【动态】第二届CSIG图像图形技术挑战赛季军团队介绍
赛道介绍
参赛方案
一、口罩数据生成
考虑到现有的一些生成口罩数据的方法,需要做3D人脸对齐(3DDFA)及人脸关键点检测。这种方法速度慢,影响训练速度,并且口罩类型有限,影响泛化效果。为了解决这些问题,团队采用了更简单有效的随机cutout的在线数据生成方法。这种在线数据生成方式具有速度快、口罩大小随机等特点,模拟了丰富的口罩样本。口罩增广的具体参数是:mask中心点选在(56,112),mask的宽高在[56,112]内随机采样,输入图片保持为112x112,从效果上可以看出,最大的模拟口罩会达到人脸的一半,而最小的模拟口罩只会遮住嘴部区域,如下图所示。另外团队还尝试了不同的口罩数量比例,从消融实验可以看出,增加口罩样本的比例,对测试集的效果有一定的提升。


二、模型结构
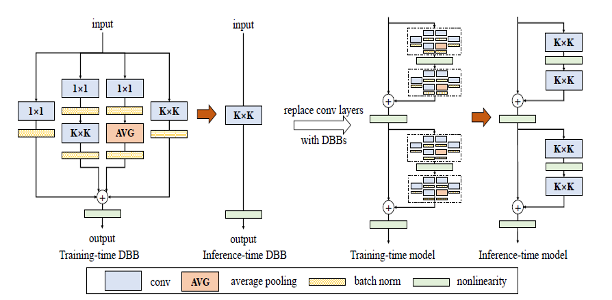
由于比赛有前向推理时间的的限制,需要在规定的推理时间内,构造一种对口罩人脸识别有效的模型。团队从模型的深度、注意力、重参数三方面进行分析,并设计了一种主干网络。其中模型的深度和重参数,可以提取丰富的人脸特征。注意力可以让提取到的特征集中在人脸的非口罩区域。主要的消融实验如下表所示。
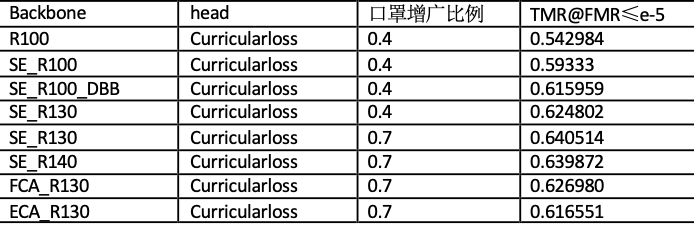
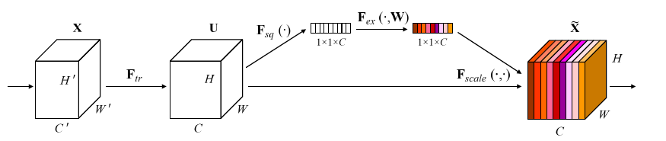
从前两行可以看出,SE注意力结构对模型效果的提升很明显。另外团队还尝试了不同的注意力模型,如FCA、ECA,针对本次比赛的测试集,效果相对SE都有所下降,但是要比不加注意力的效果好。说明在模型中加入注意力网络,能提到更有效的口罩人脸特征。SE注意力的结构如下图所示。
三、数据清洗
通过对训练数据进行分析,团队发现提供的训练数据有一些脏数据,如多个ID是同一个人,一个ID内有多个人以及一些非人脸的ID。这些脏数据会影响训练过程提取准确的特征。团队做了数据清洗的工作:采用复杂的网络在原始数据集上做了训练,用得到的模型,根据类内、类间、非人脸、以及类内样本较少等几方面做了清洗;用第一轮清洗后的数据,训练模型再做了第二轮清洗。这样经过两轮迭代清洗后,清洗掉了3700多ID、88000多图片,剩余的数据作为最后的训练集。结果证明数据清洗使效果得到了提升。
四、场景泛化
总结与展望
非常感谢视频国家工程实验室和中国图象图形学学会举办的权威的、专业的挑战赛事,在比赛中团队有机会和更多高水平战队以赛会友,促进交流学习,检验知识,锻炼队伍,凝聚精神。很荣幸在本次比赛中获得赛道第三名,并进入总决赛中获得了季军。再次感谢视频国家工程实验室和中国图象图形学学会举办的本次挑战赛。希望视频国家工程实验室和中国图象图形学学会多举办类似的高水准竞赛,带动团队继续技术创新之路。