微软亚洲研究院论文解读:GAN在网络特征学习中的应用(PPT+视频)
本文为 1 月 10 日,上海交通大学博士生、微软亚洲研究院实习生——王鸿伟在第 23 期 PhD Talk 中的直播分享实录。
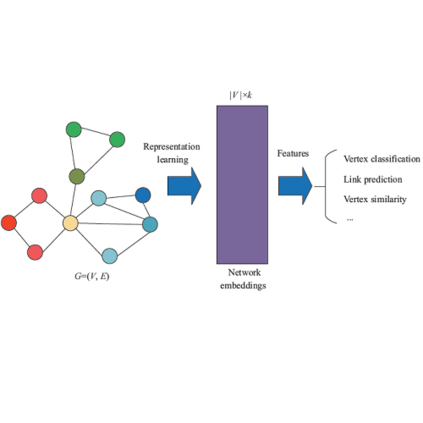
网络特征学习(network representation learning / network embedding)是近年来兴起的一个特征学习的研究分支。
作为一种降维方法,网络特征学习试图将一个网络中的节点映射到一个低维连续向量空间中,并在该低维空间中保持原有网络的结构信息,以辅助后续的连接预测、节点分类、推荐系统、聚类、可视化等任务。
在本期的 PhD Talk 中,来自上海交通大学的博士生王鸿伟,和大家一起回顾了近五年来网络特征学习领域的研究进展。
随后,他还以第一作者的身份,为大家解读了上海交通大学、微软亚洲研究院和香港理工大学在 AAAI 2018 上发表的工作:GraphGAN: Graph Representation Learning with Generative Adversarial Nets。该工作引入生成对抗网络(GAN)的框架,利用生成器和判别器的对抗训练进行网络特征学习。
最后,他还简单介绍了网络特征学习在情感预测和推荐系统领域的应用,这些工作是他以第一作者发表在 WSDM,CIKM,WWW 等数据挖掘国际顶级会议上的最新成果。
△ Talk 实录回放
Outline

本次直播主要分为三个部分。首先,我会为大家介绍 Graph Representation Learning 的定义、应用、分类方法和相关代表作。
第二部分,我将为大家介绍我们发表在 AAAI 2018 上的一篇论文 GraphGAN: Graph Representation Learning with Generative Adversarial Nets。
最后,我还将介绍我们在 Graph Representation Learning 领域的一些应用,包括推荐和情感预测。
上图底部是三份比较有价值的资料,第一份是 Graph Embedding 的 Survey,第二份是一个论文清单,其中包含近五年来较为经典的 Network Representation Learning 相关论文。第三份是我写的关于推荐系统和网络表示学习的文献综述,欢迎大家参考。
关于GRL
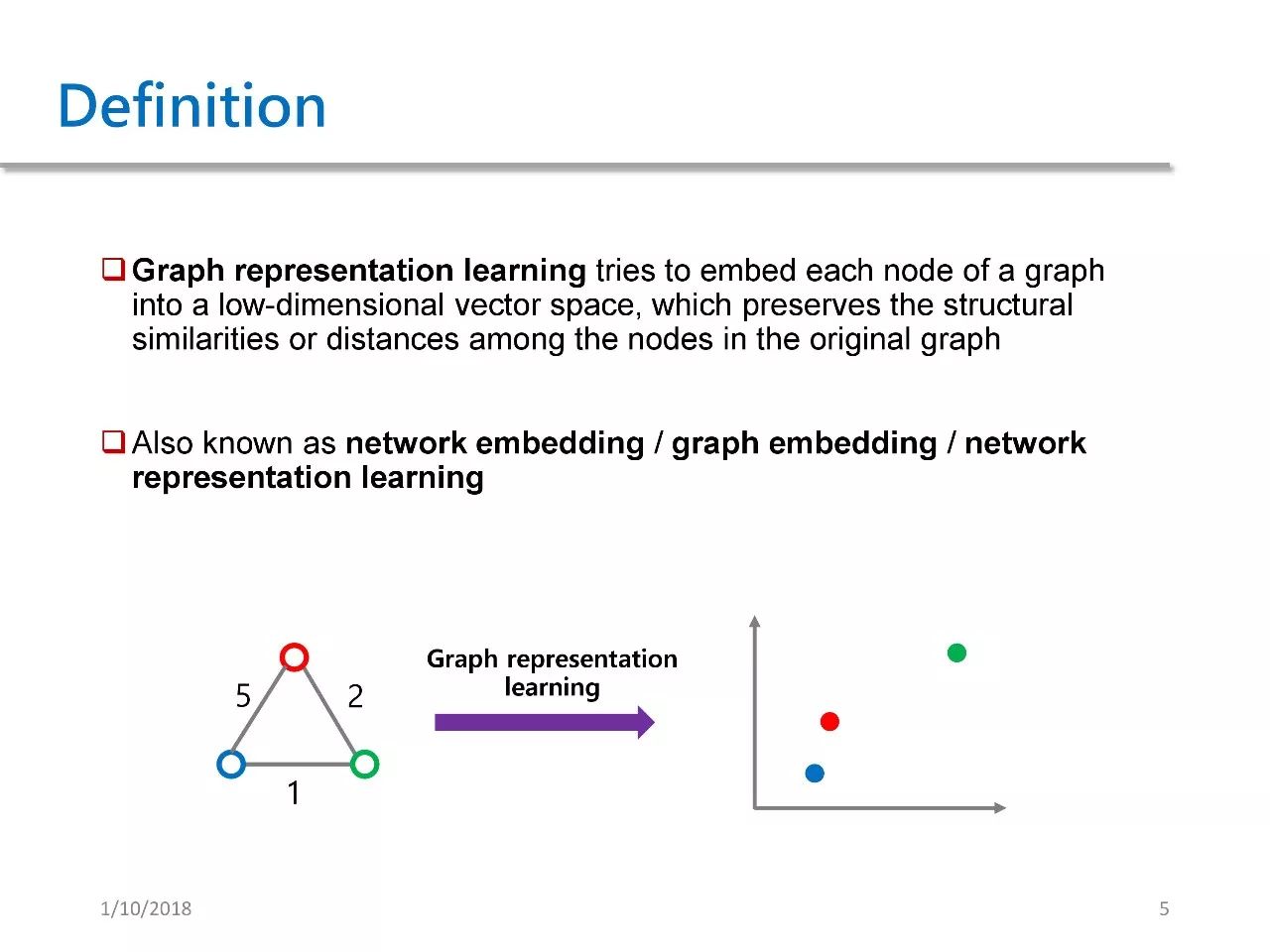
首先简单介绍一下 Graph Representation Learning 的定义,中文可以称之为图特征学习或者网络特征学习。其主要目的在于,将图中每一个节点都映射到一个低维向量空间,并且在此空间内保持原有图的结构信息或距离信息。
以上并非官方权威定义,Graph Representation Learning 目前没有任何官方定义或名字,它也可以被称作 Network Embedding、Graph Embedding 或 GRL。
我们来看上图中的简单例子,左图有三个节点和三条边,其中的数字表示各边的权值 weight,我们通过 GRL 将其映射到一个二维空间中。可以发现,如果两个点之间的 weight 越大,那么它们之间的距离就越近。这就是 GRL 的精髓所在,即在低维空间中保持原有图的结构信息。

Graph Representation Learning 的应用相当广泛,它可以被用于链路预测、 节点分类、推荐系统、视觉、知识图谱表示、聚类、Text Embedding 以及社会网络分析。
GRL分类方法

我们将 GRL 的方法按照三种不同分类来进行简单介绍。
首先按输入进行分类,既然是 GRL,那么其输入肯定是一张图,但图的种类有很多:
第一种叫同构图,即图中的节点和边都只有一种,比如引用网络,其中的节点表示每篇 paper,边表示引用关系。同构图又可以根据是否有加权进行细分,即其边是否权值、边是否有向,以及边是否有正负号。
第二种是异构图,即网络中的节点和边不止一种,一般分为两种情况:
1. 多媒体网络。比如有的 paper 就考虑过一张图具备图像和文本两种节点,以及图像文本、图像图像和文本文本这三种边。
2. 知识图谱。图中节点表示的是实体,边表示的关系。每一个三元,HRT 都表示头节点 H 和尾节点 T 有关系 R。由于关系 R 可以有很多种,因此 KG 也属于一种异构图。
第三种是 Graph with side information,side information 即为辅助信息。这种图是指除了边和点之外,节点和边都会带有辅助信息,比如边和点都有 label,边和点都有 attribute,或者 note 有 feature。
它们的区别在于 label 是类别型的,attribute 可以是离散的,也可以是连续的,而 feature 就可能是文本或图像等更复杂的一些特征。
第四种是 Graph Transformed from non-relational data,即从非关系型数据中转换成的图,一般是指在高维空间中的一些数据。这通常是早期 GRL 方法会用到的数据,其中最为典型的例子是稍后还将提到的流形学习,我们可以将这种方法理解为一种降维方法。

按输出内容我们也可以对 GRL 方法进行分类。
第一种方法会输出 node embedding,即为每个节点输出 embedding,这也是最常见的一种输出。我们前面说到的那些方法基本上都是输出 node embedding。
第二种方法是输出 edge embedding,即为每个边输出 embedding。这种输出有两种情况,一种是在 KG 里面,我们会为每一个 relation,也就是每条边都有输出。在 link prediction 的应用中,我们也会为每一条边来输出一个特征,并在后续工作中将其作为边的特征来进行一些分类任务。
第三种方法会输出 sub-graph embedding,也就是子图的 embedding,包括子结构或团体的 embedding。
第四种是全图的 embedding,即为一个整图来输出 embedding。如果我们对蛋白质、分子这类数量较多的小图进行 embedding,就可以对比两个分子的相似性。

