AAAI 2019 提前看:融合质量不理想数据
机器之心原创
作者:Yuanyuan Li
编辑:Haojin Yang
1. 介绍
选文理由:从 AAAI 发布的 paper list 整体来看,令人喜悦的是靠近底层的问题研究和靠近工业界的产品研究都很多。前者保证了科研界的活跃度和今后行业发展的基础,后者则保证了短期内一些研究落地的可能性。不过,很多项目仍然有研究空间,离落地-或者说成熟期-有一定距离。比如人脸识别的项目已经发展了很多年,应用该技术的产品也很多,但今年接收的论文仍然出现不少在人脸识别方向对算法的改进和扩展的文章。说明 AI 整个行业虽然收到了公众很大的关注,也在过去几年中取得了长足的进展,从产品角度来看仍然有很长的路要走、可以走。
这篇文章笔者想讨论的研究主要跟数据质量相关。此前腾讯 AI Lab 主任张潼返回学术界的消息引起了对于学界和业界之间的鸿沟的思考。的确,学界和业界建立、解决问题和衡量解决方案的标准是完全不同的。在学术研究中,很多时候我们可以使用网上的开源数据进行模型训练,所需要考虑的主要是模型架构等问题。而在产品开发中,一个项目的第一步往往是收集足够、合适的数据。由于时间、成本和项目高度定制化等原因,数据收集往往是最困难的。比较常见的情况是数据获取之后,我们仍然发现其中有相当一部分质量不理想,如图像的分辨率太低、标签错误或不清楚如何给标签等。更糟的情况下我们甚至不确定该如何对数据的质量进行评估。而模型的训练及后续工作必须在此基础上开展。AAAI 给出的 paper list 中有一些针对不理想数据所开展的研究,笔者从其中选取了已经在网上公布的论文进行本次讨论。
2. 论文讨论
1. Fully Convolutional Network with Multi-Step Reinforcement Learning for Image Processing
链接:https://arxiv.org/abs/1811.04323
作者个人主页:https://www.hal.t.u-tokyo.ac.jp/~furuta/
本文一作 Ryosuke Furuta 是东京大学的一名博士生,主要研究方向是计算机视觉,图像识别,MRF 优化。
由于神经网络在计算机视觉任务上的出色表现,许多图像处理工作也开始试图使用神经网络,如图像降噪、图像增强。这即是本文试图解决的问题,比较特别的是,不同于常见的使用卷积神经网络或 GAN 的方法,作者试图通过建立像素奖励(pixelRL)来进行图像处理的强化学习。
文章以大名鼎鼎的 Asynchronous Advantage Actor-Critic (A3C) algorithm 算法为基础,A3C 算法的一个核心设计是使用 parallel agents,自然的,在本文的情境下可以为每个像素都分配一个 agent,agent 可以执行操作来更改像素值。因此,令 I_i 作为有 N 个 pixel 的图像中的第 i 个像素,其对应的 agent 的 policy 就可以写作$\pi_i(a_i^{(t)}|s_i^{(t)})$,其中$a_i^{(t)}$和$s_i^{(t)}$分别对应第 i 个 agent 在时间 t 的 action 和 state。在时间 t,agents 可以通过在整张图片上执行 action 合集 $a^{(t)} = ( a_1^{(t)}, a_2^{(t)}, ..., a_N^{(t)})$来更新 state $s^{(t+1)} = (s_1^{(t+1)}, s_2^{(t+1)}, ..., s_N^{(t+1)}) 和获取奖励 $r^{(t)} = ( r_1^{(t)}, r_2^{(t)}, ..., r_N^{(t)})$。agent 可以执行的 action 的集合 A 需要提前给定,而状态$s_i^{(0)}$则可以轻松地设定为 I_i,即我们以原图初始化模型。
pixelRL 的目标是习得最优策略(policy)$\pi = (\pi_1, ..., \pi_N)$以使得像素的总预期奖励最大化:
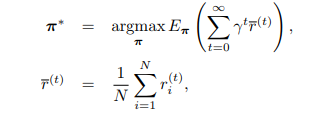
