KDD 2020 | 融合多视图行为信息的多任务查询补全推荐方法

作者 | 殷 迪

背景
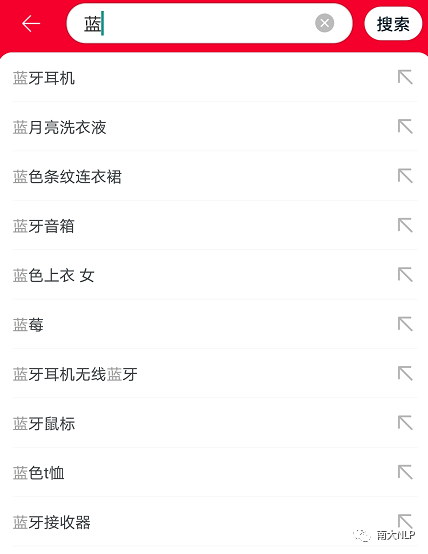
查询自动补全(Query Auto-Completion, 简称QAC)是现代搜索引擎的一个重要功能模块。如下图所示,该模块的主要功能为:在用户向搜索框输入查询的过程中,根据当前查询前缀(如“蓝”)推荐一些个性化的查询补全建议(如“蓝牙耳机”等)供选择,从而提高用户的搜索效率。
QAC模块的性能要求主要包括两个方面:
准确性:能够准确地预测用户的意图,从而使推荐结果列表有较高的个性化程度。例如,当用户当前输入为“蓝”时,搜索意图有多种可能性,包括“蓝牙耳机”、“蓝月亮洗衣液”、“蓝色条纹连衣裙”等,QAC模块需要根据前缀和一些个性化特征预测用户的完整意图,并将对应的补全查询排到列表靠前的位置。
实时性:大部分搜索引擎要求QAC模块能在用户输入过程中实时给出推荐列表,因此会要求该功能的响应时间尽可能短(如不超过300ms)。
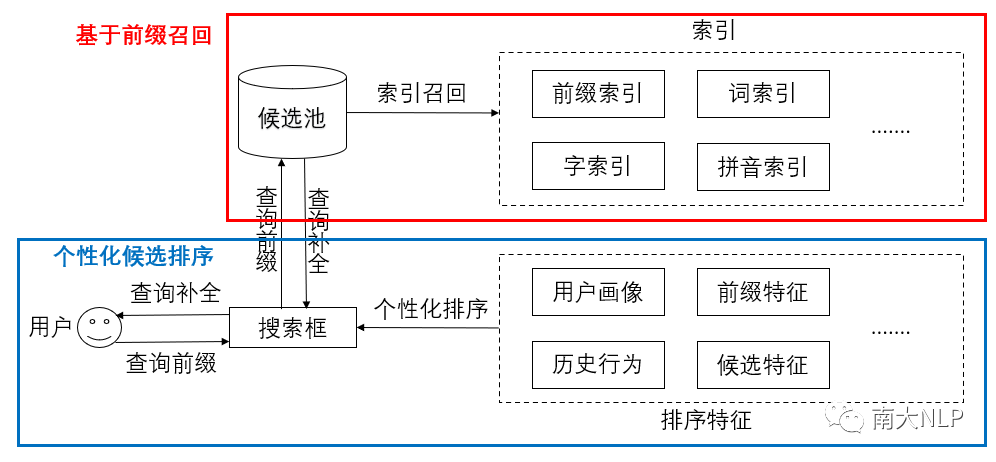
与大部分搜索或推荐任务类似,QAC一般采用“先召回后排序”的两阶段过程:首先,从历史搜索记录中挖掘出一个查询候选池,并从前缀、分词、单字、拼音等多个维度建立查询索引;在召回阶段,根据用户当前输入的查询前缀,使用索引进行多路召回,合并后得到一个初步的候选集;在排序阶段,使用一个基于Learning to rank的个性化排序模型对候选集进行打分排序,并最终选取排名最高的N个查询按顺序展现给用户。
痛点问题
随着搜索与推荐技术的发展,QAC经历了多次更新换代。然而,当前的大部分系统仍然存在以下两个痛点问题,严重影响着该模块的性能与用户体验。
长尾输入少、无结果:在历史搜索日志中,查询的搜索次数服从“长尾分布”,即绝大部分查询搜索次数较少。在实现一个QAC系统时,出于对存储开销和计算性能的考虑,很多长尾查询不会被加入到候选池或索引中,导致对应的长尾输入少、无结果。一些历史日志中从未出现的新查询也会遇到相同的问题。
排序个性化程度低:当前大部分系统对用户搜索意图的预测准确度较低,更倾向于推荐一些高频的“头部”查询,导致不同用户在输入相同前缀时展示列表大同小异。
