科普 | 动态本体简介
本文转载自知乎专栏知识图谱和智能问答。
近年来,随着语义Web的兴起,本体技术受到了广泛关注。很多大型跨国公司都开始研究本体技术。谷歌于2012年提出了知识图谱的项目,旨在利用本体技术来提高搜索的精度和更智能化的知识浏览。国内的互联网公司,如百度、搜狗,也已经开展这方面的项目。微软提出了Probase项目,旨在通过爬取网页中的信息来构建大规模的本体。IBM利用语义Web技术来处理异构医疗数据的整合以及更准确的查询回答。本体技术在IBM的著名问答系统Watson中发挥了重要的作用。Oracle实现了一个强大的语义数据推理和索引系统。本体技术还受到欧美政府的支持。英国政府发起了http://Data.gov.uk项目,把很多政府网站的信息都以本体的形式分布。而美国政府也有类似的项目。学术界对本体的研究有很多成果,特别是在计算机科学领域,有很多实用的技术被开发。欧盟在最近5年投入大量科研经费(累积超过数亿欧元)用于本体相关的研究。
本体可以被理解成特定领域规范概念集及其逻辑关系的描述。本体为特定领域中的信息提供了一个基本的分类框架,同时也为特定领域中的信息之间的关联性提供了一定程度的逻辑描述,使得特定领域中的信息资源能够在本体描述的框架上组织成一个有机的整体。近十多年来,在许多计算机科学家与许多领域的科学家及其工程人员的共同努力之下,在许多领域都已经创建有对应的元数据与本体。使用这些特定领域的元数据与本体,我们就可以对万维网上的现有的许多信息资源采用手工,半自动化,或自动化的手段进行语义标注(Semantic Annotation)。这样,我们就可以通过针对特定领域的语义搜索引擎有效地更精准地提供人们所需要的信息资源。由于许多领域知识之间都有一定的关联性,某个元数据或本体中的一些概念可能概念等价于其他一些元数据或本体中的另外一些概念,故这些特定领域的本体与元数据都存在着一定的语义关联性。这种关联性可以通过其关联描述来刻画。于是,关联语义数据集为我们提供了跨学科跨领域的语义数据的整合体。
一个本体在生成之后,根据应用发展的需求,总是处于不断地发展和变化之中,这就需要对之进行有效的管理。这些本体管理环节包括:
1. 本体演化(Ontology Evolution):研究本体的发展过程中的变化规律及其管理与维护的相关技术。
2. 本体融合(Ontology Integration):研究如何从多个本体中集成一个新的本体。
3. 本体验证(Ontology Validation): 研究如何验证本体的正确性。
4. 本体版本化(Ontology Versioning):研究如何维护与管理本体的演化过程中所生成的不同版本的本体的相关技术。
下面以元素周期表为例介绍本体。
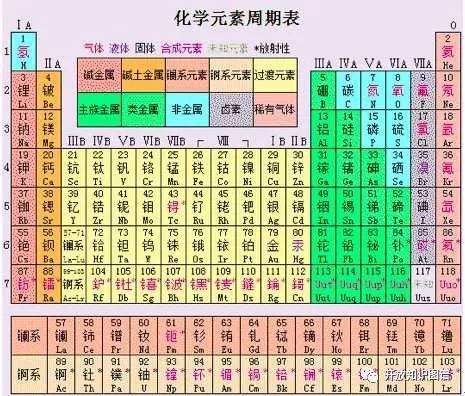
图1
如图1所示,元素周期表分为10类,比如说碱金属和碱土金属,这些可以看成是本体的类。每个类都包含一些化学元素,比如说主族金属包含铝和镓等。每一个化学元素通过百科可以找到各自的属性等信息。并且不同的化学元素之间会有一些关系。
在Palantir中,一个本体主要包括以下几个成分:
1. 对象(Object):这里对象指的是任何被建模的事物, Palantir中对象分为文档(document)、实体(entities)和事件(event)。文档是基于文本的,实体是一些类,比如说人、地点,而事件是以时间出现的事物。
2. 属性(Properties): 这里属性指的是对象的品质,比如说人的性别。
3. 关系(Relationship):这里关系指的是概念之间的关联,比如说人物之间的雇佣关系。
在Palantir中,对象、属性和关系是硬编码的,基于它们可以设计各种灵活的本体和数据模型。而这里的对象又被分为文档、实体和事件。这个分类非常有讲究,因为对于情报分析来说,很重要的就是对文档的检索以及文档的分析,对人物、组织等实体的画像和关联,对事件的建模和分析,而且文档、实体和事件之间是一个自循环的系统。这种灵活性是通过给某个对象添加不同的属性,或者给两个对象添加不同的关系来实现。跟一般的本体不一样的地方在于,动态本体允许对任何不再使用的对象、属性和关系进行移除,并且可以根据需求添加新的对象、属性和关系,所以本体是时刻处于动态更新的。另外,还支持对已有对象、属性和关系的功能的修改,比如说可以添加和修改标签、图标、解析器等。
动态本体允许一个组织对领域相关的信息进行建模,而且这种建模比较灵活。对于同一个概念或者相似概念可以多种方式进行建模。比如说,如果要对人的职业进行建模,有以下几种模式:
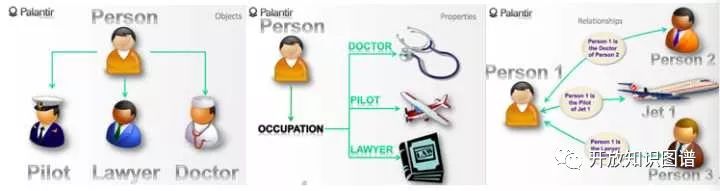
图2
图2中左边是把职业作为一种对象定义,即把Pilot、Lawyer、Doctor作为Person的子类,这里Pilot和Person一样都是对象,可以给出他们的属性等。图2中间是把职业作为Person的属性,而这里属性值是Doctor、Pilot、Lawyer。这里假设了一个人可以从事多个职业。图2中右边把职业看成是一种关系,这里有三种关系,即人和人之间的医患关系、人跟飞机之间的驾驶关系以及人跟人之间的律师关系。从图2可以看出对于不同的上下文,可以对一个事物做不同的建模。
动态本体对于异构数据的集成很有帮助。现有关系数据库的数据管理系统一般采用表和关系的固定模式来组织数据,当模式变化是,需要对表进行修改,导致很多重复劳动。另外,基于一个固定的模式也不利于对数据做集成,特别是对于数据经常要更新的场景。动态本体的提出就是为了提供一个灵活可变的数据模型,方便数据管理和多源数据的集成。在一个应用中,可以构建一个数据库的动态本体,而该动态本体可以用来集成各种数据。具体思路如下:
1. 通过一个对象类型编辑器来生成数据类型和数据类型的特征。
2. 通过一个属性类型编辑器生成属性类型并且定义该属性类型的特征。
3. 每个属性类型都有一个解析器,该解析器将一些输入的数据跟动态本体做一个映射,并且把输入数据添加到数据库中。
Palantir动态本体通过解析器可以把各种格式的数据都集成到一个数据库中,从而很好地实现了异构数据的集成。为了达到这个目前,需要将动态本体的对象类型和属性类型定义完备,同时需要将解析器的正则表达式写好,否则很难使用。这也是Palantir的动态本体的缺陷所在。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。