第三种分类方法是按照方法来进行分类。
第一种方法是基于矩阵分解。一般来说矩阵分解包含奇异值分解和谱分解,谱分解就是我们常说的特征分解,这种方法是比较传统的方法。
第二种方法是基于随机游走。这种方法盛名在外,我们后面会提到的 Deep Walk 就是基于随机游走的方法。
第三种方法是基于深度学习。其中包括基于自编码器以及基于卷积神经网络。
第四种方法是基于一些自定义的损失函数。这其中又包括三种情况,第一种是最大化边重建概率,第二种是最小化基于距离的损失函数,第三种是最小化 margin-based ranking loss,这种方法常见于 KG embedding。
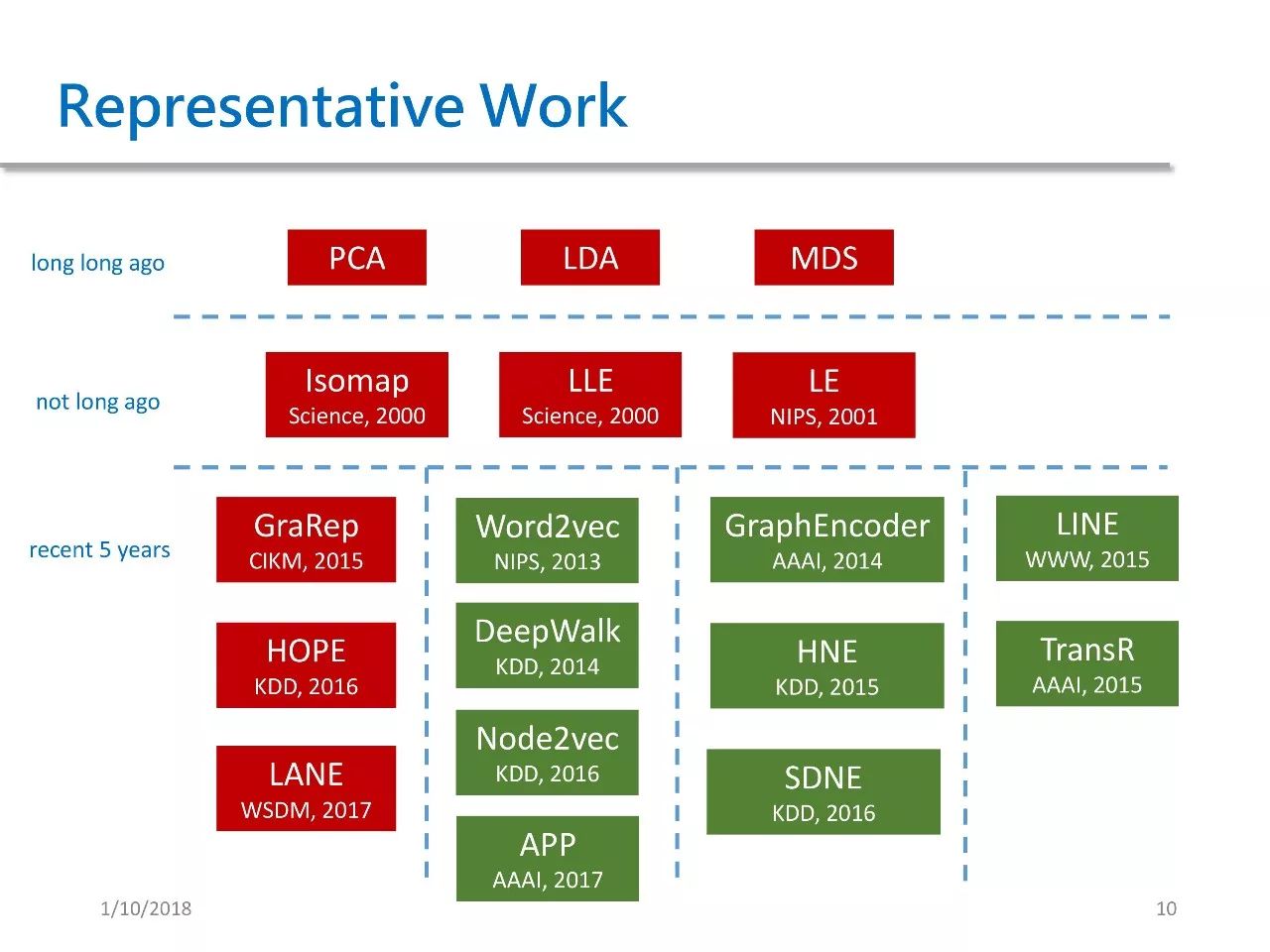
上图是我整理的 GRL 方法代表作。按照时间顺序可将它们分为三类,第一类是传统方法,包含 PCA、LDA、MDS 等降维方法。
2000 年左右出现了一批较为经典的方法,包括 ISOMAP 同态映射,LLE 局部线性镶嵌,LE 拉普拉斯特征分解。
最近五年被提出的方法也有很多,我将它们分作四类,每类都和上文提到的按方法分类逐一对应。

LDA 线性判别分析是一种传统的有监督降维方法。我们可以看到,右图里面有两类点,有正号表示的一类和有负号表示的一类。
我们需要将二维的点映射到一维上去,LDA 的目标在于让这些投影相同类的点在投影过后,同类的点之间距离尽可能变近,即让它们的协方差尽可能小,而不同类的点之间的距离尽可能远。只有这样,它才能在低维空间中对这些点进行分类或聚类操作。
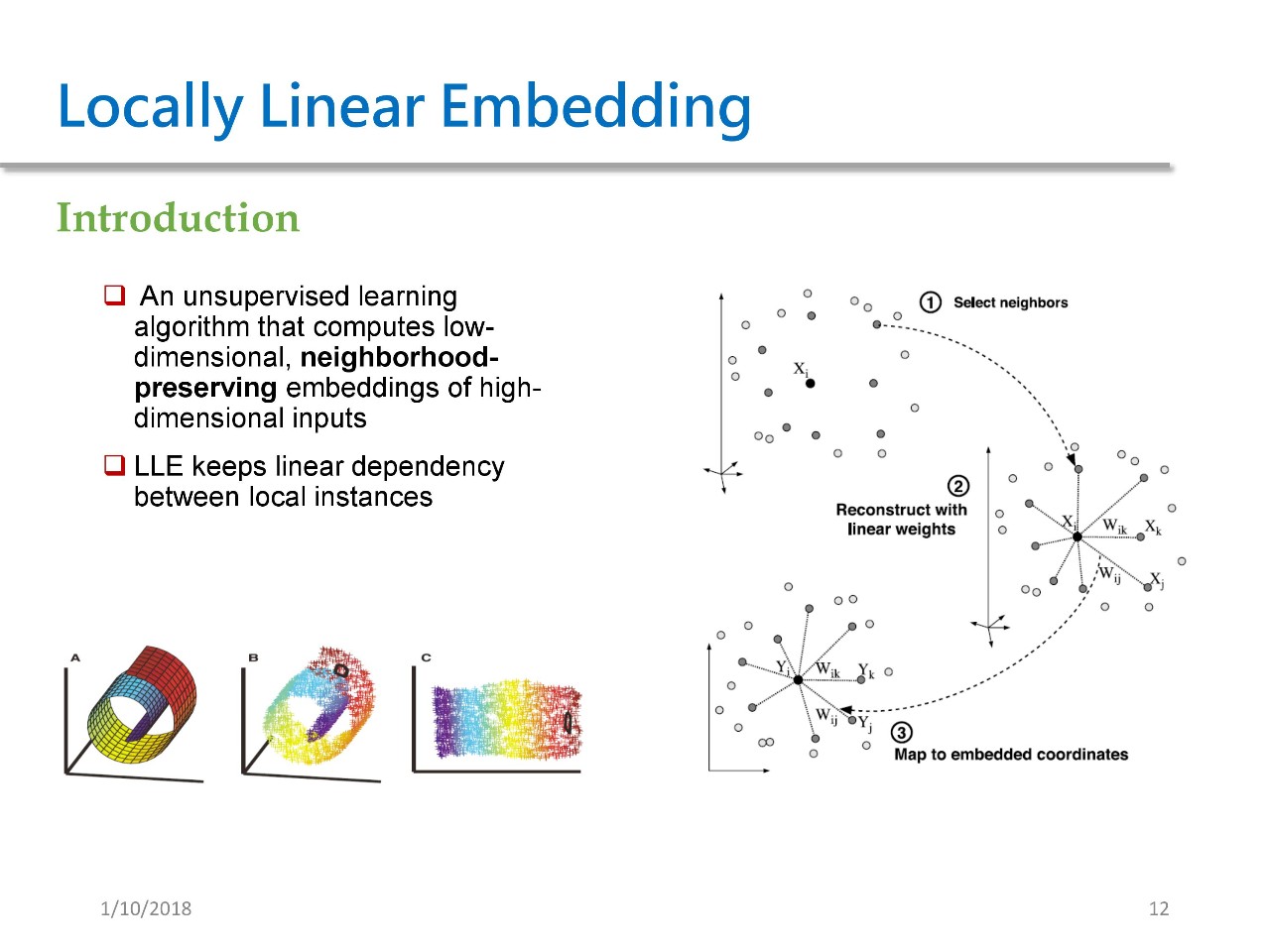
Locally Linear Embedding 是一种典型的流形学习方法,它是指将高维空间中的输入映射到低维空间,并且在低维空间中保持邻居之间的线性依赖关系。
左下图就是一个很典型的流形学习,流形指的是在高维空间中存在某些低维结构,比如说图 A 很像一个瑞士卷,它其实就是一个典型的在三维空间中的二维结构。通过 LLE 我们将其展成一个二维结构。
这种方法的目的在于保持高维空间中的邻居信息。其具体做法如下:对于每一个点 Xi,首先需要确定其邻居集合,然后再来计算 Wik Wij 这些参数。这些参数的意思是,我想用这些邻居来重新构建 Xi,这个会有唯一的解析解。在拿到 W 参数之后,我们再在低维空间中用 W 进行约束,学习得到低维的一个 embedding。

