Ian Goodfellow:你的GAN水平我来打分
选自arXiv
作者:Catherine Olsson, Surya Bhupatiraju, Tom Brown, Augustus Odena, Ian Goodfellow
机器之心编译
机器之心编辑部
如何评价生成模型的性能好坏?这似乎是一个复杂而困难的任务。Ian Goodfellow 提出的生成对抗网络 GAN 已经成为人工智能的重要研究方向,吸引了众多学者投入研究。但 GAN 也遭遇了「改无可改」的呼声(参见:六种改进均未超越原版:谷歌新研究对 GAN 现状提出质疑)。近日,Goodfellow 团队提出了一种全新生成模型评价方式,看来,GAN 的开山鼻祖终于坐不住了,他试图亲自解决这个问题。
Ian Goodfellow 表示:通过估计解释模型表现的隐技能变量来评估生成模型的能力似乎是一个很有希望的研究方向。
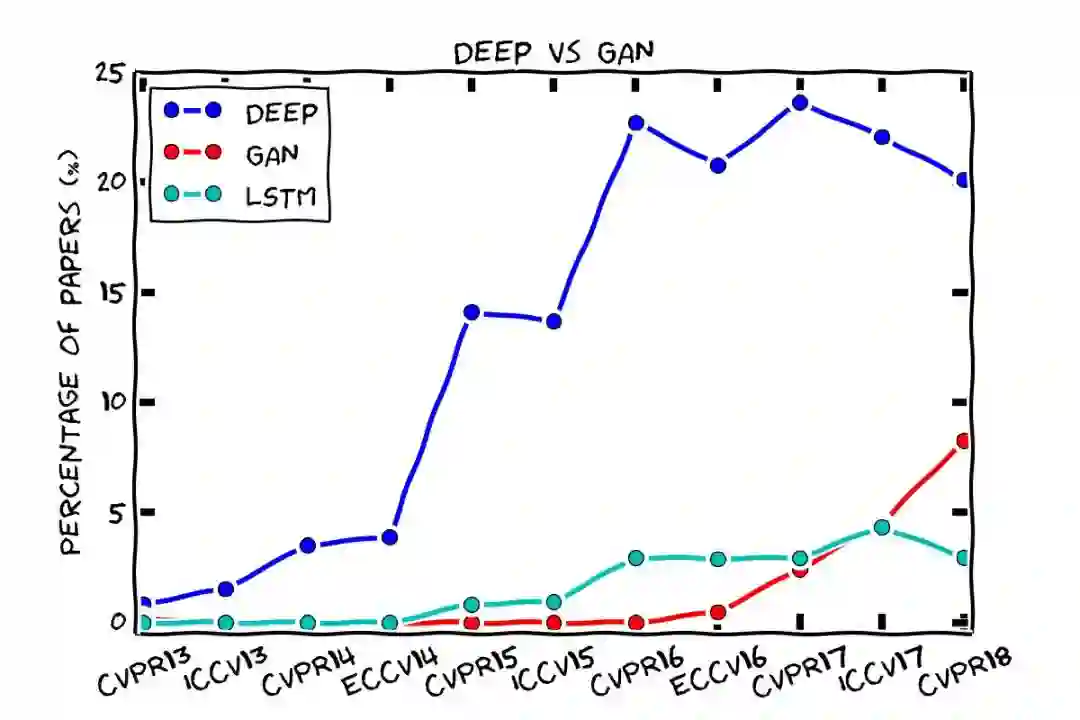
谷歌研究科学家 Jordi Pont-Tuset 对于 CVPR 各届接收论文名称的统计,GAN 已经超过 LSTM,成为了重要关键词,大有赶超「深度学习」的趋势。但众多论文里,真正的改进又有多少?
