【RecSys2017】基于“翻译”的推荐系统方案,加州大学圣地亚哥分校最新工作(附代码)
【导读】传统的推荐系统方法(如矩阵分解)习惯把用户和项目拆成两个二元组(user-item、item-item)来建模,但是这种建模方法通常忽略了两组之间的相关性。本文通过在一个转换空间中对用户和项目联合组成的三元组进行序列建模,拥有良好的泛化性能和处理大规模数据的能力。
【论文】Translation-based Recommendation

▌摘要
对用户和项目(item)之间以及项目之间复杂的交互进行建模是设计推荐系统的核心。一种经典的选择是预测用户的个性化顺序行为(或“下一项”推荐(next-item recommendation)),其中的挑战主要在于建模一个用户、她/他以前访问过的商品和下一个消费项目之间的“三阶(third-order)”交互。现有的方法通常将这些高阶交互分解为成对(pairwise)关系的组合,通过这种方式,用户喜好(用户-项交互)和顺序模式(项-项交互)被单独模型建模。在本文中,作者提出了一种统一的模型TransRec来建模大规模序列预测的这种三阶关系。在方法上,作者将项目嵌入到一个“转换空间(translation space)”中,其中用户被建模为对项序列进行操作的翻译向量(translation vectors)。从经验上看,这种方法在广泛的真实世界数据集上的表现超过了目前最好的模型表现.
▌简介
建模和预测用户和项目之间的交互,以及项目本身之间的关系是推荐系统的主要任务。例如,为了预测用户的后续行动,如下一个购买的产品、观看的电影或参观的地点,建模用户(u)、她最近消费的项目(i)和下一个要访问的项目(j)之间的三级交互是非常必要的(并且具有挑战性!)。模型不仅需要处理交互本身的复杂性,还需要处理真实世界数据的规模和固有的稀疏性。
传统的推荐方法通常擅长建模双向(即成对)的交互作用,其中矩阵分解(MF)技术利用内积对用户-项目对(即用户偏好)之间的交互进行建模。同样,也有一阶马尔可夫链(MC)模型,它通过分解转移矩阵来捕获序列中相邻项对之间的转换关系,从而有利于泛化。对于序列推荐任务,研究者们使用了可扩展的张量分解方法,如Rendle等人提出的分解个性化马尔可夫链(FPMC)。
近年来,已有两条改进FPMC的工作路线,个性化度量嵌入方法用欧氏距离代替FPMC中的内积,其中的十进制假设--尤其是三角不等式--使得模型可以更好地泛化,但是这些工作仍然采用用户偏好分量和序列连续分量建模的框架,这可能是不利的,因为这两个组成部分是内在相关的。另一项工作利用诸如平均/最大池之类的操作来聚合用户u和前一项i的表示,然后再测量它们与下一项j的交互性。虽然这两个关键部分的相关性难以解释,也不能从度量嵌入的泛化能力中受益,但这中方法部分地解决了两个部分相关性的建模问题。
本文旨在通过引入一种新的基于翻译的推荐框架来解决上述问题。图1给出了TransRec背后的关键思想:项目作为点嵌入在(潜在的)“转换空间”中;每个用户在同一个空间中被表示为“翻译向量”。 上面提到的三阶交互作用是通过个性化的翻译操作来捕获的:前一项的坐标,加上u的翻译向量(大约)确定下一项j的坐标: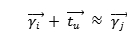
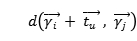
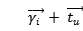
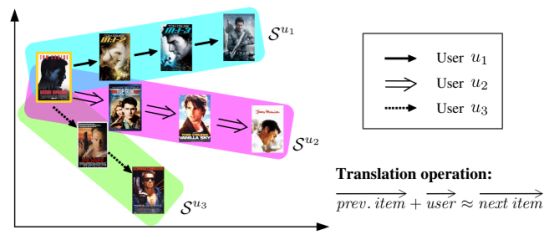
注:图1中RansRec作为一个顺序模型:项目(电影)被嵌入到一个“转换空间”中,其中每个用户都被一个翻译向量建模。这里作者演示了三个用户的历史序列: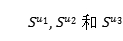
▌贡献
(1)TransRec自然地模拟了只包含一个成分(component)的三阶相互作用;
(2)TransRec还享有隐式度量假设的推广优势;
(3)TransRec由于其简单的形式,可以很容易地处理大序列(例如数百万个实例)。
▌方法
问题定义
给定用户 u的序列
表1. 数学符号表示
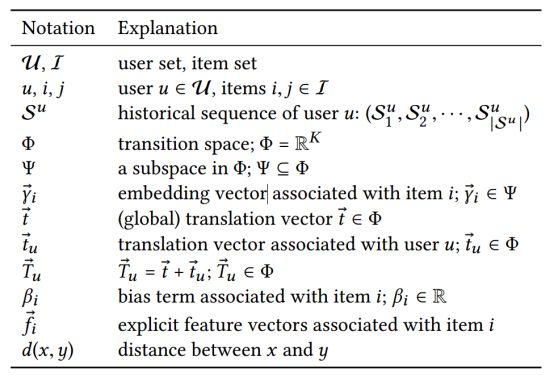
模型介绍
本文提出的模型旨在(1)捕捉个性化的序列行为,(2)很容易扩展到大型的真实世界数据集。作者学习了一个转换空间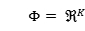
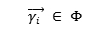
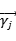