解决方案
针对上述问题,我们提出了一种融合多视图用户行为信息的多任务查询补全推荐方法,基本的解决思路包括两点:
在召回阶段,用参数化的神经网络序列生成模型根据前缀采用多样化beam search的解码策略自动“生成”一些查询补全,作为现有召回方式的补充,从而解决长尾输入少、无推荐结果的问题。
在排序阶段,引入用户历史搜索查询与浏览内容等多种视图的行为序列信息作为模型决策依据,从而更准确地预测用户的搜索意图,提升结果列表的排序个性化程度。
为了使生成模型和排序模型都能取得较高的预测准确率,设计模型时需要考虑的一个关键问题是:如何更好地建模和利用多视图的用户历史行为序列。
在搜索引擎中,用户行为常常是指搜索某个查询或浏览某个内容。为了获取更全面的历史行为信息,我们引入了搜索查询和浏览内容两个视图的用户行为序列。这些用户行为序列具备如下三个特点:
查询或内容与用户的交互频次呈长尾分布:这意味着,大部分推荐方法仅依赖交互学习行为整体embedding的方式并不能使模型学得比较好的长尾行为表示。
用户行为背后的意图存在歧义性:以查询“南京大学”为例,不同用户存在不同的搜索意图,可能是想搜南京大学的周边纪念品,也可能是想搜南京大学编写的书籍资料。因此,仅根据行为本身是难以准确理解背后意图的,结合上下文去理解会是更好的选择。
不同行为之间存在依赖关系:搜索日志中的大部分行为不是独立存在的,如用户的查询很可能一次性输不满意,会涉及到多次的修改,修改前后的查询之间显然会存在依赖关系。如何建模和刻画这些行为间的依赖关系也是一个值得考虑的问题。
针对上述特点,我们将基于Self-Attention机制的Transformer模型引入到多视图用户行为序列的建模中,提出了一种新型的层次化行为序列编码模型:如下图左边方框内容所示,该编码模型包括行为(behavior)和上下文(context)两个层次的Transformer编码器模型。
针对每个行为的建模,大部分推荐系统的常见做法是完全依赖交互学习表示,忽略了行为本身的内容信息,使得长尾行为的表示效果较差。我们则提出用Transformer模型编码每个行为中字、词级别的内容信息,这样可以有效地提升长尾行为的表示效果,对从未见过的新行为也有着非常好的泛化效果。
