ACL 2020 | 基于不同硬件搜索更好的Transformer结构

论文标题:
HAT: Hardware-Aware Transformers for Efficient Natural Language Processing
论文作者:
Hanrui Wang (MIT), Zhanghao Wu (MIT), Zhijian Liu (MIT), Han Cai (MIT), Ligeng Zhu (MIT), Chuang Gan, Song Han (MIT)
论文链接:
https://arxiv.org/abs/2005.14187
代码链接:
https://github.com/mit-han-lab/hardware-aware-transformers
收录情况:
ACL 2020
过去有大量针对Transformer结构进行简化的工作,但是它们都没有考虑到不同硬件对模型结构的影响。
本文首次提出使用网络结构搜索(NAS)的方法,针对不同的硬件,搜索适合该硬件的最佳的Transformer结构。
实验表明,在不同硬件下,得到的Transformer结构相比其他模型更小、更快,且不损效果。
更好更快的Transformer
众所周知,尽管Transformer效果很好,但由于它本身较大,难以在一些硬件上,尤其是移动手机上运行。
针对此,已经有很多工作对Transformer的结构进行改进,在大幅降低它体型的同时,保持效果不变。
然而,这些工作大都忽略了一个事实:对不同硬件而言,“最优”的Transformer结构可能大不相同。
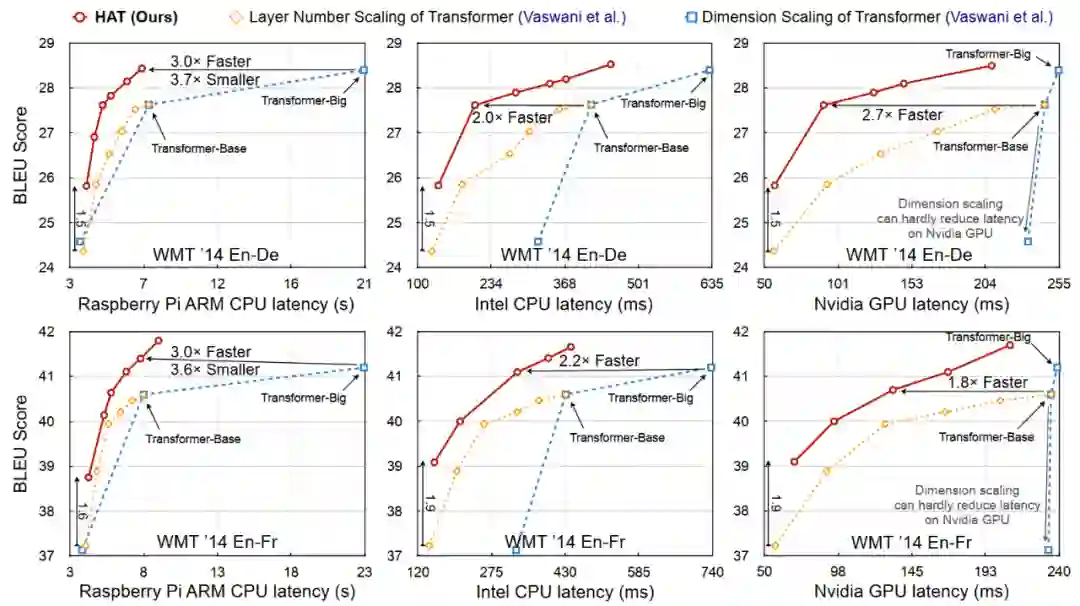
而且,过去的方法往往用FLOPs(浮点运算量)去度量模型效率,而不是更加直接的Latency(时延),在不同的硬件上,FLOPs和Latency之间并不完全对应。
