学界 | AAAI 2018获奖论文提前揭晓:两大奖项花落阿尔伯塔、牛津
机器之心报道
参与:蒋思源、李泽南、李亚洲
AAAI 2018 大会即将在 2 月 2 日于美国新奥尔良开幕。但在此之前,本届大会的获奖论文已经放出。据机器之心刚刚获得的消息,阿尔伯塔大学 Martin Müller 等人的工作获得了杰出论文(Outstanding Paper),而牛津大学 Shimon Whiteson 等人的研究获得了杰出学生论文(Outstanding Student Paper)奖。
作为人工智能领域的顶级国际会议,AAAI 大会每年举办一次。今年 AAAI 会议将于 2 月 2 日至 2 月 7 日在美国新奥尔良举办。不久之前,AAAI 2018 公布论文接收列表,国内有众多来自学界、产业界的论文被接收。据机器之心了解,阿里巴巴共有 11 篇 AAAI 2018 接收论文,腾讯 AI Lab 11 篇接收论文,之前机器之心也曾介绍过百度的 AAAI 论文《Multi-channel Encoder for Neural Machine Translation》。此外,在机器之心 AAAI 2018 论文专栏中,我们也介绍了来自南京大学、北京理工大学、浙江大学的 AAAI 2018 论文。读者们想要了解更多有关 AAAI 2018 的信息,可按照文末形式交流讨论。
虽然距离 AAAI 2018 大会的召开还有半个多月,但本届大会的获奖论文信息已经陆续出炉。阿尔伯塔大学论文《Memory-Augmented Monte Carlo Tree Search》获得杰出论文奖,牛津大学《Counterfactual Multi-Agent Policy Gradients》论文获得杰出学生论文奖。以下,我们将对这两篇获奖论文进行简单介绍:
杰出论文:Memory-Augmented Monte Carlo Tree Search

据阿尔伯塔大学 Martin Müller 教授的消息,该大学提交的论文《Memory-Augmented Monte Carlo Tree Search》获得了 AAAI 2018 大会的杰出论文奖。该论文作者分别为 Chenjun Xiao、梅劲骋与 Martin Müller。其中,梅劲骋本科毕业于华南理工大学,研究生赴上海交通大学,师从计算机系吕宝粮教授。2015 年起,他来到阿尔伯塔大学攻读博士,师从 Dale Schuurmans 教授。
Chenjun Xiao 研究生与博士阶段均师从于 Martin Müller 教授。

