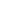本讲义系列主要整理自浙江大学《知识图谱导论》(浙江省优秀研究生课程)的课程讲义。作为一门导论性质课程,该课程希望帮助初学者梳理知识图谱基本知识点和关键技术要素,帮助技术决策者建立知识图谱的整体视图和系统工程观,帮助前沿科研人员拓展创新视野和研究方向。
本次推文主要介绍讲义的“第一讲 知识图谱概论 第1节 语言与知识”,更多内容请点击文末“往期推荐”。
在这一讲中我们希望首先对知识图谱的来龙去脉做一个概论性的介绍,我们将首先从语言和知识两个视角阐明知识图谱是实现认知人工智能的关键一环,然后我们会追溯知识图谱的发展历史,来说明知识图谱不仅和人工智能有关系,而且具有非常强烈的互联网基因。
接下来我们希望全面的探讨知识图谱的广泛应用价值。同时,知识图谱也并非是一个抽象空洞的概念,它有自己非常明晰的技术内涵和技术边界。我们希望通过第一讲,让大家充分认识到不论是从人工智能、大数据、还是互联网的视角,知识图谱都是非常重要的技术发展方向。
首先我将从“语言与知识”两个视角出发引出我们这门课的主角——知识图谱。
大家可能都有所了解,早期的人工智能有两个主要流派,一个流派称为连接主义,主张智能的实现应该模拟人脑的生理结构,即用计算机模拟人脑的神经网络连接结构,这个流派发展至今,即所谓大红大紫的深度学习;
另外一个流派称为符号主义,主张智能的实现应该模拟人类的心智,即用计算机符号记录人脑的记忆,表示人脑中的知识等,即所谓知识工程与专家系统等。