其中$\overline{r}^{(t)}$是在时间 t 所有 pixel 所获得奖励的均值。
pixelRL 的算法很容易理解,但这样设计带来的难点主要是计算量,由于算法的 agents 数量等同于图像的像素数量,而目前一张照片的分辨率至少也在 224*224*3 以上。也就是说 agents 的数量是在十万级以上的,单独训练每一个 agent 将会造成计算困难。另外,这样操作模型将只能在固定大小的图像上进行操作。为了应对这个问题,作者使用 FCN,通过参数共享来提高计算效率和保证图片大小的灵活性。
同时,作者还提出了一种叫做 RMC(reward map convolution)的学习方法来利用卷积的特性提升 PixelRL 的表现。从直观上理解,卷积操作是对某一像素点和其邻域的加权,即任何一个决策不仅仅需要考虑该像素本身的值,同时还需要考虑感受野内的像素点的值,这些像素点的重要性则由权重给定。因此,在 one-step learning 的简单情况下,价值网络(value network)的 gradient 可以计算为:
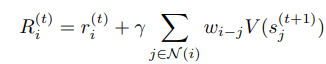
其中$w_{i-j}$是权重,代表了相邻像素在下一时间 t+1 的价值 V 对该像素的重要性。这可以自然地被视为卷积核的权重并且可以在训练过程中与价值网络和 policy 网络的参数一起更新。对于 2D 图像,仅仅需要将权重 w 设为 2D 的。这一思想也能够很容易的扩展到 n-step learning。
值得一提的是,当 FCN 卷积核的感受野被设为 1x1 时,像素的 agents 之间是互相独立的,即 agent 的参数更新仅与该 pixel 有关,和 A3C 的算法是等价的。也就是说,A3C 可以看作是本文提出的 pixelRL 在卷积核的感受野为 1x1 时的特殊情况。
作者分别在图像降噪、图像重建和色彩增强三个方面给出了实验结果。由于 agent 所能执行的 action 需要提前限定,在每一个例子中,作者都给出了 action list 以及相应的 reward function。不过由于一些任务所能够执行的 action 是相同的,在图像降噪和图像重建中作者都使用了以下 action list:
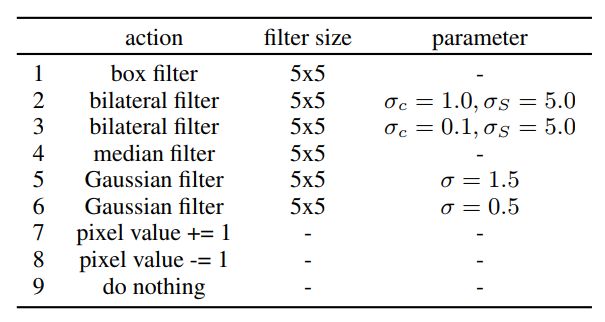
图 1:图像降噪和图像重建中所使用的 action list [图片来源:Furuta,R. et al. (2018). Fully Convolutional Network with Multi-Step Reinforcement Learning for Image Processing. AAAI.]
从作者给出的结果来看(图二第二行),降噪(salt and pepper noise)效果是非常优秀的,训练开始后很快就可以清晰辨认出图像内容。笔者认为 PixelRL 最大的优势在于其执行的操作是可理解的。相比起来,在 CNN 的端到端训练中我们仅能看到输入图像和输出结果,无法得知模型对图像都进行了什么操作。而在 PixelRL 中,由于每个像素都有一个 agent 从 action list 中选择 action 执行,模型可以被很好的可视化。图二第一行给出了在每一个时间时每个 agent 所执行的操作。可以很清楚地看到在图像的人形雕塑内的像素先整体都执行了 gaussian filer 和 median filter,随后对每个像素点进行微调。在人形雕塑外的像素则是先整体执行了 box filter 随后进行微调。即模型是先用比较强的 filter 移除噪声,在此基础上对结果进行改进(像素值+-1)。这样的逻辑对于人类也是合理的。

图 2:PixelRL 图像降噪结果 [图片来源:Furuta,R. et al. (2018). Fully Convolutional Network with Multi-Step Reinforcement Learning for Image Processing. AAAI.]