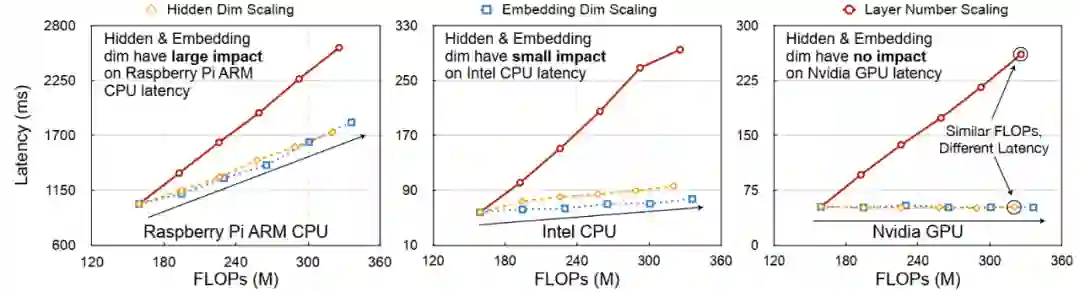
如下图所示,在Raspberry ARM CPU上,Eembedding的大小影响更大,但是对Intel CPU和NVIDIA GPU而言,Embedding就几乎没有影响。
此外,在Raspberry ARM CPU上,FLOPS和Latency大致呈线性关系,但是在Intel CPU和NVIDIA GPU上,只有模型的层数呈现这种关系,对隐藏层维数而言,相似的FLOPs会导致完全不同的Latency。这
说明了,在设计Transformer的时候,如果要追求更加精细的结果,需要考虑到不同硬件的实际条件。
但是,又该如何设计基于硬件的模型结构呢?手工设计自然过于麻烦,于是本文提出,利用网络结构搜索(NAS)方法进行自动搜索!
本文提出将解码器和编码器之间的任意Attention作为模型结构的一个变量,并且允许不同的头数、层数、隐藏层维数等其他变量,将以上变量作为一个大型的搜索空间,在其中针对不同的硬件找到最好的模型结构。
为了加快搜索速度,本文提出SuperTransformer——SubTransformer的父子类搜索方法。SuperTransformer是所有结构中最大的一个,而SubTransformer则从中采样子网络,不同子网络中相同的部分共享权重。
如此一来,就不必为每个自网络训练单独的模型,这就大大加快了搜索速度。
最后,通过实验显示,本文搜索出的模型结构不仅更小更快,而且在效果上甚至更好,超过了Evolved Transformer等结构。
总的来说,本文贡献如下:
基于不同硬件搜索不同的Transformer结构,和硬件实际条件更加契合;
提出SuperTransformer搜索范式,大大加快搜索速度;
