来源丨智源社区(http://sites.computer.org/debull/A20june/p8.pdf)
3月31日,2020年图灵奖重磅出炉,颁给了哥伦比亚大学计算机科学名誉教授 Alfred Vaino Aho 和斯坦福大学计算机科学名誉教授 Jeffrey David Ullman。
Jeff Ullman 是数据科学领域的巨擘,他的研究兴趣包括数据库理论、数据库集成、数据挖掘等。在去年撰写的一篇评论文章中,他用浅显的语言重新定义了,统计学、数据科学和机器学习之间的交叉点,并破除了其中的误读。
他认为,尽管机器学习非常重要,但它远非实现有效数据科学所需的唯一工具。
「我并不认为机器学习可以完全取代数据库社区开发的算法。」 >>加入极市CV技术交流群,走在计算机视觉的最前沿
![]()
Have we missed the boat again?
多年来,数据库领域有一种言论认为,数据库系统正在变得无关紧要。
大家似乎持一种绝望的心态。
“have we missed the boat-again”
这句话,在数据库社区里似乎司空见惯[8]。
但我想论证,数据库以及由数据库研究而产生的技术,对于“数据科学”仍然是必不可少的,特别是在解决科学、商业、医学等应用领域的重要问题上。
数据库系统的核心,一直是如何尽最大可能处理最大的数据量,无论是以MB为单位的企业工资单数据、TB为单位的基因组信息,还是PB为单位的的卫星输出信息。
我对这三个问题的回答都是“no”。我将试着依次回答这三个问题。
几年前,我受邀参加了国家研究委员会(NRC)一个叫做“数据-科学-教育圆桌会议”的小组(详见 [16])。
这个圆桌不是由 NRC 的计算机科学部门组织的,而是由统计部门组织的。参与者中,统计学家和计算机科学家的数量差不多,加上其他学科的一些人。当时的收获主要是看统计学家如何思考这个数据的世界及其应用。最明显的一点是,统计学领域将数据科学视为自己的领域。
公平地讲,首先让我们明确一点,我非常尊重统计学家和他们所做的工作。统计学在现代数据研究中变得越来越重要,包括但不限于机器学习。许多统计学家开始像数据库界或者更其他计算机科学界那样,关注计算和数据分析。仅举一个小例子,
我最喜欢的技术之一是局部敏感哈希算法(LSH),这是一个直接来源于数据库社区的想法。
然而,我在斯坦福大学统计部门的一位同事 Art Owen 向我展示了关键步骤——最小哈希(minhashing),这一步骤很大程度上加速了这个过程——这是我们几年前就应该能够弄清楚的,但是没有弄清楚。
然而,我在圆桌会议上的经验也让我感觉到,统计界的一些人正在努力将统计定义为数据科学的核心组成部分。相比之下,我更倾向于把高效处理大规模数据的算法和技术视为数据科学的中心。人们普遍认为,数据科学是一门结合了多个领域知识的学科,我对此完全赞同。但这些领域究竟是什么,它们又是如何相互作用的呢?