图 3 给出了 PixelRL 在这一数据集上,以 PSNR [dB] 为标准,和全监督方法比较的结果。作者给出了仅使用 FCN 训练 agents、使用 convGRU、使用所提出的 RMC 方法以及在数据集上进行 augmentation 的结果。可以看到使用 RMC 等方法的确能够提升模型表现,但仅凭这一数据,我们无法判断这种进步是否是显著地。
当噪声密度为 0.5 和 0.9 时,PixelRL 的表现优于 CNN,可能是因为高密度噪声造成原始像素信息丢失,从而难以用 CNN 回归噪声,因为原始像素值的信息丢失。而 PixelRL 在这种情况下在迭代操作中根据相邻像素预测像素的真实值。但值得一提的是当噪声密度比较低,CNN 方法仍然表现最优。从作者给出的在高斯噪声降噪结果上看,这一结论仍然成立(CNN 的表现优于 PixelRL)。
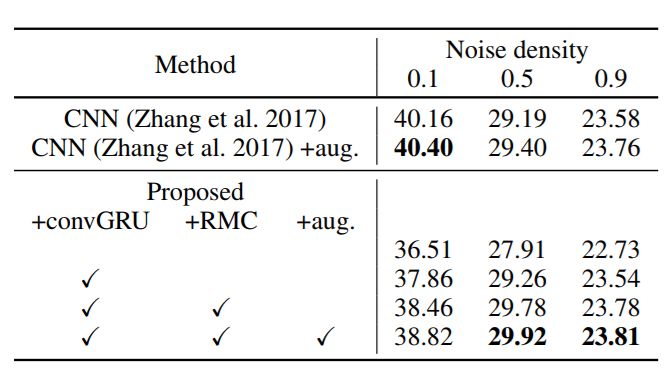
图 3:不同全监督方法在图像降噪结果上的对比,标准:PSNR [dB],噪声:salt and pepper noise [图片来源:Furuta,R. et al. (2018). Fully Convolutional Network with Multi-Step Reinforcement Learning for Image Processing. AAAI.]
图像重建中,作者使用对图像上随机覆盖一段文字的方法扰乱图像内容。从结果来看重建效果仍然是很优秀的,并且所执行的操作也被可视化。笔者觉得比较可惜的一点是文字覆盖在一片固定区域内影响的像素值是比较少的,如果作者能够给出对图像有严重缺失——比如右上角被油墨覆盖导致一片区域完全不可辨认——的重建结果就好了。

图 4:PixelRL 图像重建结果 [图片来源:Furuta,R. et al. (2018). Fully Convolutional Network with Multi-Step Reinforcement Learning for Image Processing. AAAI.]
总体来看,文章的亮点在于对 A3C 算法进行了拓展,使其能够对每个像素进行精确的修改,这使我们能够得到在细节上更准确的结果,如边缘更清晰、背景噪声更少等。同时,卷积的使用兼顾了计算效率和图像的二维属性,PixelRL 能够考虑相邻像素的信息并且其权重可以实时更新。模型所执行的操作的可视化和可理解性十分吸引人。缺点在于由于 action list 需要提前确定,并且不同的任务中往往不能通用,需要具体问题具体分析并对奖励函数做相应的修改,有损模型的通用性。与现有的全监督方法相比,模型似乎在图像内容扭曲比较严重的情况下优势更明显;当图像内容保存的比较好时,模型仅取得了接近当前最优的表现。另外,从所给出的结果来看,我们无从得知 PixelRL 相对于其他方法的计算效率究竟如何,也无法判断使用 RMC 等方法给模型表现带来的提升是否是显著地。笔者对 PixelRL 在现实应用上的意义持保留态度。
2. On the Persistence of Clustering Solutions and True Number of Clusters in a Dataset
链接:https://arxiv.org/abs/1811.00102
作者个人主页:https://www.linkedin.com/in/amber-srivastava-41906739
本文一作 Amber Srivastava 现在是伊利诺伊大学厄巴纳香槟分校机械工程系博士生,他的主要研究方向是优化理论,聚类算法,计算机辅助设计,控制系统等。