搜索得到的模型更小、更快、更好。
HAT:Hard-Aware Transformers
| 搜索空间
对Transformer而言,比较重要的参数有:Embedding维数,Hidden维数,Head数,Layer数,此外,本文还允许解码器的每一层同时关注编码器的多层而不仅仅是最后一层。以上就定义了整个搜索空间。
但是,如果要训练所有的模型并且来评估它们的BLEU值,显然是不可能的。于是,本文提出SuperTransformer——作为所有可能的模型结构的一个“父类”——来囊括所有可能的模型。
SuperTransformer是搜索空间中“最大”的一个模型,所有的其他模型都是SuperTransformer中的一个子网络,并且共享相同的部分。一个子网络只需要取SuperTransformer中的前端一部分参数即可。
下图是一个示例。蓝色部分表明:如果搜索空间中Embedding维数最大为640,当前想要测评的模型维数是512,那么我们只需要取整个大矩阵的前512维。
橙色部分同理:如果搜索空间中Hidden维数最大允许是1024,而当前考虑的模型是768,也只需要取前768维即可。
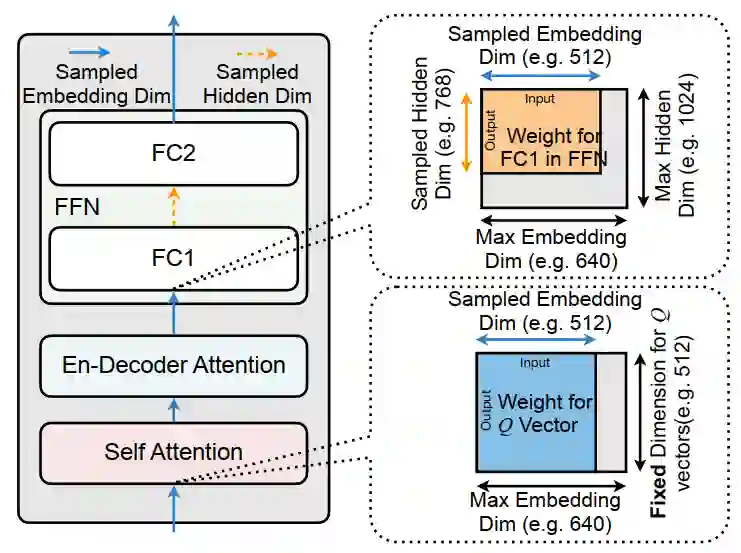
如此一来,所有的子网络都包含在了一个大的“父模型”中,训练子模型,也就意味着只需要大模型中对应的一部分参数即可。
相比一个一个训练独立的小模型,只需要像训练一个普通Transformer一样训练这个大模型,然后再从中取出子模型来做测评就可以了。这样就大大节约了训练开销。
| 搜索方法
然而,现在还有一个问题。我们的目标是直接降低模型在硬件上的Latency,这就需要对每个模型进行评估。
然而,用真实数据对每个模型都测量它们的Latency耗时太多。基于此,本文提出使用Latency Predictor,直接训练一个小的神经网络,输入模型结构,预测该模型在此硬件上的Latency。