在此基础上,我们引入了一种多头池化(Multi-head Pooling)机制用于获取每个行为的高层表示,并将对应的行为级别表示输入到一个上下文层次的Transformer模型中进行编码,通过Transformer本身的Self-Attention机制融合上下文信息实现行为语义的准确理解,同时也可以显式刻画不同行为之间的依赖关系。
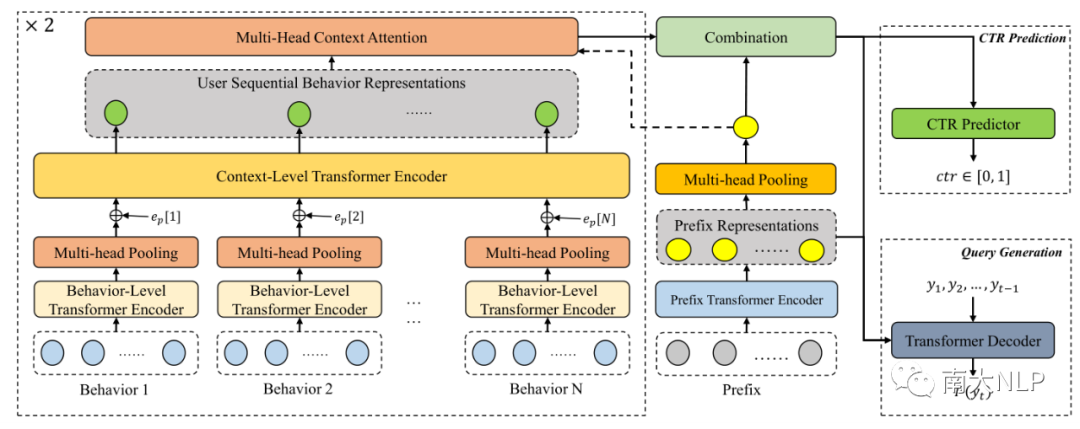
通过层次化的Transformer编码,我们可以获取更准确、更富信息量的行为序列表示。然而,并不是所有的历史行为都与用户当前的搜索意图有着强相关性。为了减少预测阶段的信息冗余,我们引入了一个多头注意力模块,以用户已输入前缀的表示作为查询,对历史行为序列中的信息进行筛选,将一些相关性强的信息表示进行加权合并后与前缀表示整合到一起,作为后续模型预测的依据。
在获取预测依据后,我们便要考虑用什么方式来预测用户的完整查询。当前查询补全推荐有两种主要解决方案:一种是将QAC模块看作一个小的搜索引擎,采用“检索排序”的方式进行结果推荐;另一种是将QAC看作一个文本生成任务,使用神经网络模型自动生成完整的查询。二者的相同点在于都需要依赖用户历史行为序列进行决策,而不同点主要体现在训练目标函数与使用的训练数据形式上:
排序往往被看作一个点击率(CTR)预估的任务,使用pointwise的目标函数进行CTR模型的训练(如Lc);而生成模型的训练则需要引导模型能准确生成每个词,有着更细粒度的训练目标函数(如Lg)。
在训练数据上,排序模型仅能使用带有用户点击行为的日志数据进行训练,而生成模型可以利用一些用户主动输入的完整查询,通过随机切分的方式构造训练数据。
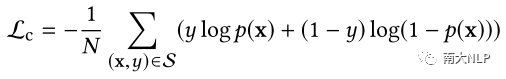
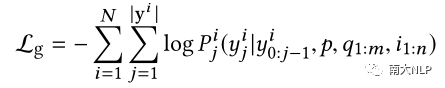
因此,我们提出通过共享层次化编码模型的方式对排序和生成进行多任务学习,使编码模型通过多目标优化与利用更多的数据进行训练来获取更好的编码表示效果。
实验分析
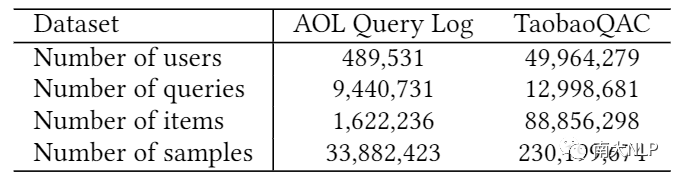
