KDD20 | 解决基于图神经网络的会话推荐中的信息损失

论文专栏: 图神经网络在推荐系统中的应用
论文解读者: 北邮 GAMMA Lab 硕士生 王浩

题目: 解决基于图神经网络的会话推荐存在的信息损失问题
会议: KDD 2020
论文地址: https://dl.acm.org/doi/pdf/10.1145/3394486.3403170
推荐理由: 这篇论文提出了目前在使用图神经网络方法来解决基于会话的推荐问题时所存在的两个信息缺失问题并建立一个没有信息丢失问题的模型,在三个公共数据集上优于最先进的模型。
1 引言
在许多在线服务中,用户的行为自然是按时间排序的。为了预测用户未来的行为,下一项(next-item)推荐系统通过从用户的历史行为中挖掘序列模式来学习用户的偏好。基于会话的推荐是下一项推荐的特殊情况。与一般的下一项推荐系统使用固定数量的前n项来预测下一项不同,基于会话的推荐系统将用户的操作分组为互不关联的会话,只使用当前会话中的项目来进行推荐。其中会话是在时间上接近的一组项目。基于会话的推荐的思想来自于这样一种观察,即会话内依赖项对下一项的影响比会话间依赖项更大。因此,一般的下一项推荐系统可能存在合并不相关会话和提取不完整会话的问题。而基于会话的推荐系统则不存在这样的问题,因此可以做出更准确的推荐,并被部署在许多在线服务中。
1.1 问题定义
基于会话推荐的目标是,根据会话中已经被点击的一系列项目,推荐用户下一次最有可能点击的项目。在形式上, 表示所有项目的集合,其中|I|表示项目的总数。任一会话是一个按照时间排序的项目集合,其中 表示会话 在第 个的项目。模型的目标是预测会话 的第 项。常用的方法是生成第 项的概率分布,然后概率排名前k的项目被推荐给用户。
1.2 基于GNN方法所存在的信息缺失问题
最近,GNNs变得越来越流行,有一些尝试将GNNs应用于基于会话的推荐,并且取得了令人兴奋的结果,并为基于会话的推荐提供了一个新的和有前景的方向,但这些方法存在两个信息丢失问题,限制了这类GNN方法的性能。首先是有损会话编码问题,基于GNN的方法需要先将每个会话序列转换成有向图的形式,其节点是会话中不同的项,边是项之间关系的转换。相邻两项之间存在前项到后项的有向边,边可以是带权重的也可以不是。如图所示,目前的转换方式是存在信息缺失的,会话与图不是一一对应关系,如下图所示,不同的会话可能对应同一个图。
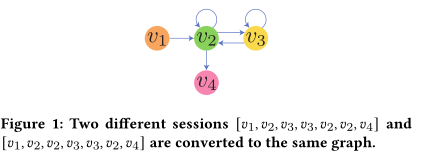
第二个问题是无效的长期依赖捕获问题,基于gnn的方法不能有效地捕获所有的长期依赖。在GNN模型的每一层中,只能捕捉1跳关系。通过叠加多层,GNN模型可以捕捉到多跳关系等于层的数量。由于叠加更多的层会因为过拟合和过平滑问题而无法提高性能,所以GNN层数一般不超过3层。因此,模型最多只能捕捉到3跳关系。然而,在实际应用程序中,会话长度很容易大于3。因此,很可能有一些重要的序列模式的长度超过3,但是由于模型的限制,这些基于gnn的模型无法捕获这些信息。
2 方法
针对当前GNN方法存在的问题,作者提出了解决信息缺失的基于GNN的推荐系统模型,其中包括两个主要组成部分。第一部分是将每个输入会话分别转换为带边序(EOP,edge-order preserving)图和快捷图(shortcut graph)的模块,因为提出的GNN模型需要两种类型的图作为输入。第二个组件是提出的GNN模型LESSR。
2.1 会话到图的转换
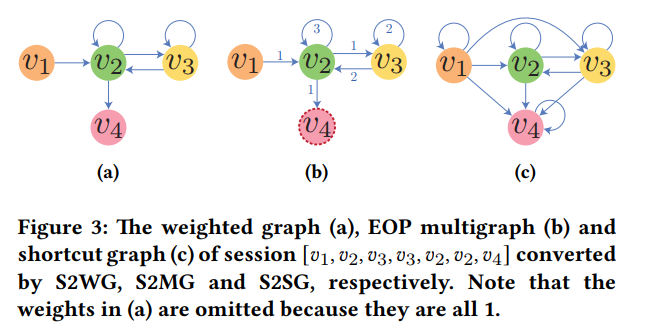
针对提出的两种信息缺失的问题,本文提出两种会话转化为图的方法,针对有损编码信息问题,提出一种名为S2MG(Session to EOP Graph)的方法,它将会话转换为EOP图;针对GNN模型层数限制捕捉长期依赖问题采用S2SG(Session to Shortcut Graph )的方法,将会话转换为快捷图。
S2MG方法:如下图所示,对于每个节点,对指向该节点的边按照时间进行排序,并记录这些边的出现顺序。如节点 中边的出现顺序为 。同时记录哪一个节点为整个会话的最后一个节点。
S2SG方法:未解决长期依赖无法捕捉问题,作者提出了一种捷径图机制,将会话中所有前期出现过的节点都与其后出现的节点相连,保证一阶邻居聚合就可以捕捉到长期依赖关系。
