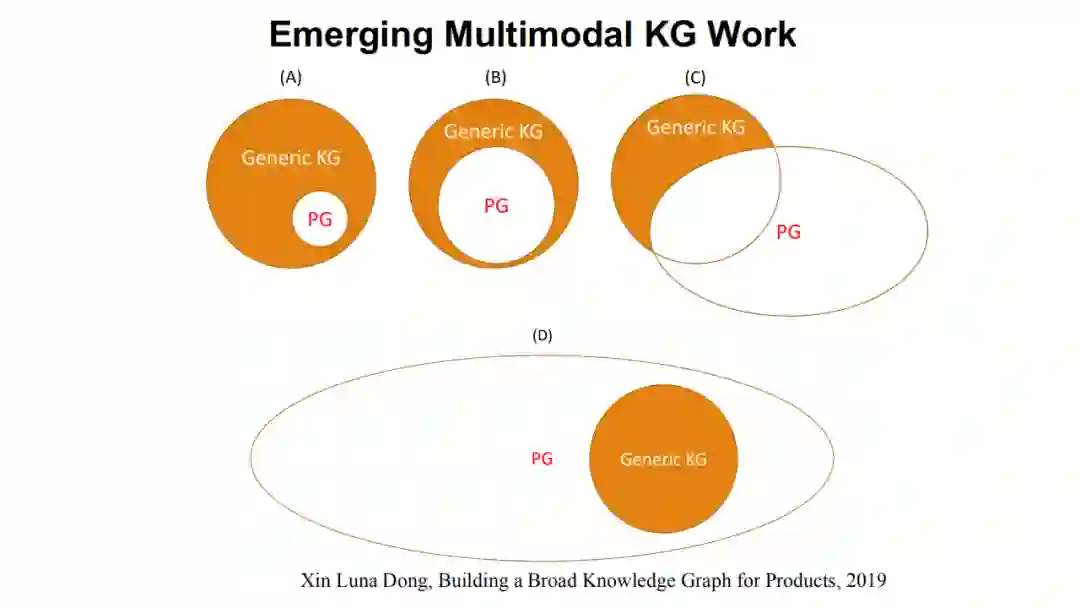
这里总结一下,我借鉴Dong老师等人的表达,上图所示为商品知识图谱。多模态知识图谱的发展最终会向上图中所总结的情况一样,在开始时(2016-2017年),多模态知识图谱只是传统知识图谱中的一个小块(如图(A)),大家刚刚开始关注这个问题;到2020年,我们发现传统知识图谱和多模态知识图谱逐渐成为并列关系(如图(B));未来,我相信多模态知识图谱必定是包含了传统知识图谱(如图(D))。
2. 我们的多模态知识图谱