乍一看这个方法似乎不靠谱,但是实际的效果却很好。如下图所示。
网络预测得到的Latency和实际的几乎没有差别,而我们需要做的,只是为每个硬件提供真实的训练数据。本文为每个硬件提供了2000个样本,按照8:1:1的方法划分数据集。
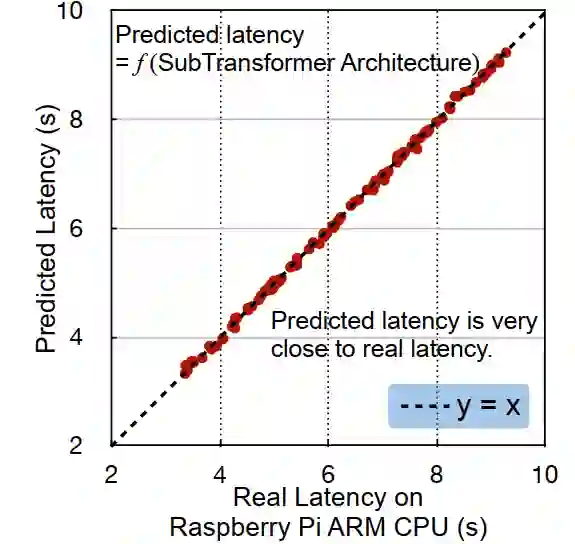
注意到Latency Predictor只用在搜索过程中,在最后实验的时候还是用的真实测得的Latency。
| 概览
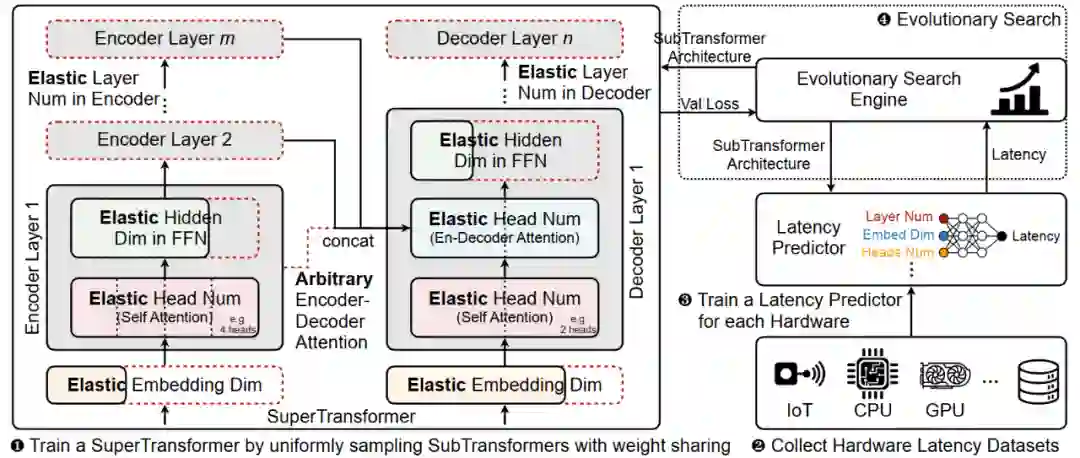
下图是HAT的方法概览。第一步就是定义搜索空间、训练SuperTransformer并从中采样子网络;第二步是搜集实际硬件-Latency的数据;第三步把这个数据训练一个Latency Predictor;最后使用进化算法搜索得到最佳的模型结构。
实验
本文在WMT’14 En-De, WMT’14 En-Fr, WMT’19 En-De, 和IWSLT’14 De-En上实验,基线模型有Transformer, Levenshtein Transformer, Evolved Transformer,和 Lite Transformer。
运行的硬件有Raspberry Pi-4 ARM Cortex-A72 CPU, Intel Xeon E5-2640 CPU, 和Nvidia TITAN Xp GPU。其他实验设置详见原文。
下图是在En-De和En-Fr上,不同模型的Latency和BLEU值结果。在Raspberry Pi ARM CPU上,HAT比Transformer Big快3倍,并且小3倍多,甚至效果还更好;在Intel CPU、Nvidia GPU上也有不小的提升。
