如何训练你的ResNet(二):Batch的大小、灾难性遗忘将如何影响学习速率
编者按:上篇文章中,我们提到了如何高效地训练ResNet。在今天的文章中,我们将对mini-batch的尺寸进行研究,同时要考虑遗忘性问题。
在上一篇文章中,我们得到了一个18层的ResNet网络,测试精度达到94%需要341秒,并且经过进一步调整后,时间缩短至297秒。
目前,训练使用的batch大小是128,batch更大,就支持更高效的计算,所以我们想试试当batch增大到512会发生什么。如果我们想估计之前的设置,就需要保证学习率和其他超参数都经过合适的调整。
具有mini-batch的随机梯度下降几乎是每次只训练一个样本,但不同的是,参数的更新会延迟到batch结束。在低学习率的限制下,你可以认为这种延迟是更高阶的效应,只要梯度只在mini-batch上求和而不是计算平均数,批处理就不会改变任何一阶的顺序。我们还在每个batch之后应用了权重衰减,它会通过batch size中的一个因素增加,从而抵消需要处理的batch数量。如果梯度根据mini-batch被平均,那么学习速率应该增加到可以消除这一影响只留下权重衰减,因为权重衰减的更新对应着学习率的因子。
所以现在我们将batch size定为512开始训练。训练时间为256秒,将学习速率增加10%,在128的batch size下,3/5的训练都能达到94%的测试精确度。如之前所料,在512的batch size下,验证结果有更大的噪声,这是因为批规范化的影响。
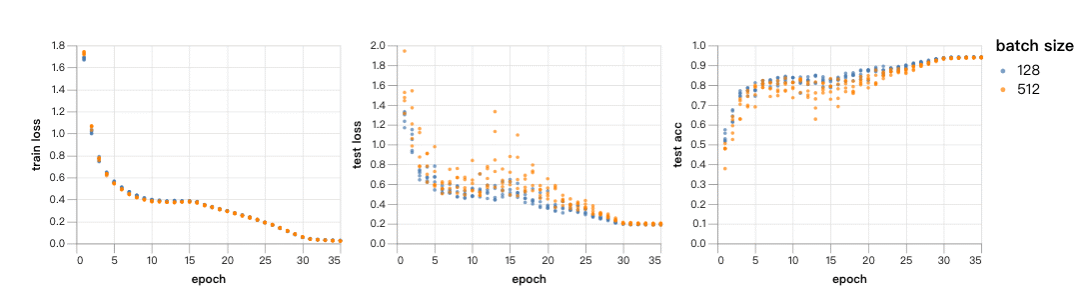
现在速度增加的很好,但是结果让我们很吃惊
考虑到要用不同的mini-batch进行训练,我们认为这一过程中我们忽略了两点。首先,我们认为延迟更新,直到这一mini-batch结束都是更高阶的影响,这在较低的学习率中是可行的。目前配置中的快速训练速度很大程度上取决于高学习率的使用。在凸优化的背景下(或仅仅是二次方的梯度下降),我们可以在某一点设置学习速率,达到最大的训练速度,在这一点处,二阶效应开始平衡一阶效应,并且一阶步长产生的益处可以通过曲率效应抵消。假设我们处于这种状态mini-batch导致的延迟更新应该产生相同的曲率惩罚,因为学习率的增加,训练会变得不稳定。简而言之,如果可以忽略高阶效应,就说明训练速度不够快。
