技术动态 | 知识图谱的策展
作者:Jiaoyan Chen, Senior Researcher, Department of Computer Science, University of Oxford, Research interests: Knowledge Base, Knowledge-based Learning, Machine Learning Explanation.
知识图谱在众多的领域中发挥了重要作用,比如聊天机器人,自然语言理解,常识推理,数据分析,机器学习等。然而,目前主流的常识知识图谱,如Wikidata和DBpedia,都存在质量管理,维护更新,一致性等方面的挑战。作为从多知识图谱的知识来源,维基百科的知识本身就存在2.8%的错误率 [1];而知识的提取、转化和创建过程也存在出现错误的可能。随着时间的推移和不同知识的融合,知识需要不断更新和维护,以确保知识的覆盖率,准确性和一致性。类似于数据策展 [8],知识图谱的策展(Knowledge GraphCuration)旨在知识图谱(知识库)的管理和维护,解决包括知识的填充(Population),知识的标准化(Canonicalization),错误知识的检测(Detection)和修复(Repair),知识的一致性(Consistency)维护等问题。
牛津大学知识表达和推理实验室 [2],联合伦敦图灵实验室AIDA项目组 [3]和挪威Sirius可扩展数据获取研究中心[4],提出了一些知识图谱策展方面的特定问题,并且结合各自在知识表达,推理,机器学习和语义网等方面的优势,进行了深入地研究。
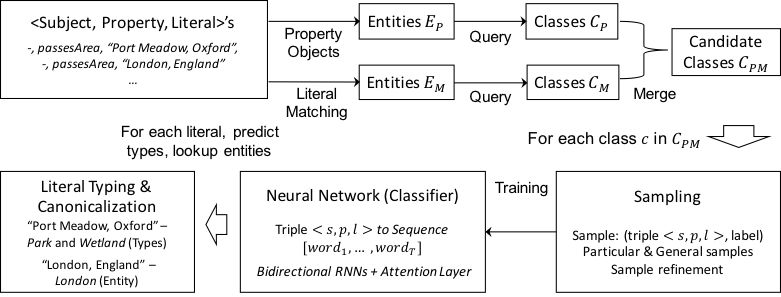
问题一:知识图谱的文本标准化(Literal Canonicalization)[7]。该工作面向基于本体的知识图谱,旨在将那些通过属性任意标注的文本和对应的语义类型与实体进行关联。研究的对象类似如下三元组事实<River_Thames,passesArea, “Port Meadow, Oxford”>。在这个例子中,宾语是一个文本”Port Meadow, Oxford”,它应该和对应的实体关联,或者成为一个新的实体(如果不存在),并且标注语义类型如Park和Place,以使得它具有更多的语义信息,获得更大的使用价值。这样的文本在那些从维基中提取的知识图谱,如DBpedia和LinkedGeoData中大量存在(事实上,我们发现Yago直接删除了这样的事实而不是对它们进行修复)。与此同时,在多个知识图谱的整合对齐时,在知识图谱演化过程中,甚至在知识贡献者编辑知识的时候,也会出现这样的问题或者有类似的需求。不同于现有的Open IE中的实体链接和聚类问题,上述文本的上下文语境存在重要差异,现有的机器学习方法很难直接应用,并且往往依赖于大量人工标注而忽略知识图谱(知识库)的本体限制。
在文本标注化过程中,我们采用下图所示的自动化框架,首先对文本所表示的实体进行类别标注。我们首先通过文本检索提取与文本接近的实体,和关系属性的所有对象实体。这些实体被称为上下文实体,而它们的类别(包括祖先类)则组成了用于标注的备选类。在这些上下文实体和备选类的基础上,我们进一步利用知识图谱的实体,事实和知识图谱的本体限制(如 class disjointness)进行高质量的正采样和负采样。然后我们利用一种基于自相关神经网络的语言模型训练分类器,预测出各个备选类的分数,并结合类与类之间的不相交性等本体限制进行类别标注。基于这些标注的类,我们判断是否存在关联实体,并且找出最有可能关联的实体(如果存在)。
问题二:表格语义标注(Semantic Annotation for Tabular Data)。ColNet [5]是另一项我们正在研究的方法,它能对表格的列进行自动化知识图谱类型标注。类似于谷歌利用网页表格(Web Table)对其知识图谱进行扩展 [6],我们可以利用ColNet的类型标注,及其后续其它语义信息标注,进行知识图谱填充。ColNet不依赖于表格数据的元数据,并且自动从现有的知识图谱中学习一种基于卷积的深度学习模型,对给出的列预测出层次化的类。基于列的类型标注,我们可以进一步标注表格元素对应的实体和表格列之间的语义关系,从而利用这些表格数据对知识图谱实体进行填充。
[1] Gabriel Weaver, Barbara Strickland, and Gregory Crane.2006. Quantifying the accuracy of relational statements in wikipedia: amethodology. In JCDL, Vol. 6. Citeseer, 358–358
[2] https://www.cs.ox.ac.uk/isg/krr/
[3] https://www.turing.ac.uk/research/research-projects/artificial-intelligence-data-analytics-aida
[4] https://sirius-labs.no/
[5] Jiaoyan Chen, Ernesto Jiménez-Ruiz, IanHorrocks, and Charles Sutton. "ColNet: Embedding the Semantics of WebTables for Column Type Prediction." AAAI 2019
[6] Cafarella, Michael, et al. "Ten years ofwebtables." Proceedings of the VLDB Endowment 11.12 (2018):2140-2149.
[7] Jiaoyan Chen, Ernesto Jiménez-Ruiz, IanHorrocks. “Canonicalizing Knowledge Base Literals”. International Semantic WebConference (ISWC), 2019.
[8] https://en.wikipedia.org/wiki/Data_curation
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。