值得一提的是,该论文的导师,阿尔伯塔大学教授 Martin Müller 是计算机围棋顶级专家。Müller 教授所带领的团队在博弈树搜索和规划的蒙特卡洛方法、大规模并行搜索和组合博弈论方面颇有建树。实际上,DeepMind 著名围棋程序 AlphaGo 的设计研发主导人物 David Silver 和黄士杰(Aja Huang)(他们分别是 AlphaGo Nature 论文的第一作者和第二作者,也名列于最近的 AlphaGo Zero 论文中)都曾师从于他。
在去年 5 月的机器之心全球机器智能峰会(GMIS 2017)上,Martin Müller 曾以重磅嘉宾的身份在会上发表了主题为《深度学习时代的启发式搜索》的演讲,并与机器之心共同观看了 AlphaGo 与柯洁等人的系列人机大战,做出精彩点评。
目前这篇论文的内容还未公开,我们将持续跟进该研究的进展。
杰出学生论文:Counterfactual Multi-Agent Policy Gradients

AAAI 2018 杰出学生论文奖则由牛津大学获得,该论文作者分别为 Jakob N. Foerster、Gregory Farquhar、Triantafyllos Afouras、Nantas Nardelli 与 Shimon Whiteson,主要研究强化学习中的多智能体协同,其提出的中心化评估新方法在《星际争霸》测试基准中获得了很好的效果。以下,我们将简要介绍这篇论文的内容。
许多复杂的强化学习(RL)问题,如自动驾驶汽车的协调(Cao et al. 2013)、网络分组分配(Ye, Zhang, and Yang 2015)和分布式物流(Ying and Dayong 2005)等问题都很自然地建模为多智能体协作系统。然而,针对单个智能体设计的强化学习在这一类问题上通常表现不佳,因为智能体的联合动作空间会随着智能体的增加而呈指数级增长。
为了克服这种复杂性,我们往往有必要采取去中心化策略(decentralised policies),即每个智能体仅根据局部的动作观察历史而选择它们自己的动作。此外,即使在联合动作空间不是特别大的情况,学习期间的局部可观察性和通信约束也可能需要使用去中心化策略。
因此,我们非常有必要构建一种新型的强化学习方法以高效地学习去中心化策略(decentralised policies)。在某些情况下,学习本身也可能需要去中心化。然而在很多情况中,学习可以在模拟器或虚拟实验室中进行,因此智能体能获得额外的状态信息和自由地通信。
去中心化策略的集中式训练是多智能体规划的标准范式(Oliehoek, Spaan, and Vlassis 2008; Kraemer and Banerjee 2016),并且这种方法最近在深度强化学习社区(Foerster et al. 2016; Jorge, Kageb ack, and Gustavsson 2016)获得了广泛的研究。但是,我们该如何更好地利用集中式学习的优势依然是一个开放性问题。