Word2vec 的本质其实是 word embedding,不是 network embedding。但由于它对后续的 network embedding 方法影响深远,所以我们来简单介绍一下。
Word2vec 中有一个 skip-gram 模型,这个模型的本质在于为每个词得到一个特征,并用这个特征来预测周围的词。因此,其具体方法就是将概率最大化。这个概率是指,给定一个中心词 WT,在以它为中心、窗口为 T 的范围中的每个词的概率。
这个概率实际上是使用 softmax 进行计算的。由于 softmax 开销很大,我们通常会用 negative sampling 来进行代替。negative sampling 是指为每个词从整个词表中选择一些 negative samples,把他们作为负样本。
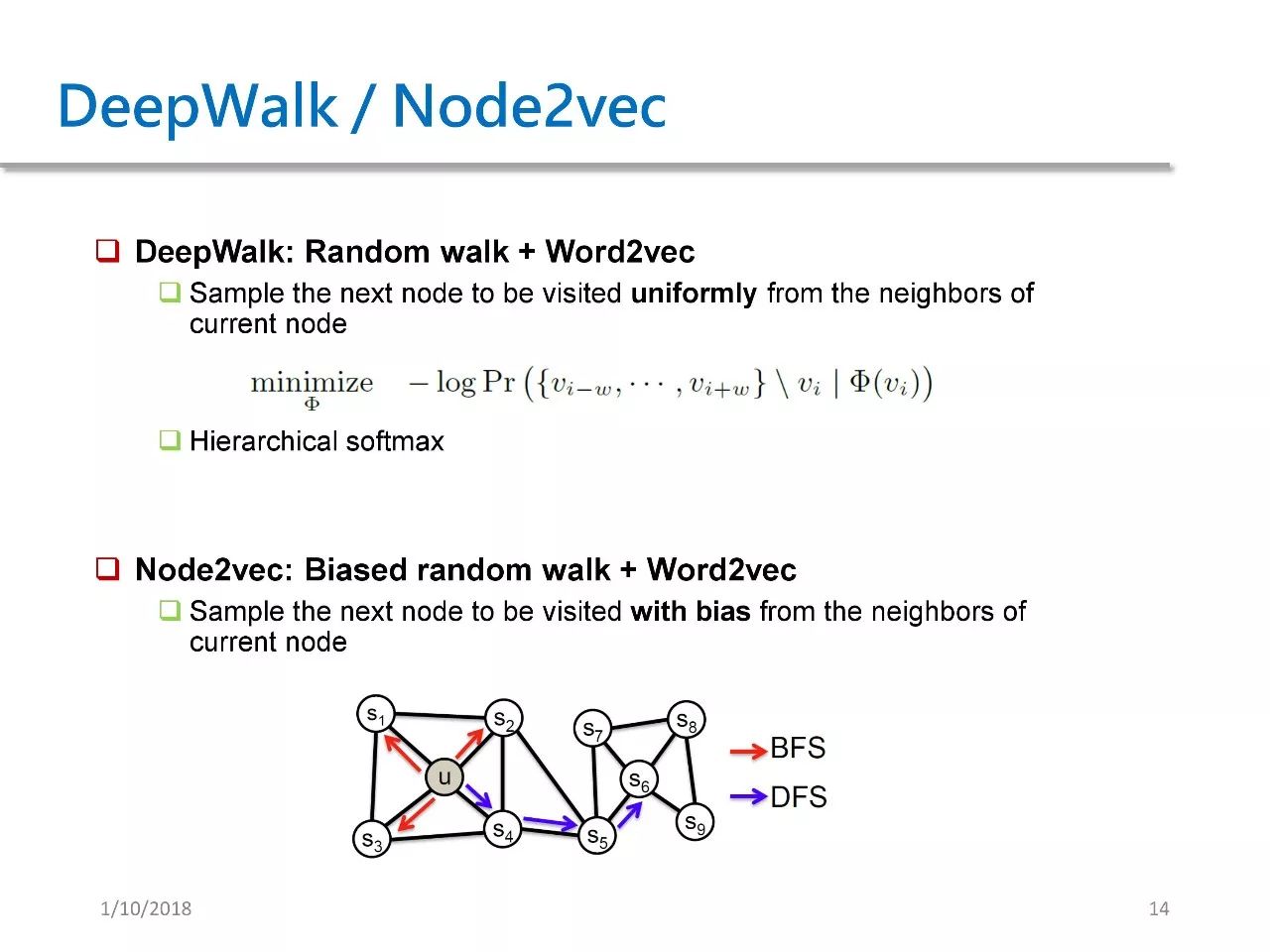
Word2vec 在 Nerwork Embedding 中有两篇很典型的工作,分别是 DeepWalk和 Node2vec。这两篇工作分别发表于 KDD 14 和 KDD 16。
DeepWalk 相当于 random walk + word2vec。从图中的每个节点出发,随机进行 random walk,从当前节点均匀、随机地选择下一个节点,然后再从下个节点均匀、随机地选择下一个节点。
这样重复 N 次之后会得到一个 path,这个 path 就可以被当做一个 sentence。这样一来,就将问题完全转换到了 Word2vec 的领域。
大家可能会问,这个方法岂不是很简单?不就是把 Word2vec 用到了 network embeddding 吗?
对的,就是这么简单。有时候 research 并不会过分强调你的方法有多新颖、数学有多花哨,而在于你能不能提出一种 motivation 够强、动作够快的方法。
Node2vec 在 DeepWalk 的基础上又做了改进。它把原来的 random walk 改成了 biased random walk。
在 DeepWalk 里,我们是均匀地选择下一个节点。但在 Node2vec 里,则是不均匀地选择下一个节点。我们可以选择模仿 DFS 不断往图的深处走, 也可以模仿 BFS 绕着一个点打转。因此,Node2vec 相比 DeepWalk 也就是新增了一个简单改进。
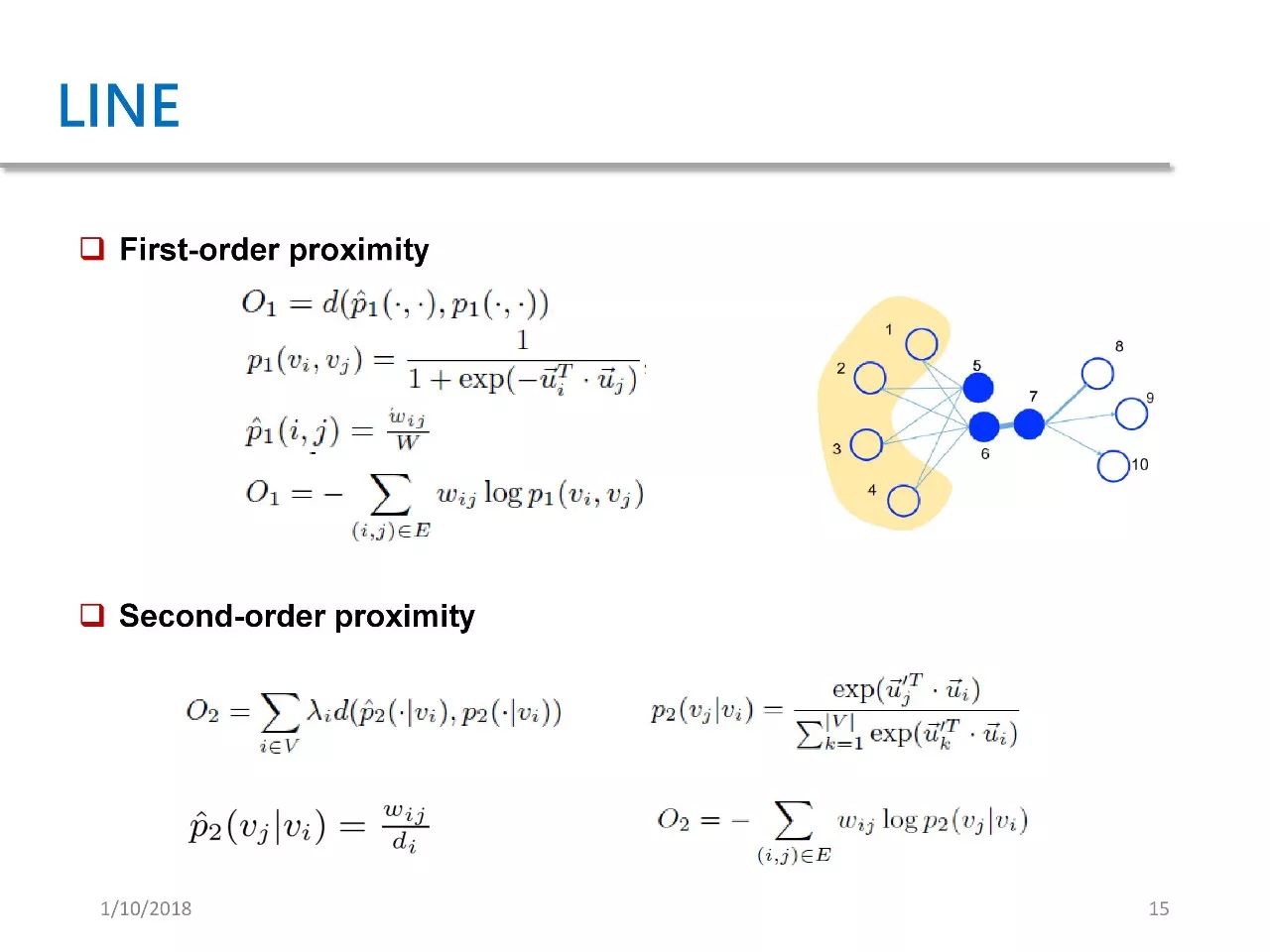
LINE 的全称是 Large-scale Network Information Embedding。这篇文章发表于 WWW 15。这个工作属于我们之前提到的自定义损失函数,因为它定义了两种损失函数,一种是一阶的临近关系,另一种是二级临近关系。
所谓的一阶临近关系就是指两个点之间是否只有相连。在右图中我们可以看到,点六和点七之间有边相连,那就可以认为它们拥有一阶临近关系。
二阶关系是指两个点的邻居的相似度。右图中点五和点六虽然没有直接相连,但它们的邻居是完全重合的,因此可以认为点五和点六的二阶临近关系很强。基于这样一种临近关系,LINE 定义了两个损失函数 O1 和 O2,然后基于这两个损失函数来进行 network embedding 的学习。