这个问题如此重要,以至于不同社区纷纷发表维恩图来证明他们自己在数据科学中的中心地位。最近有一篇文章[10]对这些图表进行了总结和评论。其他维恩图表示相关的所有观点,请查询维基百科数据科学维恩图。
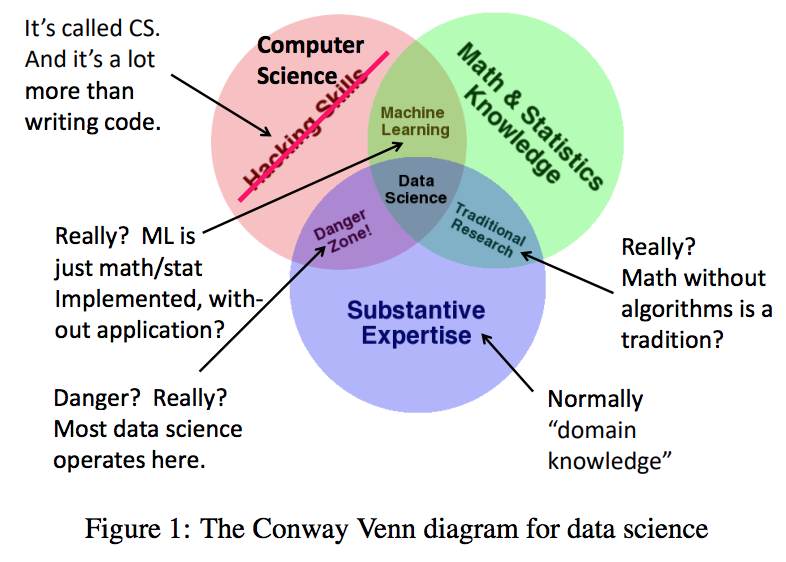
由于 Drew Conway的缘故(德鲁 · 康威,美国数据科学家,因其对数据科学的维恩图定义以及将数据科学应用于研究恐怖主义而闻名),统计学家们都习惯使用特定的图表。这个图表显示了三个相互交叉的集合:
“黑客技能”、“数学和统计学”和“实质性专业知识”
。在圆桌会议上,这个图表被多次展示,来说明统计学的重要性,我还看到统计学家在其他几个场合展示同样的图表,以解释他们的领域对数据科学的重要性。我复制了图1中的图表,但是我添加了一些点评来解释图表中存在误区之处。(如下图)
事实上,几乎图表中的每一个区域在某种程度上都有误导性。
1、首先,一个小问题: 所谓的“实质性专门知识”一般要统称为”领域知识”或类似的东西。
2、最严重的问题是将计算机科学称为“黑客技能”。
计算机科学给数据科学带来的远不止是编写代码的能力。我们提供算法、模型和框架,来解决各种各样的问题。所有这些在处理数据时都是必不可少的。
3、“传统研究”在图中显示为数学/统计与应用的交叉领域。换句话说,在这种形式的研究中,人们只考虑实际应用,而不编写任何代码,因此不会影响现实世界。我不知道这是哪来的传统,但我认为,这可不是数据库社区的传统。
4、机器学习在这个图表中有一个奇怪的位置。它被描述为“黑客”加上数学/统计。这意味着机器学习和实际应用没有任何关系。实际上,它与应用之间有着千丝万缕的联系,这就是为什么今天机器学习的算法如此受重视,不仅在数据库界,而且在整个计算机科学界都是如此。
5.然后还有 Conway 所说的“危险区域”——通过编写代码来解决应用领域中的问题,而不需要统计学家的明智指导。几乎所有的数据科学都是这样的。举一个例子,谷歌和其他邮件服务商在检测网络钓鱼邮件方面做得很好。有多好?我们真的不知道,即使我们今天可以做一个统计分析,明天也不会奏效,因为这种威胁是不断变化的。真正的危险是我们本来可以做得更好,却放任那些骗子骗走可怜虫们毕生的积蓄。
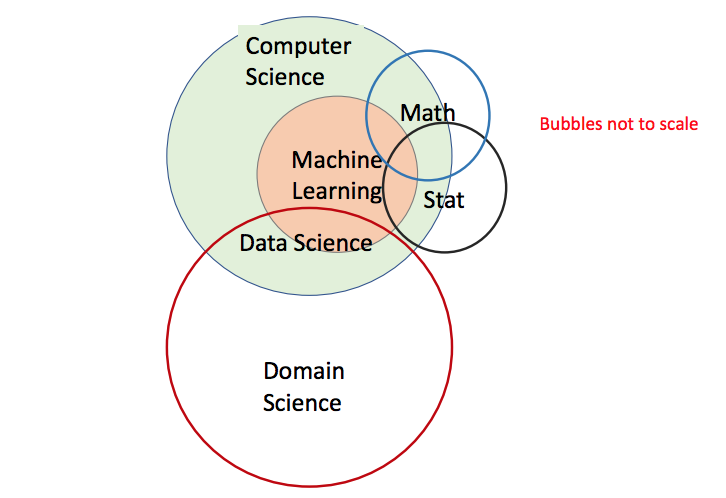
我也提出了自己的维恩图(图2) ,我相信它能更好地描述这些领域之间的关系。有计算机科学和各个其他领域的科学,数据科学就位于这些领域交叉的某些地方。机器学习是计算机科学的一个分支——是当前一个非常重要的子领域。机器学习一部分可以用于数据科学,也有很多其他和计算相关的用途。
这当中很多应用现在被认为是“人工智能”,比如无人驾驶汽车或入侵检测。最后,我认为数学和统计学对于所有的计算机科学都是非常重要的工具,虽然我图表中所画的小气泡并没有充分展示出它们的重要性。这样画是为了强调它们并不真正直接影响领域科学,而是通过在它们的帮助下开发出的软件来产生影响。
图2: 计算机科学、机器学习和统计学之间的关系(个人观点)
我所画的图中最有争议的是,数学/统计学并不能直接解决领域的应用。毕竟,康威图所说的“传统研究”就是这么做的。但是,尽管应用程序和数学/统计学之间可能存在绕过计算以外的交互,但我认为这种交互很少会从应用层面产生什么实际的好处。
为了说明这种区别,我们来看一下数据科学教育圆桌会议第四次会议的报告[14]。其中讨论的一部分集中在美国统计协会举办的“黑客马拉松”上,名为“Datafest”。从表面上看,这个活动就像我们通常看到的计算机科学专业学生参加的黑客马拉松。竞赛团队将得到一个来自某个应用领域的大数据集,但是在竞赛评分方面有很大的不同。评分的焦点不在于是否解决了什么具体的问题,以及解决方案的质量如何。