我们这门课的主角知识图谱可以归属于符号主义的流派。深度学习首先在视觉、听觉等感知任务中获得成功,本质上解决的是识别和判断问题,我们可以打比方为实现的是一种聪明的AI。但感知还是低级的智能,人的大脑依赖所学的知识进行思考、推理、理解语言等等。
因此,还有另外一种AI可以称为是有学识、有知识的AI。事实上,这两种AI对于实现真正的人工智能都很重要,缺一不可。
![]()
什么叫认知智能?认知智能有两个核心的研究命题,一个是语言理解,另外一个就是知识表示。
人类通过认识世界来积累关于世界的知识,通过学习到的知识来解决碰到的问题,比如一个医生利用他的医学知识来给病人看病。
而语言则是知识最直接的载体,目前为止,人类的绝大部分知识都是通过自然语言来描述、记录和传承的。同时反过来,正确理解语言又需要知识的帮助。
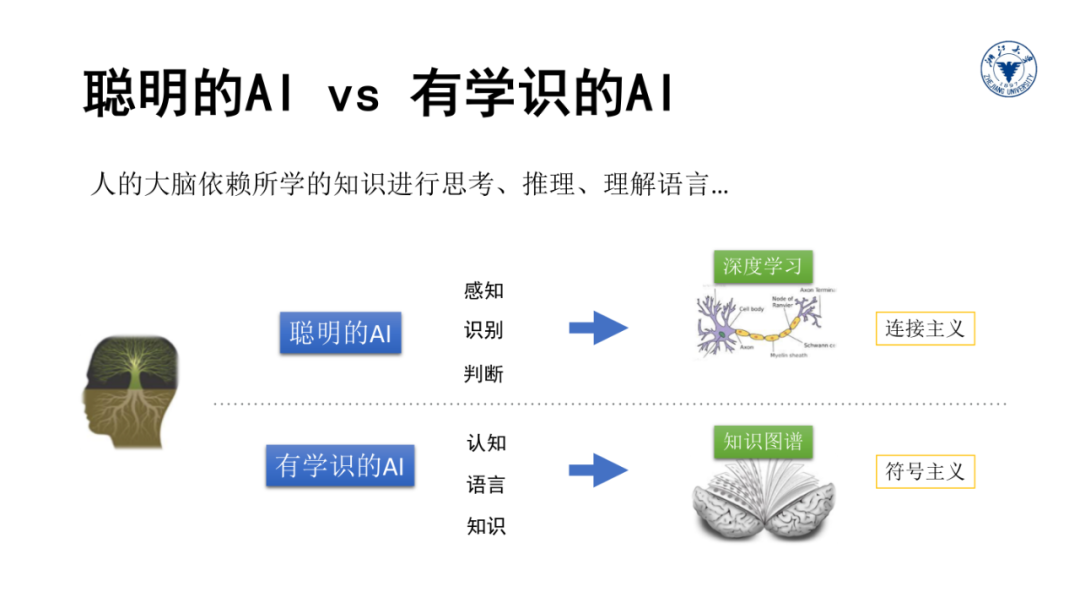
这里有个有趣的段子,G20期间,马云对秘书说,中午帮我买肯德基,30分钟后,秘书回来说,买好了,一共4.6亿美元。这当然是个玩笑,但马云的蚂蚁金服的确投资了肯德基的母公司百胜餐饮集团。当然我们这里关注的是背景知识对于理解语言的重要性。
比如假如马云的秘书是一个人工智能,它在第一个语境中,应该把肯德基识别为一种食品,而在第二个语境中应该把肯德基识别为一家公司,而且它还需要知道肯德基的母公司是百胜,蚂蚁投资了百胜,而马云是蚂蚁的实际控制人,才能正确地判断马云和肯德基的关系,这就是知识图谱。
事实上,我们每个人的大脑里面都有大量这种类型的关于万事万物的知识图谱,我们极大的依赖这些背景知识来准确理解语言和正确做出判断。