聚类算法是在各个领域都被广泛运用的一种算法,特别是学习过统计的同学对此一定非常熟悉,通常,在聚类算法中需要给定聚类数量,即聚类数量是一个超参数。而由于在实际运用中这个值通常是不确定的,往往需要对不同聚类数量的拟合结果进行比较来确定最佳聚类数量,常用的标准有 BIC、AIC,X 均值等。本文作者提出了 persistence 的概念,作为衡量聚类结果的一个新的标准。
从作者的描述看来,这一概念的提出与分辨率的概念有直接关系。因为类(cluster)的概念可以与查看数据集的分辨率比例相关联。例如,两个极端情况下,整个数据集可以被视为一个类,每个数据点自身也可以被视为一个类。这里作者给出了一个例子,图 5 中的数据是由 9 个高斯分布生成的,分布在三个超级集群(super cluster)内。如果我们选择的分辨率非常低,如图 5(a1),整个数据集中的任意两个点不可区分,那么整个数据集将被视为单个类。如果我们选择半径 r_1 的分辨率比例,如图 5(a2)所示,那么每个超级集群内的点是无法区分的,但三个超级集群之间彼此可分。即在此分辨率级别,数据集仅包含三个聚类。再进一步提高图 5(a2)中的分辨率范围后,九个高斯分布的数据点变得彼此不同,并且我们能够识别数据集中的九个聚类。
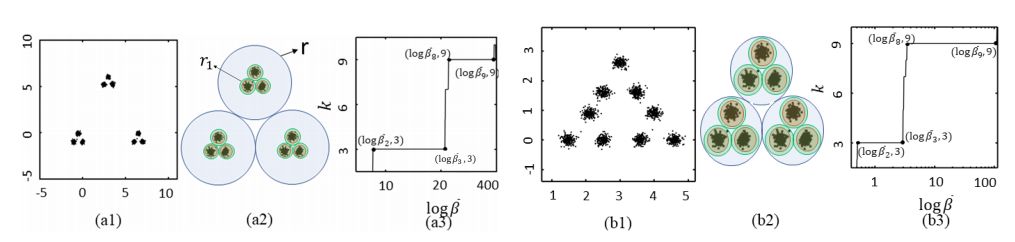
图 5:对聚类与分辨率之间关系的例证 [图片来源:Srivastava, A. et al. (2018). On the Persistence of Clustering Solutions and True Number of Clusters in a Dataset. AAAI.]
很显然,随着分辨率的变化,聚类结果也在改变。有一些聚类结果在不同的分辨率下都是最优的,有一些则不是。如在图 5(a1)中,三个超级聚类对于在很广范围的分辨率下都是持久,如每个周围的蓝色环的厚度所示。另一方面,九个高斯分布周围的绿色环相对较薄,表明识别所有九个高斯簇的聚类解决方案相对较不持久。
作者认为在大范围分辨率下都存在的聚类结果是数据真实聚类数量的一种体现,从这里出发,设计了名为 persistence 的标准使得其能衡量聚类结果相对与分辨率的稳健性。
给定数据集$X = { x_i : x_i \in R^d, 1<= i <= N}$,试图将其 N 个数据点聚类到 k 个类中。这一问题可以被视作一个 facility location problem(FTP),即试图放置 facility $Y = { y_j : y_j \in R^d, 1<= j <= k}$使得数据点与其最近 facility 之间的累积距离最小——这一思想在经典的 k-means 算法中也出现过。在 FLP 问题中,聚类问题编程求解以下优化问题:
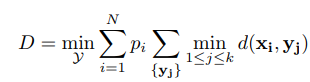
其中$p_i$是已知的$x_i$的权重,常取 1/N,$d(x_i, y_i)$是点$x_i$和$y_j$之间的距离函数,常设置为欧拉距离。作者将$\min \limits_{1<=j<=k} d(x_i, y_j)$ 近似为$ - 1/ \beta log \sum_{j=1} ^k \exp^{-\beta d(x_i, y_j)}$,因此上文中的优化问题被近似成:
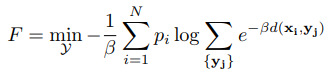
参数$\beta$决定了 F 对 D 的近似程度。当$\beta$接近无穷大,F 会无限趋近于 D;而当$\beta$接近于 0,F 则不能很好的近似 D。在 DA 算法中,F 被称为 free-energy function,β被称为退火参数。给定$\beta$的情况下,F 的极小值可以通过对$Y_j$求偏导得到的:
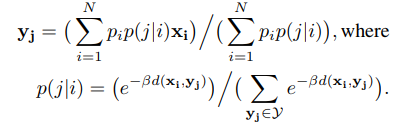
到目前为止,本文的内容都是对现有理论的描述。有趣的是,作者随后论证了退火参数β如何可以作为分辨率的度量。
当$\beta$很小时,对数据集内的任意两个点$x_1$,$x_2$,$\exp^{\beta d(x_1, y_j} \approx \exp^{\beta d(x_2, yj}$,即这两点是无法区分的。因此,在低$\beta$值时,所建立的优化函数无法区分任意两点,整个数据集将被视为单个集群。随着$\beta$值的增加,最初属于同一群集两个不同点,变得足够可分。当$\beta$趋于无穷大,数据集的每一个点都与其他点很不相同,每一个点都将被视为一个单个的集群。即,$\beta$是分辨率的度量,$log \beta$则是分辨率范围的度量。
作者由此定义了 persistence 的概念——在$\beta$值的一定范围内,最小化 F 的 Y 值应该保持不变。因此,有 k 个集群的聚类结果的 persistence 可以写作:
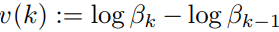
其中$\beta_k$是类的数量从 k-1 增加到 k 的分辨率。数据集真正的类的数量$k_t$可以通过求得 v(k) 的最大值得到。$\beta_k$的在欧式距离情况下解析解,由于篇幅限制这里不赘述,感兴趣的读者可以去论文中查看。
图 5(a3)和(b3)是在图 5(a1)和(b1)计算 persistence 的一个例子,可以看到,对任何 k 不等于 3 和 9 的 k 值, $log \overline{\beta_3} - log \overline{\beta_2} >> log \overline{\beta_k} - log \overline{\beta_{k-1}}$ 和 $log \overline{\beta_9} - log \overline{\beta_8} >> log \overline{\beta_k} - log \overline{\beta_{k-1}}$都成立。另外,我们还可以观察到在图 5(a1)数据上,$log \overline{\beta_3} - log \overline{\beta_2} > $log \overline{\beta_9} - log \overline{\beta_8},说明选择 3 个类比选择 9 个类更加合适,而在图 5(b1)数据上则相反。这与我们的观察相符。
作者也给出了 persistence 在非线性可分数据下的计算方法——选择一个 kernel function 将数据从低维投射到高维,由于显式地定义 kernel function 是很困难的,这里使用了在 svm 中也出现了的 kernel trick。文章中给出了 persistence 在 spherical clusters 等非线性可分数据上的结果。
图 6 给出了所使用的测试数据。图 6(a)是 4 个低方差高斯分布,图 6(b)是 4 个高方差高斯分布,图 6(c)和图 6(d)是合成数据 u,真正的类分别为 8 和 15;图 6(e)和图 6(f)则是有 3 类的 spherical clusters。
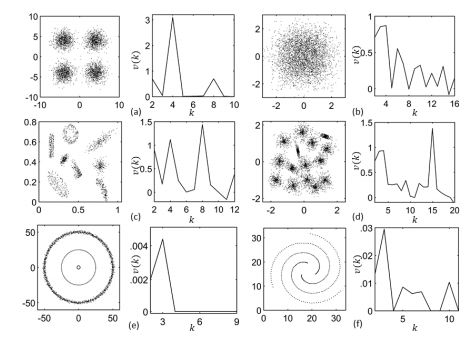
图 6:在不同数据上计算 persistence [图片来源:Srivastava, A. et al. (2018). On the Persistence of Clustering Solutions and True Number of Clusters in a Dataset. AAAI.]