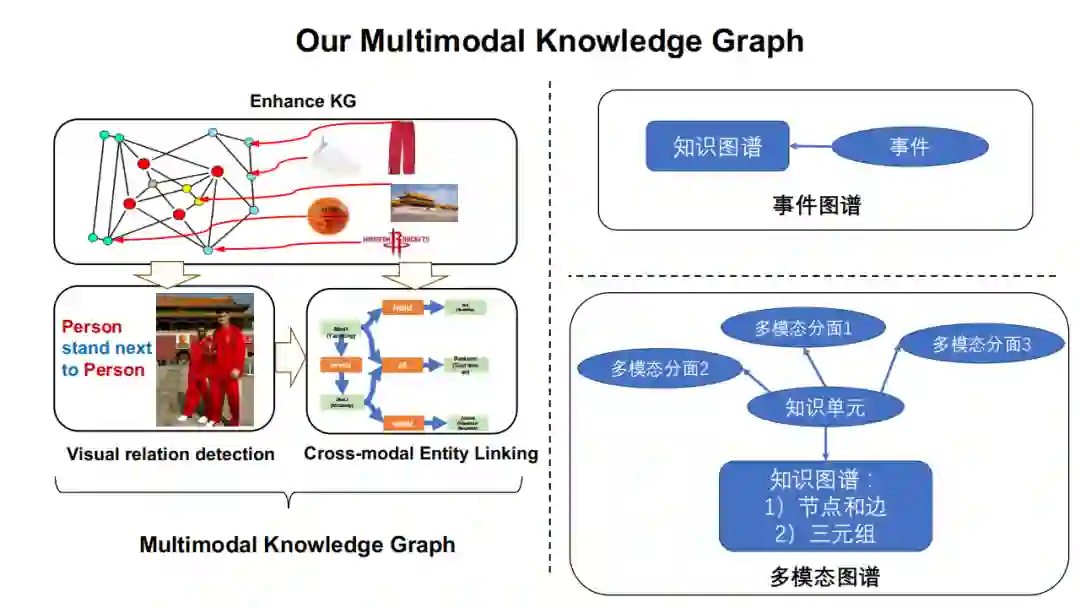
现在我简单介绍一下我们的相关工作。作为一个研究知识表示出生的团队,我们主要还是立足于我们已有的知识图谱,并不断扩展多模态的信息。然后对于给定的场景,如场景图分析、人脸识别问题,我们进行一些神经抽取。最后我们将由神经系统抽取的粗粒度类别信息与我们已有的符号信息相结合,并应用于一些实体级别的任务上。上图(右)表示我们对于多模态知识的建模,包括多模态知识图谱的“样子”,以及基于场景的多模态发现(类似于场景图)。
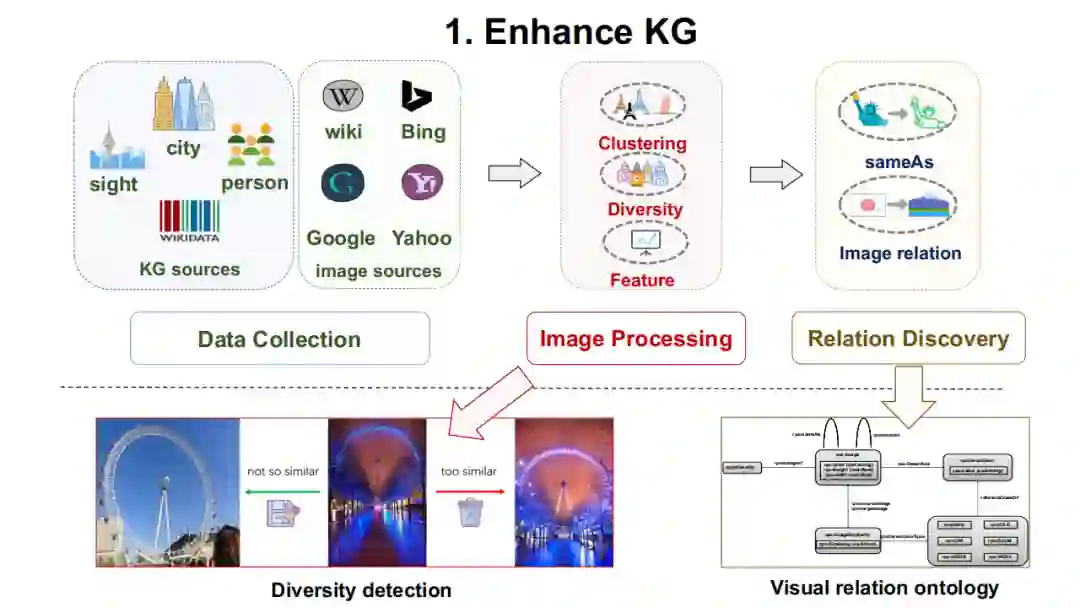