为了验证提出方案的效果,本工作构造了一个大规模查询日志数据集——TaobaoQAC,该数据集包含了20190901-20190910范围内的2亿余条手机淘宝搜索引擎查询日志。与已有AOL日志数据集不同的是,除用户主动输入的完整查询外,TaobaoQAC还包含了从输入前缀到推荐补全的用户点击行为。这使得TaobaoQAC相比AOL数据集更适合QAC问题的研究,具体的对比信息如下表所示。
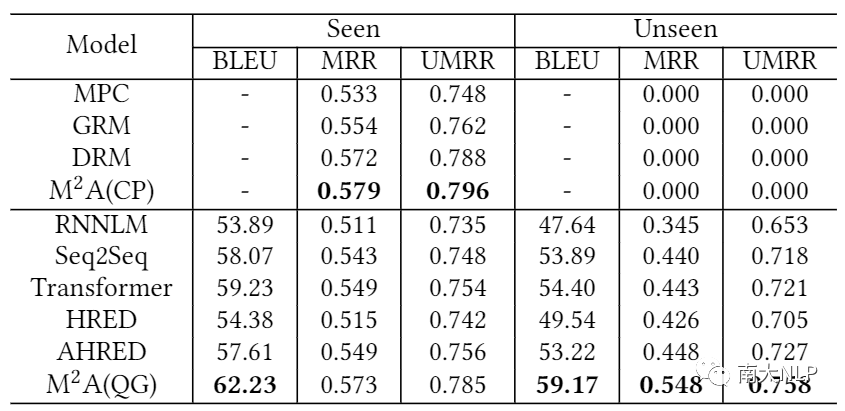
我们选取前7天日志数据作为训练集、第8天作为验证集、最后2天作为测试集进行模型的训练与评价。评价分为Seen和Unseen两个场景:Seen场景用于评价模型在有推荐候选的测试数据上的性能,Unseen场景用于评价模型在无推荐候选的测试数据上的性能。关于评价指标,我们采用机器翻译领域常用的BLEU指标评价生成模型预测结果与用户点击或输入的完整查询的相似程度,采用MRR与去除position bias的MRR(Unbiased MRR,简称UMRR)来评价不同模型的排序性能。需要说明的是,生成模型的解码器部分可以通过将每一步解码的概率连乘获取一个整体分数,从而转化为一个排序模型。
基线系统包括基于统计的MPC、基于GBDT的排序模型GRM、基于深度神经网络的排序模型DRM以及RNNLM、Seq2Seq、Transformer、HRED、AHRED等几个生成模型。从实验结果表可以看出,M2A框架的排序模块(CP)与生成模块(QG)分别取得了最好的生成性能与排序性能。在Unseen场景下,几个排序模型均不能给出推荐结果,导致相关指标为0,我们的QG模型则在所有生成模型中取得了最好的效果。
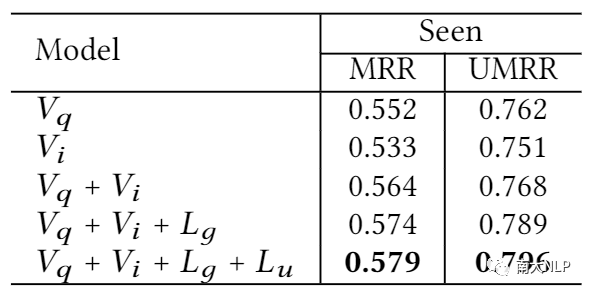
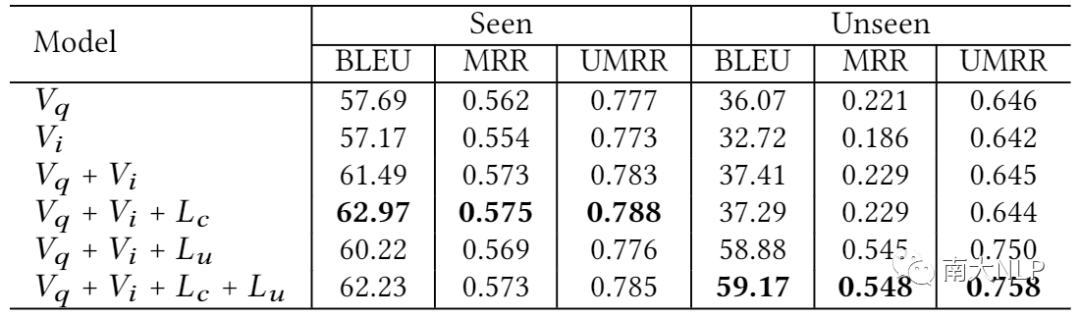
由于本文提出的框架包括多个不同的视图或任务,我们也开展了一个消融实验,在下面两个表格中,Vq代表查询视图,Vi代表浏览视图,Lg代表使用点击数据训练生成模型,Lu代表使用主动输入数据训练生成模型。我们从单视图的点击率预估模型出发,逐步添加响应的模块。
下表为点击率预估模型的消融实验结果,可以看出每个视图或者任务都能给其带来明显的增益。
下表为生成模型的消融实验结果,可以看出,引入主动输入的查询日志作为训练数据,虽然会给模型在Seen场景下的性能带来一些损失,但却能给Unseen场景上的性能带来大幅度提升,取得了一个较好的整体增益。