可以看到利用 persistence 能够准确的预测真正的聚类数,作者在一系列真实数据上所得到的结果也印证了这一点。笔者认为这篇论文非常优秀,所提出的算法从概念上易于理解,在理论上十分巧妙地将 DA 算法的退火参数设计为分辨率从而自然的得到 persistence 的计算公式。log 的使用可以带来一定的计算优势,特别是当数据集的大小 N 增加时。并且,利用 kernel trick 该算法可以轻易扩展到非线性可分的情况。有一点遗憾的是如果能够看到算法在更高维和更多数据类型(如图像数据)上的表现就更好了。另外是由于$\beta_k$的求解涉及到海森函数,作者限定了距离函数为欧拉距离以得到具体的解析解,而没有涉及更一般的解。
3. Partial Label Learning with Self-Guided Retraining
链接:http://www.ntu.edu.sg/home/boan/papers/AAAI19_Retraining.pdf
作者个人主页:http://www.ntu.edu.sg/home/boan/
本文一作 Lei Feng 难以查找,二作 Bo An 是南洋理工大学计算机科学与工程学院的副教授。曾在中国科学院计算技术研究所担任副教授。他于马萨诸塞大学阿默斯特分校获得计算机科学博士学位。Bo An 教授的研究兴趣包括人工智能,多智能体系统,博弈论,自动协商,资源分配和优化。
本文笔者想讨论的第三种不理想数据的情况是数据标签模糊。有时数据标签无法获取或标注过于昂贵而无法得到准确的标签,用这样的标签进行模型训练的学习过程叫做部分标签学习(partial label (PL) learning)——每个训练实例被分配一组候选标签,其中只有一个是正确的。第三篇论文中,作者尝试利用 self-traning 的思想处理部分标记的例子。但值得注意的是,在单纯的 self-learning 中,早期的错误标签预测可能会严重误导模型;并且由于 self-learning 隐含了标签之间是互斥的假设,生成的错误标签会直接导致真正的标签信息完全没有被使用。为了缓解这个问题,作者试图引入一个 norm 来鼓励模型实现以足够高的置信度区分 ground-truth 标签,同时尽可能多的利用候选标签信息。所介绍的算法叫做 SURE(Self-gUided REtraining)。
基于此思想,我们的介绍从对问题建模开始。给定数据 $X=[x_1, ..., x_m]^T \in R^{mxn}$和相应的标签集$Y = [y_1, ..., y_m]^T \in {0, 1}^{mxl}$,其中$y_{ij}=1$代表第 j 个标签是第 i 个数据点的候选标签之一,否则不是。由于 ground truth 标签未知,其可以被视为潜变量(latent variable)并用置信矩阵(confidence matrix)$P = [p_1, p_m]^T
\in [0, 1]^{mxl}$来表示一个标签为 ground truth 标签的置信度。$p_{ij}$代表对第 i 个数据点来说,第 j 个标签是 ground truth 标签的置信度。为实现候选标签之间尽量互斥的关系但又避免过于绝对,作者引入了最大无限范数正则化(maximum infinity norm regularization),表述如下:
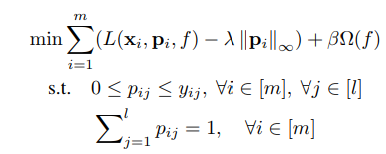
其中$[m] := {1, 2, ..., m}$,L 是所使用的损失函数,$\Omega$约束模型复杂度,即我们所熟悉的正则化,$\lamba, \beta$则是 tradeoff 参数。值得指出的是,上式中损失函数使用的不是候选标签 Y 而是潜变量 P($L(x_i, p_i, f)$)。即随着矩阵 P 的更新我们所指定的 ground truth 标签也会更新,从而保证学习过程中的自我更正能够被及时的用于模型训练。
此外,在模型训练初始时,损失函数的值往往比较大,因此会主导优化过程;仅在损失值落在一定范围内时置信矩阵的值会对优化过程造成较大影响,因此这样可以在一定程度上减轻 self-learning 中早期的错误标签预测对模型的负面影响。同时,置信矩阵的重要性可以通过修改$\lambda$的值来修改。两个约束则保证了仅候选标签的置信度应该大于等于 0 并小于 1,非候选标签的置信度应该严格为 0。并且置信度的加和应该为 1,使得我们能够将其对待为概率。这样设计的优势是能够隐含候选标签之间应当互斥的假设——因为候选标签的置信度加和应当为 1,当某一个候选标签的置信度增加时,其他一个或多个候选标签的置信度应该相应地减少。
此外,与传统自我训练的方式不同,通过以足够高的置信度拾取标签来执行确定性伪标记,通过折衷损失和最大无穷大规范来区分和扩大地面真实标签的置信度。直观地,仅在允许的损失范围内,具有足够高置信度的候选标签可被识别为地面实况标签。通过这种方式,通过训练模型和联合执行伪标记来减轻自我训练的负面影响。另外,第一个约束有两个作用:每个候选标签的置信度应大于 0,但不大于 1; 每个非候选标签的置信度应严格为 0。
为给出一个实例,作者选取了 square loss 作为损失函数、简单线性回归作为模型、squared Frobenius norm 作为控制模型复杂的范数,然后描述了优化策略。这里使用的仅仅是 alternating minimization,在回归模型中也经常使用,因此不过多赘述。值得一提的是,为了将简单线性回归模型扩展到非线性的情况,作者也使用了带 kernel trick 的 kernel function 将数据从低维投射到高维,和我们在上一篇文章中看到的一样。
到此,SURE 算法就设计完毕,完整过程如下:

优化过程结束后,对数据$\tilde{x}$预测的真实标签$\tilde{y}$则为:
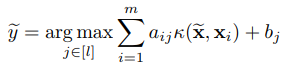
实验方面,作者选用了 4 个 UCI 数据集(deter,ecoli,glass,usps),每个 UCI 数据集可用于生成带有部分标签(PL)的数据集。生成 PL 的过程由三个参数控制——p、r 和$\epsilon$。其中 p 控制生成 PL 的比例,r 控制假阳标签(false positive)的数量,$\epsilon$控制某一个假阳标签与 ground truth 标签一起出现的概率。图 6 给出了所使用的测试数据的描述性统计。可以看到,数据集一共有 4 种配置。其中配置 I 将会选择某一特定标签,其有概率$\epsilon$与 ground truth 标签一起出现,其他标签作为假阳标签出现的概率则为$1 - \epsilon$。在配置(II),(III)和(IV)中,随机选择 r 个标签作为假阳标签,即候选标签的数量为 r+1.
