一文概览用于数据集增强的对抗生成网络架构
编者按:机器学习开发者Pedro Ferreira介绍了他在jungle.ai进行的对抗生成网络(GAN)应用研究,回顾了有助于数据集增强的GAN领域的研究进展。
生成对抗网络(Generative Adversarial Network,GAN)迅猛地占领了机器学习社区。优雅的理论基础和在计算机视觉领域不断提升的优越表现使其成为近年来机器学习最活跃的研究课题之一。事实上,Facebook AI Research的领导人Yann Lecun在2016年说过,“在我看来,GAN及其新提出的变体是机器学习在过去10年最有意思的想法。”想要了解这一课题的最新进展,请参阅这篇The GAN Zoo(GAN动物园)。
尽管GAN已被证明是很出色的图像生成模型,例如生成面部图像和卧室图像,GAN尚未在其他数据集上进行过广泛测试,例如由工厂提供的数据集,其中包含大量来自生产线上的传感器的测量值。不同于诸如图片之类的静态数据,这样的数据集甚至可能包括时序信息,机器学习模型需要利用这些时序信息预测未来的事件。在这类数据上应用生成模型可能很有用,例如,如果我们的预测模型需要更多样本进行训练以提升其概括性。另外,如果我们提出一个可以生成优质合成数据的模型,那么这个模型必定学习到了原始数据的潜在结构。既然模型学习到了潜在结构,预测模型就可以将该表示作为新特征集来利用!
本文将介绍一些可能有助于数据集增强的GAN体系结构,包括样本增强和特征增强。让我们从基本的GAN开始。
生成对抗网络
GAN模型由两部分组成:生成器(generator)和判别器(discriminator)。这里我们认为它们都是由参数确定的神经网络:G和D。判别网络的参数为最大化正确区分真实数据和伪造数据(生成网络伪造的数据)的概率这一目标而优化,而生成网络的目标是最大化判别网络不能识别其伪造的样本的概率。

生成网络如此产生样本:接受一个输入向量z,该向量取样自一个潜分布(latent distribution),应用由网络定义的函数G至该向量,得到G(z)。判别网络交替接受G(z)和x(一个真实数据样本),输出输入为真的概率。
通过适当的超参数调优和足够的训练迭代次数,生成网络和判别网络将一起收敛(通过梯度下降方法进行参数更新)至描述伪造数据的分布和取样真实数据的分布相一致的点。
本文接下来的部分将通过基于MNIST数据集生成新数字或编码原始数字至潜空间来演示GAN是如何工作的。我们也会看下如何将GAN应用到类别数据和时序数据上。
作为开始,下面是一个在MNIST数据集上训练的、基于多层感知器(MLP)的简单GAN模型生成的一些样本。
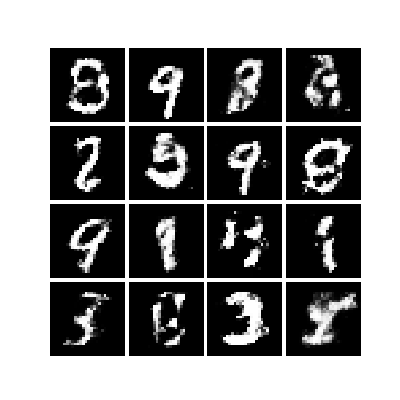
GAN并非尽善尽美
尽管GAN能如我们所见的那样工作,在实践中,GAN有一些缺点,自Ian Goodfellow等在2014年发表GAN的原始论文起,如何克服GAN的缺点一直是研究的热点。GAN的主要缺点涉及它的训练,GAN因极难训练而声名狼藉:首先,GAN的训练高度依赖超参数。其次,也是最重要的,(生成网络和判别网络的)损失函数不提供必要的信息:尽管生成的样本可能已经开始贴切地重现真实数据——显著逼近真实数据的分布——一般而言无法通过损失的趋势来指示这一表现。这意味着我们不能基于损失运行skopt之类的超参数优化器,相反必须手工迭代调优,真是可耻。
GAN架构的另一个缺点和它的功能有关。使用图一显示的基于原始的交叉熵损失的GAN,我们无法:
控制生成什么数据。
生成类别数据。
访问潜空间以便将其作为特征使用。
生成类别数据对GAN而言是一个特大难题。Ian Goodfellow在这个reddit帖子中以非常直观的方式解释了这一点:
仅当合成数据基于连续数值时,你才能对合成数据作出微小的改动。基于离散数值无法作出微小的改动。
例如,如果你输出的图像的像素值为1.0,你可以在下一步将该像素值改为1.0001.
如果你输出单词“企鹅”,你无法在下一步将其修改为“企鹅 + .001”,因为并不存在“企鹅 + .001”这样的单词。你需要经历从“企鹅”到“鸵鸟”的整个过程。
关键的想法是,生成网络不可能从一个实体(如“企鹅”)一路前进到另一个实体(如“鸵鸟”)。因为两者之间的空间出现实体的概率为0,判别网络可以轻易地识别出该空间内的样本是不真实的,因而它不可能被生成网络所愚弄。
GAN变体
为了解决原始GAN的问题,研发了一些其他的训练方式和架构。下面将加以简要介绍。这些介绍的目标是让你对如何应用这些方法至结构化数据(比如Kaggle竞赛中的数据)有所了解。
条件GAN
前面提到的GAN能生成看起来像MNIST数据集中的随机数字。但是如果我们想生成特定数字呢?只需在训练过程中做出一个小小的改动,我们就能告诉生成网络生成我们所要求的数字。在每次迭代中,生成网络的输入不仅包括z,还包括指明数字的one-hot编码向量。同样,判别网络的输入不仅包括真实样本或伪造样本,还包括同样的标签向量。