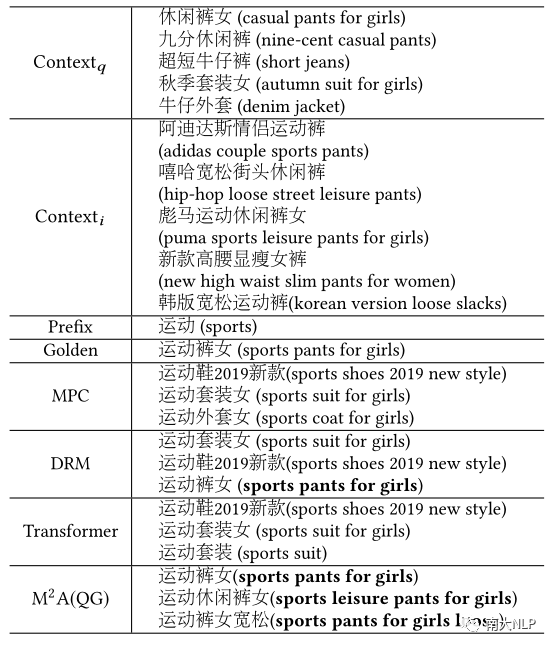
我们也观察了一些推荐案例,发现大部分基于排序或生成的方法都倾向于将一些高频查询排在推荐列表的靠前位置。而这些高频查询常常与用户当前的搜索意图无关,导致排序结果个性化不足。我们提出的方案则能较好地缓解这一问题,排序靠前的查询候选大部分都是与用户当前的搜索意图相关的。
为了验证提出方案是否能给线上服务带来增益,我们尝试在淘宝主搜索引擎场景下进行了A/B测试。由于生成模型beam search生成多个候选的策略会导致响应时间较慢,我们选择提前挖掘好之前一周少、无结果的长尾输入,进行离线的候选生成,并建立相关的索引。在线上场景,我们使用离线生成的候选与在此基础上进行扩召回得到的查询与已有候选查询共同组成完整的候选集,再用框架中的点击率预估模型进行候选排序。

上述做法的好处是,一方面能保证线上响应时间满足要求,另一方面可以综合利用生成模型的自动生成能力与CTR模型的个性化排序能力,从而取得更好的整体性能。通过近两个月的A/B测试,我们的方案给手机淘宝查询补全推荐业务带来了3.84%的PV提升、1.6%的UV提升、4.12%的点击量提升,同时使服务有响应率提升了11.06%,取得了不错的业务增益。
总结
本工作提出了一种融合多视图用户行为序列信息的多任务个性化查询补全推荐框架:通过同时建模和利用多视图用户行为序列中丰富的个性化信息,使QAC模型能够更准确地预测用户当前的搜索意图;通过候选排序与查询生成的多任务学习,同时利用多种学习目标与训练数据进行模型训练,实现了不同任务间的优势互补。整体框架在离线和在线的实验中均取得了不错的效果,为淘宝搜索引擎的查询补全推荐业务带来了显著的增益。同时,我们计划将TaobaoQAC数据集开源,方便研究与开发人员对个性化查询补全推荐问题进行更加深入的探索,数据集相关信息详见:
https://github.com/yd1996/KDD2020_TaobaoQAC
在未来的工作中,我们将考虑建模更长的用户行为序列,以提升模型预测准确率;同时也会考虑开发出更快的查询生成模型或方法,以实现在线实时生成候选查询。

阅读原文,直达“ KDD”小组,了解更多会议信息!