对于上图中的每个部分,我们都有相应的论文。

这里也做一个广告。由于多模态数据/知识图谱还是一个初级的研究领域,相信今天在座的各位同学和老师都有自己的多模态资源,我们今年在CCKS的论文征集中将有一个全新的模块,即Resource Track。欢迎大家将自己的数据都投稿至这个模块,同时它也是被正文录取的。希望大家能够在整个知识图谱与语义计算的社群中乐于分享自己的数据。
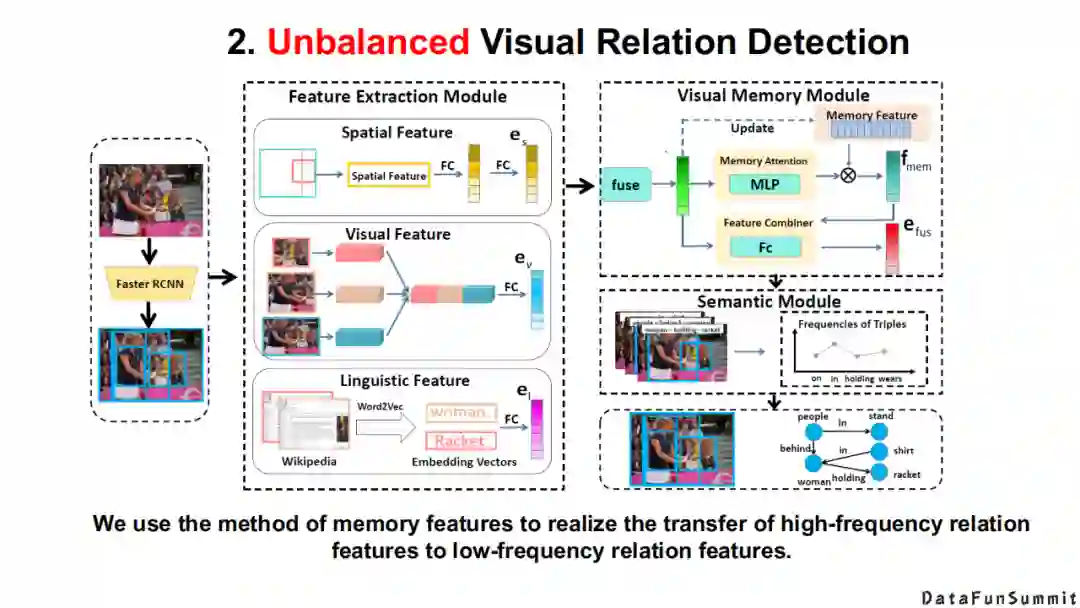
以上是我们对于场景的理解。