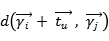
由于真实世界数据集的稀疏性,为每个用户学习单独的翻译向量可能并不是一种可供选择的方法,因此我作者增加了另一个翻译向量 来捕获所有用户的“全局”转换动态,;令:
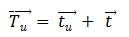
这样做的好处是当一个用户为冷启动用户时,他的个性化向量 会被置于0,这时就可以利用全局向量作为平均行为来给用户做推荐,一次解决推荐系统的冷启动问题。
最后,给定用户u从前一项i过渡到下一项j的概率可以表示为:
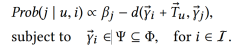
在上面的方程中,添加了一个偏置项来捕捉项目的总体受欢迎程度。
给定一个用户和相关的历史序列,推荐任务的目标是将ground-truth项目j的排序高于所有其他项目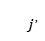
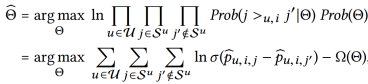
▌实验
数据集
为了全面评估TransRec的能力和适用性,作者在实验中包括了一系列可公开获取的数据集,这些数据集在域、大小、数据稀疏性和可变性/复杂性上都有很大的差异。
1. Amazon:http://jmcauley.ucsd.edu/data/amazon/
2. Epinions:http://jmcauley.ucsd.edu/data/epinions/
3. Foursquare:https://archive.org/details/201309_foursquare_dataset_umn
4. Flixter:http://www.cs.ubc.ca/∼jamalim/datasets/
5. Google Local
表2. 数据集统计统(按项目密度的上升顺序排列)
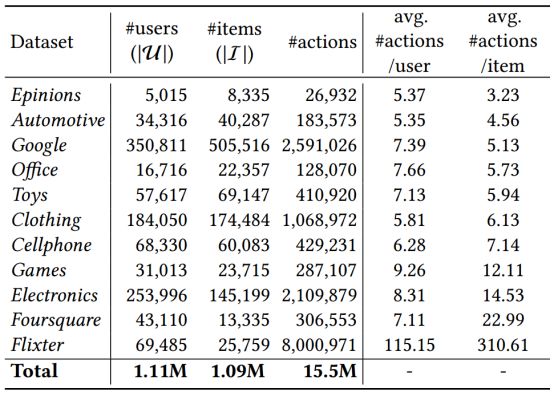
对于上述每个数据集,作者丢弃系统中关联操作少于5个的用户和项。在有星级评级的情况下,作者将所有这些都视为用户的积极反馈,因为本文处理的是隐含反馈,关注的是购买/签到行为(等等),而不是特定的评级。
Baseline方法
1. Poprec:是一种不符合标准的baseline,它根据项目的受欢迎程度对其进行排序,即推荐给用户最受欢迎的项目,并不是个性化的。
2. 贝叶斯个性化排序(BPR-MF):BPR-MF是一种以矩阵因式分解为底层预测的最先进的项目推荐模型,它忽略了系统中的序列信号。
3. 分解马尔可夫链(FMC):通过分解项-项的转移矩阵(由所有用户共享)来捕获“全局”顺序动态,但不捕获个性化行为。
4. 分解个性化马尔可夫链(FPMC):使用一个将矩阵因式分解和分解马尔可夫链相结合的预测器,以便能够捕获个性化马尔可夫行为。
5. 个性化排序度量嵌入(PRME):PRME通过两个欧氏距离之和建立个性化马尔可夫行为模型。
6. 层次表示模型(HRM):HRM通过使用聚合操作(如max-pooling)来对FPMC进行扩展,以建立更复杂的交互模型。作者比较了HRM的最大池化和平均池化两种方法。
7. 基于翻译的推荐(TransRec):本文的方法,它统一了用户偏好和序列动态。
评价指标
1. ROC曲线下面积(AUC):
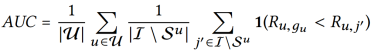
2. 点击率(Hit@50)
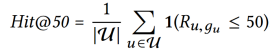
性能分析
本文模型与各baseline方法的结果比较如表3所示。
注:所有比较方法的维数k均设为10。最后一栏显示了TransRec在最佳baseline上的改善百分比。
图2和图3显示了所有方法的收敛性及对用户/项目向量表示维度K的敏感度。
表3. 表中所示为不同数据集上的结果(越高表示越好)


▌总结
作者提出了一个基于翻译(translation-based)的可扩展的方法TransRec,在推荐系统中对二元实体之间的语义复杂关系进行建模。作者分析了TransRec与现有的方法的联系,证明了它适合于建模用户之间的三阶交互。除了在大范围的、真实的数据集上顺序预测任务上取得了优异的结果之外,作者还研究了TransRec在处理逐项推荐方面的能力。这两项任务的成功表明,基于翻译的体系结构对于通用的推荐问题是有效果的。此外,作者还介绍了一个大型数据集Google Local,其中包含了世界各地数以百万计的本地企业(如餐馆、商场、商店)的详细信息,以及来自数百万用户的评级和评论。
论文链接: https://arxiv.org/pdf/1707.02410.pdf
代码、数据链接:https://sites.google.com/a/eng.ucsd.edu/ruining-he/
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

点击“阅读原文”,使用专知