另外,我们发现训练步骤只有一个,但事实上,训练是一个很长的运行过程,要改变参数就需要好几个步骤。所以,小的batch和大的batch训练之间的二阶差异可以随着时间积累,导致训练轨迹有很大不同。在之后的文章中我们会重新讨论这一点。
所以,我们该如何在限制训练速度的情况下,还可以提高batch size,同时不用维持曲率效应带来的不稳定性?答案可能是其他因素在限制学习速率,而我们并没有考虑到曲率效应。我们认为这一其他因素就是“灾难性遗忘(Catastrophic Forgetting)”,这也是在较小batch中限制学习率的原因。
首先,我们要对这一概念进行解释。这一术语通常用于,当一个模型在一个任务上训练后,又应用到第二第三个模型上。但是学习之后的任务会导致性能下降,有时这种影响是灾难性的。在我们的案例中,这些任务是来自同一个训练集的不同部分,所以单单在一个epoch中就会发生遗忘现象。学习速率越高,训练中参数所用的越多,在某一点时这会削弱模型吸收信息的能力,早期的batch就会更容易遗忘。
当我们提高batch size时,并没有立即增加模型的稳定性。如果是曲率导致的,稳定性会利可增加。反之,如果是遗忘是主要原因,模型不会受batch size的影响。
之后,我们进行了实验将曲率的效应和遗忘性区分开。曲率效应大多依赖于学习率,而遗忘主要受学习率和数据集大小的共同影响。我们绘制了在batch size为128时,训练和测试损失的折线图,训练所用的是不同大小的子集。
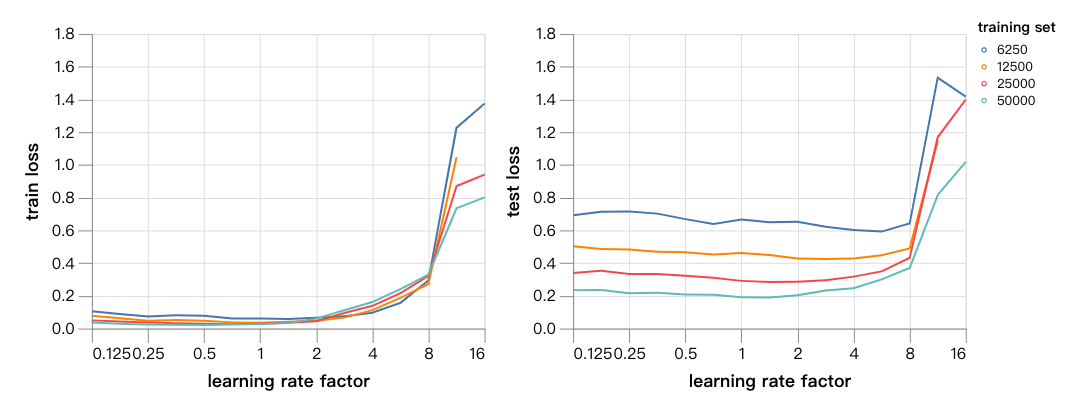
可以看到,首先,训练和测试损失都在学习速率为8的地方突然变得不稳定,这说明曲率影响在这里变得非常重要。相反,其他地方的训练和测试损失都很平稳。
如我们所料,优化学习速率因子(由测试集损失测定)和全部的训练数据集中的优化学习速率因子很接近。对于更小的数据集来说,优化学习速率因子更高。这也符合我们上面的假设:对于一个足够小的数据及来说,遗忘就不再是问题了,学习速率才是问题。对于更大的数据集,在遗忘的影响下,优化点会更低。
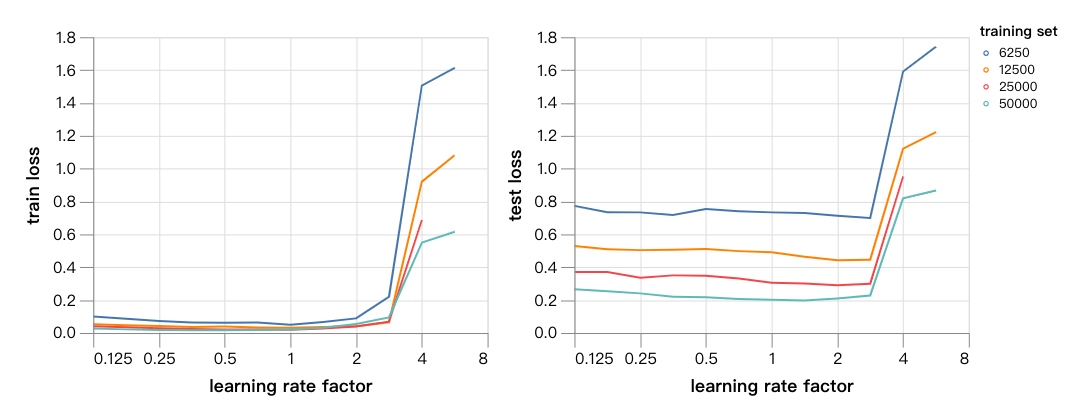