生成模型的评估是一项非常困难的任务。目前该领域已经探索了许多不同的方法,但每一种方法都存在显著的缺点。Theis [2016] 和 Borji [2018] 等人概览了这些方法,并展示了它们各自的缺点。
在这一篇论文中,谷歌大脑提出了一种通过对抗过程评估生成模型的新框架,在该对抗过程中,许多模型在锦标赛(tournament)中进行对抗。谷歌大脑团队利用先前开发的人类选手评估方法来量化模型在这类锦标赛中的性能。
在国际象棋或网球比赛中,Elo 或 Glicko2 等技能评分系统通过观察多个参赛者的胜利数和失败数,推断每一个参与者的隐藏、未观察到的技能值(它们解释了这些观察到的输赢数),从而评估他们的技能表现。同样,谷歌大脑团队通过构建一个多参与者的锦标赛将生成模型的评估构建为隐藏技能估计问题,该锦标赛可推广至噪声对比估计(NCE)和生成对抗网络(GAN)所使用的两参与者的可分辨博弈(two-player distinguishability game),并且估计参与这些锦标赛的生成模型的隐藏技能。
锦标赛的参与者可以是尝试区别真实数据和伪数据的判别器,也可以是尝试欺骗判别器将伪造数据误认为是真实数据的生成器。虽然框架主要为 GAN 设计,但它也可以估计任何成为该框架参与者的模型效果。例如显式密度模型等任何能够生成样本的模型都可以作为生成器。
我们引入了两种方法来总结锦标赛的结果:
锦标赛胜率:锦标赛中每个生成器成功欺骗判别器的平均比率。
技能评分。用技能评分系统对锦标赛的结果进行评估,然后对每个生成器生成一个技能分数。
实验表明,锦标赛是一种评估生成器模型的有效方式。首先,within-trajectory 锦标赛(在训练的连续迭代中,单个 GAN 自身的判别器和生成器的 snapshot 之间)提供了一个有用的训练进度衡量标准,即使只能接触正在训练的生成器或判别器。其次,更普遍的锦标赛(具有不同种子、超参数和架构的 GAN 生成器和判别器 snapshot 之间)提供了不同训练过的 GAN 之间的有效对比。
本论文第二部分将研究放在生成模型评估系统这一更大背景下,详细说明了谷歌大脑提出的方法和其他方法相比的优点和局限性。4.1 节初步证明了该方法适用于不能很好地表征为标准化图像嵌入的数据集,例如未标注数据集或自然图像以外的形式。谷歌大脑研究者还展示了使用技能评分系统来总结锦标赛结果,实现了在一场比赛中对所有参与者进行技能评分,而无需进行二次比赛。4.2 节展示了 GAN 判别器能成功地判断哪些样本来自于没训练过的生成器,包括其他 GAN 生成器和其他类型的生成模型。4.3 节展示了该方法可以应用于生成器近乎完美的情况下。
