总决赛冠军为磁共振图像脊柱结构多类别三维自动分割竞赛的Neuro204队。该赛道的目标是在三维磁共振图像中分割、识别出19类脊柱结构,其中包括10个椎骨和9个椎间盘,如下图所示。分割结果可为构建脊柱生物力学模型、模拟脊柱结构受力情况等提供量化分析工具,对脊柱退化性疾病的治疗具有重要意义。竞赛组织方提供172例有标注的训练数据,初赛阶段有20例测试数据,复赛阶段有23例测试数据。
![]()
团队提出了一种基于DeepLabv3+和可变形Transformer的三维图像多类别自动分割算法。
首先,使用DeepLabv3+的Encoder提取图像局部空间语义信息并构建可变形Transformer模块对提取的特征图全局上下文信息进行建模,然后通过提出的特征融合模块得到包含全局上下文信息以及局部语义信息的特征图,最后将此特征图输入到DeepLabv3+的Decoder中,从而获得最终分割结果。
由于可变形Transformer的注意力机制可关注特征图中的部分关键点而不是输入特征图上的每一个点,因此相比于普通Transformer时间和空间复杂度大大减少,使得其能够处理高分辨率三维特征图。
通过结合可变形Transformer的全局信息建模能力以及DeepLabv3+的多尺度局部空间信息提取能力可以有效的确保分类和分割的准确性。
此外,团队使用了针对性的数据增强策略,改善了训练集中各类别样本数量不平衡的问题。
一、卷积-Transformer混合网络结构的设计
团队提出了一种卷积-Transformer混合网络结构,可以有效利用卷积神经网络和Transformer对不同特征的提取能力进行3D医学图像分割,如下图所示。Transformer是一种序列到序列的预测框架,其中的自注意力机制可以根据输入内容动态调整感受野,在建模长期依赖方面优于卷积操作,因此有利于捕捉脊柱的空间排列顺序这一特征。DeepLabv3+能够有效提取局部多尺度上下文特征,可为脊柱分割任务提供丰富语义信息。该网络包含编码-解码结构,在编码器中,采用DeepLabv3+的编码器提取多尺度语义特征,基于提取的特征使用Transformer建模全局上下文依赖关系。
![]()
(a) 算法总流程图,主要包括基于DeepLabv3+的图片信息编码层,使用可变形Transformer建模全局上下文信息以及一个语义信息解码器以获得最终多类别分割结果。(b) 可变形Transformer模块。(c) 特征融合模块。
为了提高计算效率,团队引入了可变形的自注意力机制。这种注意力机制仅将注意力集中在小部分关键采样点上,从而大大降低了Transformer的时间空间复杂度。因此,Transformer可以处理DeepLabv3+生成的多尺度特征图,并保留丰富的高分辨率信息。进一步使用特征融合模块融合Transformer提取的全局上下文信息以及DeepLabv3+编码的丰富语义信息以获得最终解码特征。在解码器中,通过使用卷积网络解码提取的特征进行脊柱图像多类别准确分割。
团队的算法创新可归纳为以下三点:(1) 设计了一个卷积+Transformer的混合网络,在卷积网络中引入了Transformer编码层,解决了卷积网络因感受野有限而不能有效建模脊柱结构之间依赖关系的问题;(2) 针对普通Transformer计算量巨大的问题,引入可变形Transformer使得提出的算法能够处理多尺度和更高分辨的特征图;(3) 在Transformer编码层中设计了特征融合模块,有效融合DeepLabV3+编码的语义特征以及Transformer建模的全局上下文信息。
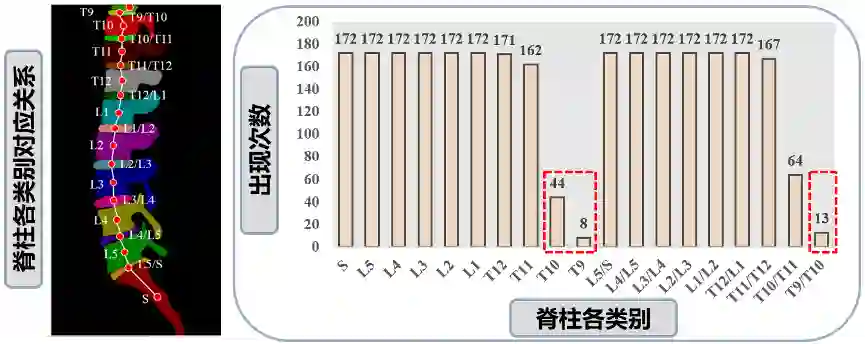
训练集中各类别样本数量严重不平衡,包含T9, T10,T9/T10这三个类别的图像分别仅占总样本量的4%、25%和7%,如下图所示。这导致这三类的分割结果在验证集中很不理想,单类准确率远低于其他类别的平均水平。为解决这一问题,团队对包含这三个类别的图片进行了针对性的手工裁剪,改变了训练图片中小样本类别的体积,从而构造了44张包含小样本类别的训练图片。团队用到的其他trick还包括:①在线数据增强,通过随机旋转-15°至15°、随机弹性变形、随机对比度调整等方法在线增强训练数据,提高模型的泛化能力;②学习率衰减策略,设置初始学习率为0.001并在90和144轮时将其调整为原来的0.2倍,从而使网络快速收敛到最优点;③提前停止,当验证集的评价指标停止增长时,及时停止训练,从而缩短训练时间。
![]()
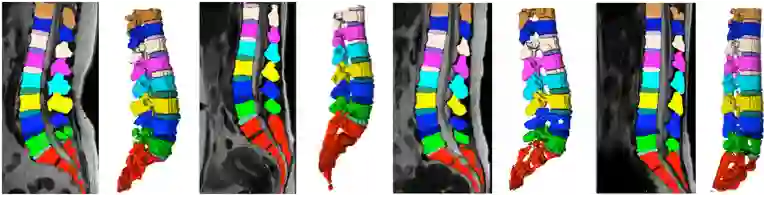
磁共振图像中脊柱结构包含多个类别(椎骨,椎间盘),下图中不同颜色代表脊柱结构不同的类别,可以看出本队提出的方法能够准确实现三维磁共振图像中脊柱结构的多类别分割。
![]()
参赛方案在三维磁共振图像中脊柱结构多类别分割结果示例
从下表可以看出,团队在小样本类别上取得较好的分割效果,在官方发布的多项指标中,本队Mean Score取得第一,小样本类别T9的分割效果优于其他队伍。
![]()
同赛道排名前五队伍的T9 Score及Mean Score
各队伍在小样本类别上的效果均不理想,因此如何提升小样本类别的分割效果是本次竞赛的关键之一。针对T9, T10等类别样本严重缺失的问题,团队使用针对性的数据增强(裁剪)策略增加小样本类别的样本数量,在一定程度上提升了这些类别的分割效果。受限于训练样本数量较少的问题,Transformer的性能并未得到很好的发挥。接下来团队拟探索使用伪标签增加小样本类别的数据量,并采用迁移学习的策略提高分割效果。
本团队依托机器人视觉感知与控制技术国家工程实验室。
另外,刘敏教授课题组(王耀南院士团队)诚聘模式识别、计算机视觉和机器人相关研究领域的博士后/教师人员,有意请联系汪嘉正(937145772@qq.com)。
![]()