TransX 表示一系列方法,X 可以指代任何字母,这些方法都是基于 KG embedding。KG embedding 是指将 KG 中的每个 entity 和 relation 都映射到一个低维连续空间中,并且保持原来的图结构信息。比较经典的方法有 TransE、TransH 和 TransR,统称为基于翻译的方法。
TransE 思路很简单,就是强制让 Head Embedding + relatioon embedding = tail embedding。换而言之,也就是把 head 加 relation 给翻译成 tail。由于这篇文章发表于 NIPS 13,因此它后续又引出了一大波 TransX 的方法。大家可以去看上图底部的这篇 survey,至少有 10 篇左右。
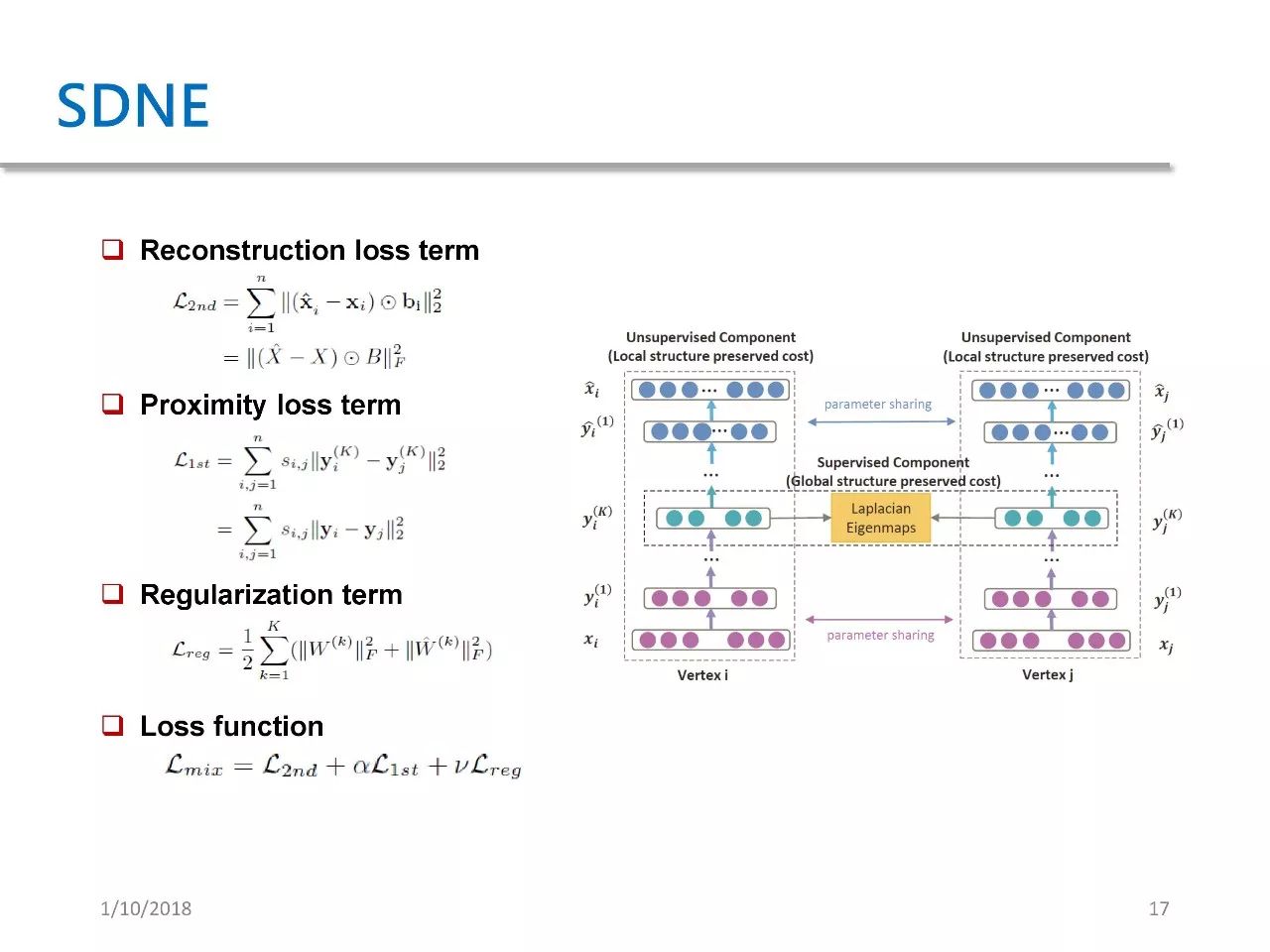
最后一篇是 SDNE,全名为 Structured Deep Network Embedding。这篇文章发表于 KDD 15,其本质就是基于 auto encoder 的一种 network embedding。
尽管右图看着比较复杂,其实它的思路非常简单。作者设计了一个 auto encoder,其输入是每个点的邻接向量。
损失一共有三项,第一项是重建损失,第二项是 proximity loss term,意思是如果两个节点有边连接,那它们的 embedding 必须尽量接近,具体接近程度取决于它们的权重。weight 越大,那么对这项损失的惩罚力度就越大。第三项是正则化项。
GraphGAN
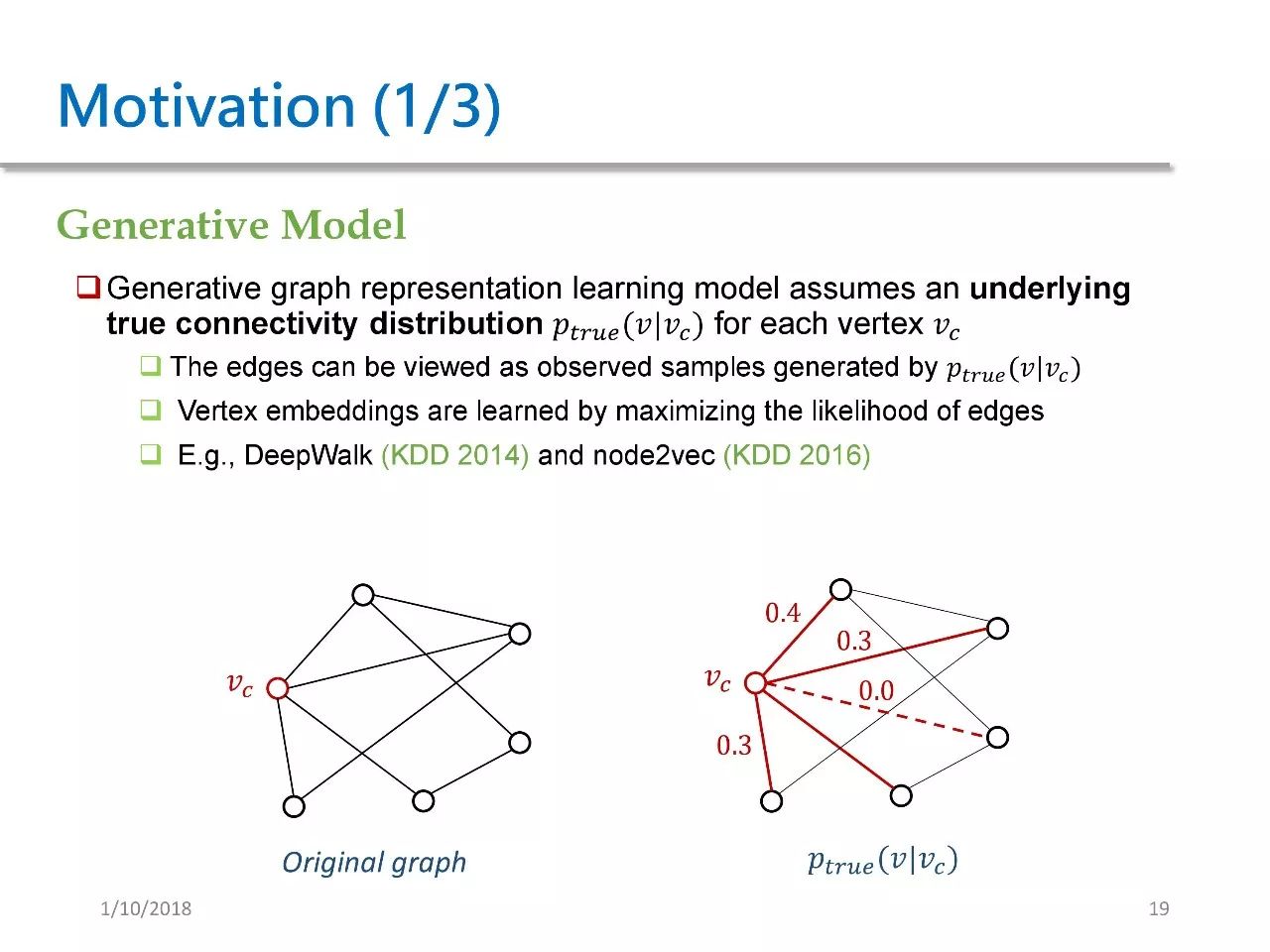
前文将 Network Embedding 的方法归为三类,而我们在 GraphGAN 里将其分为两类,第一类叫生成式模型,第二类叫判别式模型。
生成式模型是指,假定在图中存在一个潜在的、真实的连续性分布 Ptrue(V|Vc)。对于给定的 Vc 而言,我们可以看到 Vc 跟四个节点相连接,图中除了 Vc 之外还有五个节点。Ptrue(V|Vc) 就是指在除了 Vc 之外其他节点上的分布。
假设图中对于每个 Vc 都有这么一个分布,那么图中的每条边都可以看作是从 Ptrue 里采样的一些样本。这些方法都试图将边的似然概率最大化,来学习 vertex embedding。我们之前提到的 DeepWalk 和 Node2vec 都属于生成式模型。