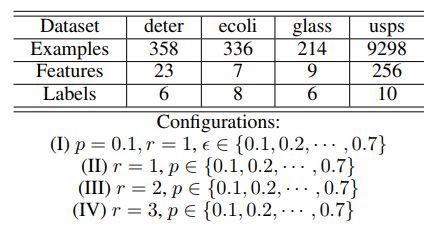
图 7:UCI 测试数据的描述性统计 [图片来源:Feng, L.; An, B. (2018). Partial Label Learning with Self-Guided Retraining. AAAI.]
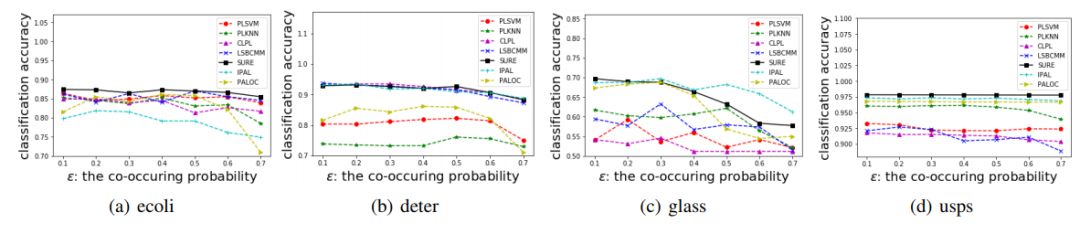
图 8 到图 11 给出了 SURE 算法和用于对比的算法在 UCI 测试数据 4 种配置上的表现。可以看到,SURE 算法在每一个测试集上的表现都是非常优秀的。单独查看某一个测试集的结果,SURE 的结果并没有显示出准确率上明显的优势,但其稳健性非常好,能够在不同情况下都保持较高的准确率。
[Image: image.png] 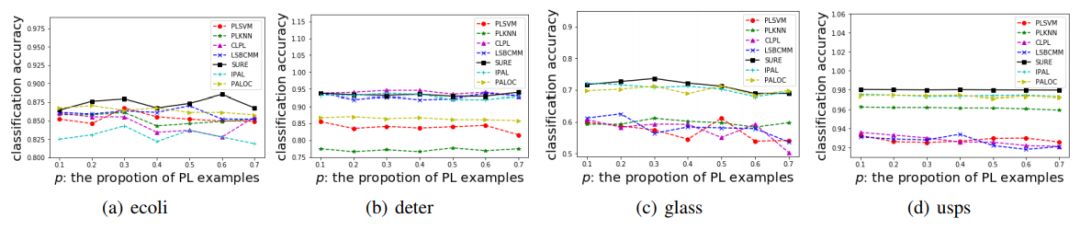
[Image: image.png] 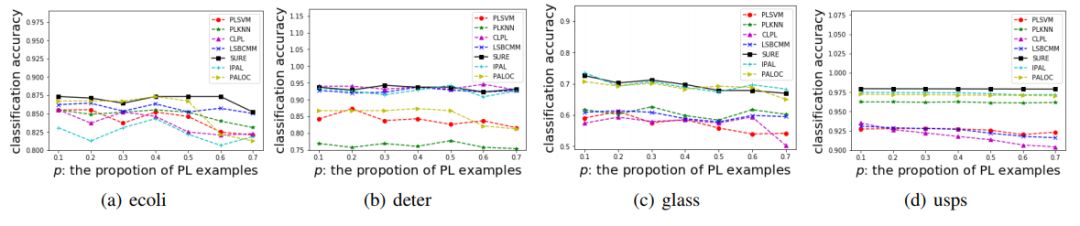
[Image: image.png] 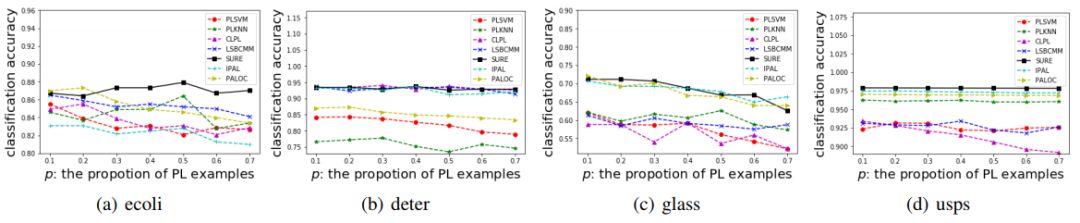
笔者个人很喜欢这篇论文,和上一篇论文一样,算法的设计十分精巧。范数的引入能够在保证灵活性的前提下取得高置信度。此外,该方法的扩展性很好,由于关键思路仅仅是对置信度增加惩罚项,对函数的限制不大。
3. 小结
可以很明显看到,笔者本次介绍的文章均是以理论为基础,有较多的公式推导——但并不难以理解——并引入了很多经典算法,比如利用 feature mapping 实现从线性到非线性的扩展、alternating minimization 来实现高效地参数更新等。论文中所提出的算法大多也是对现有模型进行一些修改,创新也并非一蹴而就。模型的基石是已经存在几十年、上百年,在上学时作为基础所学习的理论。但在今天通过对这些理论的扩展、放松和结合,结果仍然令人惊艳,同时还能够保证简洁性。在笔者所处的工业界内也是一样,许多市场上的产品使用的仍然是最基本的方法,往往,模型的精度达到一定水平后-就-准确率就不再是第一目标,稳健性、可解释性、可控性等因素则会变得更加重要。
当然,回归到本文的主题,对于质量不理想的数据,笔者的个人经验是不论使用如何精巧的模型,所得到的训练结果往往还是不如使用简单模型但数据质量好的训练结果。因此,亡羊补牢虽不失为一个策略,但在有可能的情况下通过精心设计并严格执行计划来获得好的训练数据,仍然是最好的选择。

YUANYUAN LI:几次转行,本科国际贸易,研究生转向统计,毕业后留在比利时,选择从事农用机械研发工作,主要负责图像处理,实现计算机视觉算法的落地。欣赏一切简单、优雅但有效地算法,试图在深度学习的簇拥者和怀疑者之间找到一个平衡。我追求生活的宽度,这也是为什么在工作之外,我也是机器之心的一名兼职分析师。希望在这里通过分享自己的拙见、通过思想的碰撞可以拓宽自己的思路。
机器之心个人主页:https://www.jiqizhixin.com/users/a761197d-cdb9-4c9a-aa48-7a13fcb71f83
本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




