观点 | 争议、流派,有关GAN的一切:Ian Goodfellow Q&A
选自fermatslibrary
机器之心编译
参与:思源、李泽南
自 2014 年提出以来,生成对抗网络(GAN)已经成为深度学习领域里最为重要的方向之一。其无监督学习的特性有助于解决按文本生成图像、提高图片分辨率、药物匹配、检索特定模式的图片等多种任务。近日,GAN 的提出者,谷歌大脑研究科学家 Ian Goodfellow 在问答平台上面向所有人进行了 Q&A 活动,向我们解答了有关 GAN 的背景、技术、流派,以及一些有趣的问题,我们对本次活动的内容进行了整理。
Gfred:有传言说你是在一家酒吧里想出生成对抗网络(GAN)的,真的假的?
Ian Goodfellow:这是真的,并不是谣言而已。我曾在一些采访中介绍过当时的经历:
Wired:https://www.wired.com/2017/04/googles-dueling-neural-networks-spar-get-smarter-no-humans-required/
NVIDIA Blog:https://blogs.nvidia.com/blog/2017/06/08/ai-podcast-an-argument-in-a-bar-led-to-the-generative-adversarial-networks-revolutionizing-deep-learning/
Gautam Ramachandra:能否介绍一下为实现目标函数所采用的函数导数所涉及的步骤,以及,GAN 中是否采用了贝叶斯理论?
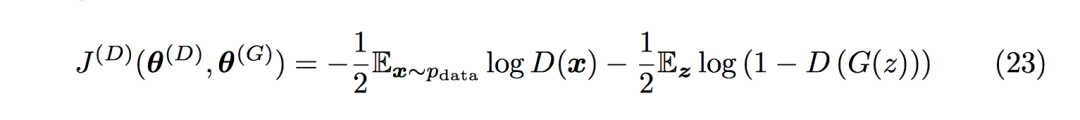
上述目标函数导数如下:

这些方程来自 NIPS 2016 上的 Tutorial《Generative Adversarial Networks》(https://arxiv.org/pdf/1701.00160.pdf)在文章的第 46 和 47 页,能不能帮我完成目标函数的函数导数步骤?
Ian Goodfellow:在 AMA 中我可能没有足够时间来完成所有 LaTex 格式函数推导的过程,不过你可以在深度学习书中找到一些有用的信息:http://www.deeplearningbook.org/contents/inference.html
大部分你需要知道的内容在方程 19.46 里。
一旦将该方程应用于 J(D),你就有了一个表达式,而且不需要知道任何有关函数导数的东西。
Avhirup Chakraborty:目前是否存在研究生成模型可迁移性的论文和工作?例如:我有一个用于生成猫和狗图片的模型,我可以利用前面的一些层级来生成狼和老虎的图片。
Ian Goodfellow:我还不知道目前有这样的研究,但我认为这种思路是可行的。对于生成器来说,后面的一些层(接近输出端的)更可能用在其他任务上。
Anshuman Suri:这可能有一点偏离主题了——你认为重新思考深度学习中「神经元」的工作方式是目前唯一一种解决对抗样本问题的可行思路吗?在你的一些视频中,你提到了一些这种通用样本的存在,因为模型的「线性」(与许多人所说的「非线性」相反)。我们目前的神经网络研究路线是错误的吗?还是说一些结合了完美的激活函数、数据增强/防御的模型就可以解决所有问题?
Ian Goodfellow:这个问题没有偏离我们的主题,因为 GAN 的鉴别器需要对于生成器制造的对抗性输入具有鲁棒性。
我确实认为目前我们使用的神经元在面临对抗样本的时候难以保持稳健,但我不认为这是唯一的问题。最近的一些论文,如《Adversarial Spheres》(https://arxiv.org/abs/1801.02774)认为,为了确保分类器的安全性,我们确实需要从基础上重新思考自己的策略,而不是仅仅重新训练其他类型的模型。Geoffrey Hinton 等人提出的 Capsule 确实在防御对抗样本的时候强于普通模型(https://openreview.net/forum?id=HJWLfGWRb)。我们尚不清楚这是防御的最佳方式,目前还没有一种防御对抗样本和业内最强攻击方式的对抗性评测。
Foivos Diakogiannis:GAN 和强化学习(RL)是否有什么相似之处?据我浅显的理解,我认为 GAN 上的生成器-鉴别器和强化学习中的代理-环境相互作用的方式非常相近,我的思考是对的吗?
Ian Goodfellow:我或许没有资格评价强化学习,但是我认为 GAN 是使用强化学习来解决生成建模的一种思路。GAN 案例的一些奇怪的地方在于奖励函数在行动中是完全已知和可微分的,奖励是非稳态的,奖励也是代理策略的一种函数。但我确实认为它基于强化学习。
Jakub Langr:你最近使用 Jacobian claping 用于训练稳定性的论文令人着迷。你是否可以提供:
另一种解释 Jacobian clamping 的方式?