判别式模型是指,模型试图直接去学习两个节点之间有边的概率。这种方法会将 Vi 和 Vj 联合作为 feature,然后输出的是 edge 的概率 P(edge|Vi, Vj)。这种方法的代表作是 SDNE,以及 DASFAA 上的一篇 PPNE。
这样分类之后,一个很自然的想法是,判别式模型和生成式模型能否进行联合。这两者其实可以看作是一个硬币的两面,他们是相互对立又相互联系的。

之前提到的 LINE 其实已经对此进行了尝试。文中提到的一阶关系和二阶关系,其实就是两个模型的不同目标函数。
生成对抗网络自 2014 年以来得到了很多关注,它定义了一个 game-theoretical minimax game,将生成式和判别式结合起来,并且在图像生成、序列生成、对话生成、信息检索以及 domain adaption 等应用中都取得了很大的成功。
受以上工作启发,我们提出了 GraphGAN,它是一个在网络生成学习中将生成模型和判别模型加以结合的框架。

接下来为大家介绍 Mnimax Game。其中 V 是节点集合,E 是边集合,我们将 N (Vc) 这个记号定义为 Vc 在图中的所有邻居,将 Ptrue (Vc) 定义成 Vc 的真实的连续性分布。
GraphGAN 试图学习以下两个模型:第一个是 G(V|Vc),它试图去接近 Ptrue (Vc)。第二个是 D(V|Vc),它的目标是判断 V 和 Vc 是否有边。
因此,我们会得到一个 two-player minimax game。这个公式是本文的关键所在,只有充分理解这个公式,才能继续之后的理解。
在这个公式中,我们做了一个 minimax 操作。在给定θD的情况下,我们试图对其进行最小化,这个公式其实是对图中每一个节点的两项期望求和。

下面来看生成器的实现和优化。在 GraphGAN 中,我们选了一个非常简单的生成器,生成器 D(V, VC) 就是一个 sigmoid 函数,它先将两者的 embedding 做内积,再用 sigmoid 函数进行处理。对于这样的实现,它的梯度自然也较为简单。
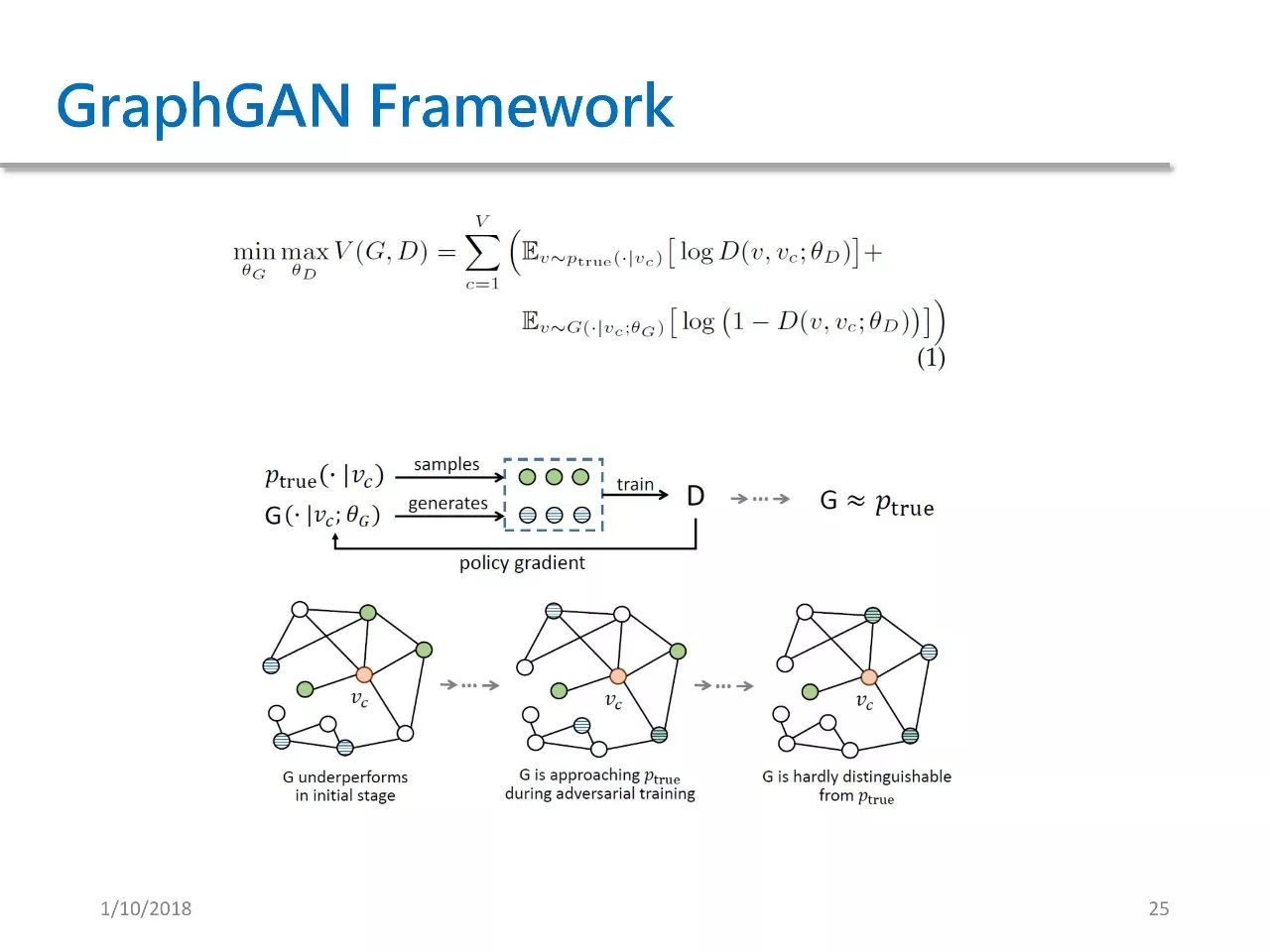
通过上图可以看出,我们在每一步的迭代中,从 Ptrue 中 sample 出来了一些跟 Vc 真实相邻的绿点,然后从 G 中又生成了一些跟 Vc 相连的蓝点。我们将绿点作为正样本,将蓝点作为负样本来训练 D,在得到 D 之后,再用 D 中的信号去反过来训练 G。
这就是之前所说的 policy gradient 过程。我们不断重复这个过程,直到生成器 G 和 Ptrue 极为接近。
在刚开始的时候,G 相对比较差,因此对于给定的 Vc 而言,G sample 的点都是一些离 Vc 很远的点。随着训练的不断进行,G sample 的点会逐渐向 Vc 接近,到最后 G sample 的点几乎都变成了真正跟 Vc 相邻的点,也就是 G 和 Ptrue 已经很难被区分了。

接下来,我们来讨论一下 G 的实现过程。一种最直观的想法是用 softmax 来实现 G,也就是将 G(v|VC) 定义成一个 softmax 函数。
这种定义有如下两个问题:首先是计算复杂度过高,计算会涉及到图中所有的节点,而且求导也需要更新图中所有节点。这样一来,大规模图将难以适用。 另一个问题是没有考虑图的结构特征,即这些点和 Vc 的距离未被纳入考虑范围内。
第二种方法是使用层次 softmax,具体来说就是组织了一棵二叉树,然后将所有节点都放在叶节点的位置,再将当前的 Vc 从根开始计算。
由于从根到每个叶结点都存在唯一路径,因此这个计算可以转换成在树的路径上的计算,即它的计算复杂度为 logN ,N 代表树的深度。这种做法虽然可以简化计算,但它仍然没有考虑到图结构特征。
第三种方法是 Negative Sampling。这种方法其实是一个优化方法,它并没有产生有效的概率分布,并且同样没有考虑图的结构特征信息。

在 GraphGAN 中,我们的目标是设计出一种 softmax 方法,让其满足如下三个要求。第一个要求是正则化,即概率和为 1,它必须是一个合法的概率分布。第二个要求是能感知图结构,并且能充分利用图的结构特征信息。最后一个要求是计算效率高,也就是 G 概率只能涉及到图中的少部分节点。