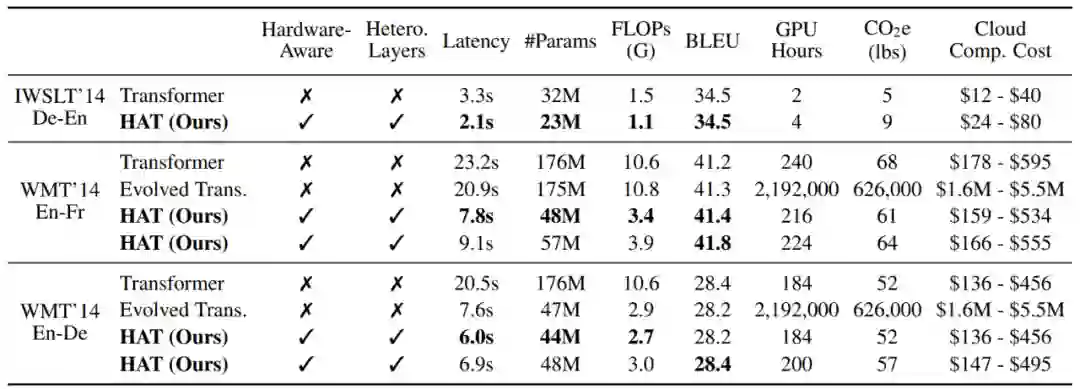
下表是具体的数据和比较。可以看到,HAT无论在Latency、参数量上,还是在FLOPs、BLEU值上,还是在搜索时间,甚至在二氧化碳排放量和花费的钱上,都有显著优势。可谓让NAS-Transformer走进千万实验室!
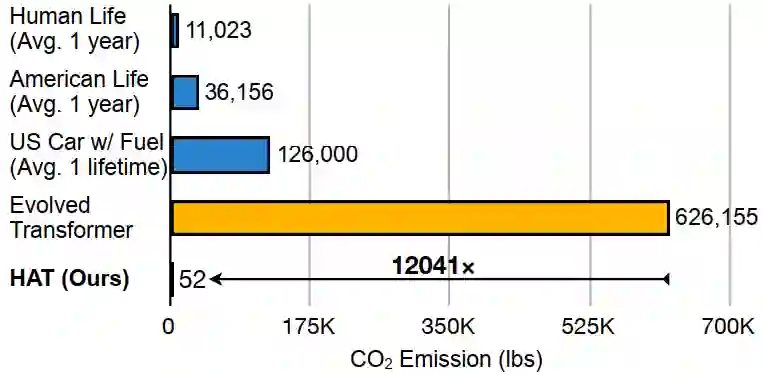
下图是搜索过程所排放的二氧化碳量比较,可以看到,HAT的排放量可以忽略不计,比Evolved Transformer少一万多倍。
除了以上实验之外,本文还做了详实的分解实验,包括:SuperTransformer的效果,是否可以加上量化,是否可以使用知识蒸馏等。读者可以参考原文。
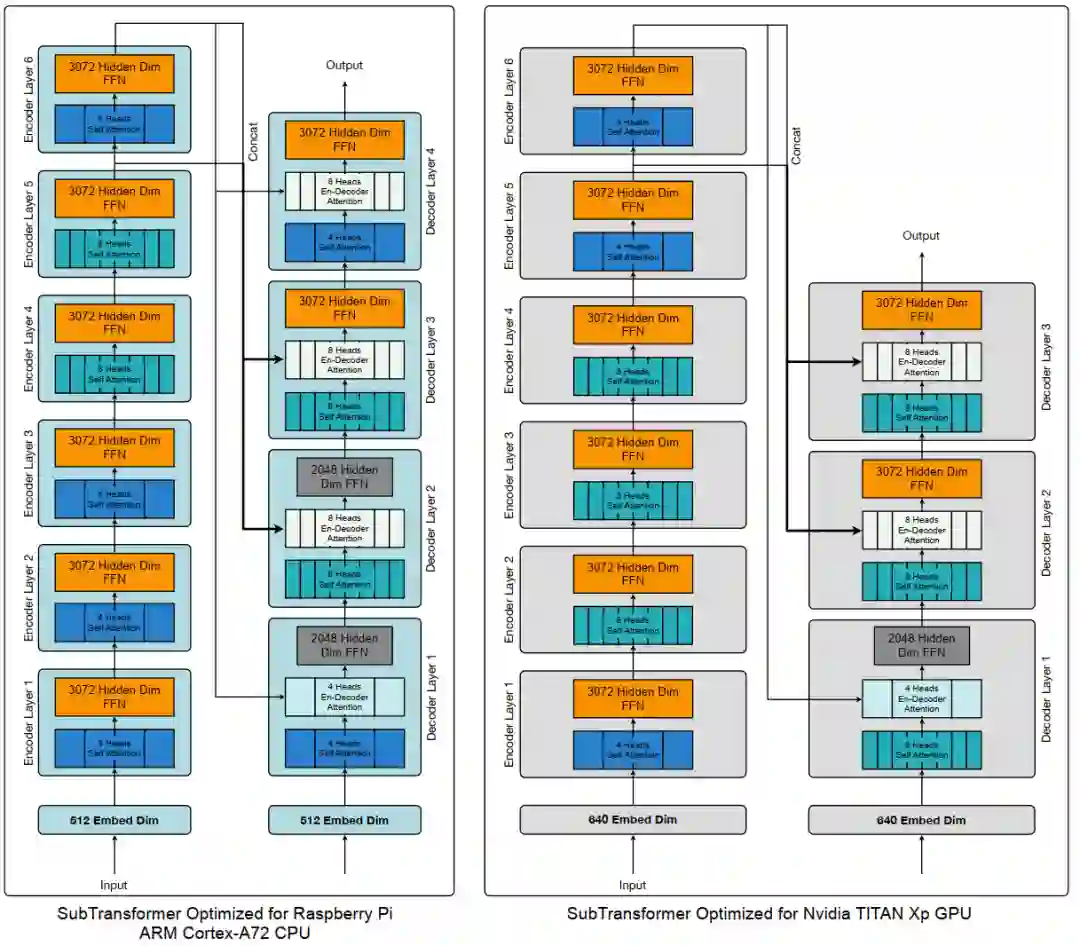
最后来看看使用HAT在不同硬件上得到的最好的结构是怎样的。如下图所示,可以发现,对Raspberry Pi ARM CPU和NVIDIA GPU,HAT得到的模型结构是很不同的。二者在层数、维度数和Attention方式上都有差别。
小结
本文提出了基于不同硬件的Transformer结构搜索方法,巧妙地提出了SuperTransformer的方法,让所有的子结构都囊括其中,从而只需要一次性训练父模型,就可以以采样的方式评估子模型了。
此外,为了进一步节约模型在评估时的开销,本文还提出了Latency Predictor,通过模型结构直接预测Latency,而不需要实际数据的输入。实验表明,本文方法可以得到更小、更快、更好的Transformer模型,而且有利环保,开销极小。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