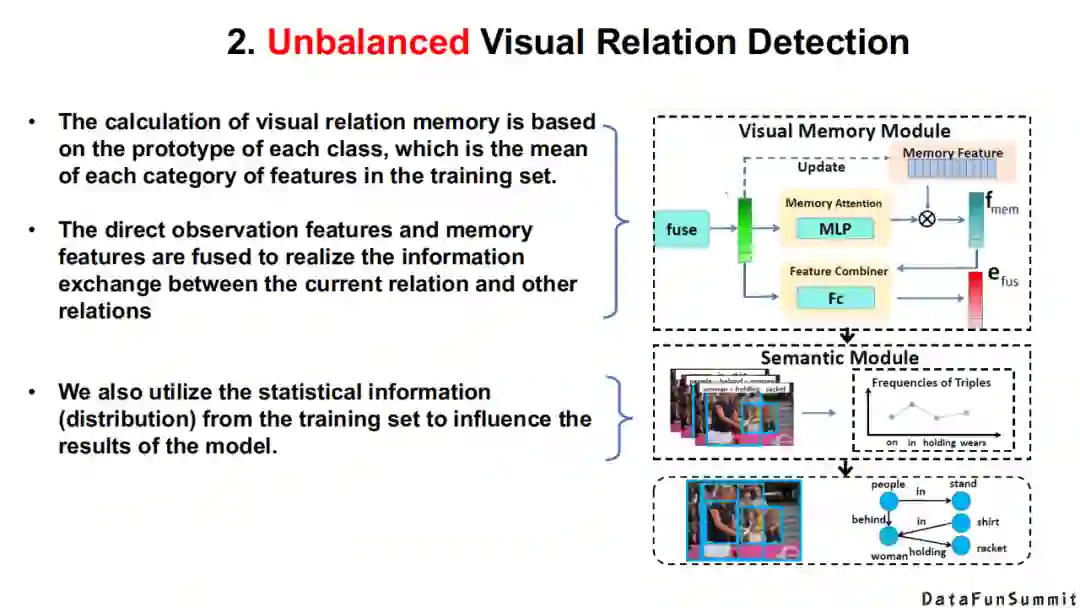
例如,我们在符号层级是如何求解这个问题的。
例如在符号层级,我们如何利用拥有的知识去解决尾部关系类型很少的实体抽取。
最后我们实现的效果是将传统意义上的粗粒度的场景图映射为一个实例级别的场景分析上。
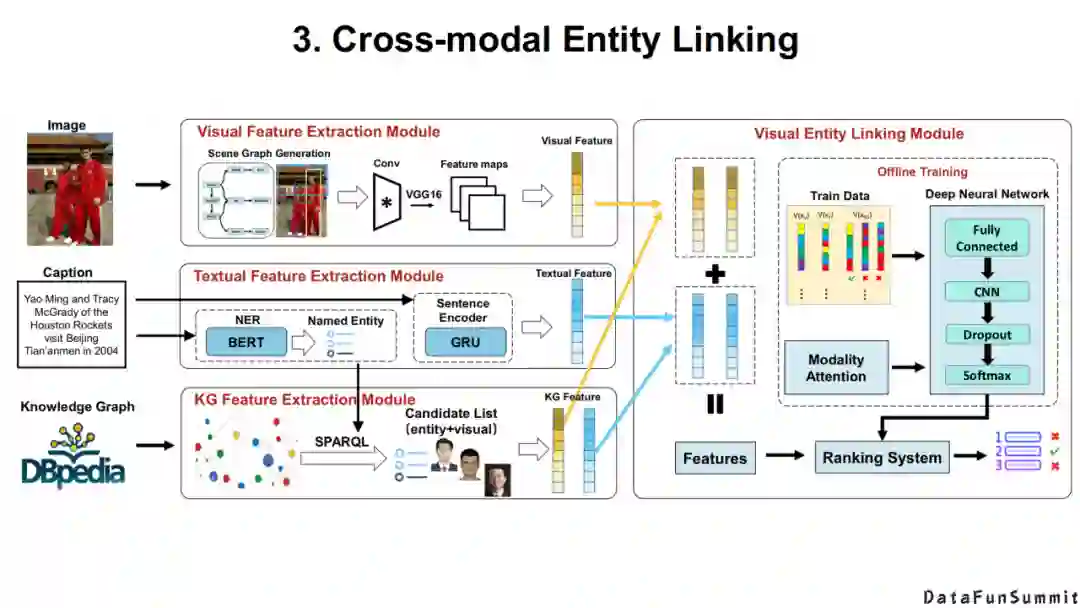
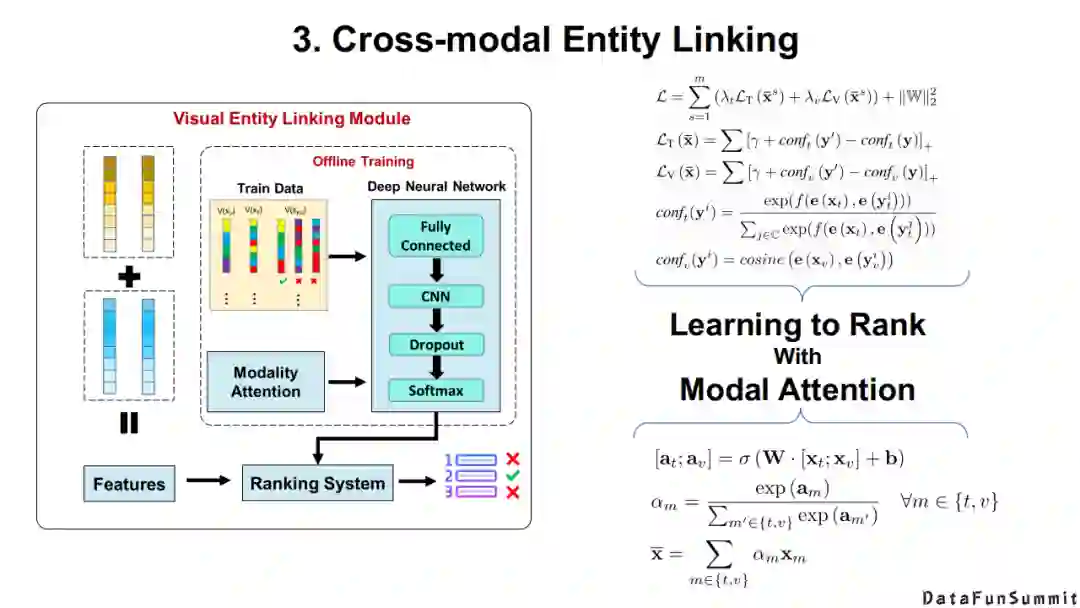

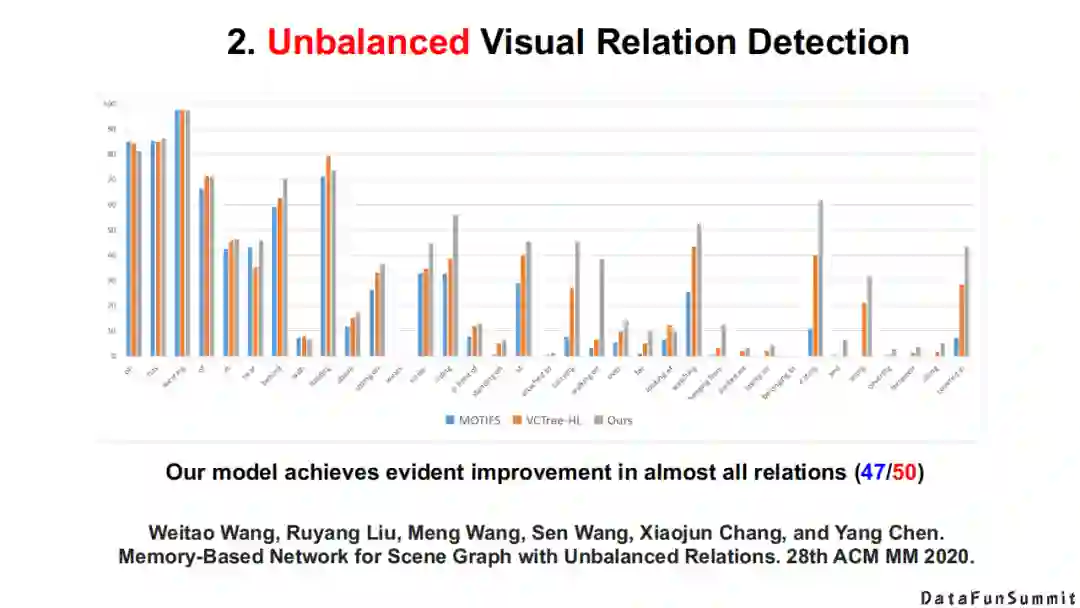
以上为该模型的整体框架,以及相应的实验结果。