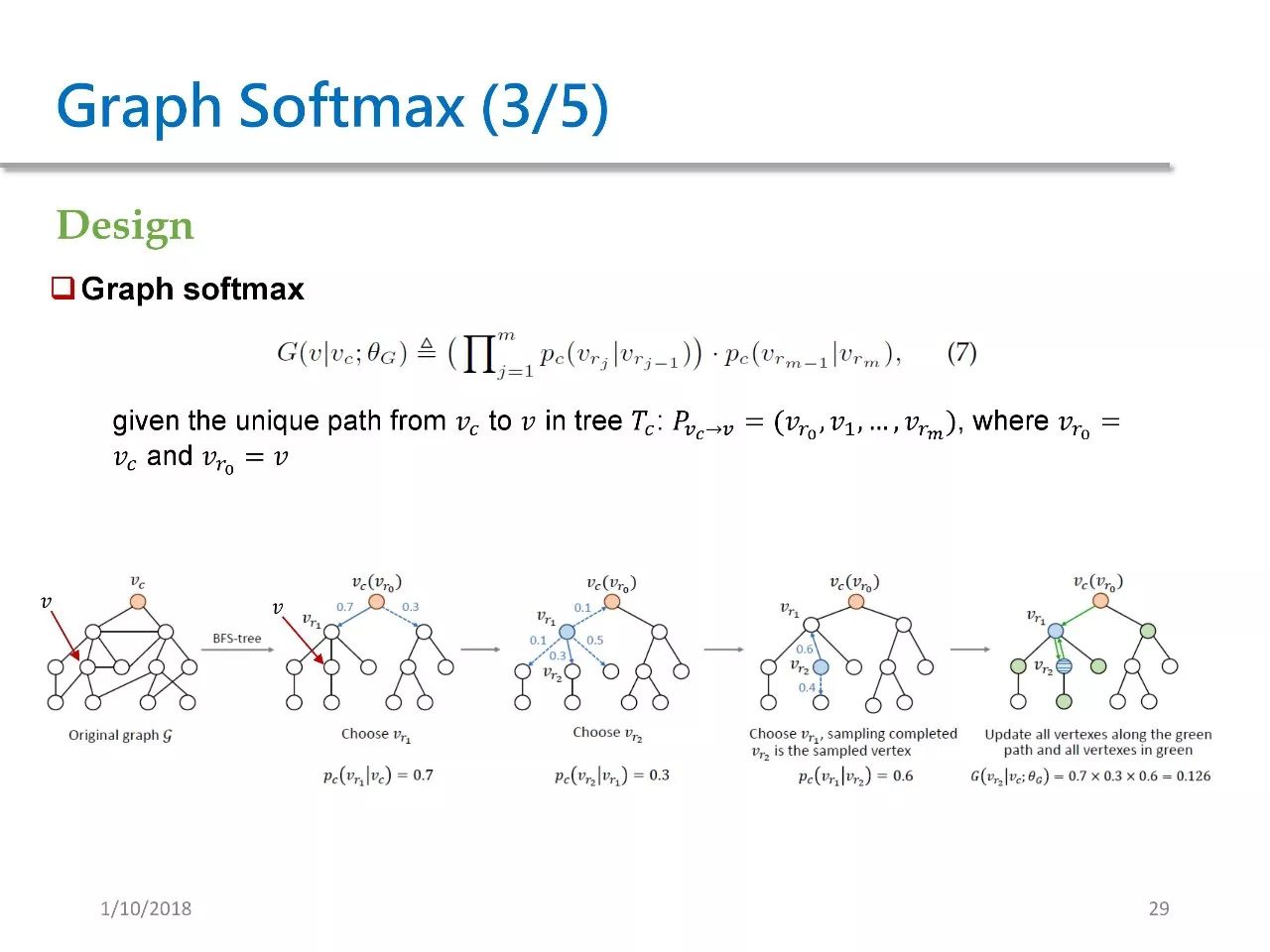
对于每个给定的结点 Vc,我们都需要以 Vc 为根来进行一次 BFS 宽度优先搜索,然后得到一颗以 Vc 为根的 BFS tree。对于这棵树上的每一个节点,我们都定义了一个 relevance probability。实际上是一个在 Vc 的邻居上的 softmax。

我们可以证明如下三个性质:
1. graph softmax 的概率和是1;
2. 在 graph softmax 中,两个节点在原图中的距离越远,那么它们的概率也随之越低。这其实就是充分利用了图的结构特征,因为两个节点在原图中的最短距离越远,它们之间有边的概率也会相应越低;
3. 在 graph softmax 的计算中,计算只会依赖于 O(d log V)。d 是图中每个节点的平均度数,V 是图 G 中的节点大小。这个数字会明显小于 softmax 的复杂度。
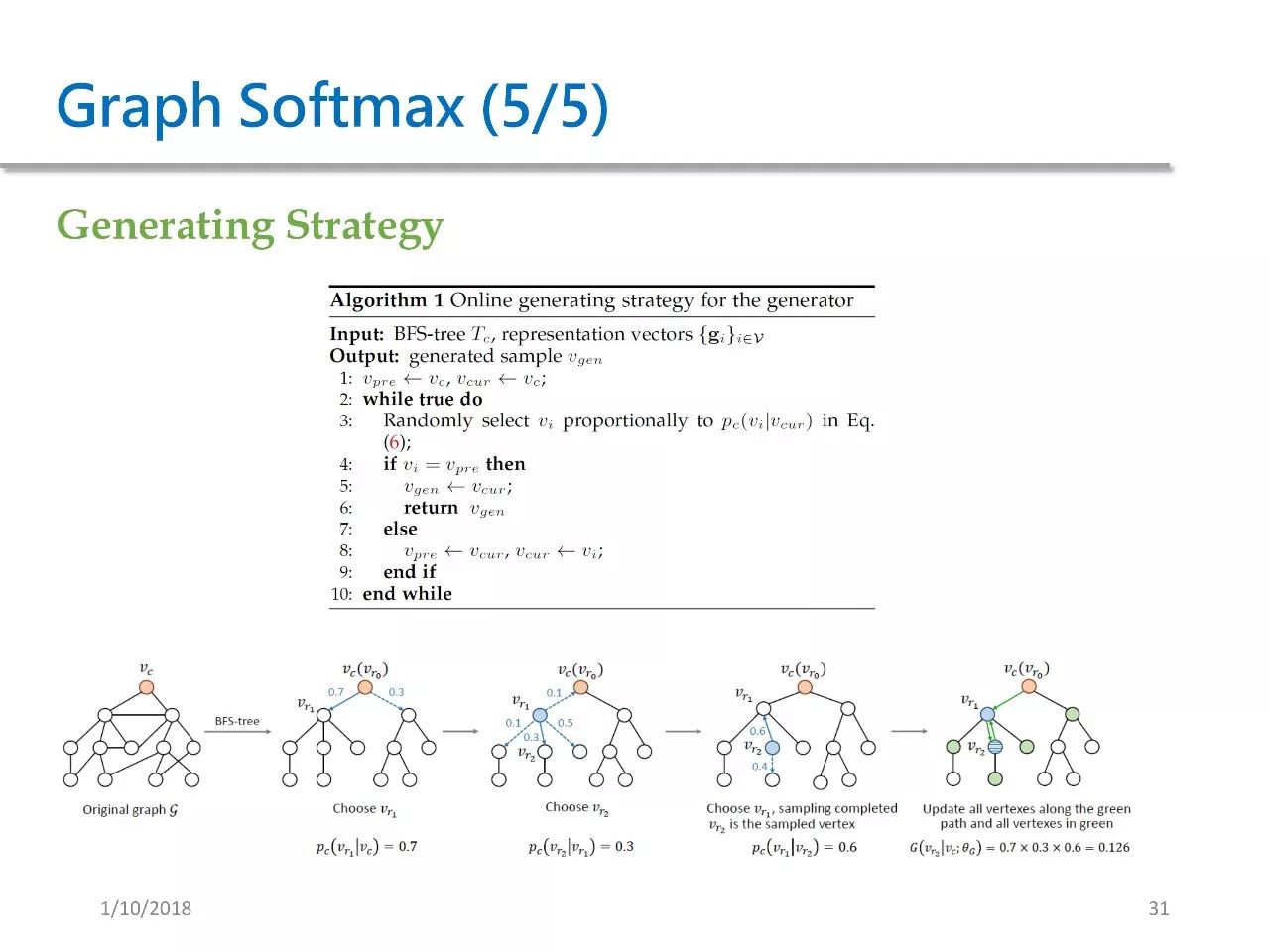
我们还相应设计了一种生成策略。这种这种生成策略并不需要将所有概率都算出来后再进行 sample,而是可以边计算边 sample。

GraphGAN 的算法如上,输入是一些超参数,我们想输出生成式模型 G 和判别式模型 D。第 3-12 行是算法的每一次迭代过程。在每一次迭代过程中,我们都重复用生成器来生成 s 个点,并用这些点来更新 θG 的参数。
随后,再重复构造正负样本来训练 D,这样做是出于稳定性的考虑。因为我们知道 GAN 的训练稳定性是一个重要问题。
实验