那到底什么是知识?柏拉图说知识是“Justified True Belief”。
实际上,人类的自然语言,以及创作的绘画和音乐、数学语言、物理模型、化学公式等都是人类知识的表示形式和传承方式。具有获取、表示和处理知识的能力是人类心智区别于其他物种心智的最本质特征
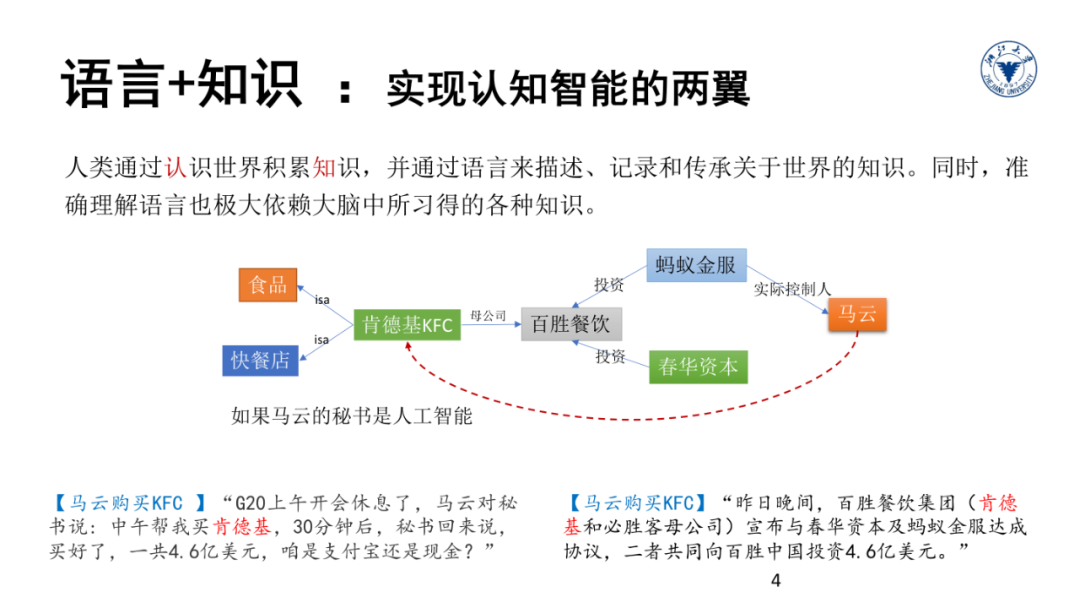
所以传统的人工智能领域有一个经典研究方向叫知识工程和专家系统。这种经常被称为是Old Fashioned AI的基本思想是建立一个系统能够从专家大脑里获取知识,这类知识可以是框架系统、语义网络或产生式规则,这个从人脑获取知识的过程叫作知识工程。再通过一个推理引擎来为非专家用户提供服务,比如辅助诊断、判案等等。
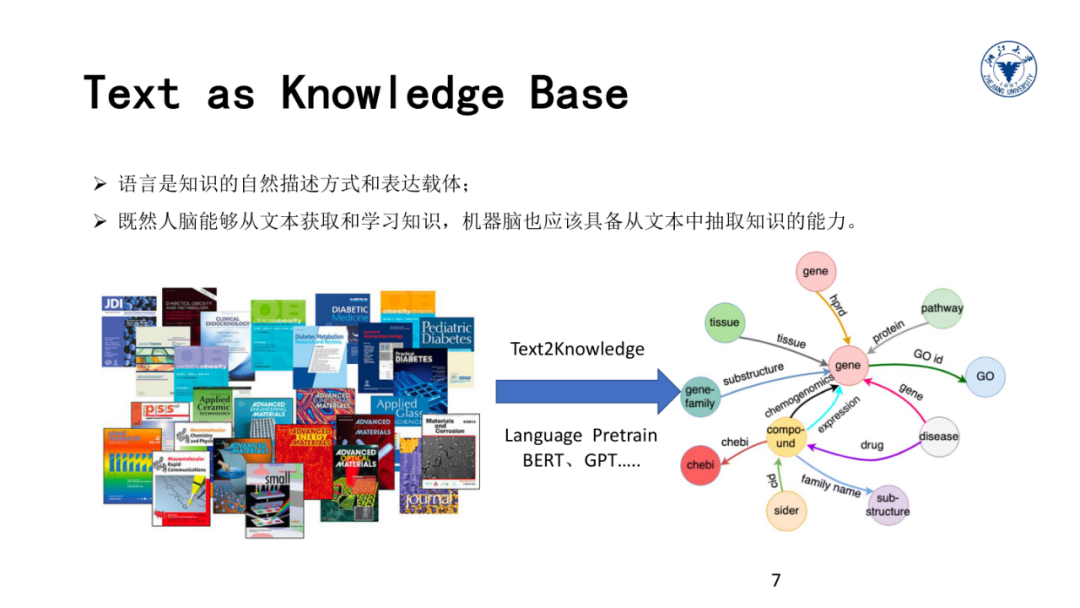
如前所述,自然语言是人类知识最主要的表达载体。既然人脑能够通过阅读来从文本获取和学习知识,机器脑也应该具备从文本中抽取知识的能力。但文本字符串似乎对机器不太友好,机器在理解人类语言方面仍然步履维艰。
比如类似于微软小冰、苹果Siri、小米小爱音箱等产品在人机对话方面体验都有很大的缺陷。当前,通过机器来理解文本中的知识有两大主要技术路线,第一种是抽取技术,例如从文本中识别实体、关系、逻辑结构等等;
第二种是文本预训练,即:通过大量的文本预料来训练一个神经网络大模型,文本中的知识被隐含在参数化的向量模型中,而向量化的表示和神经网络是对机器友好的。