稍稍解释一下该工作的重要性。GAN 的训练有好有坏,但有时我们难以理解其中的全部,因为几乎所有人都已认识到 WGAN 的贡献,但至今却没有多少超过它的研究。
我发现 GAN 训练方式的阵营有两到三个:你和 OpenAI、谷歌的同事;Mescheder、Sebastian Nowozin 与其他微软研究院等机构的研究人员。你也是这样认为的吗?
Ian Goodfellow:第三个问题,不,我认为有更多的阵营。FAIR/NYU 也有一些重要研究结果,事实上,确实是 FAIR/NYU 首先提出了 LAPGAN,真正生成了引人注目的高分辨率图像——这是 GAN 第一次得到媒体的大规模报道。另外一个非常重要的阵营是 Berkeley 和 NVIDIA 阵营,他们专注于高分辨率图像、视频、无监督翻译等方向。我不确定你所说的「阵营」是什么意思。如果你的意思是使用 GAN 的不同方式,那么是的,这些团队都是以不同方向为目标的。很多时候「阵营」意味着团体之间或多或少有冲突,但我认为在这里并没有这种情况。
第一个问题,这是一个高难度的问题,你需要了解 Jacobian clamping 的哪个方面?
至于第二个问题,在 Augustus 未来的几篇论文公布之前,想要回答有关重要性的问题还有点难。
Vineeth Bhaskara:你的论文与 Jurgen Schmidhuber 的 GAN vs PM 有多大区别?你们之间仍有分歧吗?
Ian Goodfellow:那篇论文已经被撤销提交了,我们之间仍有分歧。
Adam Ferguson:我是一名来自波士顿大学的学生,
1)在 GAN 和其他生成模型如 VAE 和 FVBN(以及 NADE、MADE、PixelCNN)之间该如何进行选择?
2)像 Librarian/Fermat Library 这样的工具对于 ML/DL 这样的领域很重要,其中的论文在 arXiv 上发表的速度远远快于期刊,这方面的未来会是什么样的?
Ian Goodfellow:这个 AMA 就是在帮助 Librarian/Fermat Library 提升效果,因为我认为这些工具非常重要。arXiv 目前基本上是一个绕开同行评议过程的方式,它使得深度学习论文的信噪比猛降。其中虽然有很多有关深度学习的好论文,但也有很多低质量的工作。今天,即使是最好的工作也会夹杂私货——论文里写了一个好的主意,却又包含不公平的推销、与其他研究不准确的比较等等。因为在其中没有任何同行评议,所以作者变得有点肆无忌惮了。
如果你想生成连续变量的真实样本,如果你需要做无监督翻译(如 CycleGAN),或者说你想做半监督学习,那么通常你需要用 GAN。如果你想生成离散的负号,那么你应该还不能用 GAN,但我们仍在做这方面的努力。如果你想要最大似然,那么你可能不需要 GAN。
Kushajveer Singh:最近你在 Twitter 中提到了你心中的 10 篇最佳 GAN 论文,你能写一篇文章列举对于初学者和专业人数来说重要的论文和其他资源吗?
Ian Goodfellow:我可能没有时间做这样的工作,而且如果我做了,它也很快就会过时。我在 2016 年 12 月写过一篇 GAN 的大型教程:https://arxiv.org/abs/1701.00160。
其中的很多理念在今天仍然适用,不过其中不包含最近发展出来的最先进的模型,如 Progressive GAN、谱归一化 GAN、带投影鉴别器的 GAN 等。
Rafa Ronaldo:定量评估 GAN 的方法是什么?
Ian Goodfellow:它取决于你希望拿 GAN 来做什么。如果你希望将它用于半监督学习,那么就使用测试集的准确率度量;如果你希望用于生成人类比较欣赏的图像(如超分辨率等),那么就需要使用人类的评分。如果你仅希望使用一般的自动化质量评分,那么我认为 Frechet Inception Distance ( https://arxiv.org/abs/1706.08500 ) 可能是最好的。当然度量方法本身仍然是研究领域中非常重要的一部分。
Andres Diaz-Pinto:现在有方法将隐变量映射到生成图像的一部分吗?换句话说,能否使用几个变量改变背景颜色,然后然后另外几个个变量修正形状或其它的属性?
Ian Goodfellow:通常情况下是可以实现的,但我们需要以特定的方式训练模型,详情请查看 InfoGAN:https://arxiv.org/abs/1606.03657。
Rafa Ronaldo:你怎样来提升编程技能以便能快速实现如 GAN 等各种有意思的想法?能不能推荐几本提升编程技能的书,或具体学习 TensorFlow 与其它深度学习框架的书?
Ian Goodfellow:我学习现代深度学习编程的路径非常间接,因为在学习使用 Python 之前,我学过各种 C、汇编、网页等编程语言。因此我也不确定怎样才能加速编程的学习过程。在编程能力方面,对我来说非常重要的一个转折点就是 2006 年参加 Jerry Cain 在斯坦福开设的 CS107 课程。在那之前,我基本只是一个编程爱好者,但上过课后,基本上我在软件开发方面就不会再困惑了。现在你们也可以在 YouTube 或 iTunes U 等站点找到该课程。
此外,当我开始第一次尝试构建 GAN 时,那时有非常多的优秀工具,如 Theano、LISA lab 计算机集群等。所以编写 GAN 不那么困难的原因有一部分就是因为这些优秀的深度学习框架,同时我在整个博士期间都在学习深度学习,因此有非常多的代码块可随时嵌入到新模型中。我第一个 GAN 的实现主要是从 MNIST 分类器代码中复制粘贴。
Jason Rotella:GAN 能用于主题建模吗?现在除了生成模型,GAN 框架还能扩展应用到其它领域吗?
Ian Goodfellow:我猜测是可以用于主题建模的,但现在并不知道任何在该领域的具体研究。一个主要的挑战即文本是由离散的字符、标记或单词组成的,但是 GAN 需要通过生成器的输出计算梯度,因此它只能用于连续型的输出。当然还是有可能使用对抗自编码器或 AVB 等模型,因此生成器实际上或是一个编码器,并能输出连续的编码。这对于文本建模可能是非常有用的属性,因为它给出了表征主题的分布。
Greg McInnes:在基因组学中,有 GAN 的用武之处吗?
Ian Goodfellow:我对基因组学没有太多的了解,但我认为用于半监督学习的 GAN 模型可能会对该领域有非常重要的作用。因为未标注的基因远要比标注的基因多,所以半监督学习有助于利用大量未标记数据从少数标注样本中学习。
Tim Salimans 为此也开发了一些方法,这些方法在 MNIST 和 SVHN 等基准测试中非常高效(https://arxiv.org/abs/1606.03498)。但到目前为止,我发现其它半监督学习方法并不是非常有效,不过半监督 GAN 目前还处于研究中。
Nicholas Teague:我比较好奇现在是否有其它一些案例成功地将 GAN 用于图像或视频之外的数据。
Ian Goodfellow:以下是我们近来将 GAN 用于文本数据的论文: https://arxiv.org/abs/1801.07736。
Gonçalo Abreu:以下陈述正确吗:「可能存在两个不同的 GAN,其中一个有较好的评分,但是在作为外部分类器时,从鉴别器中抽取特征要更差或更低效。」此外,关于结论的第四点:您为什么建议我们使用 GAN 作为特征提取器?也就是说,我们怎样才能确保由 GAN 架构产生的表征是有用的或表示了输入数据的潜在结构?最后,如果网络有足够的容量,那么生成器会不可阻挡地学习如何模拟输入数据?
Ian Goodfellow:你说的那个陈述是对的,假设你有一个完美的生成器,那么对于所有的 x,P_generator(x)=P_data(x)。那么最优判别器 D*(x)= P_data(x)/(P_generator(x)+P_data(x))=1/2,这个判别器的特征可能完全没用,因为我们可以将判别器的权重设为 0 而达到该效果。
对于特征提取,一种方法是使用判别器隐藏层的特征,另一种方法就如同自编码器一样单独学习一个独立的编码器,以下是一些关于 GAN 编码器的论文:
对抗性学习推断:https://arxiv.org/abs/1606.00704
BiGAN:https://arxiv.org/abs/1605.09782
对抗性自编码器:https://arxiv.org/abs/1511.05644
对抗性变分贝叶斯:https://arxiv.org/abs/1701.04722
alpha-GAN:https://arxiv.org/abs/1706.04987
对于生成器模拟输入数据而言,这与几乎所有生成模型的点估计都有关系。如果你在无限模型容量的情况下最大化密度函数的似然度,那么模型仅会记住训练数据。在实践中,GAN 似乎出现更多的问题是欠拟合而不是过拟合,这可能是因为我们不知道如何平衡博弈过程。下面是相关的两篇论文:
On the Quantitative Analysis of Decoder-Based Generative Models:https://arxiv.org/abs/1611.04273。
Do GANs actually learn the distribution? An empirical study:https://arxiv.org/pdf/1706.08224.pdf。
原文链接:https://fermatslibrary.com/arxiv_comments?url=https%3A%2F%2Farxiv.org%2Fpdf%2F1406.2661.pdf
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




