MorphNet:致力打造规模更小、速度更快的神经网络
文 / Andrew Poon,高级软件工程师;Dhyanesh Narayanan,Google AI Perception 团队产品经理
深度神经网络 (DNN) 已在解决图像分类、文本识别 和 语音转录 等实际难题方面显示出卓越的效能。然而,为给定问题设计适用 DNN 架构的任务依旧极富挑战性。鉴于潜在架构的搜索空间巨大,若要为您的具体应用从零开始设计一个网络,这在计算资源和时间方面都会花费高昂代价。神经架构搜索与 AdaNet 等方法使用机器学习来搜索架构设计空间,从而找出改进版架构。另一种方法是利用现有架构来解决类似问题,并针对手头任务对架构进行一次性优化。
本文中,我们提出了一种用于改进神经网络模型的复杂技术 MorphNet,其采用了上述第二种方法。MorphNet 技术最早在论文 “MorphNet:深度网络快速简洁的资源受限架构学习” (MorphNet: Fast & Simple Resource-Constrained Structure Learning of Deep Networks) 中提出,其将现有神经网络作为输入,专为新问题生成规模更小、速度更快且性能更佳的新神经网络。我们已使用该技术来解决 Google 内部难题,以设计规模更小、准确率更高的生产服务网络。目前,MorphNet 的 TensorFlow 实现已面向社区开放源代码,您可以利用该方法来提高模型效率。
工作原理
MorphNet 通过收缩和扩展阶段的循环来优化神经网络。在收缩阶段,MorphNet 通过稀疏性正则化项 (sparsifying regularizer) 识别出低效神经元,并将它们从网络中去除,因此该网络的总损失函数包含每个神经元的成本。然而,MorphNet 并未对每个神经元采用统一的成本度量,而是根据目标资源计算神经元的成本。随着训练的推进,优化器在计算梯度时会注意到资源成本信息,从而得知哪些神经元的资源效率高,哪些神经元可以去除。
例如,可以思考一下 MorphNet 如何计算神经网络的计算成本(如 FLOPs)。为简单起见,我们以表示为矩阵乘法的神经网络层为例。在此情况下,神经网络层拥有 2 个输入 (xn)、6 个权重(a、b…f)以及 3 个输出(yn;神经元)。通过使用标准教科书中的行列相乘方法,可以计算出评估该神经网络层需要 6 次相乘。
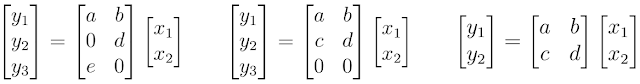
神经元的计算成本
MorphNet 将其计算为输入数和输出数的乘积。需注意,尽管左边示例显示出权重稀疏性(其中两个权重值为 0),我们仍需执行所有乘法,以此评估该神经网络层。然而,中间示例显示出结构化稀疏性,其中神经元 yn 一行中的所有权重值均为 0。MorphNet 识别出该层的新输出数为 2,且该层的乘次数量由 6 降至 4。基于此数据,MorphNet 可以确定该神经网络中每一神经元的增量成本,从而生成更高效的模型(如右图所示),其中神经元 y3 已被移除。
在扩展阶段,我们使用宽度乘数来统一扩展所有网络层的大小。例如,如果网络层大小扩展 50%,则一个低效网络层(开始有 100 个神经元,之后缩减至 10 个)将仅能扩展回 15 个,而只缩减至 80 个神经元的重要网络层则可能会扩展至 120 个,从而获得更多资源来开展工作。其中的净效应便是将计算资源从该网络中效率较低的部分重新分配给或许更有用的部分。
您可以在收缩阶段之后停止 MorphNet,从而削减网络规模,使之符合更紧凑的资源预算。这可以在给定目标成本时获得更高效的网络,但有时可能会降低准确率。或者,用户也可以完成扩展阶段,这将与最初的目标资源成本相匹配,但准确率也会更高。我们稍后将介绍此项操作的完整过程示例。
为何选择 MorphNet?