我们的实验数据集一共是如上五个。Baseline 选用的是DeepWalk,LINE,Node2vec 和 Struc2vec。
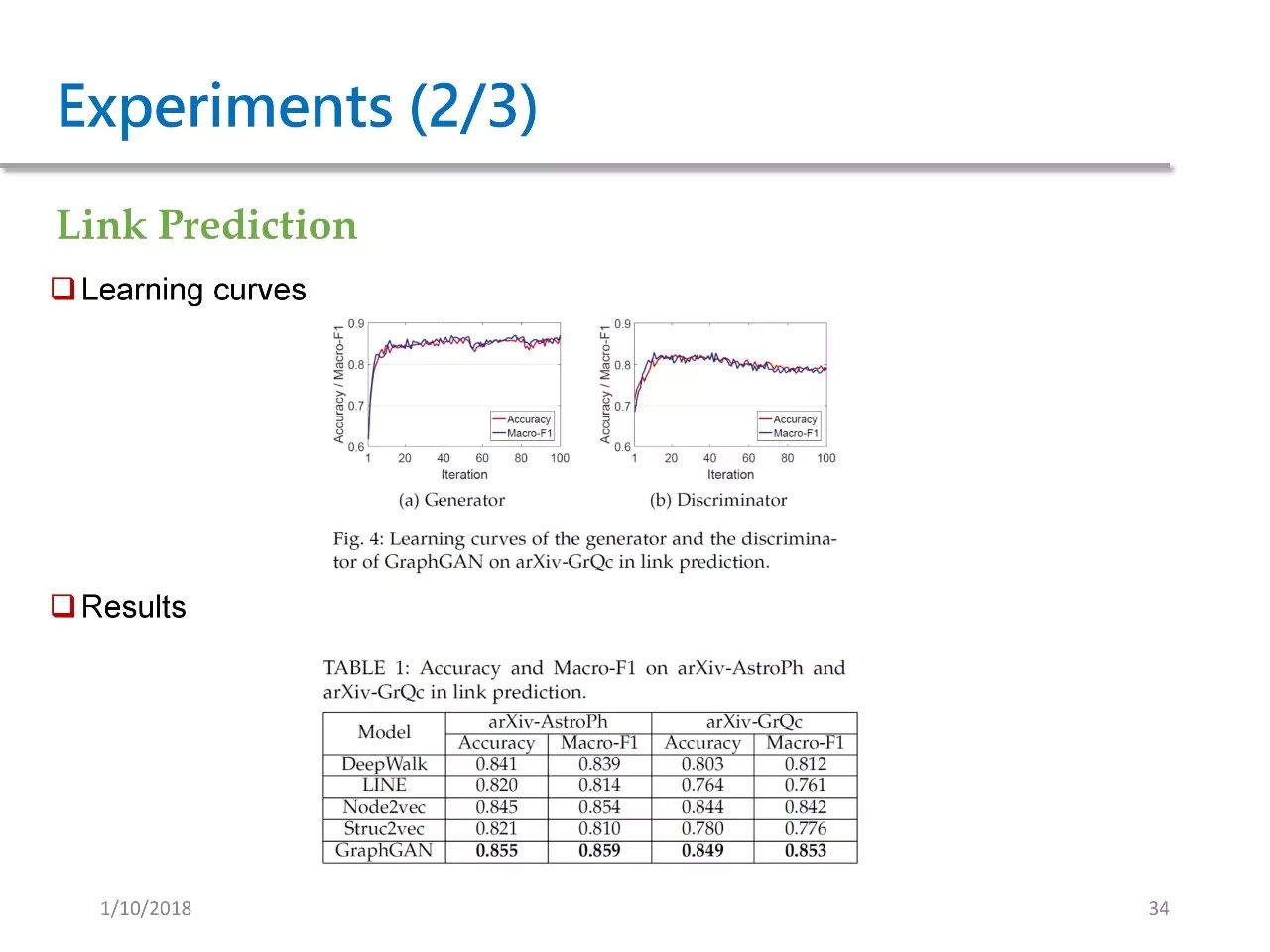
我们将 GraphGAN 用到了如下三个测场景中,第一个是 link prediction,预测两个点之间是否有边的概率。图 4 展示的是 GraphGAN 的学习曲线,对于生成器而言,在训练大概十轮之后就很快趋于稳定,并且后续一直保持性能。
对于 D 来说,它的性能是先上升,之后出现缓慢的下降。这和我们之前所描述的 GAN 框架也是相吻合的。表 1 展示了 GraphGAN 在两个数据集上都得到了最好的结果。
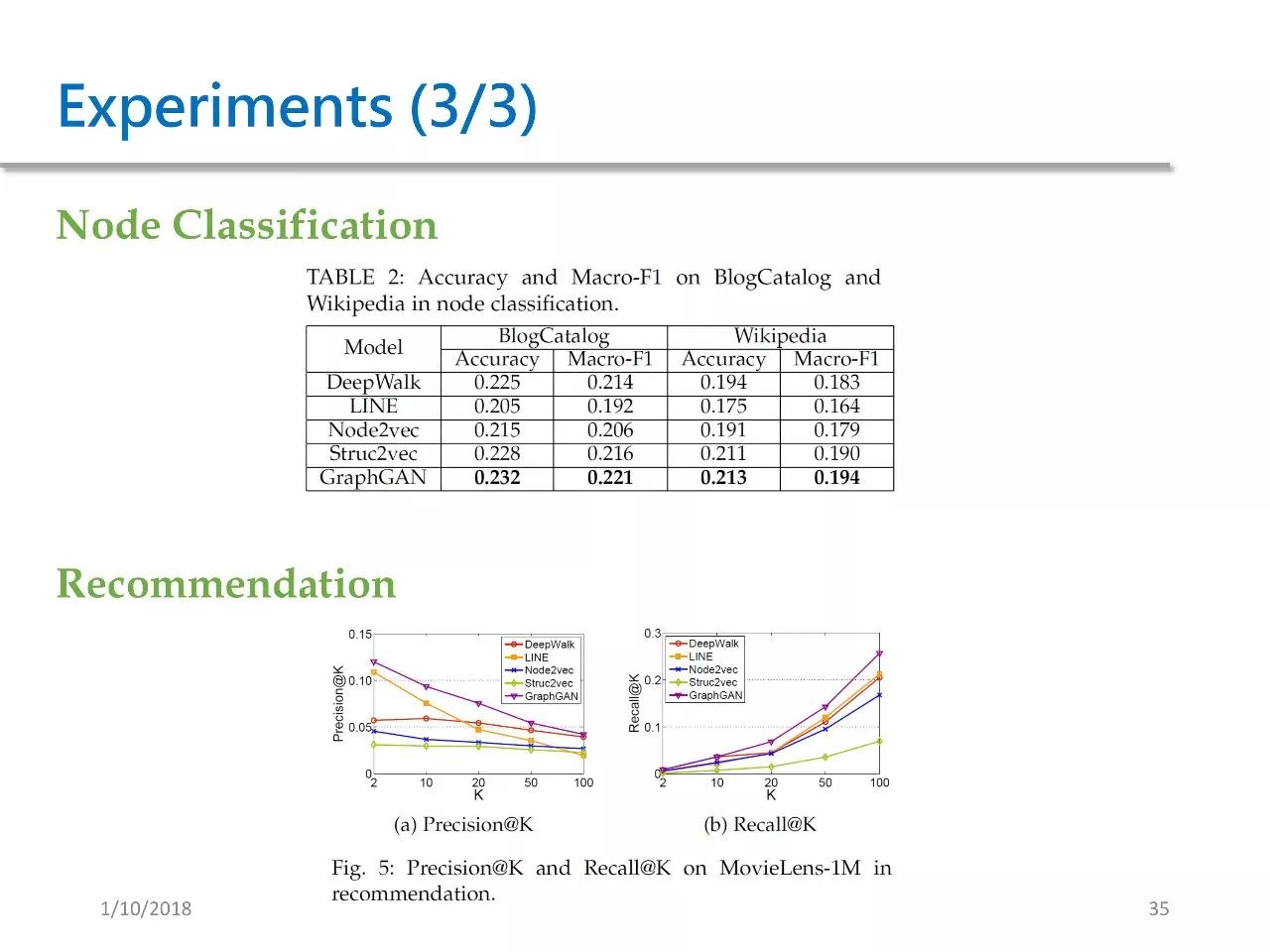
第二个测试场景是 Node Classification,在这个场景中我们想对节点进行分类,我们用的数据集是 BlogCatalog 和 Wikipedia。在这样的数据中,我们的方法取得了最好的效果。
第三个测试场景是推荐。所用的数据集是 MovieLens,我们的方法也取得了最好的效果。
总结