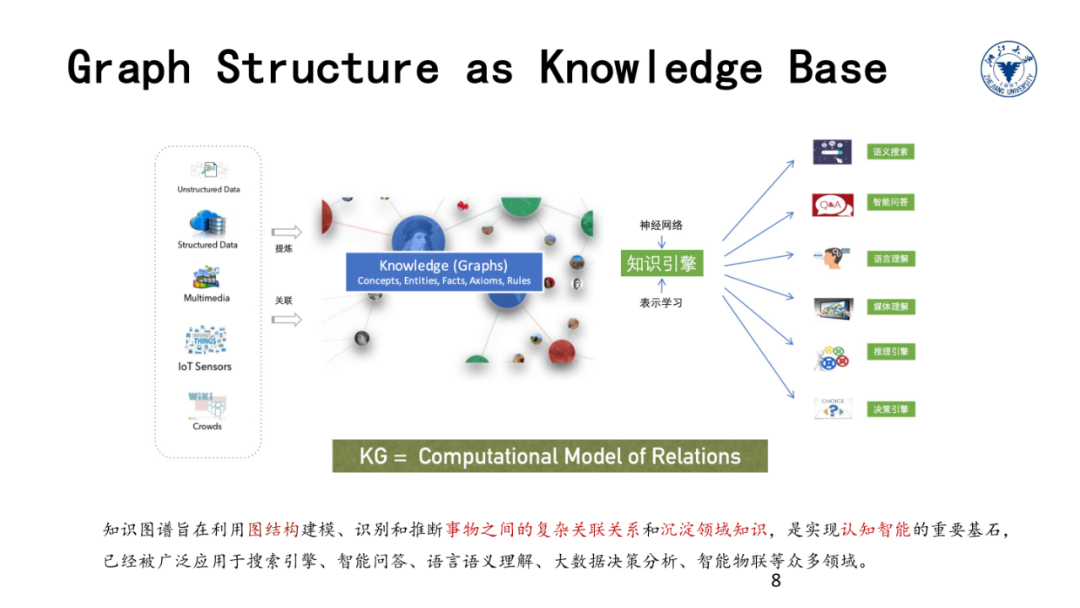
知识图谱是我们这门课的主角。简单的说,知识图谱旨在利用
图结构
建模、识别和推断
事物之间的复杂关联关系和沉淀领域知识
,已经被广泛应用于搜索引擎、智能问答、语言语义理解、大数据决策分析、智能物联等众多领域。
知识图谱是一种结构化的知识表现形式。相比起文本而言,结构化数据更易于被机器处理(比如查询和问答),同时图结构比起字符串序列能够表达更为丰富的语义和知识。
对于机器而言,图结构比文本更加友好。深度学习,或者更为准确的说是表示学习的兴起,表明参数化的向量和神经网络是适于完成快速计算的信息载体。
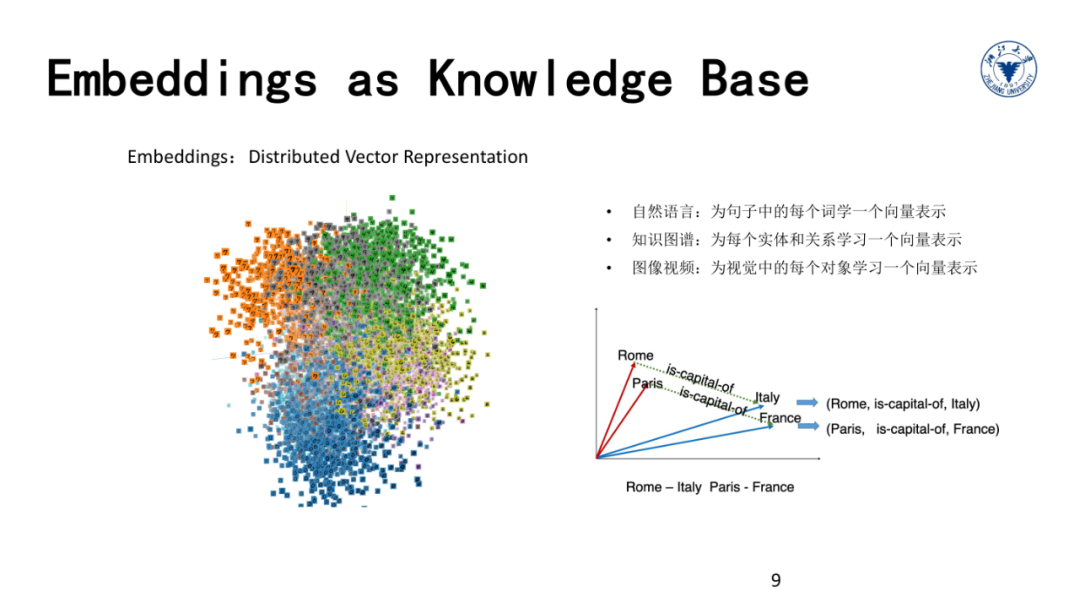
比如,我们在自然语言中,可以为每个词学一个向量表示,我们也可以为视觉场景中的每一个对象学习一个向量表示,为知识图谱中的每一个实体学习一个向量表示。我们通常把这些对象的向量化表示称为Embedding或“Distributed Vector Representation”。
如图所示,我们将所有数字的向量表示投影到向量空间,我们会发现同一个数字的不同图像的向量在空间距离更近。
因此,我们通过将词语、实体、对象、关系等都投影到向量空间,就可以更加方便的在向量空间对这些语言、视觉和知识对象进行操作,甚至可以利用神经网络来实现逻辑推理。这将是我们这门课的最重要的话题之一,将在知识图谱表示学习与推理这一讲中重点展开介绍。
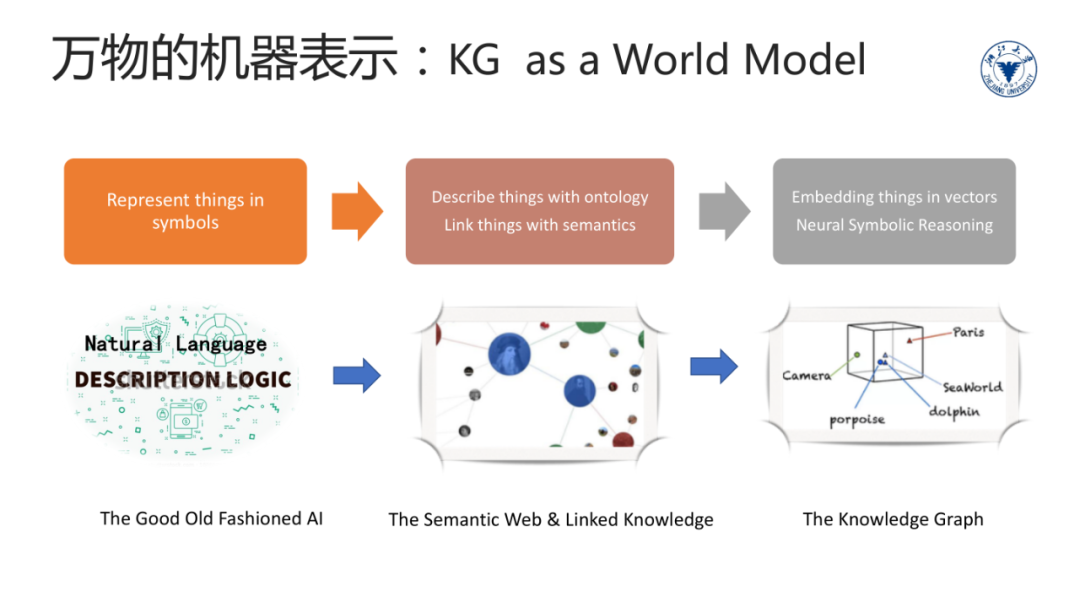