3. 其它多模态发现任务
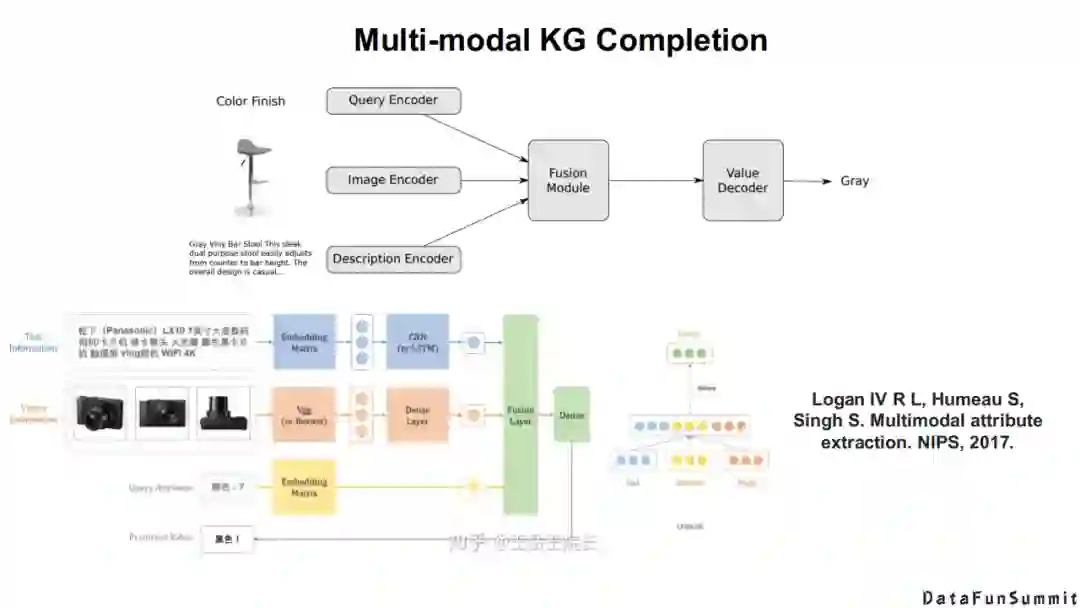
首先是多模态知识的补全,如上图所示。
还有如何从无标签视频中抽取我们常见的知识。
那么多模态是否真的有用呢?
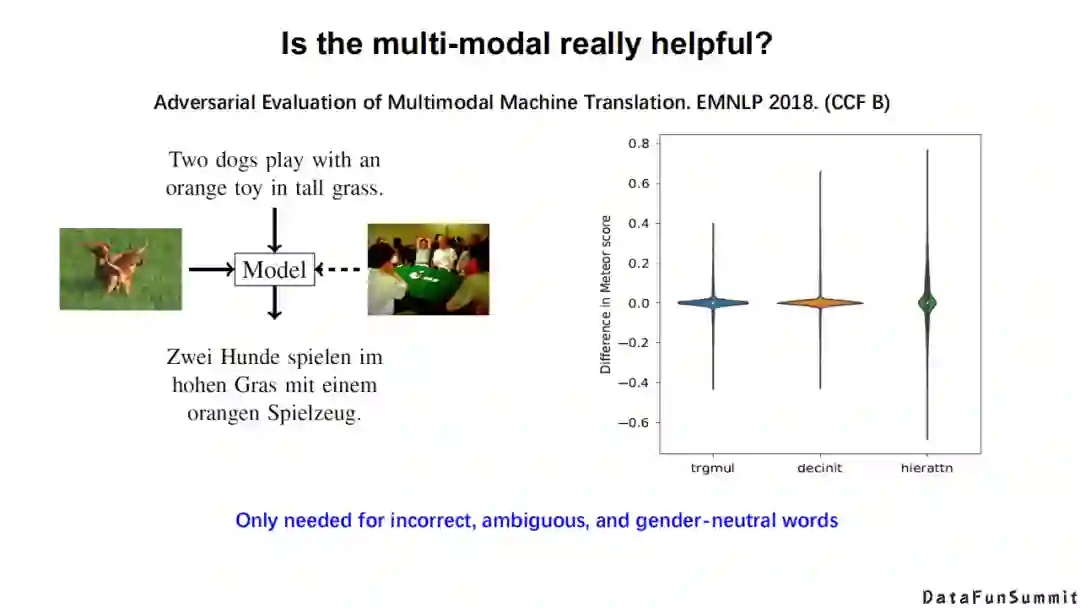
上图是多模态机器翻译的对抗性评价。
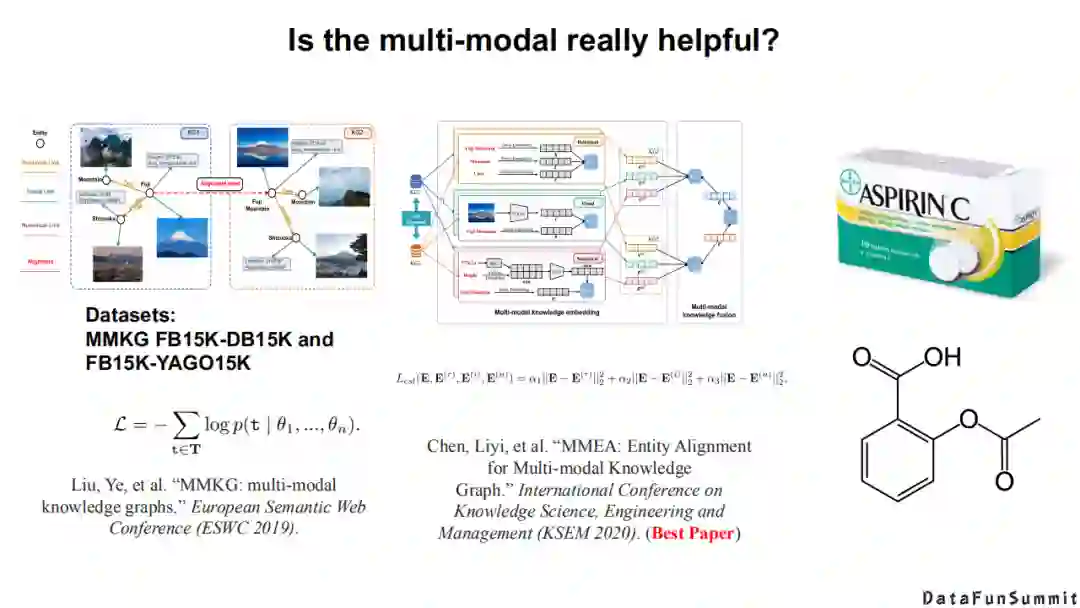
多模态知识图谱在2019年ESWC这个会议上发表了一个被广泛关注的数据集,即MMKG(multi-modal knowledge graphs)。