本文提出的 GraphGAN 是一种结合了生成模型和判别模型的框架。其中生成器拟合 Ptrue,判别器尝试去判别两个点之间是否有边。
G 和 D 实际上是在进行一个 minmax game,其中 G 试图去产生一些假的点。这些假的点不能被 D 所判别,而 D 试图去将真实值跟假的点分别开来,以避免被 G 所欺骗。
此外,我们还提出了一种 Graph Softmax 作为 G 的实现,克服了 softmax 和层次 softmax 的缺陷,具备三个良好性质。
GRL的其他应用
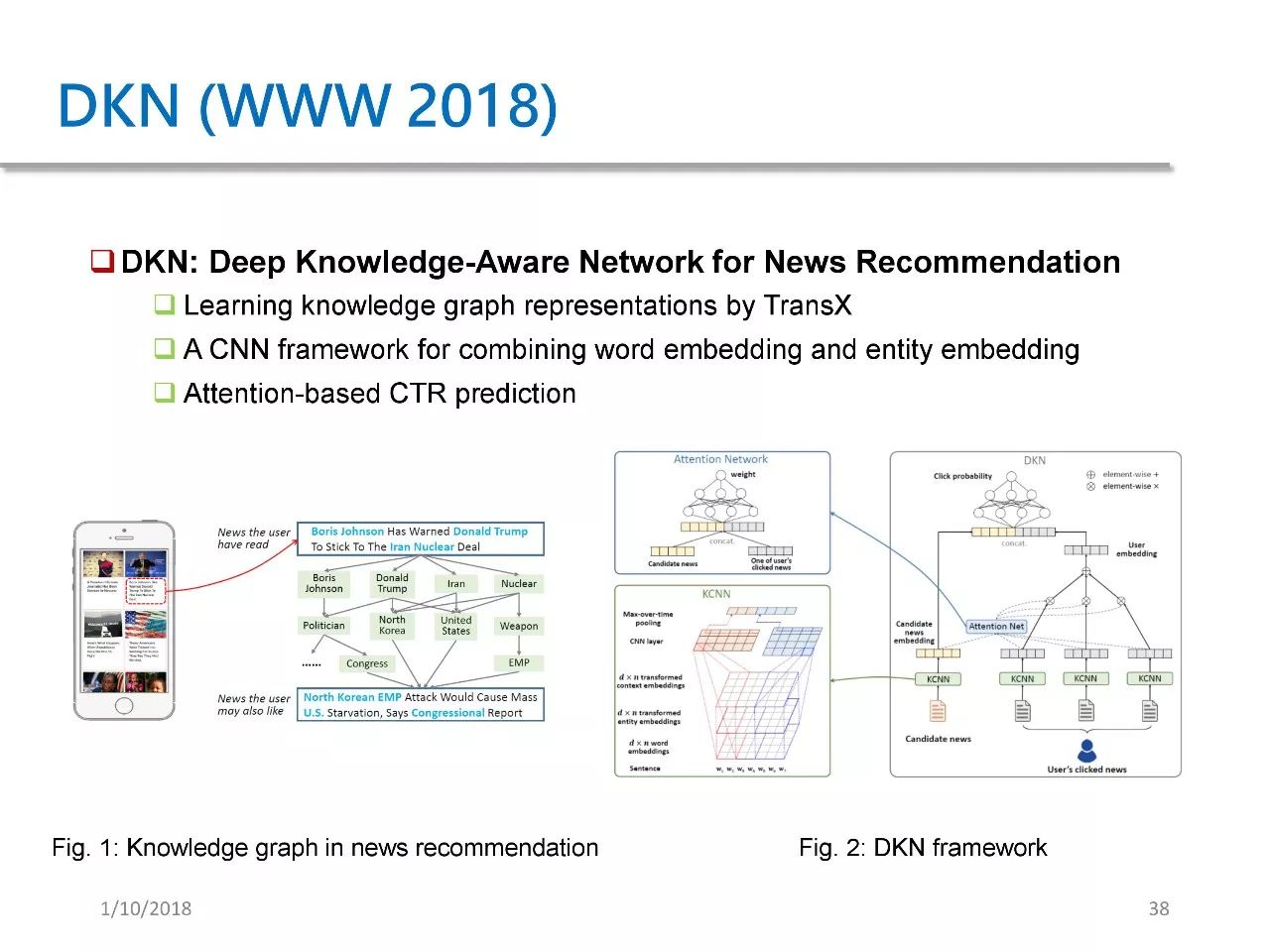
DKN 是我们发表在 WWW 2018 上的论文,它提出了一个可用于新闻推荐的 deep knowledge-aware network。在 DKN 中,我们将 KG 中的 entity embedding 和 word embedding 在一个 CNN 框架中加以结合,并且提出了一种 attention based 点击率预测模型。
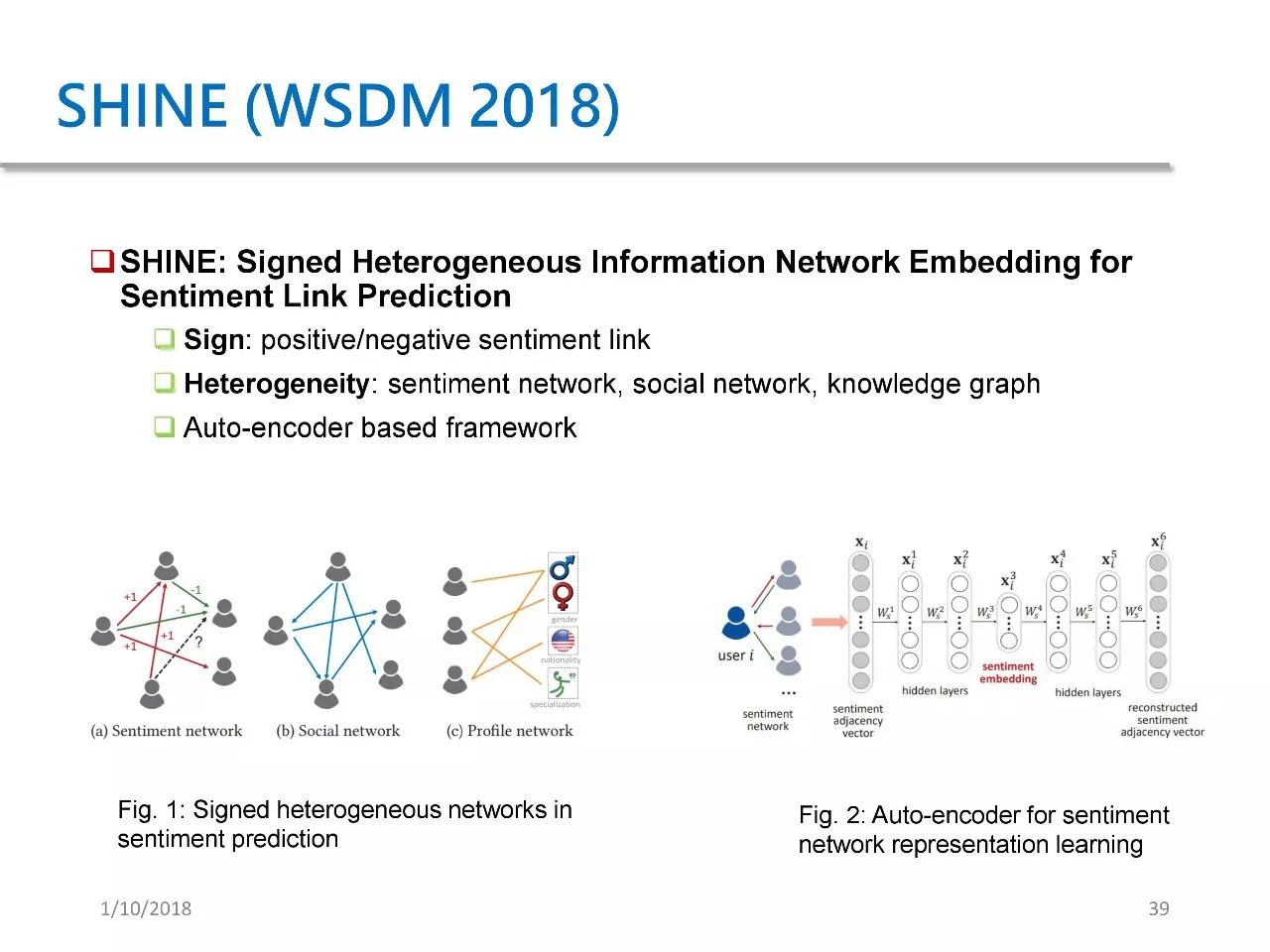
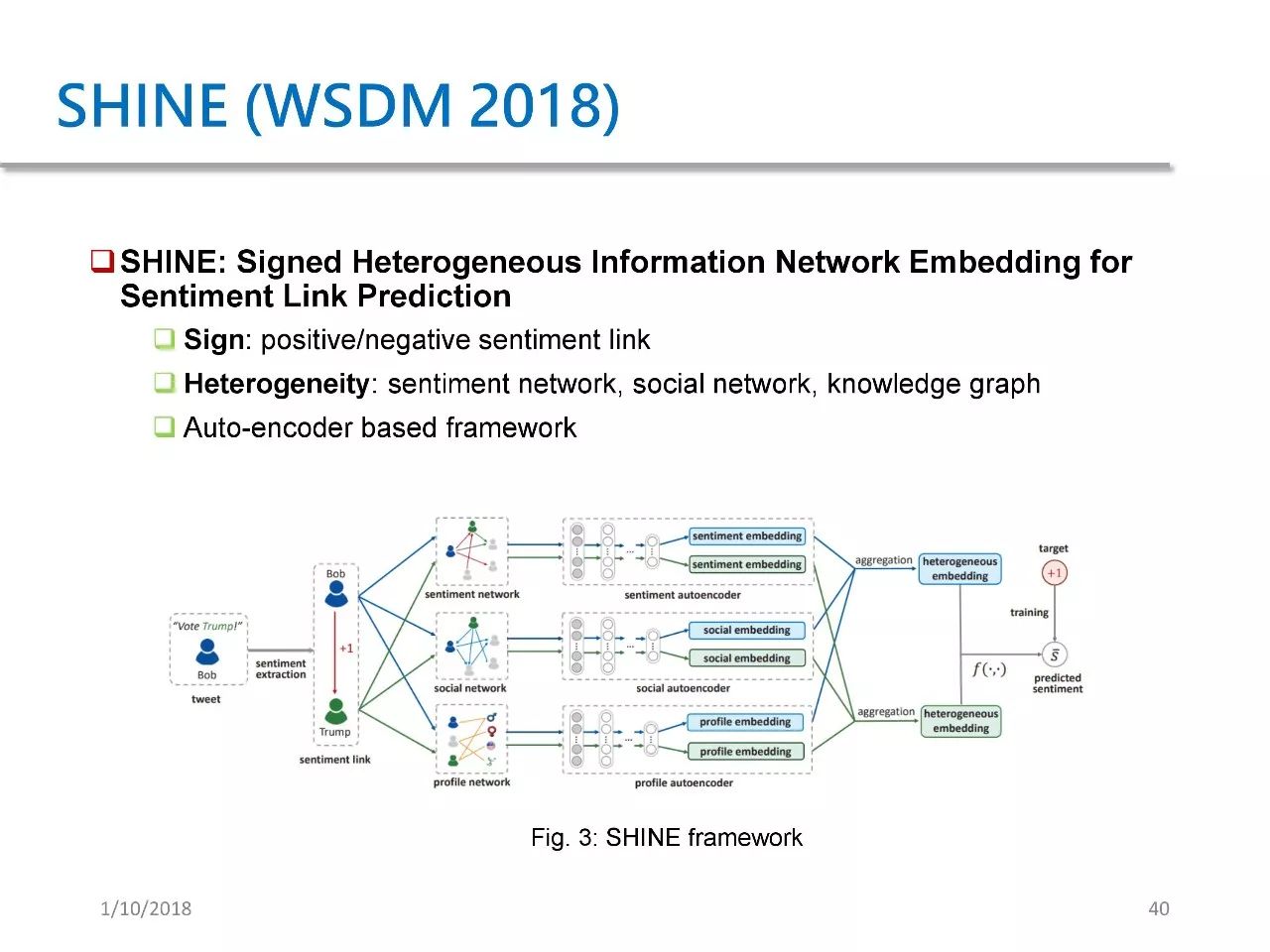
第二个应用是 SHINE,这篇论文发表于 WSDM 2018。它的目的在于预测微博用户对名人明星的情感。我们提出了一种基于自编码器的框架,这个框架其实类似于 SDNE,将它应用于三者并加以结合进行情感预测。
>>>> 获取完整PPT和视频实录
关注PaperWeekly微信公众号,回复20180110获取下载链接。
点击以下标题查看往期实录:
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。