基于与前述GAN相同的流程,但是加上了这一输出上的微小改动,条件GAN(CGAN)学习生成以输入的标签为条件的样本。
让我们为每个数字生成一个样本!在潜空间取样时,我们同时输入一个one-hot编码的向量指明我们所需的分类。对所有10个分类中的数字进行这一过程,得到图四的结果:
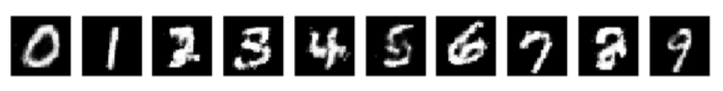
Wasserstein GAN
Wasserstein GAN(WGAN)是最流行的GAN之一,它改变了目标,从而提高了训练稳定性和可解释性(损失和样本质量的相关性),同时能够生成类别数据。关键点在于,生成网络的目标是逼近真实数据分布,因此衡量分布间的距离的指标很重要,因为该指标将是最小化的目标。WGAN选择了Wasserstein距离。Wasserstein距离也称为推土机(Earth-Mover)距离。另外,WGAN实际上采用的是Wasserstein距离的近似。WGAN选择Wasserstein距离是因为Wasserstein距离能在Kullback-Leibler散度和Jensen-Shannon散度无法收敛的分布上收敛。如果你对理论感兴趣,可以看下原始论文或这篇出色总结Read-through: Wasserstein GAN。
在实现层面,总结一下逼近Wasserstein距离意味着什么:
判别器的输出不再是概率了,这也是将判别器改名为批评者(critic)的动机。
判别器的参数截断至某个阈值(或者进行梯度惩罚)。
在每个训练迭代中,判别器的参数比生成器的参数更新更频繁。
用于类别数据的Wasserstein GAN
WGAN论文的作者展示了通过这种方式训练的GAN显示了训练上的稳定性和可解释性,但之后有研究证明,Wasserstein距离的使用赋予了GAN生成类别(categorical)数据的能力(即,并非图像之类的连续值数据,甚至不是像用1表示周日、用2表示周一这样的整型编码数据)。当在这类数据上训练原始的GAN时,判别网络的损失会在多次迭代中保持较低的水平,而生成网络的损失会不停增长。而WGAN在类别数据上训练的方式和在连续值数据一样。
我们只需如此做(图五是一个例子):数据集中的每个类别变量都对应一个生成网络的softmax输出,该输出的维度和可能的离散值数目相等。判别网络并不接受one-hot编码的softmax输出作为输入,相反,将原始的softmax输出当做一组连续值变量,传给判别网络作为输入。这样训练就能收敛!在测试时,只需one-hot编码生成网络的离散输出即可生成伪造的类别数据。
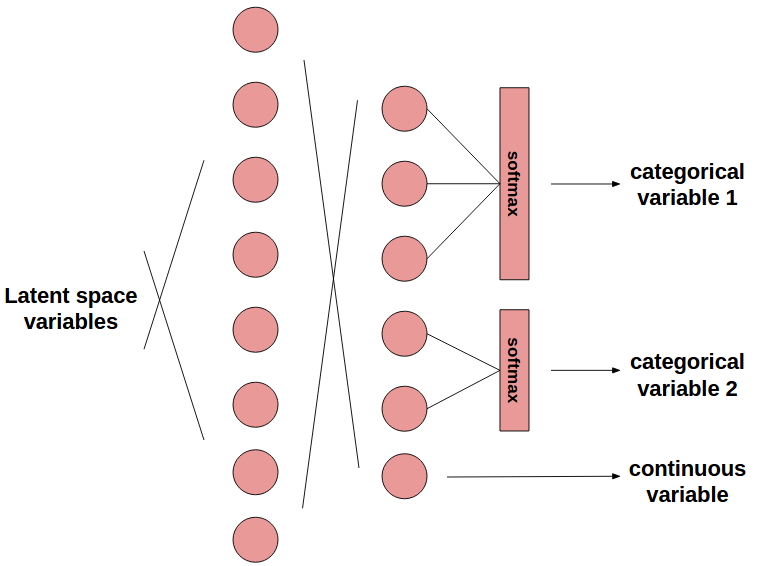
上图中的类别变量1为3个可能值中的1个,类别变量2为2个可能值中的1个。此外还有1个连续变量。
图六展示了一个在类别值的数据集上训练基于梯度惩罚的WGAN的例子,你可以在图中看到稳定的、收敛的损失函数的美丽曲线。这一个例子是在Kaggle竞赛中的Sberbank Russian Housing Market数据集(俄罗斯联邦储蓄银行的房产市场数据集)上训练的,该数据集同时包含连续变量和类别变量。

当然,你也可以组合WGAN和CGAN,以监督学习的方式训练WGAN,以生成以分类标签为条件的样本!
注意:Cramer GAN进一步改进了Wasserstein GAN,其目标是提供质量更优的样本,同时提高训练稳定性。是否能用它生成类别数据是以后的研究课题。
双向GAN
尽管WGAN看上去解决了很多问题,但它不允许访问数据的潜空间表示。寻找这样的表示可能很有帮助,不仅是因为可以通过在潜空间的连续移动控制生成什么样的数据,还因为可以通过潜空间提取特征。

双向GAN(Bidirectional GAN,BiGAN)是解决这一问题的一个尝试。它如此工作:不仅学习一个生成式网络,同时学习一个编码网络E,该编码网络映射数据至生成网络的潜空间。对抗配置中,使用一个判别网络应对生成任务和编码任务。BiGAN的作者展示了,在这一限制下,G和E这一对网络形成了一个自动编码器(autoencoder):通过E编码数据样本,再通过G解码,可以得到原始样本。
InfoGAN
之前我们看到,CGAN允许调节生成网络以根据标签生成样本。不过,是否可以通过在GAN的潜空间中强制一个类别化的结构,以完全无监督的方式学习辨别数字呢?可不可以设置一个连续的代码空间,让我们可以访问这一空间以描述数据样本的连续语义变体呢?(在MNIST的例子中,连续语义变体可能是数字的宽度和斜度。)
上述两个问题的答案都是可以。比那更好的是:我们可以同时做到这两点。真相是,我们可以施加任何我们发现有用的代码空间分布,然后训练GAN编码这些分布中有意义的特性。每份代码将学习包含数据的不同语义特性,结果等效于信息退相干(information disentanglement)。

允许我们这么干的GAN是InfoGAN。简单来说,InfoGAN试图最大化生成网络代码空间和推断网络输出的共同信息。推断网络可以简单配置为判别网络的一个输出层,共享其他参数,意味着它是算力免费(computationally free)的。一旦训练完成,InfoGAN的判别网络的推断输出层可以用来提取特征,或者,如果代码空间包含标签信息,可以用来分类!
创建一个配有两个代码空间的InfoGAN——一个连续的二维空间和一个离散的十维空间——我们能够以离散代码为条件生成特定的数字,同时以连续代码为条件生成特定风格的数字,生成如图九所示的数据。注意,在整个无监督学习计划中,没有标签的位置——在潜空间中施加一个类别分布足以让模型学习编码该分布的标签信息!

对抗自动编码器
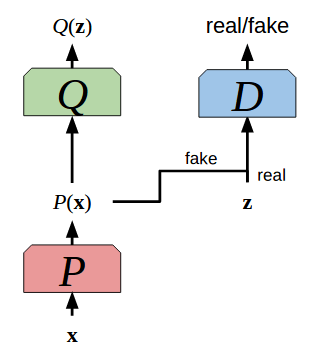
对抗自动编码器(Adversarial Autoencoder,AAE)结合了自动编码器和GAN。这一模型优化两个目标:其一,最小化通过编码网络P和解码网络Q的数据x的重建错误。其二,通过对抗训练在代码P(x)上施加一个先验分布,在对抗训练中,P为生成网络。所以,优化P和Q以最小化x和Q(z)的距离,其中z是自动编码器的代码空间向量,同时优化作为GAN的P和D,以迫使代码空间P(x)匹配预先定义的结构。这可以看成对自动编码器的正则化,迫使它学习有意义、结构化、内聚的代码空间(而不是断裂的代码空间,参考Geoffrey Hinton讲座笔记第76页),以允许进行有效的特征提取和降维。同时,由于在代码上施加了一个已知先验分布,从该先验分布取样,并将样本传给解码网络Q,形成了一个生成式建模计划!
让我们在自动编码器的对抗训练中,在代码空间上施加一个标准差为5的二维高斯分布。取样该空间的相邻点,得到一些生成数字的连续变体集。

我们还可以基于标签训练AAE,以强制标签和数字风格信息的退相干。这样,通过固定想要的标签,施加的连续潜空间中的变体将导致不同风格的同一数字。以数字八为例:

很明显,相邻点间存在有意义的关系!为我们的数据集增强问题生成样本时,这一性质可能会提供便利。
时序数据?
现实世界的结构化数据常常包含时序。在这样的数据中,每个样本和之前的样本间存在某种依赖关系。经常选择基于循环神经网络的模型来处理这种数据,原因是它们具备建模这种数据的内在能力。在我们的GAN模型中利用这些神经网络,在原则上可以产生更高质量的样本和特征!
循环GAN
让我们将之前的GAN中的MLP替换为RNN,就像这篇论文所做的那样。具体而言,我们将采用RNN的变体长短时记忆(LSTM)单元(事实上我们在谈论深度学习最最时髦的行话——哎哟,我又这么干了),在波形(Waves)数据集上进行训练。这一数据集包含偏移、频率、振幅不同的一维正弦信号和锯齿信号,所有信号的时步相同。从RNN的视角来看,每个样本包含一个30时步的波形。
我们的CGAN的生成网络和判别网络都将采用基于LSTM的神经网络,将其转化为一个RCGAN。我们将训练该RCGAN学习按需生成正弦、锯齿波形。
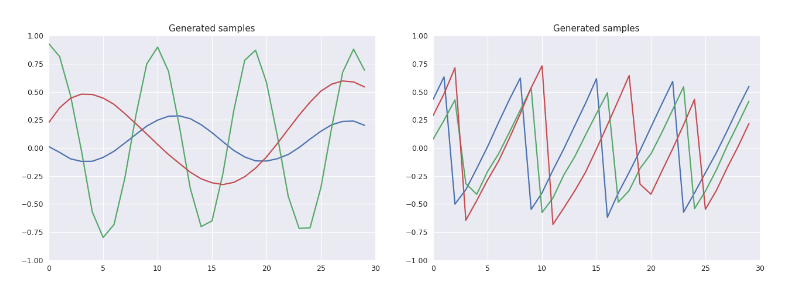
训练之后,我们也将查看潜空间中的变体是如何产生生成样本特性体现的连续变化的。具体而言,如果我们施加一个二维正态分布潜空间,并将分类标签固定为正弦波形,我们将得到图十四中显示的样本。其中,我们能很明显地看到频率和振幅由低到高的连续变化,这意味着RCGAN学习到了一个有意义的潜空间!

尽管在GAN中使用RNN对生成实值的序列化数据很有用,它仍然无法用于离散序列,是否可以配合RNN使用Wasserstein距离尚不清楚(在RNN上施加Lipschitz限制是以后的研究课题)。SeqGAN和最近的ARAE的目标是解决这一问题。
结论
我们看到,在因为GAN具有生成非常酷的图像的能力而生成的那些大惊小怪的报道(看过没有?)之外,一些架构也可能有助于处理更一般的机器学习问题,包括连续和离散的数据。本文的目的是介绍这一想法,并不打算严格地比较这些多用途生成式模型,不过本文确实证明了应该进行这样的涉及GAN的研究。
注:本文展示的例子是我在jungle.ai夏季实习期间完成的。
原文地址:https://medium.com/jungle-book/towards-data-set-augmentation-with-gans-9dd64e9628e6




