FAIR和牛津大学VGG组最新论文:多模态自监督学习
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:bingo
https://zhuanlan.zhihu.com/p/115127335
本文已由原作者授权,不得擅自二次转载
之前写过很多篇关于图像自监督学习的论文阅读笔记。最近FAIR和VGG一起推出了一篇多模态自监督学习的论文:Multi-modal Self-Supervision from Generalized Data Transformations。

https://arxiv.org/abs/2003.04298
整体流程
与图像自监督学习不同的是,多模态自监督学习需要同时考虑多种数据输入类型(图像和语音),并且利用他们的关联辅助学习。如图1,论文提出的方法主要包括三个步骤:1. 时序抖动,即从视频中随机选取一个时间起点;2. 模态选择和数据增强,选取一个特定模态进行数据增强;3. 跨模态对比学习。
如图1,对于多模态数据 



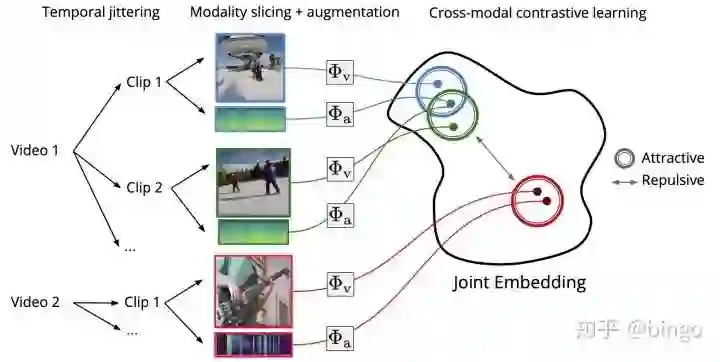
数据增强
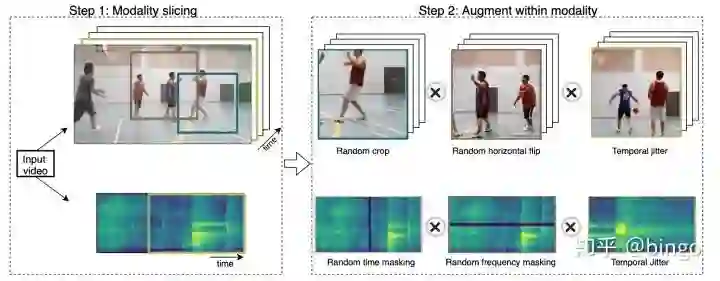
Step 1. 选择特定模态。这个步骤,只选择一个模态进行增强,另一个模态保持不变。
Step 2. 对选定的模态进行数据增强。如图2,图像增强包括裁切、水平翻转和时序抖动,语音数据增强包括时间掩盖、频域掩盖和时序抖动。
损失函数
论文使用对比损失函数进行模型训练。具体的,对于数据 





其中, 


梯度和学习过程。 

如果对于简单变换 


语音和视觉的具体实现。作者采用2种变换(

对应的损失函数:

实验
论文使用Kinetics-400数据集进行无监督训练,下游任务是动作识别(UCF101, HMDB51)和语音事件分类(ESC-50, DCASE2014)任务。
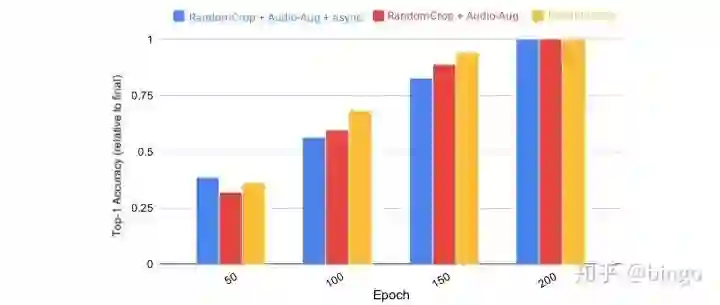
首先,如图3,通过ablation study,验证了时序抖动和语音、视频同步的重要性。
然后,如图4,作者严重了渐进课程学习的过程,即简单的变换比如随机裁切可以较快的学习,而多种复杂变换的组合学习速度较慢。

最后,在动作识别和语音事件分类任务上,论文的方法超过或者接近当前最好性能方法。
总结
多模态数据包含多种不同的数据类型,首先需要映射到同一个空间进行计算。同时,不同模态数据由于各自特性可以产生特定数据增强方法。
相关论文:
1. Multi-modal Self-Supervision from Generalized Data Transformations, arxiv
重磅!CVer-论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满1100+人,旨在交流顶会(CVPR/ICCV/ECCV等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
麻烦给我一个在看!