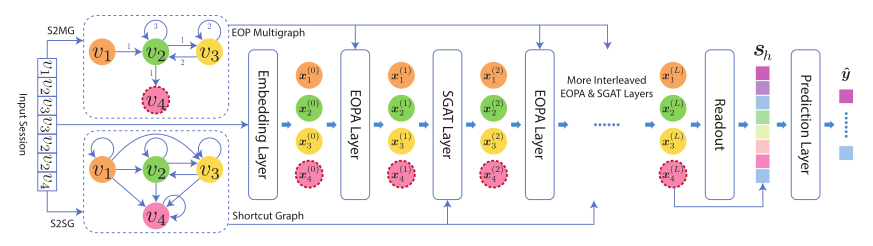
2.2 GNN模型: LESSR
论文所提出GNN模型的完整结构如下图所示:通过对EOP图与捷径图考虑不同的邻居聚合机制,分别设计了EOPA层以及SGAT层,通过堆叠这两种网络层最终获取整个会话的嵌入,然后进行下一个项目的预测。
首先介绍EOPA层,作者认为边的顺序信息对最终的项目预测影响很大,所以采用一种GRU结构对节点的一阶邻居传递的信息进行聚合,保留了邻居传播信息的相对顺序。EOPA层的定义如下公式所示
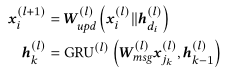
其中 和 是学习参数, 表示拼接操作。
其次对于提出的捷径图,设计一种类似GAT的邻居聚合策略。针对GNN无法堆叠多层的性质,采用捷径图使得模型可以更好的捕捉长期依赖关系,具体地说,SGAT层利用以下注意机制沿捷径图的边缘传播信息。
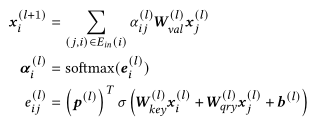
为了建立一个不存在信息丢失问题的GNN模型,堆叠了多个EOPA和SGAT层并将EOPA层与SGAT层交叉放置,原因有以下两点:
1.捷径图是原始会话的有损转换,因此连续地叠加多个SGAT层会引入有损会话编码问题。通过交错EOPA层和SGAT层,丢失的信息可以被保留在后续的EOPA层中。
2.这种方式每一种层都能有效地利用另一种层捕获的特征。EOPA层更能捕获局部上下文信息,SGAT层更能捕获全局依赖关系,因此两层的交错可以有效地结合两者的优点,提高模型学习更复杂依赖关系的能力。
基于GNN的会话推荐问题可以看做图分类问题,通过将学习到的节点表示采用readout函数进行聚合,最终学习到整个会话的表示。整个会话的表示被定义为 :
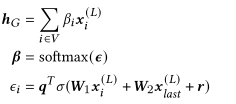
同时研究表明,会话中最后一个项目包含了用户的短期偏好,所以将h_G与模型最后一层的最后一个项目的表示拼接在一起作为最终会话的嵌入:
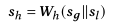
在获得会话嵌入后,我们可以使用它通过计算下个项目的概率分布来做出推荐。对I中的每个项目i,首先根据会话嵌入与项目嵌入计算一个分数:
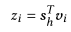
然后预测下一个项目是项目i的概率,损失函数的选择为交叉熵。
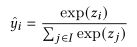
3 实验
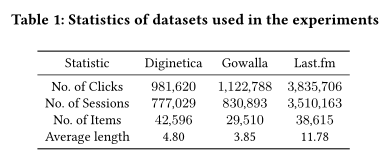
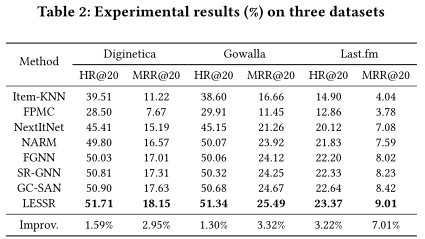
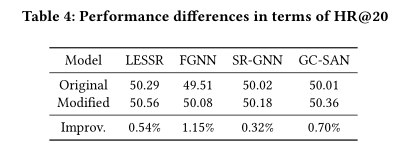
作者在以下三个公共的真实世界数据集上进行了实验,这些数据集在基于会话推荐的文献中是常用的。其对比的baseline中包含传统的Item-KNN和FPMC方法;基于CNN的NextItNet方法;基于RNN的NARM方法以及基于GNN的SR-GNN、FGNN方法。在三个数据集中,提出的LESSR方法都有显著提升。
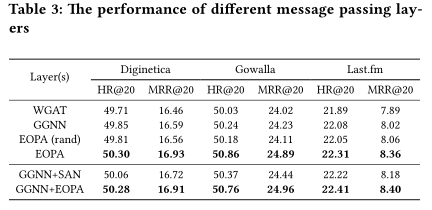
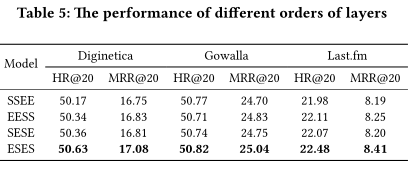
同时本文做了消融实验,证明EOPA层以及SGAT层的有效性。同时对两种层级的不同堆叠方式都进行实验比对,证明交叉堆叠是最优的堆叠方式。
4 总结
本文总结了应用于会话推荐的现有GNN模型中存在的两个信息丢失问题,即有损会话编码和无效的长期依赖捕捉问题。为了解决这两个问题,作者提出了EOPA和SGAT层,它们依赖于将会话转换为图的两种转换方式,包括S2MG和S2SG。通过结合这两种层,我们建立了一个称为LESSR的模型,该模型不存在两种信息丢失的问题,实验结果表明,在三个公共数据集上,LESSR的性能优于最先进的方法。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




