上海药物所通过多任务深度神经网络建立药物调控激酶谱的预测分析方法
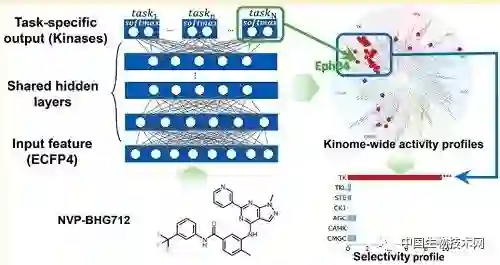
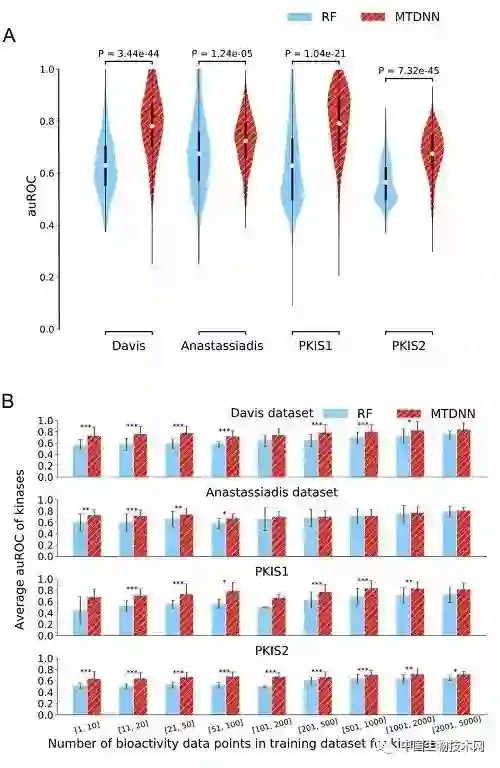
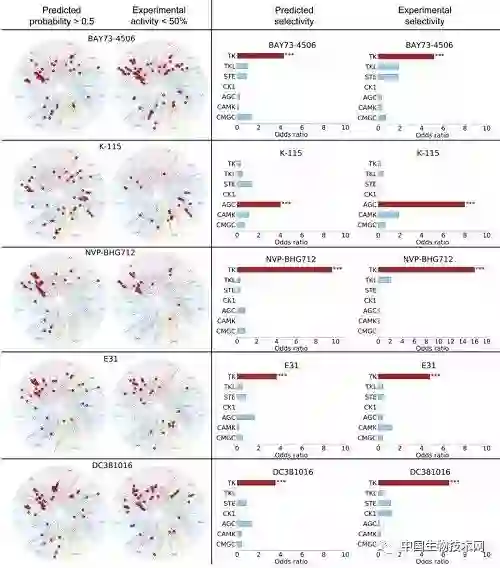
中国生物技术网诚邀生物领域科学家在我们的平台上,发表和介绍国内外原创的科研成果。
注:国内为原创研究成果或评论、综述,国际为在线发表一个月内的最新成果或综述,字数500字以上,并请提供至少一张图片。投稿者,请将文章发送至weixin@im.ac.cn。

本公众号由中国科学院微生物研究所信息中心承办
微信公众号:中国生物技术网 回复关键词“热点”可阅读热点专题文章,包括“施一公”、“肠道菌群”、“肿瘤”、“免疫”和“健康”
登录查看更多
相关内容

专知会员服务
36+阅读 · 2019年12月12日
Arxiv
3+阅读 · 2017年12月28日


相关VIP内容
专知会员服务
36+阅读 · 2019年12月12日
相关资讯
相关论文
Arxiv
3+阅读 · 2017年12月28日