论文:Skill Rating for Generative Models

论文链接:https://arxiv.org/abs/1808.04888v1
摘要:我们利用评估人类选手在竞技游戏中表现的方法,探索了一种评估生成模型的新方式。我们通过实验展示了生成器和判别器之间的锦标赛为评估生成模型提供了一种有效方式。我们介绍了两种对比锦标赛结果的方法:赢率和技能评定。评估在不同语境中都有用,包括监控单个模型在训练过程中的进展、对比两个不同的完全训练模型的能力。我们展示了包含单个模型与其之前、之后版本比赛的锦标赛可以有效辅助对训练进展的衡量。包含多个单独模型(使用不同随机种子、超参数和架构)的锦标赛提供了对不同训练 GAN 的有效对比。基于锦标赛的评定方法在概念上与大量之前的评估生成模型方法不同,且具备互补的优劣势。
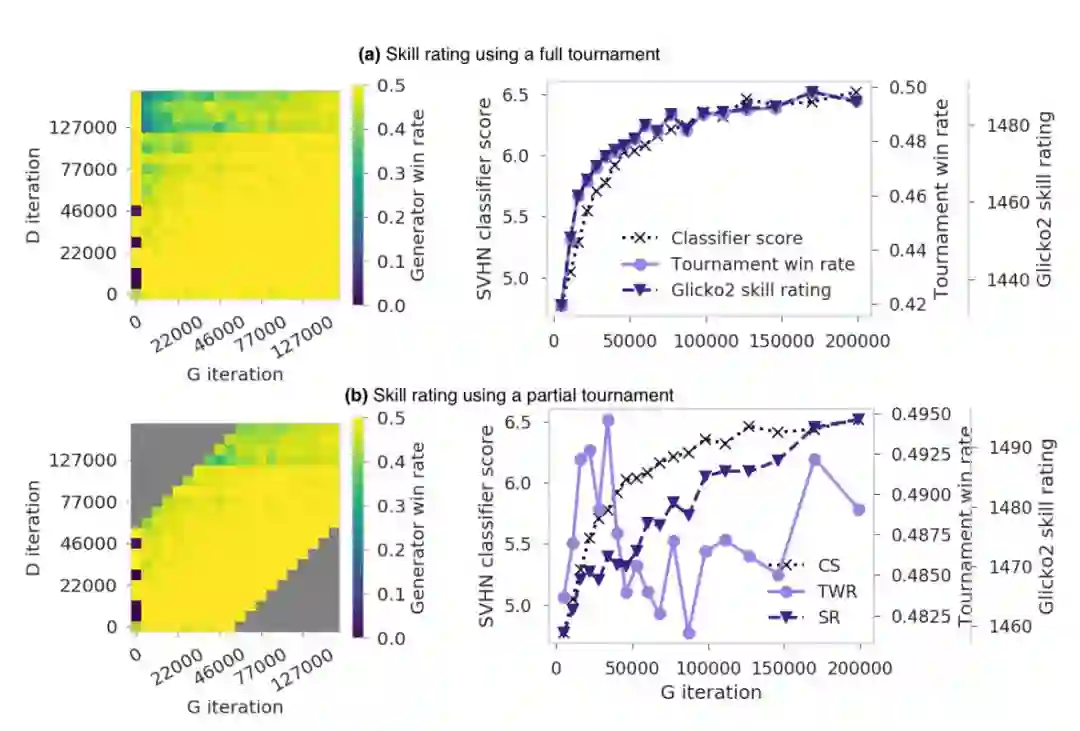
图 1:实验 1 的 Within-trajectory 锦标赛结果。图 1a:左图展示了原始比赛结果。每个像素表示来自实验 1 不同迭代的生成器和判别器之间的平均赢率。像素越亮表示生成器的性能越强。右图对比了比赛的概括性指标和 SVHN 分类器得分。该图中比赛赢率指热力图中每列平均像素值。(注意:i=0 时分类器得分低于 4.0,遮挡了同一轴线上其余曲线的对齐,因此我们选择忽略它。)图 1b 展示了相同的数据,不过它使用的是相距较远的迭代之间的比赛,如图 1b 左图褐色像素所示的部分。右图展示了技能评定继续追踪模型的进展,即使忽略了一些信息量最大的「战斗」(早期生成器和晚期判别器,如图左上角所示),而赢率不再具备信息。
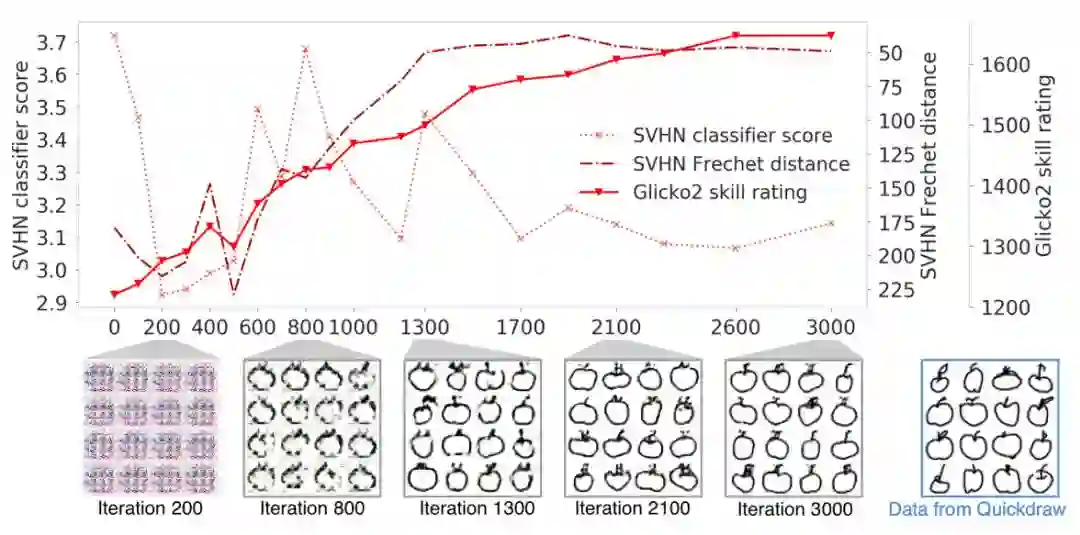
图 2:绘制苹果图片的 within-trajectory 技能评分。我们评估了在 QuickDraw 数据集上训练的 DCGAN。从左到右,主观样本(subjective sample)质量随着迭代次数的增加而提高。SVHN 分类器判断这些样本质量的能力不强,迭代 0 次时评成了最高分,此后提供了不稳定且恶化的得分。SVHN Fréchet 距离拟合地更好,采样质量的评分稳定增加,直到 1300 次迭代;但是,它会在 1300 上饱和,而主观样本质量继续增加。(注意 Fréchet 距离图上的 y 轴是反转的,这使得较低距离(更好质量)在图上位置更高)。within-trajectory 技能评分在 1300 次迭代以后继续提升。