另一个关键的挑战是多智能体间的信度分配(credit assignment;Chang, Ho, and Kaelbling 2003):在合作的环境下,联合动作通常只能产生全局奖励,因此每个智能体都很难判断它自己对团队的贡献。然而,这些奖励在合作的情况下通常是不可获取的,且往往不能鼓励单个智能体为更大的集体利益而做出牺牲。这种现象通常会在充满挑战的任务中大幅度地阻碍所智能体的学习,即使相对较少的智能体也会产生这种显现。
在本论文中,为了解决这些问题,我们提出了一种新的多智能体 RL 方法,被称作反事实多智能体(COMA)策略梯度。COMA 采用 actor-critic 方法(Konda and Tsitsiklis 2000),其中 actor(即策略)按照由 critic 评估的梯度而训练。COMA 主要基于以下三个想法。
首先,COMA 使用一个中心化的 critic(只用于学习期间),同时执行期间只需要 actor。由于学习是中心化的,因此我们可以使用中心化的 critic 限定联合动作和所有可用的状态信息,同时每个智能体的策略只限定在其自己的动作观察历史上。
第二,COMA 使用反事实基线(counterfactual baseline)。这一想法的灵感来自差异奖励(difference rewards;Wolpert and Tumer 2002; Tumer and Agogino 2007),其中每个智能体从目标奖励中学习,目标奖励将比较全局奖励与当那个智能体的动作被默认动作替代时接收的奖励。尽管差异奖励是执行多智能体信度分配(credit assignment)的有效方法,它们需要访问模拟器或者评估的奖励函数,并且总体上不清楚如何选择默认动作。COMA 通过使用中心化的 critic 计算一个特定智能体的优势函数而解决了这一问题,该函数对比了当前联合动作的评估回报与边际化单一智能体动作的反事实基线,同时保持其他智能体的动作不变。这类似于计算一个贵族效用(aristocrat utility;Wolpert and Tumer 2002),但避免了策略和效用函数之间的递归性相互依赖问题,这主要是因为反事实基线(counterfactual baseline)对策略梯度的期望贡献为零。因此,COMA 并不依赖额外的模拟、近似或关于适当默认行动的假设,它会依赖于集中式的 critic 为每一个智能体计算一个分离的基线,以推理特定智能体动作改变的反事实。
第三,COMA 使用一个 critic 表征以高效地计算反事实基线。在单次前向传播中,以所有其它智能体的动作为条件,它会为给定智能体的所有不同动作计算 Q-values。因为单个集中式的 critic 可用于全部的智能体,所有智能体的所有 Q-values 都能在一个批量的单次前向传播中计算。