在去年的KSEM上,中科大徐童老师也在这个数据集的基础上提出了自己的模型。但是,如果你自己分析过这个数据集,就会发现其中包含大量的噪声,例如阿司匹林这个药,我们在对齐两个知识图谱上的阿司匹林数据时,如果使用单模态的知识图谱去完成对齐,我们发现已经能够取得不错的效果。但是,如果加入照片信息,会发现模型的效果会降低。我们发现产生上述问题的原因在于,其中一个知识图谱中的阿司匹林是一个药盒,另外一个知识图谱中的阿司匹林是一个分子结构。在这种情况下,实际上多模态信息起的是一种反作用。到底什么场景下的多模态联合信息是有作用的,什么场景下的多模态信息是起反作用的,这也是接下来我们值得关注的问题。
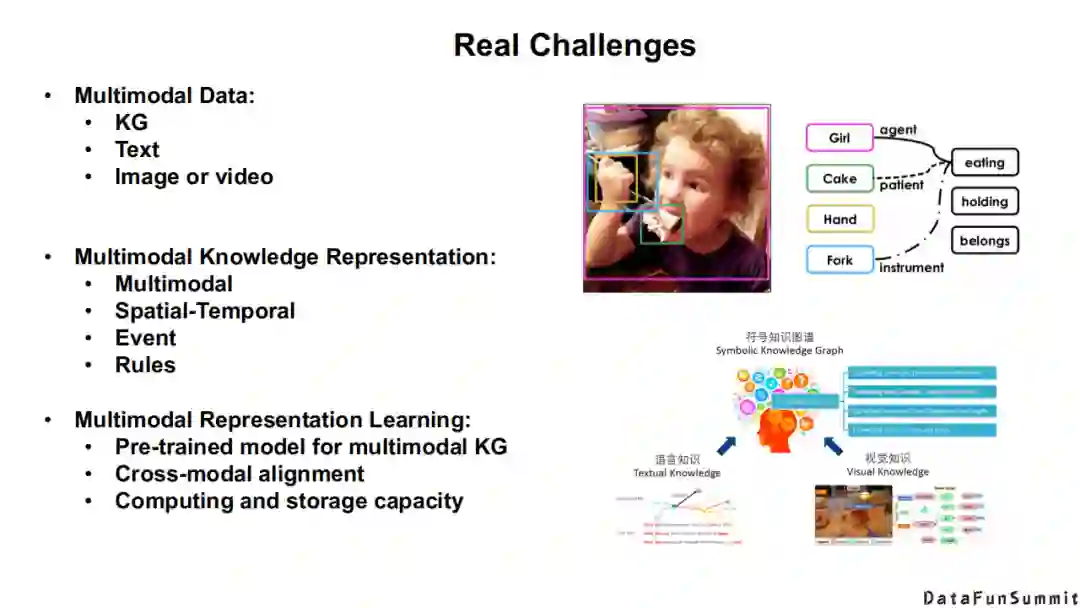
接下来,我总结了多模态数据/知识图谱中的真实挑战:
是否真正有多模态的数据,如知识图谱、文本数据、图像和视频等;
在符号层级,我们需要去思考多模态知识/符号知识应该如何去表达;
在神经网络层级,我们需要去探索多模态预训练语言模型,是否有不同模态基准的对齐,以及是否有强大的计算资源。

