百度新研究:神经传感器进行端对端语音识别(paper)

概述
在这项研究中,我们对CTC、RNN传感器和基于注意力的Seq2Seq模型进行了端对端语音识别的实证比较。没有任何语言模型,Seq2Seq和RNN-传感器模型在流行的Hub5'00基准上都优于使用语言模型的最佳报告CTC模型。
在我们内部不同的数据集中,这些趋势仍然保持着 - RBON传感器模型在波束搜索之后用语言模型重新获得胜过我们最好的CTC模型。这些结果简化了语音识别流水线,使得现在可以纯粹地将解码视为神经网络操作。我们还研究了编码器架构的选择如何影响三个模型的性能 - 当所有编码器层仅向前时,编码器对输入表示进行了大幅度取样。
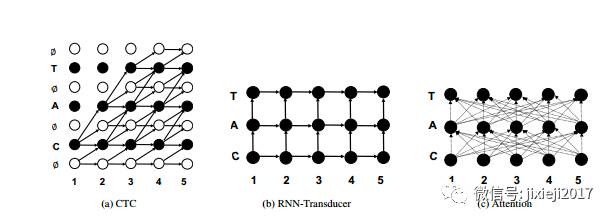
神经语音传感器
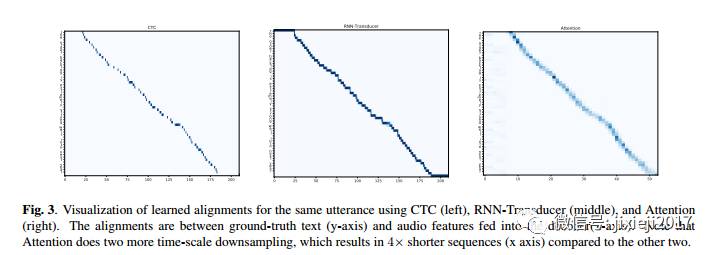
语音传感器通常由编码器组成。(也称为声学模型),它可以转换声音。高层次表示和解码器的输入,我们专注于vanilla seq2seq模型,虽然在执行局部单调注意方面也有一些努力。
扩展性能
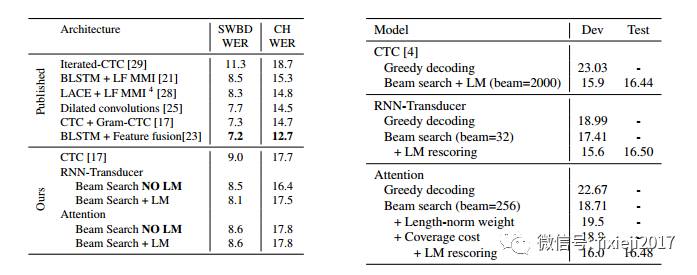
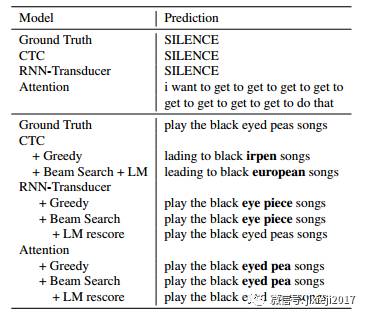
在本节中,我们对模型的性能进行了比较。涉及到公开基准以及我们自己的内部数据集。ASR的端到端模型的承诺是简化语言训练与推理管道系统。端到端CTC模型只简化了训练过程,但推理仍然涉及大规模解码。
编码器体系结构的影响
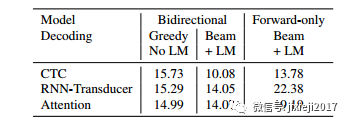
在本节中,我们使用标准的华尔街日报数据集来理解模型,执行不同的编码选择。由于编码器层远离损失函数,我们正在评估,期望一个编码器工作正常。
然而,不同的训练目标只允许不同类型的编码器:特别是:1)数量下采样的编码器是影响的重要因素,既训练模型时间,又提高精度(2)只有前向层的编码器对于流解码许可,我们也探讨了这方面的问题。我们相信这些结果可以更小更均匀了。数据集仍应保持在规模上,因此应侧重于趋势而不是优化。
paper:https://arxiv.org/pdf/1707.07413.pdf
★推荐阅读★
加入「AI从业者社群」请备注个人信息,添加小鸡微信 liulailiuwang