同样,在batch size为512的情况下,曲线图也很有趣。由于batch size比上方的大了4倍,曲线出现不稳定情况的速度更快了,当学习速率为2时即出现。我们仍然希望,学习速率因子的优化值和损失与128时的相近,因为遗忘并不对batch size产生影响。以下是得到的结果:
我们设置batch size=128,然后用一定学习速率训练,在前五个epoch中线性增加,之后达到固定的速率并继续训练25个epoch。我们在两个数据集上进行了比较:a)50%的完全训练集没有经过数据增强;b)全部数据都经过增强的数据集。当模型在b上运行时,我们将它停止,重新计算最后几个epoch的损失,这样做的目的是比较模型在最近的数据上得到的损失和此前数据上计算出的损失。
以下是学习速率是原始训练时4倍的结果:
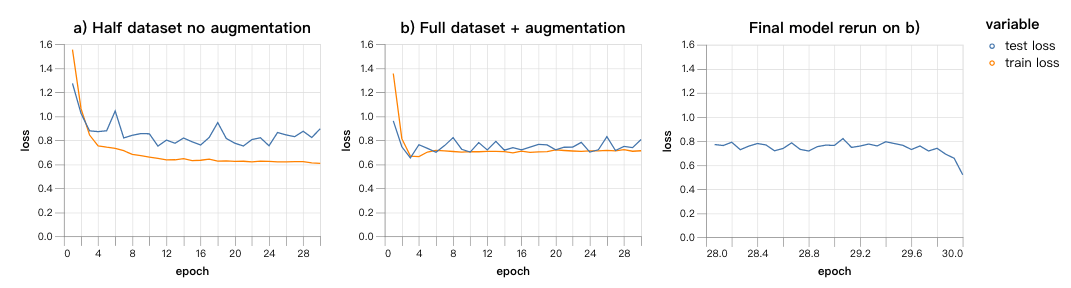
以下是原始训练是现在学习速率4倍的结果:
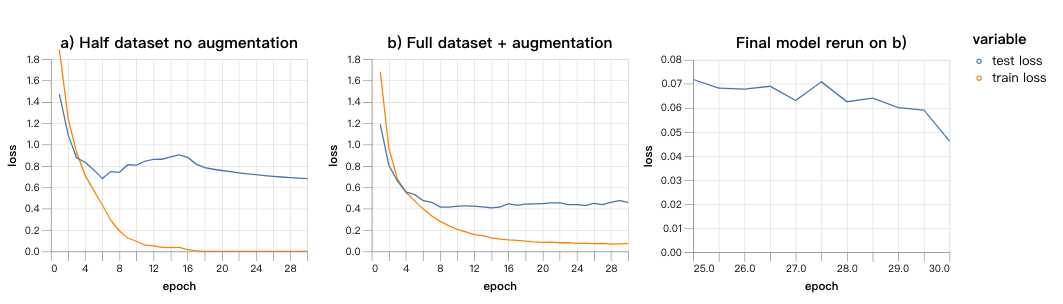
从第一组图表中,我们发现,与高学习速率相对应,测试损失几乎和模型在a、b上训练时的结果一样。这说明,训练无法从b和a中提取信息。右边的图也证明了这一结果,最近训练的batch表现出比此前的batch更低的损失,但是在半个epoch之内,损失又恢复到模型在从未见过的测试样本上的水平。这说明,模型忘记了在同一个epoch中它此前看到的东西,这也说明这一学习速率限制了它能吸收到的信息。
第二组图表表现出了相反的结果。全部经过数据增强的数据集导致了更低的测试损失,最近的训练batch比此前表现得更好。
结语
上述结果表明,如果我们想训练一个拥有较高学习速率的神经网络,那么就要考虑两点。对于目前的模型和数据集来说,在128的batch size下,我们不会受到遗忘的影响,要么可以找方法降低影响(例如用更大的、伴有稀疏更新的模型或者自然梯度下降),要么可以增大batch size。当batch size达到512时,曲率就开始影响结果,我们关注的重点应该转移到曲率上来。
对于更大的数据集,例如ImageNet-1k,遗忘的影响会更严重。这就能解释为什么在小的batch size、高学习率的训练中加速会失败。
在接下来的文章中,我们会加速批规范化,加入一些正则化,同时替换另一种基准。
原文地址:https://www.myrtle.ai/2018/09/24/howtotrainyourresnet_2

星标论智,每天获取最新资讯