相反,大奖颁给了“最佳数据可视化、最佳外部数据使用和最佳洞察力”。换句话说,黑客马拉松上获奖是因为你做了一些统计学家感兴趣的事情,而不是解决了别人的实际问题。我希望读者能从另一个角度看问题,即目标是服务,而不是自娱自乐。面向计算机科学的 Kaggle 竞赛[13]正是如此。
现在,让我们来看看机器学习的兴起是如何影响数据的使用的。毫无疑问,机器学习已经对我们利用数据解决问题的能力产生了巨大的影响。然而,我并不认为机器学习可以完全取代数据库社区开发的算法。我希望读者可以考虑三个问题:
1. 许多涉及“大数据”的问题其实并不是真正的机器学习问题;
2. 很多机器学习倡导者会把原本不属于机器学习的方法归类到其中;
3. 许多机器学习方法产生的神秘模型不可解释或不可证明。
我认为,
机器学习的一个公平的定义是利用数据创建某种模型的算法,并从中可以得到问题的答案。
例如,可以使用机器学习建立垃圾邮件模型,将给定的电子邮件来喂养模型,从而判断是或不是垃圾邮件。但并非所有有用的解决方案都可以用模型来表示。例如,我们在前面提到了局部敏感哈希数据库(LSH) ,它是数据库社区处理数据的一种重要技术。LSH 是一种用于在数据集中查找类似项的技术,使用它就不必查看所有数据对了。
在实际应用中,LSH 是一个非常强大的工具,但是它不属于机器学习模型。
3.2 机器学习倡导者有时把原本不属于机器学习的方法归入其中
比如说,聚类,它被定义为机器学习的一个分支,尽管早在机器学习出现之前,聚类就已经被研究过了。梯度下降法是另一个早于机器学习的例子,然而不知何故被普遍认为是一个机器学习的分支。另一个重要的例子是关联规则(一种常用的无监督学习算法)。关联规则于1993-1994年由拉凯什 · 阿格拉瓦尔和朋友首创,比几乎所有的机器学习概念都要早。我甚至记得曾经和一位机器学习的倡导者谈起,他提出 LSH“一定是机器学习,因为它真的是一个很好的方法。”但事实上,LSH 就是一个与机器学习毫无关系的大数据算法。
通常,机器学习算法会得出正确的结论,而这些结论只有通过所展示的模型才能够解释。而这种模型往往是如此复杂,以至于对于普通用户来说毫无意义。更重要的是,这个模型,即便能够给出正确的诊断,但可能它的推理隐藏在处理一张百万像素的图像中。另一方面,有时候,我们有权要求解释。例如,如果你的保险公司提高了你的保险费率,原因是一些预测汽车事故的模型显示你的事故发生率提高了,至少你得知道为什么会这样。
但是,非机器学习方法通常比机器学习模型更可解释。
为了看出区别,以通过关联规则识别垃圾邮件为例。产生一组“规则”,在这种情况下可以是一组单词,它们在电子邮件中的出现表明它是垃圾邮件。
您可能认为这些规则就是垃圾邮件的模型,这也就是为什么机器学习倡导者认为关联规则属于机器学习。但实际上,用于寻找关联规则的算法并没有从数据中“学习”到一个模型。
他们只是简单地计算包含某些单词的垃圾邮件的数量,如果这个数量足够高,他们就宣布一条规则,即包含这些单词的邮件是垃圾邮件。假如一个规则说,包含{ Nigerian,prince }单词的电子邮件是垃圾邮件。
相比之下,即使是最简单的机器学习技术,比如学习每个可能的单词的(正负)权重,以及在权重总和超过阈值时声明是垃圾邮件,也比基于关联规则的解决方案更准确。
但问题是关联规则方法是可解释的,而机器学习模型则不能。如果我真的是一个尼日利亚王子,我所有的电子邮件都被关联规则方法判定为垃圾邮件,那么至少我可以理解其中的原因。而另一方面,如果你问 gmail 为什么它判断某些东西是垃圾邮件,它通常的回答类似于“它看起来像其他垃圾邮件。”也就是说,gmail在使用的模型告诉你它是垃圾邮件,其余的无可奉告。
我们经常会把社会的弊病归咎于数据。错误主要来源于:
在数据-科学-教育圆桌会议上,在第五次会议上有一个关于数据伦理的讨论[15]。举例说明,一个城市希望在犯罪高发的地区部署警力。警察们手握逮捕发生地的数据,结果是他们在那些地区确实逮捕了更多的人。但是,逮捕行动并不仅仅反映犯罪的发生,也反映了警察到场进行逮捕行动本身。数据造成了误区。就是说,历史原因,警察优先被派往某些地区,数据真实地反映出,在那些地区有更多的人被捕。也许本质上只是因为,在警力不足的地方,逮捕率较低。
数据可能使偏见永久化的另一个常见例子,一家公司在决定晋升时总是歧视妇女。他们希望利用机器学习建立一个AI系统,来处理简历,并识别那些与他们成功晋升员工相似的特征。
但数据显示,女性候选人往往不会成功,机器学习算法便从数据中学习,从而拒绝女性的申请。这些数据再次延续了现有的偏见。但是这些数据并没有产生偏见,而是人产生了偏见。
有一种对数据使用的指责是,由数据产生的系统反映了说话者所反对的社会的某些东西。这种误读的一个明显例子涉及 Word2Vec [13] ,这是谷歌几年前开发的一个系统(后来被BERT所取代) ,该系统将单词嵌入到高维向量空间中,从而使具有相似意义的单词具有相近的向量。直观的想法是看看通常围绕在单词 w 周围的单词。那么 w 的向量就是与其周围关联单词的方向的加权组合。例如,我们预期「可口可乐」和「百事可乐」有相似的向量,因为人们谈论它们的方式大致相同。
当观察到某些向量方程的规律时,问题就出现了,例如作为向量,
London − England + France = Paris
也就是说,伦敦和巴黎,作为各自国家的首都和最大的城市,周围有许多反映这种地位的词汇。我们预期伦敦周围会有更多与英格兰有关的词汇,所以把它们拿走,代之以与法国有关的词汇。
这个观察结果无关紧要,但是其他方程式引起了一些严重的争议,例如,
doctor − man + woman = nurse
这个方程式,它是在要求“给我找一个像医生一样的职业词汇,但要更倾向于女性。”。大约50% 的医生是女性,但接近90% 的护士是女性。我们希望医生和护士这两个词是相似的,但是后者更多地出现在「她」这样的词附近。所以这个等式是有一定道理的。
这些负面例子真正反映的是,在这个社会中,女性更有可能和护理岗位联系到一起。我同意,很可能在不远的将来,情况会变化。
但我的观点是: 不
要责怪数据。
像 Word2Vec 或者 BERT 这样的系统,当在一个像维基百科这样的大型语料库上训练时,将会反映出广大公众使用的语言,而这种数据的使用又会反映出人们普遍认为是真实的东西,不管我们是否喜欢这个真实。
•尽管机器学习非常重要,但它远非实现有效数据科学所需的唯一工具或想法。
•尽管数据有误用的情况,但如果数据反映的是世界的本来面目,而不是我们希望的那样,我们就不应该责怪数据本身。
[1] R. Agrawal, T. Imielinski, and A. Swami, “Mining associations between sets of items in massive databases,” Proc. ACM SIGMOD Intl. Conf. on Management of Data, pp. 207–216, 1993.
[2] R. Agrawal and R. Srikant, “Fast algorithms for mining association rules,” Intl. Conf. on Very Large Databases, pp. 487–499, 1994.
[3] T. Bolukbasi, K.-W. Chang, J. Zou, V. Saligrama, and A. Kalai, “Man is to computer programmer as woman is to homemaker? Debiasing word embeddings,” 30th Conference on Neural Information Processing Systems, Barcelona, 2016.