我们在星际争霸单位微操的测试平台上评估了 COMA,近来它已经因为较高的随机性、大型状态动作空间和延迟奖励成为了挑战性的强化学习基准任务。以前的研究工作(Usunier et al. 2016; Peng et al. 2017)利用集中控制策略而对整个状态进行调控,因此其在宏观动作上有非常强劲的表现,这种策略会利用星际争霸的内置 planner 而结合移动与攻击动作。产生一个有意义的去中心化基准即使对于较少智能体也被证明是非常有挑战性的,因此我们提出了一种大规模减少每个智能体的视野以移除访问宏观动作的变体方法。
我们在这个新基准上的经验结果表示,COMA 相比于其它 actor-critic 方法和 COMA 本身的切除版可以显著地提升性能。此外,COMA 的最佳智能体可以和集中控制器的顶尖结果相匹配,因此它也能获得全部的状态信息和宏观动作。
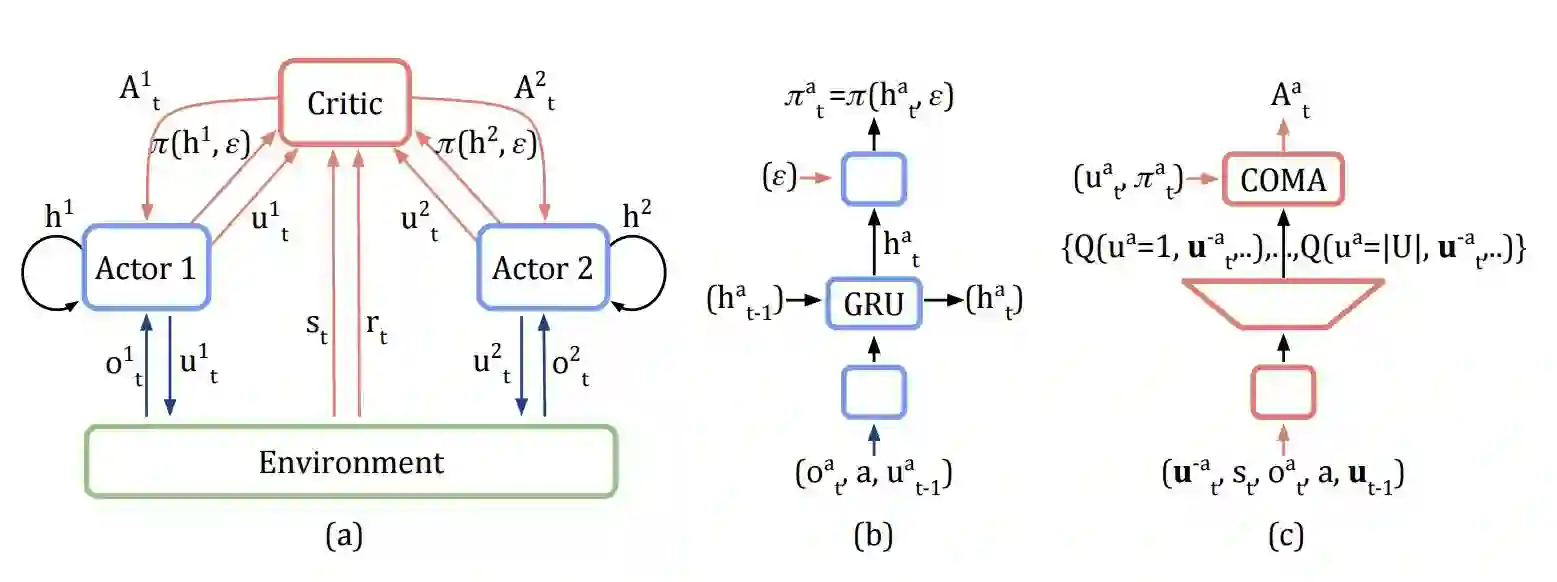
图 1:图(a),去中心 actor、环境之间的信息流,以及 COMA 的中心化评估(centralised critic);红色箭头和组件只在中心化学习中才需要。图(b)和(c),actor 和评估(critic)的架构。
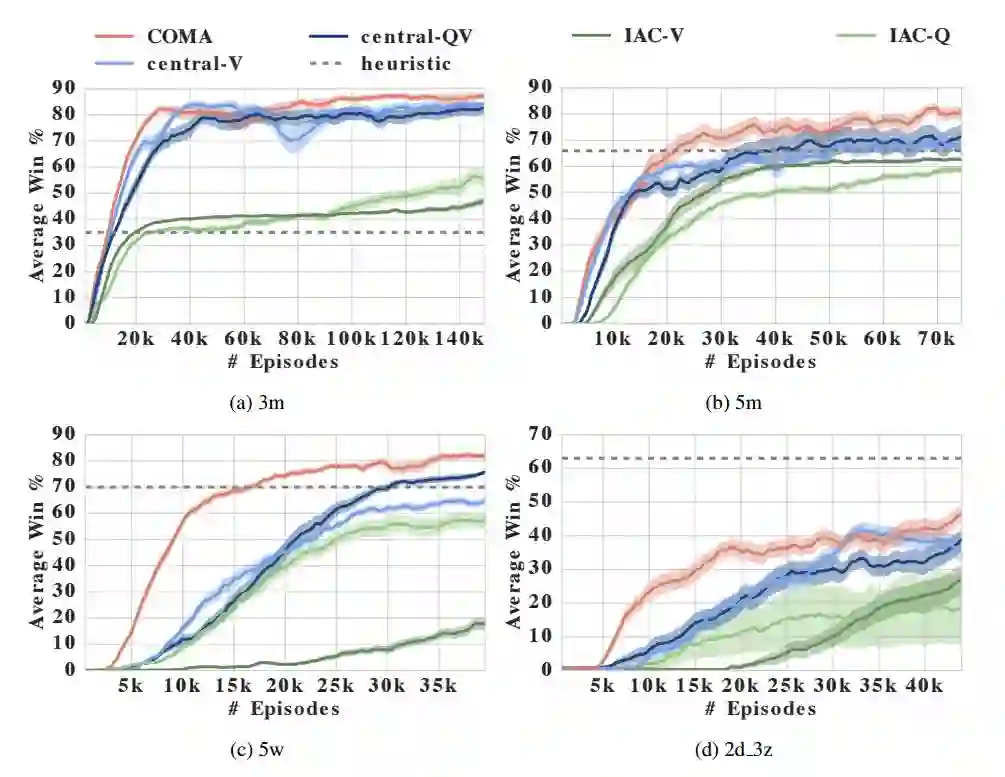

表 1:所有方法和手工编写的启发式方法在不同地图上的 1000 个评估片段的平均胜利百分数(去中心设定、有限视野)。最高的平均性能用粗体标出,括号里的值表示 95% 置信区间,例如 87(3) = 87 ± 3。此外还有,COMA(去中心的)的最大胜利百分数,与启发式方法、已发表结果的对比(在中心化设定中评估)。
论文:Counterfactual Multi-Agent Policy Gradients
论文链接:http://www.cs.ox.ac.uk/people/shimon.whiteson/pubs/foersteraaai18.pdf
很多现实世界的问题,如网络分组路由和自动驾驶汽车协调,都是被自然地建模为多智能体合作系统的。我们急需一种新的强化学习方式来有效学习这种系统的去中心策略。对此,我们提出了一种新的反事实多智能体(COMA)策略梯度方法。COMA 使用中心化评论来估算 Q 函数和去中心参与者的行为来优化智能体策略。此外,为了解决多智能体信度分配的挑战,它使用了一个反事实基线以边缘化单个智能体的行为,同时其它智能体的行为保持固定。COMA 还使用了一种关键的表征方法,允许单次前向传播就可以高效地计算反事实基线。我们使用具备显著的局部可观测性的去中心变体,在星际争霸单位微操的测试平台上评估了 COMA。实验证明,COMA 显著地提升了平均性能,在相同的设定下超越了其它多智能体 actor critic 方法,且最佳性能的智能体可与当前最佳的中心化控制器相比较,并能获得全部状态的信息访问。