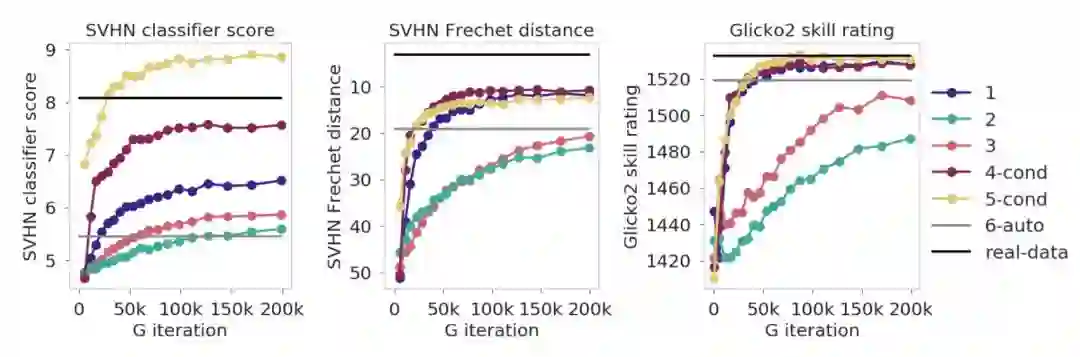
图 3:多轨竞赛结果。我们组织了一个竞赛,其中包含 SVHN 生成器和具有不同种子、超参数和架构的模型的判别器 snapshot(已在 4.2 节中提及)。我们利用 SVHN 分类器评分 (左)、SVHN Fréchet 距离 (中) 和技能评分方法(右;见 3.2 节)对其进行评估。每个点代表一个模型一次迭代的分数。总体轨迹表明随着训练次数增加,每个模型都得到了改进。要注意 Fréchet 距离图上的 y 轴是反转的,这使得较短的距离(质量较好)在坐标图上标得更高。真实数据样本的得分用黑线表示。6-auto 的分数是根据单个 snapshot 而非一条完整的训练曲线来计算的,并以灰线表示。技能评分生成的学习曲线与 Fréchet 距离生成的学习曲线大致相同,仅在条件模型 4-cond 和 5-cond 中与分类器得分的曲线不一致——我们在 4.2 节中对此差异进行了推测。

图 4:完全训练的生成模型样本。从每个训练模型中,我们展示了 64 个样本(来自 GAN 的 200,000 次迭代和 6-auto 的 106 次 epoch),以及用于比较的真实数据。在每组样本中,我们列出模型的 Glicko2 技能评分(SR)、SVHN 分类器分数(CS)以及模型的 SVHN Fréchet 距离(FD)。我们的技能评分系统在实验 5-cond 中略逊于真实数据,但优于 runner-ups 4-cond 和 1,而分类器得分 5-cond 比真实数据好,Fréchet 距离 5-cond 比 4-cond 和 1 都差。在其它情况下,我们系统的排名与 Fréchet 距离一致。
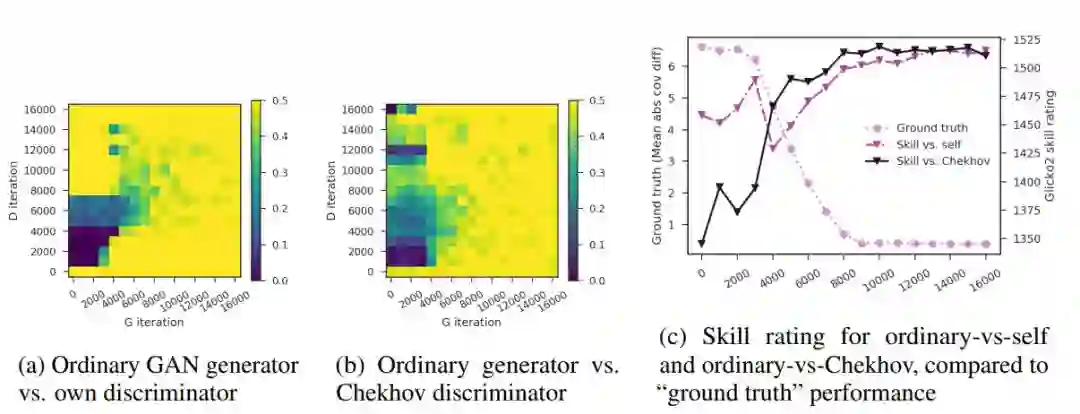
图 5:用一个简单的任务来评估近乎完美的生成器。我们训练一个普通的 GAN 来模拟具有全协方差矩阵的高斯分布。迭代 8000 次以后的生成器已经掌握了这个任务。迭代 8000 次以后的判别器不再产生有用的判断(图 5a),迭代 8000 次之后的 Chekhov GAN 判别器则仍可以判断之前的生成器样本(图 5b)。图 5c 对这些判别器的技能评分与普通生成器的真实性能进行了比较,并将之衡量为生成器的协方差矩阵估计和数据协方差矩阵之间的平均绝对差。与 within-trajectory 比赛相比,Chekhov 判别器的技能评分更符合真实情况。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