[4] A.Z. Broder, M. Charikar, A.M. Frieze, and M. Mitzenmacher, “Min-wise independent permutations,” ACM Symposium on Theory of Computing, pp. 327–336, 1998.
[5] T. Buonocore, “Man is to doctor as woman is to nurse: the gender bias of word embeddings,” https://towardsdatascience.com/gender-bias-word-embeddings-76d9806a0e17
[
6] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” arXiv:1810.04805, 2018.
[7] A. Gionis, P. Indyk, and R. Motwani, “Similarity search in high dimensions via hashing,” Proc. Intl. Conf. on Very Large Databases, pp. 518–529, 1999.
[8] B. Howe, M.J. Franklin, L.M. Haas, T. Kraska, and J.D. Ullman: “Data science education: we’re missing the boat, again,” ICDE, pp. 1473–1474, 2017.
[9] https://www.kaggle.com/
[10] https://www.kdnuggets.com/2016/10/battle-data-science-venn-diagrams.html
[11] J. Leskovec, A. Rajaraman, and J.D.Ullman, Mining of Massive Datasets 3rd edition, Cambridge Univ. Press, 2020. Available for download at http://www.mmds.org
[12] P. Li, A.B. Owen, and C.H. Zhang. “One permutation hashing,” Conf. on Neural Information Processing Systems 2012, pp. 3122–3130.
[13] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” ArXiv:1301.3781, 2013.
[14] https://www.nationalacademies.org/event/10-20-2017/docs/DCE05D1E271C31C585455B25E43AE9E5462ED3312DB2
[15] https://www.nationalacademies.org/event/12-08-2017/docs/D8EE65EFC7F4B0C368D267EDAD10E5AB1BAFBE3369D2
[16] https://www.nationalacademies.org/our-work/roundtable-on-data-science-postsecondary-education
[17] https://en.wikipedia.org/wiki/Right to explanation
公众号后台回复“长尾学习综述”获取颜水成等最新深度长尾学习综述PDF
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~
![]()