我们这门课的主角——知识图谱本质上可以看作是一种世界模型——World Model。
纵观人工智能相关方向的发展历史,一直有一个核心的命题是寻找合适的万物机器表示,记录有关世界的知识。在传统的专家系统时代,人们发明了描述逻辑等符号化的知识表示方法来描述万物。人类的自然语言也是符号化的描述客观世界的表示方法。
到了互联网时代,人们又设想用本体和语义链接有关万物的数据和知识,这也是知识图谱的起源之一。随着表示学习和神经网络的兴起,人们发现数值化的向量表示更易于捕获那些隐藏的不易于明确表示的知识,并且比起符号表示更易于机器处理。
知识图谱同时拥抱机器的符号表示和向量表示,并能将两者有机的结合起来解决搜索、问答、推理、分析等多个方面的问题。关于这一点的介绍也将贯穿这门课程的始终。
我们最后做一个小结:人的大脑依靠所学的知识进行思考和推理
,具有表示、学习和处理知识的能力是人类心智区别于其他物种最根本的区别。
语言是知识的最主要表示载体
,语言与知识是实现认知智能最重要的两个方面。知识图谱是一种
结构化的知识表示方法
,相比于文本更易于被机器查询和处理。
语言与知识的向量化表示
,以及利用神经网络实现语言理解与知识处理是目前最重要的技术发展趋势之一。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取5000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取5000+AI主题知识资源