流利说基于深度学习的语法检错方法—DeepGrammar
概述
语言学习者常常会在口语和书面表达中出现各种语法错误,所以语法错误自动纠正可以极大地帮助学习者更好地掌握语言。行业内对自动语法错误自动纠正的研究已经有几十年的历史了,Conll2013和Conll2014甚至为语法自动纠正设置了一个shared task 来推动语法检错技术的发展。语法检错的方法主要分为以下三种:
基于规则的语法检错方法,虽然简单明了,但由于语言的复杂性,其覆盖面低即其召回率(Recall)较低,如果真正用在产品当中,必须投入大量人力编写规则。
基于分类器的方法,比如最大熵分类器(Han et al., 2006)可用于检测冠词错误,其预测每一个名词短语前应该使用什么冠词(a/an/the或者不使用冠词)。
基于翻译模型的方法,将错误的句子翻译成正确的句子。由于深度学习的发展,利用NMT(神经网络机器翻译)的方法进行语法检错也取得了不错的成果。
模型概述
流利说作为一家专注于语言教育领域的科技企业,当然也十分重视这一方面的研发,今天就来介绍一下我们的工作成果:以主谓一致错误检测为例介绍流利说的基于神经网络的语法检错方法(DeepGrammar)。
在英语中,每个动词的使用跟其上下文单词密切相关,在不同句子中,每个动词的上下文单词迥异且数目不同,但是 DeepGrammar 可以通过神经网络,将上下文信息表示为固定长度的向量,然后用这个向量去预测动词的形态(第一人称还是第三人称单数)。如果预测的动词形态与原始句子中动词形态不一致的话,我们就认为检测出了语法错误。
DeepGrammar 是基于双向 GRU 网络,其输入是动词周围的词语。下图所示的就是 DeepGrammar 的系统框架图。
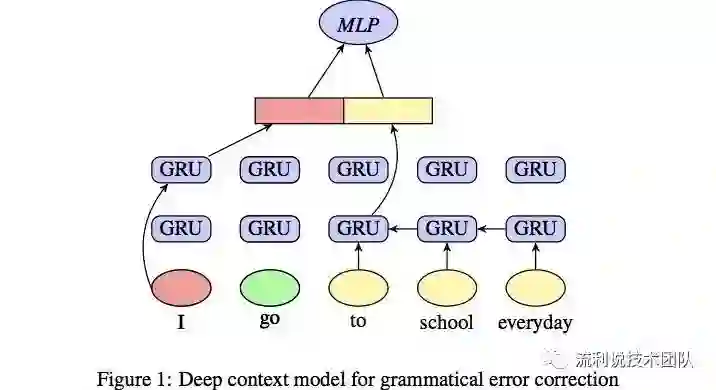
如图中所示,我们向左边的 GRU 网络输入左边的 context(‘I’),对右边的 GRU 网络输入右边的 context(‘to school every day’)。将左右两个 GRU 网络的输出拼接起来即可以得到 context vector,如下式所示。
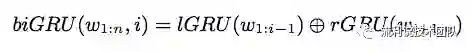
然后进过多层感知器(MLP)和 softmax 层来预测动词的形态,如下面所示:

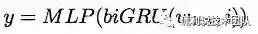
训练的损失函数是交叉熵 (cross entropy loss function),如下式所示:
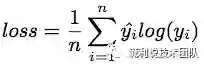
DeepGrammar 不同于传统的分类器方法需要很强的特征工程,也不同于机器翻译的方法需要大量的标注好的错误语料,DeepGrammar 可以直接从原生语料(native corpus)中学习语义的特征表示,来预测词汇的形态。另外也可以很容易的将 DeepGrammar 扩展到其他类型的语法错误上,例如名词单复数,冠词错误,介词错误等其他错误。
性能表现
下面我们通过几个例子来看下 DeepGrammar 在多种语法错误下的性能。
| Wrong Sentences | Correction Sentences |
|---|---|
| he might end up disheartenhis family | he might end up disheartening his family |
| ... negative impacts to the family | ... negative impacts on the family |
| The popularity of social media sites have made ... | The popularity of social media sites has mademark ... |
| Having support from relatives are vital | Having support from relatives is vital |
| ... after realising his or her conditions | ... after realising his or her condition . |
| Especially for the young people without marriage | Especially for young people without marriage |
| the government encouragepeople to give more birth | the government encouragespeople to give more birth |
转自:流利说技术团队