最后谈一下不同模态的知识,不同的研究者有不同的见解。大家一定不要把多模态想象成图片、文本、音频、视频,以及非结构化的知识。例如在照片层级,我们有cp图像,也有核磁共振图像,超声图像,其实这些都是多模态的数据;在文本层级,也可以定义出属于自己的多模态信息。
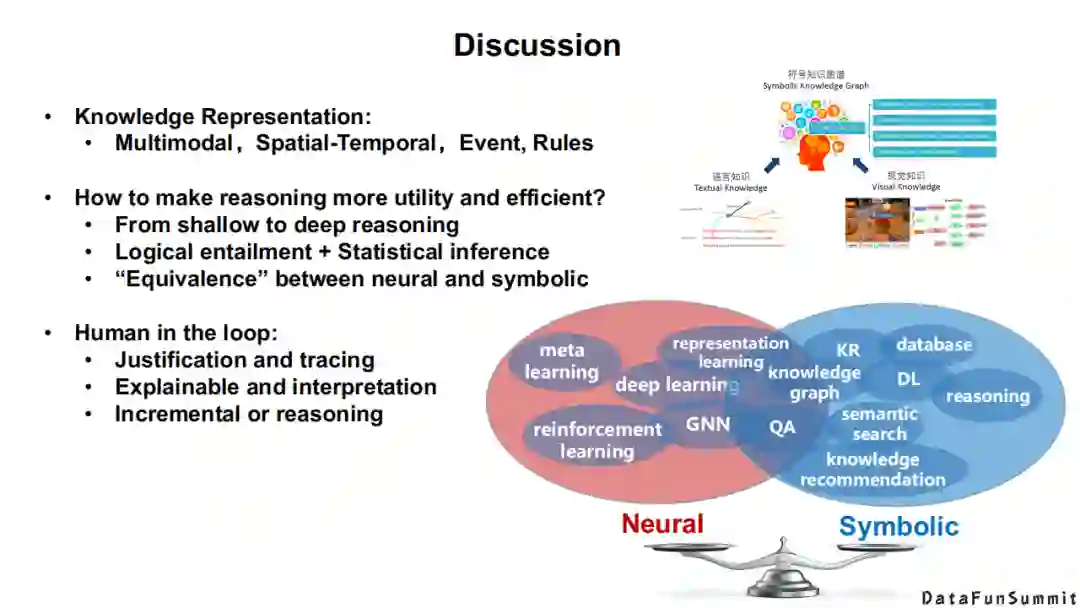
上图给出了这个领域未来的浅层研究方向,大家可以去探讨。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“多模态” 就可以获取《多模态专知资料合集》专知下载链接