MorphNet 可提供以下四大关键价值主张:
有针对性的正则化:MorphNet 所采用的正则化方法比其他稀疏性正则化方法更有目的性。具体来说,MorphNet 方法用于促成更好的稀疏化,其目的在于减少特定资源(如每次推理的 FLOPs 或模型大小)。这可以更好地控制由 MorphNet 生成的网络结构,因为这些网络结构可能会因应用领域和相关约束而产生显著差异。例如,下图左侧面板展示了一个基线网络,该网络具有在 JFT 数据集上训练出的常用 ResNet-101 架构。在指定目标 FLOPs(如中间图所示,FLOPs 降低 40%)或模型大小(如右图所示,权重减少 43%)的情况下,MorphNet 生成的结构具有显著差异。在优化计算成本时,相比于网络较高层中的低分辨率神经元,较低层中的高分辨率神经元易于遭到更多修剪。但当目标是较小模型时,修剪权衡策略则恰恰相反
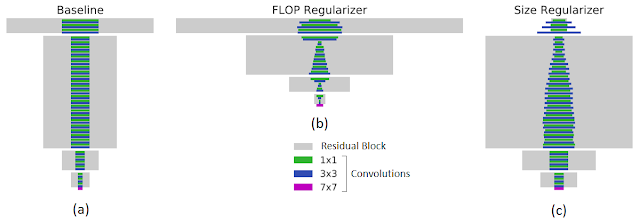
MorphNet 有针对性的正则化。矩形宽度与网络层中的通道数成正比。底部的紫色条表示输入层。左图:输入到 MorphNet 的基线网络。中图:应用 FLOPs 正则化参数 (FLOPs regularizer) 后的输出结果。右图:应用尺寸正则化参数 (size regularizer) 后的输出结果
MorphNet 是为数不多几款能够通过设立特定参数目标来实现优化的解决方案之一。这令其可以针对特定实现设立具体的参数目标。例如,通过结合特定于设备的计算时间和内存时间,您可按一种明确的规则将延迟时间设为首要优化参数
拓扑变换:由于 MorphNet 会学习每一层包含的全部神经元,因此该算法可能会遇到一个特殊情况,即,将一层中的所有神经元全都稀疏化。当一层中的神经元数量为 0 时,这会切断受影响的网络分支,从而有效改变网络的拓扑结构。例如,在 ResNet 架构中,MorphNet 可能会保留残差连接,但移除残差块(如下图左侧所示)。而对于 Inception 架构,MorphNet 可能会移除整个并行塔 (parallel tower)(如下图右侧所示)
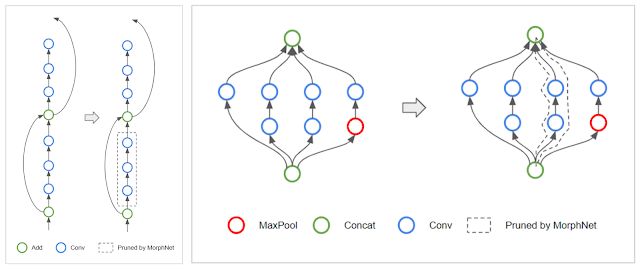
左图:MorphNet 可以移除 ResNet 式网络中的残差连接
右图:MorphNet 还可移除 Inception 式网络中的并行塔
可扩展性:MorphNet 在单次训练中学习新的结构,对于训练预算有限的情况十分适用。MorphNet 还可直接应用于昂贵的网络和数据集。例如,在上述对比中,MorphNet 直接应用于 ResNet-101,后者最初是在 JFT 数据集上耗费数百个 GPU 月后训练得出
可移植性:MorphNet 输出的网络具备 “可移植性”,这是因为它们可以从头开始训练,且模型权重并未与架构学习过程绑定。您无需担心要复制检查点或遵循特定的训练方法执行训练。只需正常训练新网络即可
网络变换
作为示范,我们以 FLOPs 为目标,将 MorphNet 应用于通过 ImageNet 数据集训练的 Inception V2 模型(参见下图)。基线方法使用宽度乘数,通过统一缩减每个卷积的输出数量来权衡准确率和 FLOPs(红线)。MorphNet 方法则在缩小模型时直接瞄准 FLOPs,从而生成更好的权衡曲线(蓝线)。这样一来,在相同准确率的情况下,MorphNet 方法的 FLOPs 成本要比基线法低 11% 至 15%。
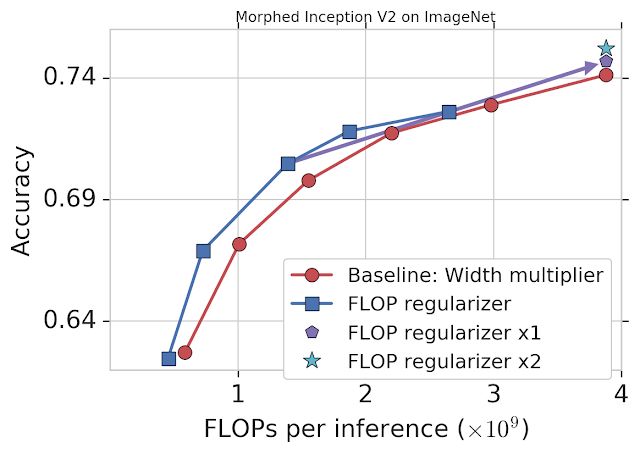
MorphNet 应用于通过 ImageNet 数据集训练的 Inception V2 模型。仅应用 FLOPs 正则化参数(蓝线)的性能比基线法(红线)性能高出 11% 至 15%。一个完整循环之后(使用 FLOPs 正则化参数和宽度乘数),在耗费相同成本的情况下,模型的准确率有所提升(“x1”;紫色符号);第二个循环过后,模型性能得以继续提升(“x2”;青色符号)
在此阶段,您可以选择一个 MorphNet 网络来满足更小的 FLOPs 预算。或者,您也可将网络扩展回原始的 FLOPs 成本来完成该循环,从而以相同成本获得更高的准确率(紫线符号)。重复 MorphNet 缩小 / 扩展循环将能再次提升准确率(青色符号),继而使整体准确率提升 1.1%。
结论
我们已将 MorphNet 应用到 Google 的多个生产级图像处理模型中。使用 MorphNet 可显著减小模型尺寸 /FLOPs 成本,且几乎不会造成质量损失。我们邀请您试用 MorphNet,您可在 此处 找到开放源代码 TensorFlow 实现,此外还可阅读 MorphNet 论文 以获取更多详情(https://arxiv.org/pdf/1711.06798.pdf)。
注:此处 链接
https://github.com/google-research/morph-net
致谢
Photobooth 是 Google 多个团队共同协作的成果。此项目的主要贡献者包括:Kojo Acquah、Chris Breithaupt、Chun-Te Chu、Geoff Clark、Laura Culp、Aaron Donsbach、Relja Ivanovic、Pooja Jhunjhunwala、Xuhui Jia、Ting Liu、Arjun Narayanan、Eric Penner、Arushan Raj、Divya Tyam、Raviteja Vemulapalli、Julian Walker、Jun Xie、Li Zhang、Andrey Zhmoginov、Yukun Zhu。
更多 AI 相关阅读:



